[Www sparc com v9] имеет регистровый
[www.sparc.com v9] имеет регистровый файл, объем которого у старых версий процессора составлял 136 32-разрядных слов, а у современных 520 и более. Этот файл состоит из групп по 8 регистров.
Программе одновременно доступно 32 регистра, нумеруемые от 0 до 31, называемые регистровым окном. Из них регистр 0 (обозначаемый как % g0) — выделенный, чтение из него всегда возвращает 0. Следующие 7 регистров (обозначаемые как %g1-%g7) используются для глобальных переменных. Эти регистры не входят в регистровое окно. Регистры с r8 по r15 (%о0-%о7) используются для передачи параметров вызываемой процедуре (r15 используется для хранения адреса возврата подпрограммы), регистры с г24 по г31 (%i0-%i7)— для доступа к параметрам, и, наконец, регистры с г16 по г23 (%I0-%I7) — для хранения локальных переменных. При вызове подпрограммы, команда save сдвигает регистровое окно, так что регистры %оО-%о7 вызывающей процедуры становятся регистрами %о0-%о7 процедуры вызванной. Регистры rО-r7 сдвигом регистрового окна не затрагиваются.
Таким образом, регистровый файл выполняет функции стека вызовов — в нем сохраняются адреса возврата, передаются параметры и хранятся локальные переменные. Впрочем, такой подход при всей его привлекательности имеет большой недостаток— глубина стека вызовов оказывается ограничена глубиной регистрового файла. Способ устранения этого ограничения описан в разд. Косвенный регистровый режим со смещением.
Важно еще раз отметить, "что обычно далеко не все имеющиеся регистры непосредственно доступны программе. Так, в системе команд х86 предусмотрено всего восемь регистров общего назначения, но современные суперскалярные реализации этой архитектуры (Pentium II, Athlon и т. д.) имеют более сотни физических регистров и несколько арифметико-логических устройств. Логика предварительной выборки дешифрует несколько команд и назначает исполнение этих команд на свободные АЛУ, по мере их поступления, с использованием свободных копий регистров, при этом, не нарушая связи по данным между последовательными командами.
При наличии большого количества регистров существует два подхода к их выбору. Первый состоит в том, что каждый код операции работает только со
СВОИМ регистром. Команда move %eax, %ebx — это одна команда, a move
%еах, %esp — совсем другая. При этом бывает и так, что некоторые команды Для некоторых регистров не определены.
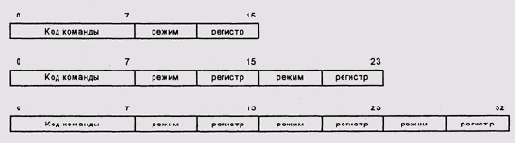
Второй подход, более симпатичный автору, называется ортогональной системой команд, и состоит в том, что все команды (или хотя бы большинство) могут работать с любыми регистрами. Номер регистра при этом кодируется специальным битовым полем в коде команды (или несколькими битовыми полями, если команда оперирует несколькими регистрами) (Рисунок 2.3).
Абсолютная адресация
Абсолютная адресация
При абсолютной адресации адресное поле команды непосредственно содержит номер целевой ячейки памяти. Таким способом производятся обращения к объектам с постоянными адресами: статическим и внешним переменным, точкам входа подпрограмм.
Как и в случае с обсуждавшейся в предыдущем подразделе литеральной адресацией, процессор, который использует такую адресацию, либо должен иметь команды переменной длины, либо его команда должна быть длиннее адреса. Второе условие выполняется не только у процессоров гарвардской архитектуры, но и у многих старых компьютеров с небольшим адресным пространством.
Абсолютная адресация в системе команд SPARC
Абсолютная адресация в системе команд SPARC
У процессоров SPARC реализация абсолютной адресации похожа на реализацию адресации литеральной: под адресацию занимается регистр, командой sethi %hi (addr) , reg в него загружается старшая часть адреса, а затем происходит собственно адресация. Для формирования 64-разрядного адреса необходимо занимать два регистра и выполнять ту же программу, что и в примере 2.1.
Обращение к переменной в памяти происходит так, как показано в примере 2.2.
