Для чего компьютеры объединяют в сети
Для чего вообще потребовалось объединять компьютеры в сети? Что привело к появлению сетей?
Одной из главных причин стала необходимость совместного использования ресурсов (как физических, так и информационных). Если в организации имеется несколько компьютеров и эпизодически возникает потребность в печати какого-нибудь текста, то не имеет смысла покупать принтер для каждого компьютера. Гораздо выгоднее иметь один сетевой принтер для всех вычислительных машин. Аналогичная ситуация может возникать и с файлами данных. Зачем держать одинаковые файлы данных на всех компьютерах, поддерживая их когерентность, если можно хранить файл на одной машине, обеспечив к нему сетевой доступ со всех остальных?Второй причиной следует считать возможность ускорения вычислений. Здесь сетевые объединения машин успешно конкурируют с многопроцессорными вычислительными комплексами. Многопроцессорные системы, не затрагивая по существу строение операционных систем, требуют достаточно серьезных изменений на уровне hardware, что очень сильно повышает их стоимость. Во многих случаях можно добиться требуемой скорости вычислений параллельного алгоритма, используя не несколько процессоров внутри одного вычислительного комплекса, а несколько отдельных компьютеров, объединенных в сеть. Такие сетевые вычислительные кластеры часто имеют преимущество перед многопроцессорными комплексами в соотношении эффективность/стоимость.Следующая причина связана с повышением надежности работы вычислительной техники. В системах, где отказ может вызвать катастрофические последствия (атомная энергетика, космонавтика, авиация и т. д.), несколько вычислительных комплексов устанавливаются в связи, дублируя друг друга. При выходе из строя основного комплекса его работу немедленно продолжает дублирующий. Наконец, последней по времени появления причиной (но для многих основной по важности) стала возможность применения вычислительных сетей для общения пользователей. Электронные письма практически заменили письма обычные, а использование вычислительной техники для организации электронных или телефонных разговоров уверенно вытесняет обычную телефонную связь.
Двухуровневые адреса
При двухуровневой адресации полный сетевой адрес процесса или промежуточного объекта для хранения данных складывается из двух частей – адреса вычислительного комплекса, на котором находится процесс или объект в сети (удаленного адреса), и адреса самого процесса или объекта на этом вычислительном комплексе (локального адреса). Уникальность полного адреса будет обеспечиваться уникальностью удаленного адреса для каждого компьютера в сети и уникальностью локальных адресов объектов на компьютере. Давайте подробнее рассмотрим проблемы, возникающие для каждого из компонентов полного адреса.
Локальная адресация. Понятие порта
Во второй лекции мы говорили, что каждый процесс, существующий в данный момент в вычислительной системе, уже имеет собственный уникальный номер – PID. Но этот номер неудобно использовать в качестве локального адреса процесса при организации удаленной связи. Номер, который получает процесс при рождении, определяется моментом его запуска, предысторией работы вычислительного комплекса и является в значительной степени случайным числом, изменяющимся от запуска к запуску. Представьте себе, что адресат, с которым вы часто переписываетесь, постоянно переезжает с место на место, меняя адреса, так что, посылая очередное письмо, вы не можете с уверенностью сказать, где он сейчас проживает, и поймете все неудобство использования идентификатора процесса в качестве его локального адреса. Все сказанное выше справедливо и для идентификаторов промежуточных объектов, использующихся при локальном взаимодействии процессов в схемах с непрямой адресацией.
Для локальной адресации процессов и промежуточных объектов при удаленной связи обычно организуется новое специальное адресное пространство, например представляющее собой ограниченный набор положительных целочисленных значений или множество символических имен, аналогичных полным именам файлов в файловых системах. Каждый процесс, желающий принять участие в сетевом взаимодействии, после рождения закрепляет за собой один или несколько адресов в этом адресном пространстве. Каждому промежуточному объекту при его создании присваивается свой адрес из этого адресного пространства. При этом удаленные пользователи могут заранее договориться о том, какие именно адреса будут зарезервированы для данного процесса, независимо от времени его старта, или для данного объекта, независимо от момента его создания. Подобные адреса получили название портов, по аналогии с портами ввода-вывода.
Необходимо отметить, что в системе может существовать несколько таких адресных пространств для различных способов связи. При получении данных от удаленного процесса операционная система смотрит, на какой порт и для какого способа связи они были отправлены, определяет процесс, который заявил этот порт в качестве своего адреса, или объект, которому присвоен данный адрес, и доставляет полученную информацию адресату. Виды адресного пространства портов (т. е. способы построения локальных адресов) определяются, как правило, протоколами транспортного уровня эталонной модели.
Многоуровневая модель построения сетевых вычислительных систем
Даже беглого взгляда на перечень проблем, связанных с логической организацией взаимодействия удаленных процессов, достаточно, чтобы понять, что построение сетевых средств связи – задача более сложная, чем реализация локальных средств связи. Поэтому обычно задачу создания таких средств решают по частям, применяя уже неоднократно упоминавшийся нами "слоеный", или многоуровневый, подход.
Как уже отмечалось при обсуждении "слоеного" строения операционных систем на первой лекции, при таком подходе уровень N системы предоставляет сервисы уровню N+1, пользуясь в свою очередь только сервисами уровня N-1. Следовательно, каждый уровень может взаимодействовать непосредственно только со своими соседями, руководствуясь четко закрепленными соглашениями – вертикальными протоколами, которые принято называть интерфейсами.
Самым нижним уровнем в слоеных сетевых вычислительных системах является уровень, на котором реализуется реальная физическая связь между двумя узлами сети. Из предыдущего раздела следует, что для обеспечения обмена физическими сигналами между двумя различными вычислительными системами необходимо, чтобы эти системы поддерживали определенный протокол физического взаимодействия – горизонтальный протокол.
На самом верхнем уровне находятся пользовательские процессы, которые инициируют обмен данными. Количество и функции промежуточных уровней варьируются от одной системы к другой. Вернемся к нашей аналогии с пересылкой почтовых отправлений между людьми, проживающими в разных городах, правда, с порядком их пересылки несколько отличным от привычного житейского порядка. Рассмотрим в качестве пользовательских процессов руководителей различных организаций, желающих обменяться письмами. Руководитель (пользовательский процесс) готовит текст письма (данные) для пересылки в другую организацию. Затем он отдает его своему секретарю (совершает системный вызов – обращение к нижележащему уровню), сообщая, кому и куда должно быть направлено письмо. Секретарь снимает с него копию и выясняет адрес организации.
Далее идет обращение к нижестоящему уровню, допустим, письмо направляется в канцелярию. Здесь оно регистрируется (ему присваивается порядковый номер), один экземпляр запечатывается в конверт, на котором указывается, кому и куда адресовано письмо, впечатывается адрес отправителя. Копия остается в канцелярии, а конверт отправляется на почту (переход на следующий уровень). На почте наклеиваются марки и делаются другие служебные пометки, определяется способ доставки корреспонденции и т. д. Наконец, поездом, самолетом или курьером (физический уровень!) письмо следует в другой город, в котором все уровни проходятся в обратном порядке. Пользовательский уровень (руководитель) после подготовки исходных данных и инициации процесса взаимодействия далее судьбой почтового отправления не занимается. Все остальное (включая, быть может, проверку его доставки и посылку копии в случае утери) выполняют нижележащие уровни.
Заметим, что на каждом уровне взаимодействия в городе отправителя исходные данные (текст письма) обрастают дополнительной служебной информацией. Соответствующие уровни почтовой службы в городе получателя должны уметь понимать эту служебную информацию. Таким образом, для одинаковых уровней в различных городах необходимо следование специальным соглашениям – поддержка определенных горизонтальных протоколов.
Точно так же в сетевых вычислительных системах все их одинаковые уровни, лежащие выше физического, виртуально обмениваются данными посредством горизонтальных протоколов. Наличие такой виртуальной связи означает, что уровень N компьютера 2 должен получить ту же самую информацию, которая была отправлена уровнем N компьютера 1. Хотя в реальности эта информация должна была сначала дойти сверху вниз до уровня 1 компьютера 1, затем передана уровню 1 компьютера 2 и только после этого доставлена снизу вверх уровню N этого компьютера.
Формальный перечень правил, определяющих последовательность и формат сообщений, которыми обмениваются сетевые компоненты различных вычислительных систем, лежащие на одном уровне, мы и будем называть сетевым протоколом.
Всю совокупность вертикальных и горизонтальных протоколов (интерфейсов и сетевых протоколов) в сетевых системах, построенных по "слоеному" принципу, достаточную для организации взаимодействия удаленных процессов, принято называть семейством протоколов или стеком протоколов. Сети, построенные на основе разных стеков протоколов, могут быть объединены между собой с использованием вычислительных устройств, осуществляющих трансляцию из одного стека протоколов в другой, причем на различных уровнях слоеной модели
Эталоном многоуровневой схемы построения сетевых средств связи считается семиуровневая модель открытого взаимодействия систем (Open System Interconnection – OSI), предложенная Международной организацией Стандартов (International Standard Organization – ISO) и получившая сокращенное наименование OSI/ISO (см. рис. 14.1).
Давайте очень кратко опишем, какие функции выполняют различные уровни модели OSI/ISO [Олифер, 2001]:
Уровень 1 – физический. Этот уровень связан с работой hardware. На нем определяются физические аспекты передачи информации по линиям связи, такие как: напряжения, частоты, природа передающей среды, способ передачи двоичной информации по физическому носителю, вплоть до размеров и формы используемых разъемов. В компьютерах за поддержку физического уровня обычно отвечает сетевой адаптер.Уровень 2 – канальный. Этот уровень отвечает за передачу данных по физическому уровню без искажений между непосредственно связанными узлами сети. На нем формируются физические пакеты данных для реальной доставки по физическому уровню. Протоколы канального уровня реализуются совместно сетевыми адаптерами и их драйверами (понятие драйвера рассматривалось в лекции 13).Уровень 3 – сетевой. Сетевой уровень несет ответственность за доставку информации от узла-отправителя к узлу-получателю. На этом уровне частично решаются вопросы адресации, осуществляется выбор маршрутов следования пакетов данных, решаются вопросы стыковки сетей, а также управление скоростью передачи информации для предотвращения перегрузок в сети. Уровень 4 – транспортный.
Регламентирует передачу данных между удаленными процессами. Обеспечивает доставку информации вышележащим уровнем с необходимой степенью надежности, компенсируя, быть может, ненадежность нижележащих уровней, связанную с искажением и потерей данных или доставкой пакетов в неправильном порядке. Наряду с сетевым уровнем может управлять скоростью передачи данных и частично решать проблемы адресации.

Рис. 14.1. Семиуровневая эталонная модель OSI/ISO
Уровень 5 – сеансовый. Координирует взаимодействие связывающихся процессов. Основная задача – предоставление средств синхронизации взаимодействующих процессов. Такие средства синхронизации позволяют создавать контрольные точки при передаче больших объемов информации. В случае сбоя в работе сети передачу данных можно возобновить с последней контрольной точки, а не начинать заново.Уровень 6 – уровень представления данных. Отвечает за форму представления данных, перекодирует текстовую и графическую информацию из одного формата в другой, обеспечивает ее сжатие и распаковку, шифрование и декодирование. Уровень 7 – прикладной. Служит для организации интерфейса между пользователем и сетью. На этом уровне реализуются такие сервисы, как удаленная передача данных, удаленный терминальный доступ, почтовая служба и работа во Всемирной паутине (Web-браузеры).
Надо отметить, что к приведенной эталонной модели большинство практиков относится без излишнего пиетета. Эта модель не предвосхитила появления различных семейств протоколов, таких как, например, семейство протоколов TCP/IP, а наоборот, была создана под их влиянием. Ее не следует рассматривать как готовый оптимальный чертеж для создания любого сетевого средства связи. Наличие некоторой функции на определенном уровне не гарантирует, что это ее наилучшее место, некоторые функции (например, коррекция ошибок) дублируются на нескольких уровнях, да и само деление на 7 уровней носит отчасти произвольный характер. Хотя в конце концов были созданы работающие реализации этой модели, но наиболее распространенные семейства протоколов лишь до некоторой степени согласуются с ней.Как отмечено в книге [Таненбаум, 2002], она больше подходит для реализации телефонных, а не вычислительных сетей. Ценность предложенной эталонной модели заключается в том, что она показывает направление, в котором должны двигаться разработчики новых вычислительных сетей.
Проблемы 3–5, перечисленные в разделе "Основные вопросы логической организации передачи информации" между удаленными процессами, относятся в основном к сетевому и транспортному уровням эталонной модели и, соответственно, решаются на уровне сетевых и транспортных протоколов. Давайте приступим, наконец, к их рассмотрению.
