ГЕОГРАФИЯ ФОРТА
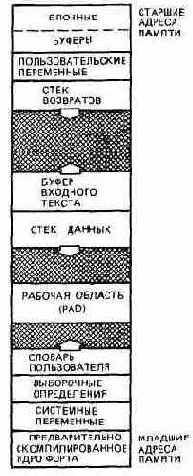 | Вы видите на рисунке карту памяти1 типичной Форт-системы для одного пользователя. Мультипрограммные системы, такие, как полиФорт, устроены намного сложнее, о чем пойдет речь позднее. А пока рассмотрим простой случай и последовательно изучим каждый район нашей карты.
Предварительно скомпилированное ядро Форта. В памяти с младшими адресами расположен единственный предварительно скомпилированный участок системы (уже скомпилированный в словарную форму). В одних системах коды этого участка хранятся на диске (как правило, блоки 1-8) и автоматически загружаются в память с произвольной выборкой во время запуска или восстановления вашего компьютера, в других - такой участок неизменно находится в программируемой постоянной памяти и становится доступным сразу, как только вы включаете компьютер. В предварительно скомпилированном участке обычно хранится большая часть математических операций и слов форматизации чисел одинарной длины, операции преобразования стека одинарной длины, команды редактирования, структуры управления, ассемблер, все определяющие слова, которые вам уже известны, и, конечно, интерпретаторы текста и адреса2. |
1Для начинающих. Здесь показано, каким образом распределяется намять компьютера в конкретной системе в зависимости от ее назначения Память разбита на участки по 1024 байта. Это число называется «К» (от слова «кило», означающего тысячу).
2 Для специалистов. Чтобы получить представление о том, как компактен Форт, вам достаточно знать, что весь предварительно скомпилированный участок полифорта занимает меньше 8К байтов памяти
Системные переменные. Следующий раздел памяти содержит системные переменные, которые созданы предварительно скомпилированным ядром Форта и используются всей системой. Они, как правило, не применяются пользователем.
Выборочные определения. Тот раздел Форт-системы, который не был предварительно скомпилирован, хранится на диске в виде исходного текста. Какую часть определений из этого раздела загружать, а какую - нет, вы можете решить сами, что улучшит управление использованием памяти вашего компьютера.
Блок загрузки для всех выборочных определений называется блоком выбора.
Словарь пользователя. Словарь расширяется в сторону увеличения адресов памяти по мере того, как вы добавляете ваши собственные определения в область памяти, называемую словарем пользователя. Его следующая доступная ячейка в любой момент времени определяется содержимым переменной с именем Н (или DP). Во время компиляции указатель Н, по мере того как очередной элемент добавляется к словарю, переходит с ячейки на ячейку (или с байта на байт). Таким образом, для компилятора указатель Н выступает в качестве закладки; он указывает то место в словаре, куда компилятор может компилировать следующий объект. Этот указатель также используется словом ALLOT, которое передвигает его на заданное число байтов. Например, выражение 10 ALLOT добавляет к нему 10 и, следовательно, компилятор зарезервирует память в словаре для массива, состоящего из 10 байтов (или пяти ячеек).
Родственным словом является и HERE, которое определяется весьма просто: : HERE ( -- текущий-адрес ) H @ ;
Оно помещает значение Н в стек. Слово , (запятая) помещает значение одинарной длины в следующую доступную ячейку словаря: : , ( n -- ) HERE ! 2 ALLOT ;
т. е. запоминает некоторое значение в HERE и продвигает указатель словаря на два байта, закрепляя память под это значение. С помощью HERE вы можете определить, какой объем памяти требуется для любого фрагмента вашей программы, для чего нужно сравнить HERE до компиляции и после нее. Например, выражение HERE 220 LOAD HERE SWAP - . 196 ok
показывает, что определения, загруженные блоком 220, заняли 196 байтов памяти словаря.
Рабочая область (PAD). На некотором удалении от HERE вы обнаружите в своем словаре небольшую область памяти, называемую рабочей областью. Наша рабочая область обычно служит для хранения строк символов в коде ASCII, которые подвергаются обработке перед выводом на терминал. Так, слова, осуществляющие форматирование чисел, используют рабочую область для обработки чисел в коде ASCII во время их перевода, прежде чем вывести эти числа с помощью TYPE,
Размер рабочей области не определен.
В большинстве систем расстояние между началом рабочей области и вершиной стека данных измеряется сотнями и даже тысячами байтов.
Поскольку адрес начала рабочей области определяется относительно последнего элемента словаря, он изменяется всякий раз при добавлении нового определения либо выполнении FORGET или EMPTY.