Адресация оперативной памяти
Адресация оперативной памяти
С точки зрения процессора, оперативная память представляет собой массив пронумерованных ячеек. Номер каждой ячейки памяти называется ее адресом. Разрядность адреса является одной из важнейших характеристик процессора и реализуемой им системы команд. Разрядность важна не как самоцель, а потому, что ею обусловлен объем адресуемой памяти — адресного пространства. Системы с 16-разрядным адресом способны адресовать 64 Кбайт (65 536) ячеек памяти, а с 32-разрядным — 4 Гбайт (4 294 967 296) ячеек. В наше время адресуемая память в 4 Гбайт для многих приложений считается неприемлемо маленькой и требуется 64-разрядная адресация.
Процессору обычно приходится совершать арифметические операции над адресами, поэтому разрядность адреса у современных процессоров обычно совпадает с разрядностью основного АЛУ.
У некоторых компьютеров адресация (нумерация) ячеек памяти фиксированная: одна и та же ячейка памяти всегда имеет один и тот же номер. Такая адресация называется физической. Адрес при этом разбит на битовые поля, которые непосредственно используются в качестве номера физической микросхемы памяти, и номеров строки и столбца в этой микросхеме. Напротив, большинство современных процессоров общего назначения используют виртуальную адресацию, когда номер конкретной ячейки памяти определяется не физическим размещением этой ячейки, а контекстом, в котором происходит адресация. Способы реализации виртуальной памяти и необходимость ее применения обсуждаются в главе 5.
В старых компьютерах размер адресуемой ячейки памяти данных совпадал с разрядностью АЛУ центрального процессора и разрядностью шины данных. Адресуемая ячейка называлась словом. В процессорах манчестерской архитектуры, которые могут использовать одну и ту же память как для команд, так и для данных, оба размера определялись длиной команды. Из-за этого многие процессоры такого типа имели странные по современным представлениям разрядности — 48, 36, иногда даже 25 бит.
Адресация с использованием счетчика команд
Адресация с использованием счетчика команд
Любой процессор предоставляет как минимум один способ такой адресации: адресация самих команд при их последовательной выборке осуществляется при помощи счетчика команд с постинкрементом. У процессоров с командами переменной длины величина постинкремента зависит от кода команды.
Некоторые процессоры позволяют использовать счетчик команд наравне со всеми остальными регистрами общего назначения. Запись в этот регистр приводит к передаче управления по адресу, который соответствует записанному значению. Чтение из этого регистра позволяет узнать адрес текущей команды, что само по себе не очень полезно и часто может быть сделано Другими способами. Однако использование других режимов адресации со счетчиком команд порой позволяет делать неожиданные, но весьма полезные трюки.
разрядный адрес, который позволял адресовать
Адресное пространство PDP-11
Машины серии PDP-11 имеют 16- разрядный адрес, который позволял адресовать 64 Кбайт. У старших моделей серии это пространство разбито на 8 сегментов по 8 Кбайт каждый. Каждому из этих сегментов соответствует свой селектор банка (в данном случае следует уже говорить о дескрипторе сегмента) (Рисунок 2.17). Физическое адресное пространство, которое может быть охвачено дескрипторами сегментов, составляет 2 Мбайт, что намного больше адресов, доступных отдельному процессу. На первый взгляд, эта конструкция представляет собой усложненную реализацию банковой адресации, цель которой — только расширить физическое адресное пространство за пределы логического, но тот факт, что, кроме физического адреса, каждый сегмент имеет и другие атрибуты, в том числе права доступа, заставляет нас признать, что это уже совсем другая история, заслуживающая отдельной главы (см. главу 5).

Рисунок 2.17. Виртуальная память PDP-11/20
Банки команд в Р/С
Банки команд в Р/С
У микроконтроллеров PIC арифметические операции производятся только над младшими 8 битами счетчика команд, поэтому относительные и вычислимые переходы допустимы только в пределах 256-командного банка. Однако полное — с учетом селектора банка — адресное пространство для команд достигает 64 Кбайт, а у старших моделей и 16 Мбайт за счет использования двух регистров-расширителей. Переключение банка осуществляется специальными командами "длинного" — межбанкового — перехода.
Если банковая адресация реализована как внешнее устройство, проблема межбанковой передачи управления встает перед нами в полный рост. Поскольку мы не имеем команд межбанкового перехода, любой такой переход состоит минимум из двух команд: переключения банка и собственно перехода. Каждая из них нарушает порядок исполнения команд.
