ВВОД ИЗ ВХОДНОГО ПОТОКА
Мы рассмотрели выше, каким образом ожидается ввод с клавиатуры. Однако Форт-система позволяет осуществлять ввод и из входного потока. Напоминаем, что входной поток - это последовательность символов, предназначенных для обработки текстовым интерпретатором. Символы могут быть расположены в буфере входного текста (в режиме интерпретации) или в блоке (в режиме загрузки).
Предположим, что пользователь хотел бы иметь возможность задавать свое имя, используя слово Я, например: Я BACЯ<return>
Пользователь должен набрать фрагмент Я ВАСЯ на одной строке, а затем нажать клавишу RETURN, Нам нужно, чтобы слово Я помещало имя пользователя в массив ИМЯ-ПОЛЬЗОВАТЕЛЯ. Но фрагмент ВАСЯ находится впереди по входному потоку и слово Я, следовательно, не может «ожидать» его с помощью EXPECT, так как он уже введен. Вместо этого необходимо найти средство для чтения опережающего слова.
Таким средством является слово WORD (СЛОВО). Оно сканирует входной поток в поисках фрагмента текста, ограниченного символом, код ASCII которого хранится в вершине стека. Например, выражение BL WORD
будет просматривать входной поток в поисках фрагмента текста, ограниченного пробелами. Найденную подстроку WORD поместит в свой собственный временный буфер вместе со счетчиком символов в первом байте буфера. В Форте строка символов, предваряемая одним байтом, в котором содержится число символов данной строки, называется строкой со счетчиком. Затем WORD вносит в вершину стека адрес своего временного буфера1.
Слово WORD - важный элемент текстового интерпретатора Форта, в котором выражение BL WORD применяется для сканирования входного потока в поисках слов и чисел.
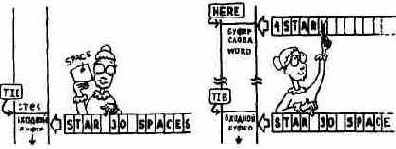
Пересылая фрагмент текста, WORD дополняет его в конце пробелом, но этот пробел не учитывается в счетчике. Вы можете создать определение Я следующим образом (используя массив, созданный ранее для слова ВСТРЕЧА): : Я ( имя-пользователя ( -- ) ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 BLANK BL WORD COUNT ИМЯ-ПОЛЬЗОВАТЕЛЯ SWAP CMOVE ;
Чтобы видеть вводимое имя, можно воспользоваться ранее определенным словом .ПОЛЬЗОВАТЕЛЬ.
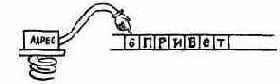
Каковы функции слова COUNT? Это слово разделяет адрес строки со счетчиком на адрес и счетчик. Полученный адрес указывает начало текста, а не байт со счетчиком. Например, при заданном в вершине стека адресе строки со счетчиком ПРИВЕТ
1 Для пользователей систем фиг-Форта. Ваша версия слова WORD ничего в вершине стека не оставляет. Для обеспечения совместимости с текстом рассматриваемого примера переопределите его:
: WORD ( -- a) WORD HERE ;
слово COUNT заносит в стек счетчик, увеличивает адрес:
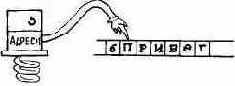
и в вершине стека остаются адрес строки и значение счетчика, которые могут служить аргументами для слов TYPE, CMOVE и т. д.
В нашем определении Я слово WORD оставляет в вершине стека адрес строки со счетчиком, а слово COUNT разделяет этот адрес на адрес и счетчик. Слово АДРЕС-ПОЛЬЗОВАТЕЛЯ обеспечивает адрес назначения. Слово SWAP расставляет аргументы в требуемом порядке (источник - получатель - счетчик) для CMOVE.
Обратите внимание на необычную стековую нотацию слова Я. По существующему соглашению описание, предшествующее стековому комментарию, указывает фрагмент, поиск которого во входном потоке осуществляется в данном определении. Может применяться также символ «\ »: : Я \ имя-пользователя ( -- ) ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 BLANK BL WORD COUNT ИМЯ-ПОЛЬЗОВАТЕЛЯ SWAP CMOVE ;
Отметим две особенности слова WORD. Первая особенность связана с тем, что, поскольку это слово используется текстовым интерпретатором Форта, найденный им фрагмент будет затерт при чтении следующего фрагмента из входного потока. Введите выражение BL WORD HI COUNT TYPE
Выражение BL WORD прочитает фрагмент HI и поместит его во временный буфер, но во время интерпретации слова COUNT фрагмент HI будет затерт фрагментом COUNT и в первом байте окажется значение счетчика 5, а не 2. При выполнении слова COUNT в вершину стека заносится значение счетчика 5. Наконец, при интерпретации слова TYPE фрагмент TYPE затрет предыдущий и выведется на экран (включая пробел пятым символом).
Поскольку WORD обычно находится внутри определения, фрагмент, полученный в результате выполнения этого слова, нужно переслать из буфера последнего в более надежное хранилище до считывания из входного потока очередного слова.
Другая особенность слова WORD состоит в том, что оно не воспринимает начальные вхождения символа-ограничителя. Если
в начале некоторого фрагмента набраны пробелы или если слова разделены пробелами, то выражение BL WORD осуществляет поиск до первого значащего символа и считывает фрагмент до первого пробела. Помещаются во временный буфер и учитываются в счетчике только значащие символы. Указанная особенность может вызывать затруднения при работе со словом WORD. Например, в гл. 3 было введено слово .(, обеспечивающее непосредственный вывод на экран очередного фрагмента из входного потока до правой круглой скобки. Это слово может быть определено следующим образом:: .( \ текст) ( -- ) ASCII ) WORD COUNT TYPE ;
Комментарий означает, что в данном определении фрагмент будет считываться до правой круглой скобки «)». Но в таком определении не предусмотрена ситуация с пустой строкой (без символов): .() CR CR
Наше определение не воспримет правую круглую скобку, поскольку она является первым просматриваемым символом, а посчитает фрагмент CR CR за строку, которая должна быть выведена на экран. Для подобных ситуаций в ряде Форт-систем имеется слово PARSE (РАЗБОР), функционирующее аналогично слову WORD, но воспринимающее начальные вхождения символа-ограничителя. Помните, что PARSE оставляет в вершине стека адрес строки и значение счетчика, а не адрес строки со счетчиком, как это делает WORD.
Ниже приводится слово, которым вы можете воспользоваться: : TEXT ( с) PAD 80 BLANK WORD COUNT PAD SWAP CMOVE> ;
Подобно WORD, слово TEXT выбирает из стека символ-ограничитель и сканирует входной поток до тех пор, пока из него не будет считан фрагмент, ограниченный этим символом. Затем фрагмент помещается в рабочую область (PAD). Отличительной чертой TEXT является то, что рабочая область перед занесением строки" заполняется пробелами, что облегчает выполнение слов TYPE и
-TRALLING.
|
WORD |
( с -- а) |
Чтение слова, ограниченного заданным символом, из входного потока. Полученный фрагмент оформляется в виде строки со счетчиком и ее адрес помещается в стек. |
|
COUNT |
( a -- a+1 #) |
Преобразование адреса строки со счетчиком (длина которой находится в первом строки) в формат, соответствующий использования словом TYPE а именно: в стек заносится адрес начала текста строки и ее длина. |