Подобная организация тем не менее гарантирует безопасность, так как рабочая область никогда не используется при выполнении перечисленных выше действий. Слово PAD вносит в вершину стека текущий адрес начала рабочей области. Оно имеет довольно простое определение:: PAD ( -- a) HERE 34 + ;
т.е. помещает в стек адрес, который отстоит на фиксированное число байтов от HERE (в действительности это число может меняться).
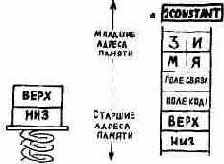
Стек данных. Намного выше рабочей области расположен участок, зарезервированный под стек данных. У вас может создаться впечатление, что значения где-то передвигаются вверх и вниз, как будто их кто-то «вталкивает» и «выталкивает», однако на самом деле ничего подобного не происходит. Единственное, что изменяется, - это указатель вершины стека.
Как вы увидите в дальнейшем, при занесении некоторого числа в стек фактически лишь уменьшается указатель (т. е. указывает на следующий участок в направлении к младшим адресам памяти), а затем число запоминается в том месте, куда показывает указатель. Когда вы удаляете число из стека, оно выбирается из участка, на который показывает указатель, после чего последний увеличивается.
Все числа, расположенные на карте памяти выше указателя стека, не имеют смысла.
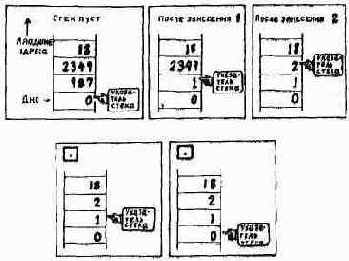
Но мере добавления в стек новых значений он «растет» в направлении младших адресов памяти.
Указатель стека выбирается посредством слова SP@1. Так как это слово доставляет адрес самого верхнего участка стека, выражение SP@ выбирает содержимое вершины стека. Такая операция, конечно, идентична операции DUP. Если у вас в стеке находится пять значений, то пятое значение можно скопировать с помощью выражения: SP@ 8 + @
(но в большинстве случаев это не может считаться хорошим стилем программирования).
На дно стека указывает переменная S0. Она всегда содержит адрес ячейки, расположенной непосредственно под ячейкой, соответствующей «пустому» стеку.
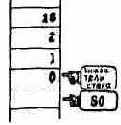
Заметим, что при размещении чисел двойной длины как в стеке, так и в словаре старшая по порядку ячейка размещается по
1 Для пользователей систем полифорта Это слово имеет имя 'S
младшему адресу. При выполнении операций 2! и 2@ (см. рисунок). Этот порядок размещения ячеек сохраняется.
Буфер входного текста. Буфер входного текста представляет собой область памяти длиной, как правило, 80 байт, куда поступают вводимые с клавиатуры символы после нажатия клавиши «возврат каретки». Именно здесь они будут просмотрены текстовым интерпретатором.
Не путайте этот термин с термином входной поток (см. гл. 3), который означает последовательность слов, подлежащих интерпретации. Данная последовательность может быть расположена либо в буфере входного текста (в режиме интерпретации), либо в блоке, содержащем исходный текст (в режиме загрузки).
Буфер входного текста увеличивается в направлении старших адресов памяти (в том же направлении, что и рабочая область (PAD)). Слово TIB выбирает начальный адрес буфера. (На фиг-Форте вы можете ввести "TIB @", на полиФорте - "S0 @".)
Стек возвратов. Выше буфера входного текста расположен стек возвратов, функционирование которого идентично функционированию стека данных.
Пользовательские переменные. Следующий раздел памяти содержит пользовательские переменные. Эти переменные включают в себя слова BASE, S0 и многие другие, которые мы рассмотрели ниже.
Блочные буферы. В самой верхней области памяти расположены буферы блоков. Каждый буфер имеет объем 1024 байта для размещения содержимого дискового блока. Всякий раз, когда вы осуществляете доступ к какому-либо блоку (например, распечатывая или загружая его), система копирует данный блок с диска в такой буфер, где он может изменяться с помощью редактора или интерпретироваться посредством слова LOAD.
Более подробно мы обсудим блочные буферы в гл. 10.
На этом наше путешествие по карте памяти типичной Форт-системы индивидуального пользования завершается. Далее приводится перечень уже знакомых вам слов, которые используются при работе с различными участками памяти.
|
Н или DP |
( -- а) |
Занесение в стек адреса указателя словаря. |
|
HERE |
( -- а) |
Занесение в стек адреса очередного доступного участка словаря. |
|
PAD |
( -- а) |
Занесение в стек адреса начала рабочей области, в которой хранятся строки символов в процессе промежуточной обработки. |
|
SP@ или 'S |
( -- а) |
Занесение в стек адреса вершины стека данных до того, как исполнено само слово SP@. |
|
S0 |
( -- а) |
Содержит адрес дна стека данных. |
|
TIB |
( -- a) |
Занесение в стек адреса начала буфера входного текста. |