Рассмотрим ситуацию детальнее (Рисунок 2.15): из кода, находящегося в банке 1 по адресу OxlOaf, мы хотим вызвать процедуру, находящуюся в банке 2 по адресу 0x2000. Если мы сначала выполним переключение банка, мы окажемся в банке 2 по адресу ОхЮЬО, не имея никакого представления о том, какой же код или данные размещены по этому адресу. С той же проблемой мы столкнемся, если сначала попытаемся сделать переход по адресу Oxlfff.
В качестве решения можно предложить размещение по адресу Oxlfff в банке 1 команды переключения на банк 2. Возможно, для этого придется переместить какой-то код или данные, но мы попадем по желаемому адресу. Впро-Чем, если мы постоянно осуществляем межбанковые переходы, этот подход Потребует вставки команд переключения банка для каждой возможной точки входа во всех остальных банках. Ручное (да и автоматизированное)размещение этих команд — операция чрезвычайно трудоемкая, и возникает естественная идея: сконцентрировать все эти вставленные команды и соответствующие им точки входа в каком-то одном месте. Впрочем, даже эта идея не дает нам ответа на вопрос, как же при такой архитектуре возвращать управление из процедур? Вставлять команду переключения еще и для каждой команды вызова?
Банки памяти
Банки памяти
Банки памяти используются, когда адресное пространство процессора мало, а приложение требует. При этом стоимостные и электротехнические ограничения позволяют нам установить в систему гораздо больше памяти, чем процессор может адресовать. Например, у многих" микроконтроллеров адрес имеет длину всего 8 бит, однако 256 байт данных, и тем более 256 команд кода для большинства приложений недостаточно. Многие из ранних персональных компьютеров, основанных на 8-разрядных микропроцессорах i8085 и Z80 с 16-разрядным адресом, имели гораздо больше 64 Кбайт памяти. Например, популярные в годы детства авторов компьютеры Yamaha имели до 2 Мбайт оперативной памяти.
Адресация дополнительной памяти в этой ситуации обеспечивается дополнительным адресным регистром, который может быть как конструктивным элементом процессора, так и внешним устройством. Этот регистр дает нам дополнительные биты адреса, которые и обеспечивают адресацию дополнительной памяти. Регистр этот называется расширителем адреса или селектором банка, а область памяти, которую можно адресовать, не изменяя селектор банка, - банком памяти. Значение регистра-селектора называют номером банка.
Банковая адресация в 16разрядных микропроцессорах
Банковая адресация в 16-разрядных микропроцессорах
Внимательный читатель, знакомый с системой команд Intel 8086, не может не отметить, что "сегментные" регистры этого процессора имеют мало общего с собственно сегментацией, описываемой в главе 5. Эти регистры более похожи на причудливый гибрид селектора банков и базового регистра. Как и описываемый далее PIC, I8086 имеет команды "ближних" (внутрибанковых) и "дальних" (межбанковых) переходов, вызовов и возвратов.
Относящийся к тому же поколению процессоров Zylog 800 имеет полноценные селекторы банков. Из всех изготовителей 16-разрядных микропроцессоров только инженеры фирмы Motorola осмелились расширить адрес до 24 бит (это потребовало увеличения разрядности регистров и предоставления команд 32-разрядного сложения), все остальные так или иначе экспериментировали с селекторами банков и вариациями на эту тему.
Работа с банками памяти данных обычно не представляет больших проблем, за исключением ситуаций, когда нам нужно скопировать из одного банка в другой структуру данных, которую невозможно разместить в регистрах процессора. Существенно более сложную задачу представляет собой передача управления между банками программной памяти.
В том случае, когда селектор банка программной памяти интегрирован в процессор, предоставляются специальные команды, позволяющие перезагрузить одновременно "младшую" (собственно регистр PC) и "старшую" (селектор банка) части счетчика команд.
Базовоиндексный режим
Базово-индексный режим
В этом режиме адрес операнда образуется сложением двух или, реже, большего количества регистров и, возможно, еще и адресного смещения. Такой режим может использоваться для адресации массивов — один регистр содержит базовый адрес массива, второй — индекс, откуда и название. Иногда значение индексного регистра умножается на размер операнда, иногда — нет.