Одноуровневые адреса
В небольших компьютерных сетях можно построить одноуровневую систему адресации. При таком подходе каждый процесс, желающий стать участником удаленного взаимодействия (при прямой адресации), и каждый объект, для такого взаимодействия предназначенный (при непрямой адресации), получают по мере необходимости собственные адреса (символьные или числовые), а сами вычислительные комплексы, объединенные в сеть, никаких самостоятельных адресов не имеют. Подобный метод требует довольно сложного протокола обеспечения уникальности адресов. Вычислительный комплекс, на котором запускается взаимодействующий процесс, должен запросить все компьютеры сети о возможности присвоения процессу некоторого адреса. Только после получения от них согласия процессу может быть назначен адрес. Поскольку процесс, посылающий данные другому процессу, не может знать, на каком компоненте сети находится процесс-адресат, передаваемая информация должна быть направлена всем компонентам сети (так называемое широковещательное сообщение – broadcast message), проанализирована ими и либо отброшена (если процесса-адресата на данном компьютере нет), либо доставлена по назначению. Так как все данные постоянно передаются от одного комплекса ко всем остальным, такую одноуровневую схему обычно применяют только в локальных сетях с прямой физической связью всех компьютеров между собой (например, в сети NetBIOS на базе Ethernet), но она является существенно менее эффективной, чем двухуровневая схема адресации.
Основные вопросы логической организации передачи информации между удаленными процессами
К числу наиболее фундаментальных вопросов, связанных с логической организацией взаимодействия удаленных процессов, можно отнести следующие:
Как нужно соединять между собой различные вычислительные системы физическими линиями связи для организации взаимодействия удаленных процессов? Какими критериями при этом следует пользоваться?Как избежать возникновения race condition при передаче информации различными вычислительными системами после их подключения к общей линии связи? Какие алгоритмы могут при этом применяться?Какие виды интерфейсов могут быть предоставлены пользователю операционными системами для передачи информации по сети? Какие существуют модели взаимодействия удаленных процессов? Как процессы, работающие под управлением различных по своему строению операционных систем, могут общаться друг с другом?Какие существуют подходы к организации адресации удаленных процессов? Насколько они эффективны? Как организуется доставка информации от компьютера-отправителя к компьютеру-получателю через компьютеры-посредники? Как выбирается маршрут для передачи данных в случае разветвленной сетевой структуры, когда существует не один вариант следования пакетов данных через компьютеры-посредники?
Разумеется, степень важности этих вопросов во многом зависит от того, с какой точки зрения мы рассматриваем взаимодействие удаленных процессов. Системного программиста, в первую очередь, интересуют интерфейсы, предоставляемые операционными системами. Сетевого администратора больше будут занимать вопросы адресации процессов и выбора маршрута доставки данных. Проектировщика сетей в организации – способы соединения компьютеров и обеспечения корректного использования разделяемых сетевых ресурсов. Мы изучаем особенности строения и функционирования частей операционных систем, ответственных за взаимодействие удаленных процессов, а поэтому рассматриваемый перечень вопросов существенно сокращается.
Выбор способа соединения участников сетевого взаимодействия физическими линиями связи (количество и тип прокладываемых коммуникаций, какие именно устройства и как они будут соединять,т. е. топология сети) определяется проектировщиками сетей исходя из имеющихся средств, требуемой производительности и надежности взаимодействия. Все это не имеет отношения к функционированию операционных систем, является внешним по отношению к ним и в нашем курсе рассматриваться не будет.
В современных сетевых вычислительных комплексах решение вопросов организации взаимоисключений при использовании общей линии связи, как правило, также находится вне компетенции операционных систем и вынесено на физический уровень организации взаимодействия. Ответственность за корректное использование коммуникаций возлагается на сетевые адаптеры, поэтому подобные проблемы мы тоже рассматривать не будем.
Из приведенного перечня мы с вами подробнее остановимся на решении вопросов, приведенных в пунктах 3–5.
Полные адреса. Понятие сокета (socket)
Таким образом, полный адрес удаленного процесса или промежуточного объекта для конкретного способа связи с точки зрения операционных систем определяется парой адресов: <числовой адрес компьютера в сети, порт>. Подобная пара получила наименование socket (в переводе – "гнездо" или, как стали писать в последнее время, сокет), а сам способ их использования – организация связи с помощью сокетов. В случае непрямой адресации с использованием промежуточных объектов сами эти объекты также принято называть сокетами. Поскольку разные протоколы транспортного уровня требуют разных адресных пространств портов, то для каждой пары надо указывать, какой транспортный протокол она использует, – говорят о разных типах сокетов.
В современных сетевых системах числовой адрес обычно получает не сам вычислительный комплекс, а его сетевой адаптер, с помощью которого комплекс подключается к линии связи. При наличии нескольких сетевых адаптеров для разных линий связи один и тот же вычислительный комплекс может иметь несколько числовых адресов. В таких системах полные адреса удаленного адресата (процесса или промежуточного объекта) задаются парами <числовой адрес сетевого адаптера, порт> и требуют доставки информации через указанный сетевой адаптер.
Понятие протокола
Для описания происходящего в автономной операционной системе в лекции 2 было введено основополагающее понятие "процесс", на котором, по сути дела, базируется весь наш курс. Для того чтобы описать взаимодействие удаленных процессов и понять, какие функции и как должны выполнять дополнительные части сетевых операционных систем, отвечающих за такое взаимодействие, нам понадобится не менее фундаментальное понятие – протокол.
"Общение" локальных процессов напоминает общение людей, проживающих в одном городе. Если взаимодействующие процессы находятся под управлением различных операционных систем, то эта ситуация подобна общению людей, проживающих в разных городах и, возможно, в разных странах.
Каким образом два человека, находящиеся в разных городах, а тем более странах, могут обмениваться информацией? Для этого им обычно приходится прибегать к услугам соответствующих служб связи. При этом между службами связи различных городов (государств) должны быть заключены определенные соглашения, позволяющие корректно организовывать такой обмен. Если речь идет, например, о почтовых отправлениях, то в первую очередь необходимо договориться о том, что может представлять собой почтовое отправление, какой вид оно может иметь. Некоторые племена индейцев для передачи информации пользовались узелковыми письмами – поясами, к которым крепились веревочки с различным числом и формой узелков. Если бы такое письмо попало в современный почтовый ящик, то, пожалуй, ни одно отделение связи не догадалось бы, что это – письмо, и пояс был бы выброшен как ненужный хлам. Помимо формы представления информации необходима договоренность о том, какой служебной информацией должно снабжаться почтовое отправление (адрес получателя, срочность доставки, способ пересылки: поездом, авиацией, с помощью курьера и т. п.) и в каком формате она должна быть представлена. Адреса, например, в России и в США принято записывать по-разному. В России мы начинаем адрес со страны, далее указывается город, улица и квартира.
В США все наоборот: сначала указывается квартира, затем улица и т. д. Конечно, даже при неправильной записи адреса письмо, скорее всего, дойдет до получателя, но можно себе представить растерянность почтальона, пытающегося разгадать, что это за страна или город – "кв.162"? Как видим, доставка почтового отправления из одного города (страны) в другой требует целого ряда соглашений между почтовыми ведомствами этих городов (стран).
Аналогичная ситуация возникает и при общении удаленных процессов, работающих под управлением разных операционных систем. Здесь процессы играют роль людей, проживающих в разных городах, а сетевые части операционных систем – роль соответствующих служб связи. Для того чтобы удаленные процессы могли обмениваться данными, необходимо, чтобы сетевые части операционных систем руководствовались определенными соглашениями, или, как принято говорить, поддерживали определенные протоколы. Термин "протокол" уже встречался нам в лекции 13, посвященной организации ввода-вывода в операционных системах, при обсуждении понятия "шина". Мы говорили, что понятие шины подразумевает не только набор проводников, но и набор жестко заданных протоколов, определяющий перечень сообщений, который может быть передан с помощью электрических сигналов по этим проводникам, т. е. в "протокол" мы вкладывали практически тот же смысл. В следующем разделе мы попытаемся дать более формализованное определение этого термина.
Необходимо отметить, что и локальные процессы при общении также должны руководствоваться определенными соглашениями или поддерживать определенные протоколы. Только в автономных операционных системах они несколько завуалированы. В роли таких протоколов выступают специальная последовательность системных вызовов при организации взаимодействия процессов и соглашения о параметрах системных вызовов.
Различные способы решения проблем 3–5, поднятых в предыдущем разделе, по существу, представляют собой различные соглашения, которых должны придерживаться сетевые части операционных систем, т.
е. различные сетевые протоколы. Именно наличие сетевых протоколов позволяет организовать взаимодействие удаленных процессов.
При рассмотрении перечисленных выше проблем необходимо учитывать, с какими сетями мы имеем дело.
В литературе принято говорить о локальных вычислительных сетях (LAN – Local Area Network) и глобальных вычислительных сетях (WAN – Wide Area Network). Строгого определения этим понятиям обычно не дается, а принадлежность сети к тому или иному типу часто определяется взаимным расположением вычислительных комплексов, объединенных в сеть. Так, например, в большинстве работ к локальным сетям относят сети, состоящие из компьютеров одной организации, размещенные в пределах одного или нескольких зданий, а к глобальным сетям – сети, охватывающие все компьютеры в нескольких городах и более. Зачастую вводится дополнительный термин для описания сетей промежуточного масштаба – муниципальных или городских вычислительных сетей (MAN – Metropolitan Area Network) – сетей, объединяющих компьютеры различных организаций в пределах одного города или одного городского района. Таким образом, упрощенно можно рассматривать глобальные сети как сети, состоящие из локальных и муниципальных сетей. А муниципальные сети, в свою очередь, могут состоять из нескольких локальных сетей. На самом деле деление сетей на локальные, глобальные и муниципальные обычно связано не столько с местоположением и принадлежностью вычислительных систем, соединенных сетью, сколько с различными подходами, применяемыми для решения поставленных вопросов в рамках той или иной сети, – с различными используемыми протоколами.
Проблемы адресации в сети
Любой пакет информации, передаваемый по сети, должен быть снабжен адресом получателя. Если взаимодействие подразумевает двустороннее общение, то в пакет следует также включить и адрес отправителя. В лекции 4 мы описали один из протоколов организации надежной связи с использованием контрольных сумм, нумерации пакетов и подтверждения получения неискаженного пакета в правильном порядке. Для отправки подтверждений обратный адрес также следует включать в пересылаемый пакет. Таким образом, практически каждый сетевой пакет информации должен быть снабжен адресом получателя и адресом отправителя. Как могут выглядеть такие адреса?
Несколько раньше, обсуждая отличия взаимодействия удаленных процессов от взаимодействия локальных процессов, мы говорили, что удаленные адресаты должны обладать уникальными адресами уже не в пределах одного компьютера, а в рамках всей сети. Существует два подхода к наделению объектов такими сетевыми адресами: одноуровневый и двухуровневый.
Проблемы маршрутизации в сетях
При наличии прямой линии связи между двумя компьютерами обычно не возникает вопросов о том, каким именно путем должна быть доставлена информация. Но, как уже упоминалось, одно из отличий взаимодействия удаленных процессов от взаимодействия процессов локальных состоит в использовании в большинстве случаев процессов-посредников, расположенных на вычислительных комплексах, не являющихся комплексами отправителя и получателя. В сложных топологических схемах организации сетей информация между двумя компьютерами может передаваться по различным путям. Возникает вопрос: как организовать работу операционных систем на комплексах -участниках связи (это могут быть конечные или промежуточные комплексы) для определения маршрута передачи данных? По какой из нескольких линий связи (или через какой сетевой адаптер) нужно отправить пакет информации? Какие протоколы маршрутизации возможны? Существует два принципиально разных подхода к решению этой проблемы: маршрутизация от источника передачи данных и одношаговая маршрутизация.
Маршрутизация от источника передачи данных. При маршрутизации от источника данных полный маршрут передачи пакета по сети формируется на компьютере-отправителе в виде последовательности числовых адресов сетевых адаптеров, через которые должен пройти пакет, чтобы добраться до компьютера-получателя, и целиком включается в состав этого пакета. В этом случае промежуточные компоненты сети при определении дальнейшего направления движения пакета не принимают самостоятельно никаких решений, а следуют указаниям, содержащимся в пакете. Одношаговая маршрутизация. При одношаговой маршрутизации каждый компонент сети, принимающий участие в передаче информации, самостоятельно определяет, какому следующему компоненту, находящемуся в зоне прямого доступа, она должна быть отправлена. Решение принимается на основании анализа содержащегося в пакете адреса получателя. Полный маршрут передачи данных складывается из одношаговых решений, принятых компонентами сети.
Маршрутизация от источника передачи данных легко реализуется на промежуточных компонентах сети, но требует полного знания маршрутов на конечных компонентах.
Она достаточно редко используется в современных сетевых системах, и далее мы ее рассматривать не будем.
Для работы алгоритмов одношаговой маршрутизации, которые являются основой соответствующих протоколов, на каждом компоненте сети, имеющем возможность передавать информацию более чем одному компоненту, обычно строится специальная таблица маршрутов (см. рис. 14.3). В простейшем случае каждая запись такой таблицы содержит: адрес вычислительного комплекса получателя; адрес компонента сети, напрямую подсоединенного к данному, которому следует отправить пакет, предназначенный для этого получателя; указание о том, по какой линии связи (через какой сетевой адаптер) должен быть отправлен пакет. Поскольку получателей в сети существует огромное количество, для сокращения числа записей в таблице маршрутизации обычно прибегают к двум специальным приемам.
Во-первых, числовые адреса топологически близко расположенных комплексов (например, комплексов, принадлежащих одной локальной вычислительной сети) стараются выбирать из последовательного диапазона адресов. В этом случае запись в таблице маршрутизации может содержать не адрес конкретного получателя, а диапазон адресов для некоторой сети (номер сети).
Во-вторых, если для очень многих получателей в качестве очередного узла маршрута используется один и тот же компонент сети, а остальные маршруты выбираются для ограниченного числа получателей, то в таблицу явно заносятся только записи для этого небольшого количества получателей, а для маршрута, ведущего к большей части всей сети, делается одна запись – маршрутизация по умолчанию (default). Пример простой таблицы маршрутизации для некоторого комплекса некой абстрактной сети приведен ниже:

Рис. 14.3. Простая таблица маршрутизации
По способам формирования и использования таблиц маршрутизации алгоритмы одношаговой маршрутизации можно разделить на три класса:
алгоритмы фиксированной маршрутизации;алгоритмы простой маршрутизации;алгоритмы динамической маршрутизации.
При фиксированной маршрутизации таблица, как правило, создается в процессе загрузки операционной системы. Все записи в ней являются статическими. Линия связи, которая будет использоваться для доставки информации от данного узла к некоторому узлу A в сети, выбирается раз и навсегда. Обычно линии выбирают так, чтобы минимизировать полное время доставки данных. Преимуществом этой стратегии является простота реализации. Основной же недостаток заключается в том, что при отказе выбранной линии связи данные не будут доставлены, даже если существует другой физический путь для их передачи.
В алгоритмах простой маршрутизации таблица либо не используется совсем, либо строится на основе анализа адресов отправителей приходящих пакетов информации. Различают несколько видов простой маршрутизации – случайную, лавинную и маршрутизацию по прецедентам. При случайной маршрутизации прибывший пакет отсылается в первом попавшемся направлении, кроме исходного. При лавинной маршрутизации один и тот же пакет рассылается по всем направлениям, кроме исходного. Случайная и лавинная маршрутизации, естественно, не используют таблиц маршрутов. При маршрутизации по прецедентам таблица маршрутизации строится по предыдущему опыту, исходя из анализа адресов отправителей приходящих пакетов. Если прибывший пакет адресован компоненту сети, от которого когда-либо приходили данные, то соответствующая запись об этом содержится в таблице маршрутов, и для дальнейшей передачи пакета выбирается линия связи, указанная в таблице. Если такой записи нет, то пакет может быть отослан случайным или лавинным способом. Алгоритмы простой маршрутизации действительно просты в реализации, но отнюдь не гарантируют доставку пакета указанному адресату за приемлемое время и по рациональному маршруту без перегрузки сети.
Наиболее гибкими являются алгоритмы динамической или адаптивной маршрутизации, которые умеют обновлять содержимое таблиц маршрутов на основе обработки специальных сообщений, приходящих от других компонентов сети, занимающихся маршрутизацией, удовлетворяющих определенному протоколу.
Такие алгоритмы принято делить на два подкласса: алгоритмы дистанционно-векторные и алгоритмы состояния связей.
При дистанционно-векторной маршрутизации компоненты операционных систем на соседних вычислительных комплексах сети, занимающиеся выбором маршрута (их принято называть маршрутизатор или router), периодически обмениваются векторами, которые представляют собой информацию о расстояниях от данного компонента до всех известных ему адресатов в сети. Под расстоянием обычно понимается количество переходов между компонентами сети (hops), которые необходимо сделать, чтобы достичь адресата, хотя возможно существование и других метрик, включающих скорость и/или стоимость передачи пакета по линии связи. Каждый такой вектор формируется на основании таблицы маршрутов. Пришедшие от других комплексов векторы модернизируются с учетом расстояния, которое они прошли при последней передаче. Затем в таблицу маршрутизации вносятся изменения, так чтобы в ней содержались только маршруты с кратчайшими расстояниями. При достаточно длительной работе каждый маршрутизатор будет иметь таблицу маршрутизации с оптимальными маршрутами ко всем потенциальным адресатам.
Векторно-дистанционные протоколы обеспечивают достаточно разумную маршрутизацию пакетов, но не способны предотвратить возможность возникновения маршрутных петель при сбоях в работе сети. Поэтому векторно-дистанционная маршрутизация может быть эффективна только в относительно небольших сетях. Для больших сетей применяются алгоритмы состояния связей, на каждом маршрутизаторе строящие графы сети, в качестве узлов которого выступают ее компоненты, а в качестве ребер, обладающих стоимостью, существующие между ними линии связи. Маршрутизаторы периодически обмениваются графами и вносят в них изменения. Выбор маршрута связан с поиском оптимального по стоимости пути по такому графу.
Подробное описание протоколов динамической маршрутизации можно найти в [Олифер, 2002], [Таненбаум, 2003].
Обычно вычислительные сети используют смесь различных стратегий маршрутизации.Для одних адресов назначения может использоваться фиксированная маршрутизация, для других – простая, для третьих – динамическая. В локальных вычислительных сетях обычно используются алгоритмы фиксированной маршрутизации, в отличие от глобальных вычислительных сетей, в которых в основном применяют алгоритмы адаптивной маршрутизации. Протоколы маршрутизации относятся к сетевому уровню эталонной модели.
Сетевые и распределенные операционные системы
В первой лекции мы говорили, что существует два основных подхода к организации операционных систем для вычислительных комплексов, связанных в сеть, – это сетевые и распределенные операционные системы. Необходимо отметить, что терминология в этой области еще не устоялась. В одних работах все операционные системы, обеспечивающие функционирование компьютеров в сети, называются распределенными, а в других, наоборот, сетевыми. Мы придерживаемся той точки зрения, что сетевые и распределенные системы являются принципиально различными.
В сетевых операционных системах для того, чтобы задействовать ресурсы другого сетевого компьютера, пользователи должны знать о его наличии и уметь это сделать. Каждая машина в сети работает под управлением своей локальной операционной системы, отличающейся от операционной системы автономного компьютера наличием дополнительных сетевых средств (программной поддержкой для сетевых интерфейсных устройств и доступа к удаленным ресурсам), но эти дополнения существенно не меняют структуру операционной системы.
Распределенная система, напротив, внешне выглядит как обычная автономная система. Пользователь не знает и не должен знать, где его файлы хранятся, на локальной или удаленной машине, и где его программы выполняются. Он может вообще не знать, подключен ли его компьютер к сети. Внутреннее строение распределенной операционной системы имеет существенные отличия от автономных систем.
Изучение строения распределенных операционных систем не входит в задачи нашего курса. Этому вопросу посвящены другие учебные курсы – Advanced operating systems, как называют их в англоязычных странах, или "Современные операционные системы", как принято называть их в России.
В этой лекции мы затронем вопросы, связанные с сетевыми операционными системами, а именно – какие изменения необходимо внести в классическую операционную систему для объединения компьютеров в сеть.
Синхронизация удаленных процессов
Мы рассмотрели основные принципы логической организации сетевых средств связи, внешние по отношению к взаимодействующим процессам. Однако, как отмечалось в лекции 5, для корректной работы таких процессов необходимо обеспечить определенную их синхронизацию, которая устранила бы возникновение race condition на соответствующих критических участках. Вопросы синхронизации удаленных процессов обычно рассматриваются в курсах, посвященных распределенным операционным системам. Интересующиеся этими вопросами могут обратиться к книгам [Silberschatz, 2002], [Таненбаум II, 2003].
Связь с установлением логического соединения и передача данных с помощью сообщений
Рассказывая об отличиях взаимодействия локальных и удаленных процессов, мы упомянули, что в основе всех средств связи на автономном компьютере так или иначе лежит механизм совместного использования памяти, в то время как в основе всех средств связи между удаленными процессами лежит передача сообщений. Неудивительно, что количество категорий средств удаленной связи сокращается до одной – канальных средств связи. Обеспечивать интерфейс для сигнальных средств связи и разделяемой памяти, базируясь на передаче пакетов данных, становится слишком сложно и дорого.
Рассматривая канальные средства связи для локальных процессов в лекции 4, мы говорили о существовании двух моделей передачи данных по каналам связи (теперь мы можем говорить о двух принципиально разных видах протоколов организации канальной связи): поток ввода-вывода и сообщения. Для общения удаленных процессов применяются обе модели, однако теперь уже более простой моделью становится передача информации с помощью сообщений. Реализация различных моделей происходит на основе протоколов транспортного уровня OSI/ISO.
Транспортные протоколы связи удаленных процессов, которые предназначены для обмена сообщениями, получили наименование протоколов без установления логического соединения (connectionless) или протоколов обмена датаграммами, поскольку само сообщение здесь принято называть датаграммой (datagramm) или дейтаграммой. Каждое сообщение адресуется и посылается процессом индивидуально. С точки зрения операционных систем все датаграммы – это независимые единицы, не имеющие ничего общего с другими датаграммами, которыми обмениваются эти же процессы.
Необходимо отметить, что с точки зрения процессов, обменивающихся информацией, датаграммы, конечно, могут быть связаны по содержанию друг с другом, но ответственность за установление и поддержание этой семантической связи лежит не на сетевых частях операционных систем, а на самих пользовательских взаимодействующих процессах (вышележащие уровни эталонной модели).
По-другому обстоит дело с транспортными протоколами, которые поддерживают потоковую модель. Они получили наименование протоколов, требующих установления логического соединения (connection-oriented). И в их основе лежит передача данных с помощью пакетов информации. Но операционные системы сами нарезают эти пакеты из передаваемого потока данных, организовывают правильную последовательность их получения и снова объединяют полученные пакеты в поток, так что с точки зрения взаимодействующих процессов после установления логического соединения они имеют дело с потоковым средством связи, напоминающим pipe или FIFO. Эти протоколы должны обеспечивать надежную связь.
Удаленная адресация и разрешение адресов
Инициатором связи процессов друг с другом всегда является человек, будь то программист или обычный пользователь. Как мы неоднократно отмечали в лекциях, человеку свойственно думать словами, он легче воспринимает символьную информацию. Поэтому очевидно, что каждая машина в сети получает символьное, часто даже содержательное имя. Компьютер не разбирается в смысловом содержании символов, ему проще оперировать числами, желательно одного и того же формата, которые помещаются, например, в 4 байта или в 16 байт. Поэтому каждый компьютер в сети для удобства работы вычислительных систем получает числовой адрес. Возникает проблема отображения пространства символьных имен (или адресов) вычислительных комплексов в пространство их числовых адресов. Эта проблема получила наименование проблемы разрешения адресов.
С подобными задачами мы уже сталкивались, обсуждая организацию памяти в вычислительных системах (отображение имен переменных в их адреса в процессе компиляции и редактирования связей) и организацию файловых систем (отображение имен файлов в их расположении на диске). Посмотрим, как она может быть решена в сетевом варианте.
Первый способ решения заключается в том, что на каждом сетевом компьютере создается файл, содержащий имена всех машин, доступных по сети, и их числовые эквиваленты. Обращаясь к этому файлу, операционная система легко может перевести символьный удаленный адрес в числовую форму. Такой подход использовался на заре эпохи глобальных сетей и применяется в изолированных локальных сетях в настоящее время. Действительно, легко поддерживать файл соответствий в корректном виде, внося в него необходимые изменения, когда общее число сетевых машин не превышает нескольких десятков. Как правило, изменения вносятся на некотором выделенном административном вычислительном комплексе, откуда затем обновленный файл рассылается по всем компонентам сети.
В современной сетевой паутине этот подход является неприемлемым. Дело даже не в размерах подобного файла, а в частоте требуемых обновлений и в огромном количестве рассылок, что может полностью подорвать производительность сети.
Используем полученную структуру для построения имен компьютеров, подобно тому как мы поступали при построении полных имен файлов в структуре директорий файловой системы. Только теперь, двигаясь от корневой вершины к терминальному узлу – отдельному компьютеру, будем вести запись имен подобластей справа налево и отделять имена друг от друга с помощью символа ".".
Допустим, некоторая подобласть, состоящая из одного компьютера, получила имя serv, она входит в подобласть, объединяющую все компьютеры некоторой лаборатории, с именем crec. Та, в свою очередь, входит в подобласть всех компьютеров Московского физико-технического института с именем mipt, которая включается в область ранга 1 всех компьютеров России с именем ru. Тогда имя рассматриваемого компьютера во Всемирной сети будет serv.crec.mipt.ru. Аналогичным образом можно именовать и подобласти, состоящие более чем из одного компьютера.
В каждой полученной именованной области, состоящей более чем из одного узла, выберем один из компьютеров и назначим его ответственным за эту область – сервером DNS. Сервер DNS знает числовые адреса серверов DNS для подобластей, входящих в его зону ответственности, или числовые адреса отдельных компьютеров, если такая подобласть включает в себя только один компьютер. Кроме того, он также знает числовой адрес сервера DNS, в зону ответственности которого входит рассматриваемая область (если это не область ранга 1), или числовые адреса всех серверов DNS ранга 1 (в противном случае). Отдельные компьютеры всегда знают числовые адреса серверов DNS, которые непосредственно за них отвечают.
Рассмотрим теперь, как процесс на компьютере serv.crec.mipt.ru может узнать числовой адрес компьютера ssp.brown.edu. Для этого он обращается к своему DNS-серверу, отвечающему за область crec.mipt.ru, и передает ему нужный адрес в символьном виде. Если этот DNS-сервер не может сразу представить необходимый числовой адрес, он передает запрос DNS-серверу, отвечающему за область mipt.ru. Если и тот не в силах самостоятельно справиться с проблемой, он перенаправляет запрос серверу DNS, отвечающему за область 1-го ранга ru.
Этот сервер может обратиться к серверу DNS, обслуживающему область 1-го ранга edu, который, наконец, затребует информацию от сервера DNS области brown.edu, где должен быть нужный числовой адрес. Полученный числовой адрес по всей цепи серверов DNS в обратном порядке будет передан процессу, направившему запрос (см. рис. 14.2).

Рис. 14.2. Пример разрешения имен с использованием DNS-серверов
В действительности, каждый сервер DNS имеет достаточно большой кэш, содержащий адреса серверов DNS для всех последних запросов. Поэтому реальная схема обычно существенно проще, из приведенной цепочки общения DNS-серверов выпадают многие звенья за счет обращения напрямую.
Рассмотренный способ разрешения адресов позволяет легко добавлять компьютеры в сеть и исключать их из сети, так как для этого необходимо внести изменения только на DNS-сервере соответствующей области.
Если DNS-сервер, отвечающий за какую-либо область, выйдет из строя, то может оказаться невозможным разрешение адресов для всех компьютеров этой области. Поэтому обычно назначается не один сервер DNS, а два – основной и запасной. В случае выхода из строя основного сервера его функции немедленно начинает выполнять запасной.
В реальных сетевых вычислительных системах обычно используется комбинация рассмотренных подходов. Для компьютеров, с которыми чаще всего приходится устанавливать связь, в специальном файле хранится таблица соответствий символьных и числовых адресов. Все остальные адреса разрешаются с использованием служб, аналогичных службе DNS. Способ построения удаленных адресов и методы разрешения адресов обычно определяются протоколами сетевого уровня эталонной модели.
Мы разобрались с проблемой удаленных адресов и знаем, как получить числовой удаленный адрес нужного нам компьютера. Давайте рассмотрим теперь проблему адресов локальных: как нам задать адрес процесса или объекта для хранения данных на удаленном компьютере, который в конечном итоге и должен получить переданную информацию.
Проблема состоит в том, что добавление или удаление компонента сети требует внесения изменений в файлы на всех сетевых машинах. Второй метод разрешения адресов заключается в частичном распределении информации о соответствии символьных и числовых адресов по многим комплексам сети, так что каждый из этих комплексов содержит лишь часть полных данных. Он же определяет и правила построения символических имен компьютеров.
Один из таких способов, используемый в Internet, получил английское наименование Domain Name Service или сокращенно DNS. Эта аббревиатура широко используется и в русскоязычной литературе. Давайте рассмотрим данный метод подробнее.
Организуем логически все компьютеры сети в некоторую древовидную структуру, напоминающую структуру директорий файловых систем, в которых отсутствует возможность организации жестких и мягких связей и нет пустых директорий. Будем рассматривать все компьютеры, входящие во Всемирную сеть, как область самого низкого ранга (аналог корневой директории в файловой системе) – ранга 0. Разобьем все множество компьютеров области на какое-то количество подобластей (domains). При этом некоторые подобласти будут состоять из одного компьютера (аналоги регулярных файлов в файловых системах), а некоторые – более чем из одного компьютера (аналоги директорий в файловых системах). Каждую подобласть будем рассматривать как область более высокого ранга. Присвоим подобластям собственные имена таким образом, чтобы в рамках разбиваемой области все они были уникальны. Повторим такое разбиение рекурсивно для каждой области более высокого ранга, которая состоит более чем из одного компьютера, несколько раз, пока при последнем разбиении в каждой подобласти не окажется ровно по одному компьютеру. Глубина рекурсии для различных областей одного ранга может быть разной, но обычно в целом ограничиваются 3 – 5 разбиениями, начиная от ранга 0.
В результате мы получим дерево, неименованной вершиной которого является область, объединяющая все компьютеры, входящие во Всемирную сеть, именованными терминальными узлами – отдельные компьютеры (точнее – подобласти, состоящие из отдельных компьютеров), а именованными нетерминальными узлами – области различных рангов.
Взаимодействие удаленных процессов как основа работы вычислительных сетей
Все перечисленные выше цели объединения компьютеров в вычислительные сети не могут быть достигнуты без организации взаимодействия процессов на различных вычислительных системах. Будь то доступ к разделяемым ресурсам или общение пользователей через сеть – в основе всего этого лежит взаимодействие удаленных процессов, т. е. процессов, которые находятся под управлением физически разных операционных систем. Поэтому мы в своей работе сосредоточимся именно на вопросах кооперации таких процессов, в первую очередь выделив ее отличия от кооперации процессов в одной автономной вычислительной системе (кооперации локальных процессов), о которой мы говорили в лекциях 4, 5 и 6.
Изучая взаимодействие локальных процессов, мы разделили средства обмена информацией по объему передаваемых между ними данных и возможности влияния на поведение другого процесса на три категории: сигнальные, канальные и разделяемая память. На самом деле во всей этой систематизации присутствовала некоторая доля лукавства. Мы фактически классифицировали средства связи по виду интерфейса обращения к ним, в то время как реальной физической основой для всех средств связи в том или ином виде являлось разделение памяти. Семафоры представляют собой просто целочисленные переменные, лежащие в разделяемой памяти, к которым посредством системных вызовов, определяющих состав и содержание допустимых операций над ними, могут обращаться различные процессы. Очереди сообщений и pip'ы базируются на буферах ядра операционной системы, которые опять-таки с помощью системных вызовов доступны различным процессам. Иного способа реально передать информацию от процесса к процессу в автономной вычислительной системе просто не существует. Взаимодействие удаленных процессов принципиально отличается от ранее рассмотренных случаев. Общей памяти у различных компьютеров физически нет. Удаленные процессы могут обмениваться информацией, только передавая друг другу пакеты данных определенного формата (в виде последовательностей электрических или электромагнитных сигналов, включая световые) через некоторый физический канал связи или несколько таких каналов, соединяющих компьютеры.
Поэтому в основе всех средств взаимодействия удаленных процессов лежит передача структурированных пакетов информации или сообщений.При взаимодействии локальных процессов и процесс–отправитель информации, и процесс-получатель функционируют под управлением одной и той же операционной системы. Эта же операционная система поддерживает и функционирование промежуточных накопителей данных при использовании непрямой адресации. Для организации взаимодействия процессы пользуются одними и теми же системными вызовами, присущими данной операционной системе, с одинаковыми интерфейсами. Более того, в автономной операционной системе передача информации от одного процесса к другому, независимо от используемого способа адресации, как правило (за исключением микроядерных операционных систем), происходит напрямую – без участия других процессов-посредников. Но даже и при наличии процессов-посредников все участники передачи информации находятся под управлением одной и той же операционной системы. При организации сети, конечно, можно обеспечить прямую связь между всеми вычислительными комплексами, соединив каждый из них со всеми остальными посредством прямых физических линий связи или подключив все комплексы к общей шине (по примеру шин данных и адреса в компьютере). Однако такая сетевая топология не всегда возможна по ряду физических и финансовых причин. Поэтому во многих случаях информация между удаленными процессами в сети передается не напрямую, а через ряд процессов-посредников, "обитающих" на вычислительных комплексах, не являющихся компьютерами отправителя и получателя и работающих под управлением собственных операционных систем. Однако и при отсутствии процессов-посредников удаленные процесс-отправитель и процесс-получатель функционируют под управлением различных операционных систем, часто имеющих принципиально разное строение.Вопросы надежности средств связи и способы ее реализации, рассмотренные нами в лекции 4, носили для случая локальных процессов скорее теоретический характер.
Мы выяснили, что физической основой "общения" процессов на автономной вычислительной машине является разделяемая память. Поэтому для локальных процессов надежность передачи информации определяется надежностью ее передачи по шине данных и хранения в памяти машины, а также корректностью работы операционной системы. Для хороших вычислительных комплексов и операционных систем мы могли забыть про возможную ненадежность средств связи. Для удаленных процессов вопросы, связанные с надежностью передачи данных, становятся куда более значимыми. Протяженные сетевые линии связи подвержены разнообразным физическим воздействиям, приводящим к искажению передаваемых по ним физических сигналов (помехи в эфире) или к полному отказу линий (мыши съели кабель). Даже при отсутствии внешних помех передаваемый сигнал затухает по мере удаления от точки отправления, приближаясь по интенсивности к внутренним шумам линий связи. Промежуточные вычислительные комплексы сети, участвующие в доставке информации, не застрахованы от повреждений или внезапной перезагрузки операционной системы. Поэтому вычислительные сети должны организовываться исходя из предпосылок ненадежности доставки физических пакетов информации.При организации взаимодействия локальных процессов каждый процесс (в случае прямой адресации) и каждый промежуточный объект для накопления данных (в случае непрямой адресации) должны были иметь уникальные идентификаторы – адреса – в рамках одной операционной системы. При организации взаимодействия удаленных процессов участники этого взаимодействия должны иметь уникальные адреса уже в рамках всей сети.Физическая линия связи, соединяющая несколько вычислительных комплексов, является разделяемым ресурсом для всех процессов комплексов, которые хотят ее использовать. Если два процесса попытаются одновременно передать пакеты информации по одной и той же линии, то в результате интерференции физических сигналов, представляющих эти пакеты, произойдет взаимное искажение передаваемых данных.Для того чтобы избежать возникновения такой ситуации (race condition!) и обеспечить эффективную совместную работу вычислительных систем, должны выполняться условия взаимоисключения, прогресса и ограниченного ожидания при использовании общей линии связи, но уже не на уровне отдельных процессов операционных систем, а на уровне различных вычислительных комплексов в целом.
Давайте теперь, абстрагировавшись от физического уровня организации связи и не обращая внимания на то, какие именно физические средства – оптическое волокно, коаксиальный кабель, спутниковая связь и т. д. – лежат в основе объединения компьютеров в сеть, обсудим влияние перечисленных отличий на логические принципы организации взаимодействия удаленных процессов.
в вычислительные сети являются потребности
Основными причинами объединения компьютеров в вычислительные сети являются потребности в разделении ресурсов, ускорении вычислений, повышении надежности и облегчении общения пользователей.
Вычислительные комплексы в сети могут находиться под управлением сетевых или распределенных вычислительных систем. Основой для объединения компьютеров в сеть служит взаимодействие удаленных процессов. При рассмотрении вопросов организации взаимодействия удаленных процессов нужно принимать во внимание основные отличия их кооперации от кооперации локальных процессов.
Базой для взаимодействия локальных процессов служит организация общей памяти, в то время как для удаленных процессов – это обмен физическими пакетами данных.
Организация взаимодействия удаленных процессов требует от сетевых частей операционных систем поддержки определенных протоколов. Сетевые средства связи обычно строятся по "слоеному" принципу. Формальный перечень правил, определяющих последовательность и формат сообщений, которыми обмениваются сетевые компоненты различных вычислительных систем, лежащие на одном уровне, называется сетевым протоколом. Каждый уровень слоеной системы может взаимодействовать непосредственно только со своими вертикальными соседями, руководствуясь четко закрепленными соглашениями – вертикальными протоколами или интерфейсами. Вся совокупность интерфейсов и сетевых протоколов в сетевых системах, построенных по слоеному принципу, достаточная для организации взаимодействия удаленных процессов, образует семейство протоколов или стек протоколов.
Удаленные процессы, в отличие от локальных, при взаимодействии обычно требуют двухуровневой адресации при своем общении. Полный адрес процесса состоит из двух частей: удаленной и локальной.
Для удаленной адресации используются символьные и числовые имена узлов сети. Перевод имен из одной формы в другую (разрешение имен) может осуществляться с помощью централизованно обновляемых таблиц соответствия полностью на каждом узле или с использованием выделения зон ответственности специальных серверов. Для локальной адресации процессов применяются порты. Упорядоченная пара из адреса узла в сети и порта получила название socket.
Для доставки сообщения от одного узла к другому могут использоваться различные протоколы маршрутизации.
С точки зрения пользовательских процессов обмен информацией может осуществляться в виде датаграмм или потока данных.
Формализация подхода к обеспечению информационной безопасности
Проблема информационной безопасности оказалась настолько важной, что в ряде стран были выпущены основополагающие документы, в которых регламентированы основные подходы к проблеме информационной безопасности. В результате оказалось возможным ранжировать информационные системы по степени надежности.
Наиболее известна оранжевая (по цвету обложки) книга Министерства обороны США [DoD, 1993]. В этом документе определяется четыре уровня безопасности – D, С, В и А. По мере перехода от уровня D до А к надежности систем предъявляются все более жесткие требования. Уровни С и В подразделяются на классы (C1, C2, В1, В2, ВЗ). Чтобы система в результате процедуры сертификации могла быть отнесена к некоторому классу, ее защита должна удовлетворять оговоренным требованиям.
В качестве примера рассмотрим требования класса C2, которому удовлетворяют ОС Windows NT, отдельные реализации Unix и ряд других.
Каждый пользователь должен быть идентифицирован уникальным входным именем и паролем для входа в систему. Доступ к компьютеру предоставляется лишь после аутентификации.Система должна быть в состоянии использовать эти уникальные идентификаторы, чтобы следить за действиями пользователя (управление избирательным доступом). Владелец ресурса (например, файла) должен иметь возможность контролировать доступ к этому ресурсу.Операционная система должна защищать объекты от повторного использования. Перед выделением новому пользователю все объекты, включая память и файлы, должны инициализироваться.Системный администратор должен иметь возможность вести учет всех событий, относящихся к безопасности.Система должна защищать себя от внешнего влияния или навязывания, такого как модификация загруженной системы или системных файлов, хранящихся на диске.
Сегодня на смену оранжевой книге пришел стандарт Common Criteria, а набор критериев Controlled Access Protection Profile сменил критерии класса C2.
Основополагающие документы содержат определения многих ключевых понятий, связанных с информационной безопасностью.
Некоторые из них (аутентификация, авторизация, домен безопасности и др.) будут рассмотрены в следующей лекции. В дальнейшем мы также будем оперировать понятиями "субъект" и "объект" безопасности. Субъект безопасности – активная системная составляющая, к которой применяется политика безопасности, а объект – пассивная. Примерами субъектов могут служить пользователи и группы пользователей, а объектов – файлы, системные таблицы, принтер и т. п.
По существу, проектирование системы безопасности подразумевает ответы на следующие вопросы: какую информацию защищать, какого рода атаки на безопасность системы могут быть предприняты, какие средства использовать для защиты каждого вида информации? Поиск ответов на данные вопросы называется формированием политики безопасности, которая помимо чисто технических аспектов включает также и решение организационных проблем. На практике реализация политики безопасности состоит в присвоении субъектам и объектам идентификаторов и фиксации набора правил, позволяющих определить, имеет ли данный субъект авторизацию, достаточную для предоставления к данному объекту указанного типа доступа.
Формируя политику безопасности, необходимо учитывать несколько базовых принципов. Так, Зальтцер (Saltzer) и Шредер (Schroeder) (1975) на основе своего опыта работы с MULTICS сформулировали следующие рекомендации для проектирования системы безопасности ОС.
Проектирование системы должно быть открытым. Hарушитель и так все знает (криптографические алгоритмы открыты).Не должно быть доступа по умолчанию. Ошибки с отклонением легитимного доступа будут обнаружены скорее, чем ошибки там, где разрешен неавторизованный доступ.Нужно тщательно проверять текущее авторство. Так, многие системы проверяют привилегии доступа при открытии файла и не делают этого после. В результате пользователь может открыть файл и держать его открытым в течение недели и иметь к нему доступ, хотя владелец уже сменил защиту.Давать каждому процессу минимум возможных привилегий.Защитные механизмы должны быть просты, постоянны и встроены в нижний слой системы, это не аддитивные добавки (известно много неудачных попыток "улучшения" защиты слабо приспособленной для этого ОС MS-DOS).Важна физиологическая приемлемость.Если пользователь видит, что защита требует слишком больших усилий, он от нее откажется. Ущерб от атаки и затраты на ее предотвращение должны быть сбалансированы.
Приведенные соображения показывают необходимость продумывания и встраивания защитных механизмов на самых ранних стадиях проектирования системы.
Криптография как одна из базовых технологий безопасности ОС
Многие службы информационной безопасности, такие как контроль входа в систему, разграничение доступа к ресурсам, обеспечение безопасного хранения данных и ряд других, опираются на использование криптографических алгоритмов. Имеется обширная литература по этому актуальному для безопасности информационных систем вопросу.
Шифрование – процесс преобразования сообщения из открытого текста (plaintext) в шифротекст (ciphertext) таким образом, чтобы:
его могли прочитать только те стороны, для которых оно предназначено;проверить подлинность отправителя (аутентификация);гарантировать, что отправитель действительно послал данное сообщение.
В алгоритмах шифрования предусматривается наличие ключа. Ключ – это некий параметр, не зависящий от открытого текста. Результат применения алгоритма шифрования зависит от используемого ключа. В криптографии принято правило Кирхгофа: "Стойкость шифра должна определяться только секретностью ключа". Правило Кирхгофа подразумевает, что алгоритмы шифрования должны быть открыты.
В методе шифрования с секретным или симметричным ключом имеется один ключ, который используется как для шифрования, так и для расшифровки сообщения. Такой ключ нужно хранить в секрете. Это затрудняет использование системы шифрования, поскольку ключи должны регулярно меняться, для чего требуется их секретное распространение. Наиболее популярные алгоритмы шифрования с секретным ключом: DES, TripleDES, ГОСТ и ряд других.
Часто используется шифрование с помощью односторонней функции, называемой также хеш- или дайджест-функцией. Применение этой функции к шифруемым данным позволяет сформировать небольшой дайджест из нескольких байтов, по которому невозможно восстановить исходный текст. Получатель сообщения может проверить целостность данных, сравнивая полученный вместе с сообщением дайджест с вычисленным вновь при помощи той же односторонней функции. Эта техника активно используется для контроля входа в систему. Например, пароли пользователей хранятся на диске в зашифрованном односторонней функцией виде.
Наиболее популярные хеш-функции: MD4, MD5 и др.
В системах шифрования с открытым или асимметричным ключом (public/ assymmetric key) используется два ключа (см. рис. 15.1). Один из ключей, называемый открытым, несекретным, используется для шифрования сообщений, которые могут быть расшифрованы только с помощью секретного ключа, имеющегося у получателя, для которого предназначено сообщение. Иногда поступают по-другому. Для шифрования сообщения используется секретный ключ, и если сообщение можно расшифровать с помощью открытого ключа, подлинность отправителя будет гарантирована (система электронной подписи). Этот принцип изобретен Уитфилдом Диффи (Whitfield Diffie) и Мартином Хеллманом (Martin Hellman) в 1976 г.
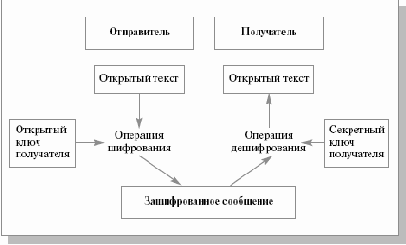
Рис. 15.1. Шифрование открытым ключом
Использование открытых ключей снимает проблему обмена и хранения ключей, свойственную системам с симметричными ключами. Открытые ключи могут храниться публично, и каждый может послать зашифрованное открытым ключом сообщение владельцу ключа. Однако расшифровать это сообщение может только владелец открытого ключа при помощи своего секретного ключа, и никто другой. Несмотря на очевидные удобства, связанные с хранением и распространением ключей, асимметричные алгоритмы гораздо менее эффективны, чем симметричные, поэтому во многих криптографических системах используются оба метода.
Среди несимметричных алгоритмов наиболее известен RSA, предложенный Роном Ривестом (Ron Rivest), Ади Шамиром (Adi Shamir) и Леонардом Эдлманом (Leonard Adleman). Рассмотрим его более подробно.
Шифрование с использованием алгоритма RSA
Идея, положенная в основу метода, состоит в том, чтобы найти такую функцию y=?(x), для которой получение обратной функции x=f-1(y) было бы в общем случае очень сложной задачей (NP-полной задачей). Например, получить произведение двух чисел n=p?q просто, а разложить n на множители, если p и q достаточно большие простые числа, – NP-полная задача с вычислительной сложностью ~ n10. Однако если знать некую секретную информацию, то найти обратную функцию x=f-1(y) существенно проще. Такие функции также называют односторонними функциями с лазейкой или потайным ходом.
Применяемые в RSA прямая и обратная функции просты. Они базируются на применении теоремы Эйлера из теории чисел.
Прежде чем сформулировать теорему Эйлера, необходимо определить важную функцию ?(n) из теории чисел, называемую функцией Эйлера. Это число взаимно простых (взаимно простыми называются целые числа, не имеющие общих делителей) с n целых чисел, меньших n. Например, ?(7)=6. Очевидно, что, если p и q – простые числа и p

Теорема Эйлера
Теорема Эйлера утверждает, что для любых взаимно простых чисел x и n (x < n)
x?(n)mod n = 1
или в более общем виде
xk?(n)+1mod n = 1
Сформулируем еще один важный результат. Для любого m>0 и 0<e<m, где e и m взаимно просты, найдется единственное 0<d<m, такое, что
de mod m = 1.
Здесь d легко можно найти по обобщенному алгоритму Евклида (см., например, Д. Кнут. Искусство программирования на ЭВМ, т.2, 4.5.2). Известно, что вычислительная сложность алгоритма Евклида ~ ln n.
Подставляя ?(n) вместо m, получим de mod?(n)=1
или
de = k?(n)+1
Тогда прямой функцией будет
?(x) = xe mod n
где x – положительное целое, x<n=pq, p и q – целые простые числа и, следовательно,
?(n)=(p-1)(q-1)
где e – положительное целое и e<?(n). Здесь e и n открыты. Однако p и q неизвестны (чтобы их найти, нужно выполнить разбиение n на множители), следовательно, неизвестна и ?(n), а именно они и составляют потайной ход.
Вычислим обратную функцию
?-1(y) = yd mod n = xed mod n = xk?(n)+1 mod n = x
Последнее преобразование справедливо, поскольку x<n и x и n взаимно просты.
При практическом использовании алгоритма RSA вначале необходимо выполнить генерацию ключей. Для этого нужно:
Выбрать два очень больших простых числа p и q;Вычислить произведение n=p?q;Выбрать большое случайное число d, не имеющее общих сомножителей с числом (p-1)?(q-1);Определить число e, чтобы выполнялось
(e?d)mod((p-1)?(q-1))=1.
Тогда открытым ключом будут числа e и n, а секретным ключом – числа d и n.
Теперь, чтобы зашифровать данные по известному ключу {e,n}, необходимо сделать следующее.
Разбить шифруемый текст на блоки, где i-й блок представить в виде числа M, величина которого меньше, чем n. Это можно сделать различными способами, например используя вместо букв их номера в алфавите.Зашифровать текст, рассматриваемый как последовательность чисел m(i), по формуле c(i)=(m(i)e)mod n.
Чтобы расшифровать эти данные, используя секретный ключ {d,n}, необходимо вычислить: m(i) = (c(i)d) mod n. В результате будет получено множество чисел m(i), которые представляют собой часть исходного текста.
Например, зашифруем и расшифруем сообщение "AБВ", которое представим как число 123.
Выбираем p=5 и q=11 (числа на самом деле должны быть большими).
Находим n=5?11=55.
Определяем (p-1)?(q-1)=40. Тогда d будет равно, например, 7.
Выберем e, исходя из (e?7) mod 40=1. Например, e=3.
Теперь зашифруем сообщение, используя открытый ключ {3,55}
C1 = (13) mod 55 = 1 C2 = (23) mod 55 = 8 C3 = (33) mod 55 = 27
Теперь расшифруем эти данные, используя закрытый ключ {7,55}.
M1 = (17) mod 55 = 1 M2 = (87) mod 55 = 2097152 mod 55 = 2 M3 = (277) mod 55 = 10460353203 mod 55 = 3
Таким образом, все данные расшифрованы.
Угрозы безопасности
Знание возможных угроз, а также уязвимых мест защиты, которые эти угрозы обычно эксплуатируют, необходимо для того, чтобы выбирать наиболее экономичные средства обеспечения безопасности.
Считается, что безопасная система должна обладать свойствами конфиденциальности, доступности и целостности. Любое потенциальное действие, которое направлено на нарушение конфиденциальности, целостности и доступности информации, называется угрозой. Реализованная угроза называется атакой.
Конфиденциальная (confidentiality) система обеспечивает уверенность в том, что секретные данные будут доступны только тем пользователям, которым этот доступ разрешен (такие пользователи называются авторизованными). Под доступностью (availability) понимают гарантию того, что авторизованным пользователям всегда будет доступна информация, которая им необходима. И наконец, целостность (integrity) системы подразумевает, что неавторизованные пользователи не могут каким-либо образом модифицировать данные.
Защита информации ориентирована на борьбу с так называемыми умышленными угрозами, то есть с теми, которые, в отличие от случайных угроз (ошибок пользователя, сбоев оборудования и др.), преследуют цель нанести ущерб пользователям ОС.
Умышленные угрозы подразделяются на активные и пассивные. Пассивная
угроза – несанкционированный доступ к информации без изменения состояния системы, активная – несанкционированное изменение системы. Пассивные атаки труднее выявить, так как они не влекут за собой никаких изменений данных. Защита против пассивных атак базируется на средствах их предотвращения.
Можно выделить несколько типов угроз. Наиболее распространенная угроза – попытка проникновения в систему под видом легального пользователя, например попытки угадывания и подбора паролей. Более сложный вариант – внедрение в систему программы, которая выводит на экран слово login. Многие легальные пользователи при этом начинают пытаться входить в систему, и их попытки могут протоколироваться. Такие безобидные с виду программы, выполняющие нежелательные функции, называются "троянскими конями".
Иногда удается торпедировать работу программы проверки пароля путем многократного нажатия клавиш del, break, cancel и т. д. Для защиты от подобных атак ОС запускает процесс, называемый аутентификацией пользователя (см. лекцию 16, раздел "Идентификация и аутентификация").
Угрозы другого рода связаны с нежелательными действиями легальных пользователей, которые могут, например, предпринимать попытки чтения страниц памяти, дисков и лент, которые сохранили информацию, связанную с предыдущим использованием. Защита в таких случаях базируется на надежной системе авторизации (см. лекцию 16, раздел "Авторизация. Разграничение доступа к объектам ОС"). В эту категорию также попадают атаки типа отказ в обслуживании, когда сервер затоплен мощным потоком запросов и становится фактически недоступным для отдельных авторизованных пользователей.
Наконец, функционирование системы может быть нарушено с помощью программ-вирусов или программ-"червей", которые специально предназначены для того, чтобы причинить вред или недолжным образом использовать ресурсы компьютера. Общее название угроз такого рода – вредоносные программы (malicious software). Обычно они распространяются сами по себе, переходя на другие компьютеры через зараженные файлы, дискеты или по электронной почте. Наиболее эффективный способ борьбы с подобными программами – соблюдение правил "компьютерной гигиены". Многопользовательские компьютеры меньше страдают от вирусов по сравнению с персональными, поскольку там имеются системные средства защиты.
Таковы основные угрозы, на долю которых приходится львиная доля ущерба, наносимого информационным системам.
В ряде монографий [Столлингс, 2001; Таненбаум, 2002] также рассматривается модель злоумышленника, поскольку очевидно, что необходимые для организации защиты усилия зависят от предполагаемого противника. Обеспечение безопасности имеет и правовые аспекты, но это уже выходит за рамки данного курса.
в США произошло событие, названное
В октябре 1988 г. в США произошло событие, названное специалистами крупнейшим нарушением безопасности амеpиканских компьютеpных систем из когда-либо случавшихся. 23-летний студент выпускного куpса Коpнельского унивеpситета Робеpт Т. Моppис запустил в компьютеpной сети ARPANET пpогpамму, пpедставлявшую собой pедко встpечающуюся pазновидность компьютеpных виpусов – сетевых "чеpвей". В pезультате атаки был полностью или частично заблокиpован pяд общенациональных компьютеpных сетей, в частности Internet, CSnet, NSFnet, BITnet, ARPANET и несекpетная военная сеть Milnet. В итоге виpус поpазил более 6200 компьютеpных систем по всей Амеpике, включая системы многих кpупнейших унивеpситетов, институтов, пpавительственных лабоpатоpий, частных фиpм, военных баз, клиник, агентства NASA. Общий ущеpб от этой атаки оценивается специалистами минимум в 100 млн. долл. Р. Моppис был исключен из унивеpситета с пpавом повтоpного поступления чеpез год и пpиговоpен судом к штpафу в 270 тыс. долл. и тpем месяцам тюpемного заключения.
Важность решения проблемы информационной безопасности в настоящее время общепризнана, подтверждением чему служат громкие процессы о нарушении целостности систем. Убытки ведущих компаний в связи с нарушениями безопасности информации составляют триллионы долларов, причем только треть опрошенных компаний смогли определить количественно размер потерь. Проблема обеспечения безопасности носит комплексный характер, для ее решения необходимо сочетание законодательных, организационных и программно-технических мер.
Таким образом, обеспечение информационной безопасности требует системного подхода и нужно использовать разные средства и приемы – морально-этические, законодательные, административные и технические. Нас будут интересовать последние. Технические средства реализуются программным и аппаратным обеспечением и решают разные задачи по защите, они могут быть встроены в операционные системы либо могут быть реализованы в виде отдельных продуктов. Во многих случаях центр тяжести смещается в сторону защищенности операционных систем.
Есть несколько причин для реализации дополнительных средств защиты. Hаиболее очевидная – помешать внешним попыткам нарушить доступ к конфиденциальной информации. Не менее важно, однако, гарантировать, что каждый программный компонент в системе использует системные ресурсы только способом, совместимым с установленной политикой применения этих ресурсов. Такие требования абсолютно необходимы для надежной системы. Кроме того, наличие защитных механизмов может увеличить надежность системы в целом за счет обнаружения скрытых ошибок интерфейса между компонентами системы. Раннее обнаружение ошибок может предотвратить "заражение" неисправной подсистемой остальных.
Политика в отношении ресурсов может меняться в зависимости от приложения и с течением времени. Операционная система должна обеспечивать прикладные программы инструментами для создания и поддержки защищенных ресурсов. Здесь реализуется важный для гибкости сиcтемы принцип – отделение политики от механизмов. Механизмы определяют, как может быть сделано что-либо, тогда как политика решает, что должно быть сделано. Политика может меняться в зависимости от места и времени. Желательно, чтобы были реализованы по возможности общие механизмы, тогда как изменение политики требует лишь модификации системных параметров или таблиц.
К сожалению, построение защищенной системы предполагает необходимость склонить пользователя к отказу от некоторых интересных возможностей. Например, письмо, содержащее в качестве приложения документ в формате Word, может включать макросы. Открытие такого письма влечет за собой запуск чужой программы, что потенциально опасно. То же самое можно сказать про Web-страницы, содержащие апплеты. Вместо критического отношения к использованию такой функциональности пользователи современных компьютеров предпочитают периодически запускать антивирусные программы и читать успокаивающие статьи о безопасности Java.
к числу дисциплин, развивающихся чрезвычайно
Информационная безопасность относится к числу дисциплин, развивающихся чрезвычайно быстрыми темпами. Только комплексный, систематический, современный подход способен успешно противостоять нарастающим угрозам.
Ключевые понятия информационной безопасности: конфиденциальность, целостность и доступность информации, а любое действие, направленное на их нарушение, называется угрозой.
Основные понятия информационной безопасности регламентированы в основополагающих документах.
Существует несколько базовых технологий безопасности, среди которых можно выделить криптографию.
Анализ некоторых популярных ОС с точки зрения их защищенности
Итак, ОС должна способствовать реализации мер безопасности или непосредственно поддерживать их. Примерами подобных решений в рамках аппаратуры и операционной системы могут быть:
разделение команд по уровням привилегированности;сегментация адресного пространства процессов и организация защиты сегментов;защита различных процессов от взаимного влияния за счет выделения каждому своего виртуального пространства;особая защита ядра ОС;контроль повторного использования объекта;наличие средств управления доступом;структурированность системы, явное выделение надежной вычислительной базы (совокупности защищенных компонентов), обеспечение компактности этой базы;следование принципу минимизации привилегий - каждому компоненту дается ровно столько привилегий, сколько необходимо для выполнения им своих функций.
Большое значение имеет структура файловой системы. Hапример, в ОС с дискреционным контролем доступа каждый файл должен храниться вместе с дискреционным списком прав доступа к нему, а, например, при копировании файла все атрибуты, в том числе и ACL, должны быть автоматически скопированы вместе с телом файла.
В принципе, меры безопасности не обязательно должны быть заранее встроены в ОС - достаточно принципиальной возможности дополнительной установки защитных продуктов. Так, сугубо ненадежная система MS-DOS может быть усовершенствована за счет средств проверки паролей доступа к компьютеру и/или жесткому диску, за счет борьбы с вирусами путем отслеживания попыток записи в загрузочный сектор CMOS-средствами и т. п. Тем не менее по-настоящему надежная система должна изначально проектироваться с акцентом на механизмы безопасности.
Авторизация. Разграничение доступа к объектам ОС
После успешной регистрации система должна осуществлять авторизацию (authorization) - предоставление субъекту прав на доступ к объекту. Средства авторизации контролируют доступ легальных пользователей к ресурсам системы, предоставляя каждому из них именно те права, которые были определены администратором, а также осуществляют контроль возможности выполнения пользователем различных системных функций. Система контроля базируется на общей модели, называемой матрицей доступа. Рассмотрим ее более подробно.
Как уже говорилось в предыдущей лекции, компьютерная система может быть смоделирована как набор субъектов (процессы, пользователи) и объектов. Под объектами мы понимаем как ресурсы оборудования (процессор, сегменты памяти, принтер, диски и ленты), так и программные ресурсы (файлы, программы, семафоры), то есть все то, доступ к чему контролируется. Каждый объект имеет уникальное имя, отличающее его от других объектов в системе, и каждый из них может быть доступен через хорошо определенные и значимые операции.
Операции зависят от объектов. Hапример, процессор может только выполнять команды, сегменты памяти могут быть записаны и прочитаны, считыватель магнитных карт может только читать, а файлы данных могут быть записаны, прочитаны, переименованы и т. д.
Желательно добиться того, чтобы процесс осуществлял авторизованный доступ только к тем ресурсам, которые ему нужны для выполнения его задачи. Это требование минимума привилегий, уже упомянутое в предыдущей лекции, полезно с точки зрения ограничения количества повреждений, которые процесс может нанести системе. Hапример, когда процесс P вызывает процедуру А, ей должен быть разрешен доступ только к переменным и формальным параметрам, переданным ей, она не должна иметь возможность влиять на другие переменные процесса. Аналогично компилятор не должен оказывать влияния на произвольные файлы, а только на их хорошо определенное подмножество (исходные файлы, листинги и др.), имеющее отношение к компиляции. С другой стороны, компилятор может иметь личные файлы, используемые для оптимизационных целей, к которым процесс Р не имеет доступа.
Различают дискреционный (избирательный) способ управления доступом и полномочный (мандатный).
При дискреционном доступе, подробно рассмотренном ниже, определенные операции над конкретным ресурсом запрещаются или разрешаются субъектам или группам субъектов. С концептуальной точки зрения текущее состояние прав доступа при дискреционном управлении описывается матрицей, в строках которой перечислены субъекты, в столбцах - объекты, а в ячейках - операции, которые субъект может выполнить над объектом.
Полномочный подход заключается в том, что все объекты могут иметь уровни секретности, а все субъекты делятся на группы, образующие иерархию в соответствии с уровнем допуска к информации. Иногда это называют моделью многоуровневой безопасности, которая должна обеспечивать выполнение следующих правил.
Простое свойство секретности. Субъект может читать информацию только из объекта, уровень секретности которого не выше уровня секретности субъекта. Генерал читает документы лейтенанта, но не наоборот.*-свойство. Субъект может записывать информацию в объекты только своего уровня или более высоких уровней секретности. Генерал не может случайно разгласить нижним чинам секретную информацию.
Некоторые авторы утверждают [Таненбаум, 2002], что последнее требование называют *-свойством, потому что в оригинальном докладе не смогли придумать для него подходящего названия. В итоге во все последующие документы и монографии оно вошло как *-свойство.
Отметим, что данная модель разработана для хранения секретов, но не гарантирует целостности данных. Например, здесь лейтенант имеет право писать в файлы генерала. Более подробно о реализации подобных формальных моделей рассказано в [Столлингс, 2002], [Таненбаум, 2002].
Большинство операционных систем реализуют именно дискреционное управление доступом. Главное его достоинство - гибкость, основные недостатки - рассредоточенность управления и сложность централизованного контроля.
Домены безопасности
Чтобы рассмотреть схему дискреционного доступа более детально, введем концепцию домена безопасности (protection domain). Каждый домен определяет набор объектов и типов операций, которые могут производиться над каждым объектом. Возможность выполнять операции над объектом есть права доступа, каждое из которых есть упорядоченная пара <object-name, rights-set>. Домен, таким образом, есть набор прав доступа. Hапример, если домен D имеет права доступа <file F, {read, write}>, это означает, что процесс, выполняемый в домене D, может читать или писать в файл F, но не может выполнять других операций над этим объектом. Пример доменов можно увидеть на рис.16.1.

Рис. 16.1. Специфицирование прав доступа к ресурсам
Связь конкретных субъектов, функционирующих в операционных системах, может быть организована следующим образом.
Каждый пользователь может быть доменом. В этом случае набор объектов, к которым может быть организован доступ, зависит от идентификации пользователя.Каждый процесс может быть доменом. В этом случае набор доступных объектов определяется идентификацией процесса.Каждая процедура может быть доменом. В этом случае набор доступных объектов соответствует локальным переменным, определенным внутри процедуры. Заметим, что когда процедура выполнена, происходит смена домена.
Рассмотрим стандартную двухрежимную модель выполнения ОС. Когда процесс выполняется в режиме системы (kernel mode), он может выполнять привилегированные инструкции и иметь полный контроль над компьютерной системой. С другой стороны, если процесс выполняется в пользовательском режиме, он может вызывать только непривилегированные инструкции. Следовательно, он может выполняться только внутри предопределенного пространства памяти. Наличие этих двух режимов позволяет защитить ОС (kernel domain) от пользовательских процессов (выполняющихся в user domain). В мультипрограммных системах двух доменов недостаточно, так как появляется необходимость защиты пользователей друг от друга. Поэтому требуется более тщательно разработанная схема.
В ОС Unix домен связан с пользователем. Каждый пользователь обычно работает со своим набором объектов.
Другие способы контроля доступа
Иногда применяется комбинированный способ. Например, в том же Unix на этапе открытия файла происходит анализ ACL (операция open). В случае благоприятного исхода файл заносится в список открытых процессом файлов, и при последующих операциях чтения и записи проверки прав доступа не происходит. Список открытых файлов можно рассматривать как перечень возможностей.
Существует также схема lock-key, которая является компромиссом между списками прав доступа и перечнями возможностей. В этой схеме каждый объект имеет список уникальных битовых шаблонов (patterns), называемых locks. Аналогично каждый домен имеет список уникальных битовых шаблонов, называемых ключами (keys). Процесс, выполняющийся в домене, может получить доступ к объекту, только если домен имеет ключ, который соответствует одному из шаблонов объекта.
Как и в случае мандатов, список ключей для домена должен управляться ОС. Пользователям не разрешается проверять или модифицировать списки ключей (или шаблонов) непосредственно. Более подробно данная схема изложена в [Silberschatz, 2002].
Идентификация и аутентификация
Для начала рассмотрим проблему контроля доступа в систему. Наиболее распространенным способом контроля доступа является процедура регистрации. Обычно каждый пользователь в системе имеет уникальный идентификатор. Идентификаторы пользователей применяются с той же целью, что и идентификаторы любых других объектов, файлов, процессов. Идентификация заключается в сообщении пользователем своего идентификатора. Для того чтобы установить, что пользователь именно тот, за кого себя выдает, то есть что именно ему принадлежит введенный идентификатор, в информационных системах предусмотрена процедура аутентификации (authentication, опознавание, в переводе с латинского означает "установление подлинности"), задача которой - предотвращение доступа к системе нежелательных лиц.
Обычно аутентификация базируется на одном или более из трех пунктов:
то, чем пользователь владеет (ключ или магнитная карта);то, что пользователь знает (пароль);атрибуты пользователя (отпечатки пальцев, подпись, голос).
Мандаты возможностей. Capability list
Как отмечалось выше, если матрицу доступа хранить по строкам, то есть если каждый субъект хранит список объектов и для каждого объекта - список допустимых операций, то такой способ хранения называется "мандаты" или "перечни возможностей" (capability list). Каждый пользователь обладает несколькими мандатами и может иметь право передавать их другим. Мандаты могут быть рассеяны по системе и вследствие этого представлять большую угрозу для безопасности, чем списки контроля доступа. Их хранение должно быть тщательно продумано.
Примерами систем, использующих перечни возможностей, являются Hydra, Cambridge CAP System [Denning, 1996].
Матрица доступа
Модель безопасности, специфицированная в предыдущем разделе (см. рис. 16.1), имеет вид матрицы, которая называется матрицей доступа. Какова может быть эффективная реализация матрицы доступа? В общем случае она будет разреженной, то есть большинство ее клеток будут пустыми. Хотя существуют структуры данных для представления разреженной матрицы, они не слишком полезны для приложений, использующих возможности защиты. Поэтому на практике матрица доступа применяется редко. Эту матрицу можно разложить по столбцам, в результате чего получаются списки прав доступа (access control list - ACL). В результате разложения по строкам получаются мандаты возможностей (capability list или capability tickets).
MS-DOS
ОС MS-DOS функционирует в реальном режиме (real-mode) процессора i80x86. В ней невозможно выполнение требования, касающегося изоляции программных модулей (отсутствует аппаратная защита памяти). Уязвимым местом для защиты является также файловая система FAT, не предполагающая у файлов наличия атрибутов, связанных с разграничением доступа к ним. Таким образом, MS-DOS находится на самом нижнем уровне в иерархии защищенных ОС.
Недопустимость повторного использования объектов
Контроль повторного использования объекта предназначен для предотвращения попыток незаконного получения конфиденциальной информации, остатки которой могли сохраниться в некоторых объектах, ранее использовавшихся и освобожденных другим пользователем. Безопасность повторного применения должна гарантироваться для областей оперативной памяти (в частности, для буферов с образами экрана, расшифрованными паролями и т. п.), для дисковых блоков и магнитных носителей в целом. Очистка должна производиться путем записи маскирующей информации в объект при его освобождении (перераспределении). Hапример, для дисков на практике применяется способ двойной перезаписи освободившихся после удаления файлов блоков случайной битовой последовательностью.
NetWare, IntranetWare
Замечание об отсутствии изоляции модулей друг от друга справедливо и в отношении рабочей станции NetWare. Однако NetWare - сетевая ОС, поэтому к ней возможно применение и иных критериев. Это на данный момент единственная сетевая ОС, сертифицированная по классу C2 (следующей, по-видимому, будет Windows 2000). При этом важно изолировать наиболее уязвимый участок системы безопасности NetWare - консоль сервера, и тогда следование определенной практике поможет увеличить степень защищенности данной сетевой операционной системы. Возможность создания безопасных систем обусловлена тем, что число работающих приложений фиксировано и пользователь не имеет возможности запуска своих приложений.
процессора i80x86. Изоляция программных модулей
OS/2 работает в защищенном режиме (protected-mode) процессора i80x86. Изоляция программных модулей реализуется при помощи встроенных в этот процессор механизмов защиты памяти. Поэтому она свободна от указанного выше коренного недостатка систем типа MS-DOS. Но OS/2 была спроектирована и разработана без учета требований по защите от несанкционированного доступа. Это сказывается прежде всего на файловой системе. В файловых системах OS/2 HPFS (high performance file system) и FAT нет места ACL. Кроме того, пользовательские программы имеют возможность запрета прерываний. Следовательно, сертификация OS/2 на соответствие какому-то классу защиты не представляется возможной.
Считается, что такие операционные системы, как MS-DOS, Mac OS, Windows, OS/2, имеют уровень защищенности D (по оранжевой книге). Но, если быть точным, нельзя считать эти ОС даже системами уровня безопасности D, ведь они никогда не представлялись на тестирование.
Пароли, уязвимость паролей
Наиболее простой подход к аутентификации - применение пользовательского пароля.
Когда пользователь идентифицирует себя при помощи уникального идентификатора или имени, у него запрашивается пароль. Если пароль, сообщенный пользователем, совпадает с паролем, хранящимся в системе, система предполагает, что пользователь легитимен. Пароли часто используются для защиты объектов в компьютерной системе в отсутствие более сложных схем защиты.
Недостатки паролей связаны с тем, что трудно сохранить баланс между удобством пароля для пользователя и его надежностью. Пароли могут быть угаданы, случайно показаны или нелегально переданы авторизованным пользователем неавторизованному.
Есть два общих способа угадать пароль. Один связан со сбором информации о пользователе. Люди обычно используют в качестве паролей очевидную информацию (скажем, имена животных или номерные знаки автомобилей). Для иллюстрации важности разумной политики назначения идентификаторов и паролей можно привести данные исследований, проведенных в AT&T, показывающие, что из 500 попыток несанкционированного доступа около 300 составляют попытки угадывания паролей или беспарольного входа по пользовательским именам guest, demo и т. д.
Другой способ - попытаться перебрать все наиболее вероятные комбинации букв, чисел и знаков пунктуации (атака по словарю). Например, четыре десятичные цифры дают только 10 000 вариантов, более длинные пароли, введенные с учетом регистра символов и пунктуации, не столь уязвимы, но тем не менее таким способом удается разгадать до 25% паролей. Чтобы заставить пользователя выбрать трудноугадываемый пароль, во многих системах внедрена реактивная проверка паролей, которая при помощи собственной программы-взломщика паролей может оценить качество пароля, введенного пользователем.
Несмотря на все это, пароли распространены, поскольку они удобны и легко реализуемы.
Шифрование пароля
Для хранения секретного списка паролей на диске во многих ОС используется криптография. Система задействует одностороннюю функцию, которую просто вычислить, но для которой чрезвычайно трудно (разработчики надеются, что невозможно) подобрать обратную функцию.
Например, в ряде версий Unix в качестве односторонней функции используется модифицированный вариант алгоритма DES. Введенный пароль длиной до 8 знаков преобразуется в 56-битовое значение, которое служит входным параметром для процедуры crypt(), основанной на этом алгоритме. Результат шифрования зависит не только от введенного пароля, но и от случайной последовательности битов, называемой привязкой (переменная salt). Это сделано для того, чтобы решить проблему совпадающих паролей. Очевидно, что саму привязку после шифрования необходимо сохранять, иначе процесс не удастся повторить. Модифицированный алгоритм DES выполняется, имея входное значение в виде 64-битового блока нулей, с использованием пароля в качестве ключа, а на каждой следующей итерации входным параметром служит результат предыдущей итерации. Всего процедура повторяется 25 раз. Полученное 64-битовое значение преобразуется в 11 символов и хранится рядом с открытой переменной salt.
В ОС Windows NT преобразование исходного пароля также осуществляется многократным применением алгоритма DES и алгоритма MD4.
Хранятся только кодированные пароли. В процессе аутентификации представленный пользователем пароль кодируется и сравнивается с хранящимися на диске. Таким образом, файл паролей нет необходимости держать в секрете.
При удаленном доступе к ОС нежелательна передача пароля по сети в открытом виде. Одним из типовых решений является использование криптографических протоколов. В качестве примера можно рассмотреть протокол опознавания с подтверждением установления связи путем вызова - CHAP (Challenge Handshake Authentication Protocol).
Опознавание достигается за счет проверки того, что у пользователя, осуществляющего доступ к серверу, имеется секретный пароль, который уже известен серверу.
Пользователь инициирует диалог, передавая серверу свой идентификатор. В ответ сервер посылает пользователю запрос (вызов), состоящий из идентифицирующего кода, случайного числа и имени узла сервера или имени пользователя. При этом пользовательское оборудование в результате запроса пароля пользователя отвечает следующим ответом, зашифрованным с помощью алгоритма одностороннего хеширования, наиболее распространенным видом которого является MD5. После получения ответа сервер при помощи той же функции с теми же аргументами шифрует собственную версию пароля пользователя. В случае совпадения результатов вход в систему разрешается. Существенно, что незашифрованный пароль при этом по каналу связи не посылается.
В микротелефонных трубках используется аналогичный метод.
В системах, работающих с большим количеством пользователей, когда хранение всех паролей затруднительно, применяются для опознавания сертификаты, выданные доверенной стороной (см., например, [Столлингс, 2001]).
Смена домена
В большинстве ОС для определения домена применяются идентификаторы пользователей. Обычно переключение между доменами происходит, когда меняется пользователь. Но почти все системы нуждаются в дополнительных механизмах смены домена, которые используются, когда некая привилегированная возможность необходима большому количеству пользователей. Hапример, может понадобиться разрешить пользователям иметь доступ к сети, не заставляя их писать собственные сетевые программы. В таких случаях для процессов ОС Unix предусмотрена установка бита set-uid. В результате установки этого бита в сетевой программе она получает привилегии ее создателя (а не пользователя), заставляя домен меняться на время ее выполнения. Таким образом, рядовой пользователь может получить нужные привилегии для доступа к сети.
Список прав доступа. Access control list
Каждая колонка в матрице может быть реализована как список доступа для одного объекта. Очевидно, что пустые клетки могут не учитываться. В результате для каждого объекта имеем список упорядоченных пар <domain, rights-set>, который определяет все домены с непустыми наборами прав для данного объекта.
Элементами списка могут быть процессы, пользователи или группы пользователей. При реализации широко применяется предоставление доступа по умолчанию для пользователей, права которых не указаны. Например, в Unix все субъекты-пользователи разделены на три группы (владелец, группа и остальные), и для членов каждой группы контролируются операции чтения, записи и исполнения (rwx). В итоге имеем ACL - 9-битный код, который является атрибутом разнообразных объектов Unix.
Unix
Рост популярности Unix и все большая осведомленность о проблемах безопасности привели к осознанию необходимости достичь приемлемого уровня безопасности ОС, сохранив при этом мобильность, гибкость и открытость программных продуктов. В Unix есть несколько уязвимых с точки зрения безопасности мест, хорошо известных опытным пользователям, вытекающих из самой природы Unix (см., например, раздел "Типичные объекты атаки хакеров" в книге [Дунаев, 1996]). Однако хорошее системное администрирование может ограничить эту уязвимость.
Относительно защищенности Unix сведения противоречивы. В Unix изначально были заложены идентификация пользователей и разграничение доступа. Как оказалось, средства защиты данных в Unix могут быть доработаны, и сегодня можно утверждать, что многие клоны Unix по всем параметрам соответствуют классу безопасности C2.
Обычно, говоря о защищенности Unix, рассматривают защищенность автоматизированных систем, одним из компонентов которых является Unix-сервер. Безопасность такой системы увязывается с защитой глобальных и локальных сетей, безопасностью удаленных сервисов типа telnet и rlogin/rsh и аутентификацией в сетевой конфигурации, безопасностью X Window-приложений. Hа системном уровне важно наличие средств идентификации и аудита.
В Unix существует список именованных пользователей, в соответствии с которым может быть построена система разграничения доступа.
В ОС Unix считается, что информация, нуждающаяся в защите, находится главным образом в файлах.
По отношению к конкретному файлу все пользователи делятся на три категории:
владелец файла;члены группы владельца;прочие пользователи.
Для каждой из этих категорий режим доступа определяет права на операции с файлом, а именно:
право на чтение;право на запись;право на выполнение (для каталогов - право на поиск).
В итоге девяти (3х3) битов защиты оказывается достаточно, чтобы специфицировать ACL каждого файла.
Аналогичным образом защищены и другие объекты ОС Unix, например семафоры, сегменты разделяемой памяти и т.
п.
Указанных видов прав достаточно, чтобы определить допустимость любой операции с файлами. Например, для удаления файла необходимо иметь право на запись в соответствующий каталог. Как уже говорилось, права доступа к файлу проверяются только на этапе открытия. При последующих операциях чтения и записи проверка не выполняется. В результате, если режим доступа к файлу меняется после того, как файл был открыт, это не сказывается на процессах, уже открывших этот файл. Данное обстоятельство является уязвимым с точки зрения безопасности местом.
Наличие всего трех видов субъектов доступа: владелец, группа, все остальные - затрудняет задание прав "с точностью до пользователя", особенно в случае больших конфигураций. В популярной разновидности Unix - Solaris имеется возможность использовать списки управления доступом (ACL), позволяющие индивидуально устанавливать права доступа отдельных пользователей или групп.
Среди всех пользователей особое положение занимает пользователь root, обладающий максимальными привилегиями. Обычные правила разграничения доступа к нему не применяются - ему доступна вся информация на компьютере.
В Unix имеются инструменты системного аудита - хронологическая запись событий, имеющих отношение к безопасности. К таким событиям обычно относят: обращения программ к отдельным серверам; события, связанные с входом/выходом в систему и другие. Обычно регистрационные действия выполняются специализированным syslog-демоном, который проводит запись событий в регистрационный журнал в соответствии с текущей конфигурацией. Syslog-демон стартует в процессе загрузки системы.
Таким образом, безопасность ОС Unix может быть доведена до соответствия классу C2. Однако разработка на ее основе автоматизированных систем более высокого класса защищенности может быть сопряжена с большими трудозатратами.
Выявление вторжений. Аудит системы защиты
Даже самая лучшая система защиты рано или поздно будет взломана. Обнаружение попыток вторжения является важнейшей задачей системы защиты, поскольку ее решение позволяет минимизировать ущерб от взлома и собирать информацию о методах вторжения. Как правило, поведение взломщика отличается от поведения легального пользователя. Иногда эти различия можно выразить количественно, например подсчитывая число некорректных вводов пароля во время регистрации.
Основным инструментом выявления вторжений является запись данных аудита. Отдельные действия пользователей протоколируются, а полученный протокол используется для выявления вторжений.
Аудит, таким образом, заключается в регистрации специальных данных о различных типах событий, происходящих в системе и так или иначе влияющих на состояние безопасности компьютерной системы. К числу таких событий обычно причисляют следующие:
вход или выход из системы;операции с файлами (открыть, закрыть, переименовать, удалить);обращение к удаленной системе;смена привилегий или иных атрибутов безопасности (режима доступа, уровня благонадежности пользователя и т. п.).
Если фиксировать все события, объем регистрационной информации, скорее всего, будет расти слишком быстро, а ее эффективный анализ станет невозможным. Следует предусматривать наличие средств выборочного протоколирования как в отношении пользователей, когда слежение осуществляется только за подозрительными личностями, так и в отношении событий. Слежка важна в первую очередь как профилактическое средство. Можно надеяться, что многие воздержатся от нарушений безопасности, зная, что их действия фиксируются.
Помимо протоколирования, можно периодически сканировать систему на наличие слабых мест в системе безопасности. Такое сканирование может проверить разнообразные аспекты системы:
короткие или легкие пароли;неавторизованные set-uid программы, если система поддерживает этот механизм;неавторизованные программы в системных директориях;долго выполняющиеся программы;нелогичная защита как пользовательских, так и системных директорий и файлов. Примером нелогичной защиты может быть файл, который запрещено читать его автору, но в который разрешено записывать информацию постороннему пользователю;потенциально опасные списки поиска файлов, которые могут привести к запуску "троянского коня";изменения в системных программах, обнаруженные при помощи контрольных сумм.
Любая проблема, обнаруженная сканером безопасности, может быть как ликвидирована автоматически, так и передана для решения менеджеру системы.
Windows NT/2000/XP
С момента выхода версии 3.1 осенью 1993 года в Windows NT гарантировалось соответствие уровню безопасности C2. В настоящее время (точнее, в 1999 г.) сертифицирована версия NT 4 с Service Pack 6a с использованием файловой системы NTFS в автономной и сетевой конфигурации. Следует помнить, что этот уровень безопасности не подразумевает защиту информации, передаваемой по сети, и не гарантирует защищенности от физического доступа.
Компоненты защиты NT частично встроены в ядро, а частично реализуются подсистемой защиты. Подсистема защиты контролирует доступ и учетную информацию. Кроме того, Windows NT имеет встроенные средства, такие как поддержка резервных копий данных и управление источниками бесперебойного питания, которые не требуются "Оранжевой книгой", но в целом повышают общий уровень безопасности.
ОС Windows 2000 сертифицирована по стандарту Common Criteria. В дальнейшем линейку продуктов Windows NT/2000/XP, изготовленных по технологии NT, будем называть просто Windows NT.
Ключевая цель системы защиты Windows NT - следить за тем, кто и к каким объектам осуществляет доступ. Система защиты хранит информацию, относящуюся к безопасности для каждого пользователя, группы пользователей и объекта. Единообразие контроля доступа к различным объектам (процессам, файлам, семафорам и др.) обеспечивается тем, что с каждым процессом связан маркер доступа, а с каждым объектом - дескриптор защиты. Маркер доступа в качестве параметра имеет идентификатор пользователя, а дескриптор защиты - списки прав доступа. ОС может контролировать попытки доступа, которые производятся процессами прямо или косвенно инициированными пользователем.
Windows NT отслеживает и контролирует доступ как к объектам, которые пользователь может видеть посредством интерфейса (такие, как файлы и принтеры), так и к объектам, которые пользователь не может видеть (например, процессы и именованные каналы). Любопытно, что, помимо разрешающих записей, списки прав доступа содержат и запрещающие записи, чтобы пользователь, которому доступ к какому-либо объекту запрещен, не смог получить его как член какой-либо группы, которой этот доступ предоставлен.
Система защиты ОС Windows NT состоит из следующих компонентов:
Процедуры регистрации (Logon Processes), которые обрабатывают запросы пользователей на вход в систему. Они включают в себя начальную интерактивную процедуру, отображающую начальный диалог с пользователем на экране и удаленные процедуры входа, которые позволяют удаленным пользователям получить доступ с рабочей станции сети к серверным процессам Windows NT.Подсистемы локальной авторизации (Local Security Authority, LSA), которая гарантирует, что пользователь имеет разрешение на доступ в систему. Этот компонент - центральный для системы защиты Windows NT. Он порождает маркеры доступа, управляет локальной политикой безопасности и предоставляет интерактивным пользователям аутентификационные услуги. LSA также контролирует политику аудита и ведет журнал, в котором сохраняются сообщения, порождаемые диспетчером доступа.Менеджера учета (Security Account Manager, SAM), который управляет базой данных учета пользователей. Эта база данных содержит информацию обо всех пользователях и группах пользователей. SAM предоставляет услуги по легализации пользователей, применяющиеся в LSA.Диспетчера доступа (Security Reference Monitor, SRM), который проверяет, имеет ли пользователь право на доступ к объекту и на выполнение тех действий, которые он пытается совершить. Этот компонент обеспечивает легализацию доступа и политику аудита, определяемые LSA. Он предоставляет услуги для программ супервизорного и пользовательского режимов, для того чтобы гарантировать, что пользователи и процессы, осуществляющие попытки доступа к объекту, имеют необходимые права. Данный компонент также порождает сообщения службы аудита, когда это необходимо.
Microsoft Windows NT - относительно новая ОС, которая была спроектирована для поддержки разнообразных защитных механизмов, от минимальных до C2, и безопасность которой наиболее продумана. Дефолтный уровень называется минимальным, но он легко может быть доведен системным администратором до желаемого уровня.
Решение вопросов безопасности операционных систем
Решение вопросов безопасности операционных систем обусловлено их архитектурными особенностями и связано с правильной организацией идентификации и аутентификации, авторизации и аудита.
Наиболее простой подход к аутентификации - применение пользовательского пароля. Пароли уязвимы, значительная часть попыток несанкционированного доступа в систему связана с компрометацией паролей.
Авторизация связана со специфицированием совокупности аппаратных и программных объектов, нуждающихся в защите. Для защиты объекта устанавливаются права доступа к нему. Набор прав доступа определяет домен безопасности. Формальное описание модели защиты осуществляется с помощью матрицы доступа, которая может храниться в виде списков прав доступа или перечней возможностей.
Аудит системы заключается в регистрации специальных данных о различных событиях, происходящих в системе и так или иначе влияющих на состояние безопасности компьютерной системы.
Среди современных ОС вопросы безопасности лучше всего продуманы в ОС Windows NT.