На первый взгляд, ортогональные архитектуры должны испытывать определенные сложности с-кодированием такой адресации: для этого нужно два регистровых поля, а большинство остальных режимов довольствуются одним регистром. Однако многие ортогональные архитектуры, например VAX, МС680хО, SPARC реализуют этот режим, пусть иногда и с ограничениями.
имела слово разрядностью 48
БЭСМ-6
Так, БЭСМ- 6 имела слово разрядностью 48 бит и команды длиной 24 бита, состоявшие из 15-разрядного адресного поля и 9-разрядного кода операции. Адресное поле позволяло адресовать 32К слов. В одном слове размещалось две команды, при этом команды перехода могли указывать только на первую из упакованных в одно слово команд. У процессоров гарвардской архитектуры (имеющих раздельные памяти для команд и данных) разрядность АЛУ и размер команды не связаны.
CISC и RISCпроцессоры
CISC- и RISC-процессоры
Часто приходится сталкиваться с непониманием термина RISC, общепринятая расшифровка которого — Reduced Instruction Set Computer (компьютер с уменьшенной системой команд). Какой же, говорят, SPARC или PowerPC -RISC, если у него количество кодов команд не уступает или почти не уступает количеству команд в х8б? Почему тогда х86 не RISC, ведь у него команд гораздо меньше и они гораздо проще, чем у VAX 11/780, считающегося классическим примером CISC-архитектуры. Да и технологии повышения производительности у современных х86 и RISC-процессоров используются примерно те же, что и у больших компьютеров 70-х: множественные АЛУ, виртуальные регистры, динамическая перепланировка команд.
В действительности, исходно аббревиатура RISC расшифровывалась несколько иначе, а именно как Rational Instruction Set Computer (RISC, компьютер с рациональной системой команд). RISC-процессоры, таким образом противопоставлялись процессорам с необязательно сложной (CISC - Complex Instruction Set Computer, компьютер со сложной системой команд), но "иррациональной", исторически сложившейся архитектурой, в которой, в силу требований бинарной и ассемблерной совместимости с предыдущими поколениями, накоплено множество команд, специализированных регистров и концепций, в общем-то и не нужных, но вдруг отменишь команду двоично-десятичной коррекции, а какое-то распространенное приложение "сломается"? А мы заявляли бинарную совместимость. Скандал!
Понятно, что быть "рациональными" в таком понимании могут лишь осваивающие новый рынок разработчики, которых не заботит та самая бинарная совместимость. Уже сейчас, например, фирма Sun, одним из главных достоинств своих предложений на основе процессоров UltraSPARC числит полную бинарную совместимость с более ранними машинами семейства SPARC. Новые процессоры вынуждены поддерживать бинарную совместимость с 64-разрядными младшими родственниками и режим совместимости с 32-разрядными. Где уж тут заботиться о рациональности.
С другой стороны, рациональность тоже можно понимать по-разному. В конце 70-х и первой половине 80-х годов общепринятым пониманием "рациональности" считалась своеобразная (с высоты сегодняшнего дня) ориентация на языки высокого уровня. Относительно примитивные трансляторы тех времен кодировали многие операции, например прологи и эпилоги процедур, доступ к элементу массива по индексу, вычислимые переходы (switch в С, Case в Pascal) при помощи стандартных последовательностей команд. Поскольку все меньше и меньше кода писалось вручную и все больше и больше — генерировалось трансляторами, разработчики процессоров решили пойти создателям компиляторов навстречу.
Этот шаг навстречу выразился в стремлении заменить там, где это возможно, последовательности операций, часто встречающиеся в откомпилированном коде, одной командой. Среди коммерчески успешных архитектур апофеозом этого подхода следует считать семейство миникомпьютеров VAX фирмы DEC, в котором одной командой реализованы не только пролог Функции и копирование строки символов, но и, скажем, операции удаления и вставки элемента в односвязный список. Приведенная в качестве примера шестиадресной команды команда INDEX — реальная команда этого процессора. Отдельные проявления этой тенденции без труда прослеживаются и в системах команд MC68000 и 8086. Аббревиатура CISC позднее использовалась именно для характеристики процессоров этого поколения.
- Другой стороны, неумение трансляторов этого поколения эффективно Размещать переменные и промежуточные значения по регистрам считалось Доводом в пользу того, что от регистров следует отказываться и заменять их Регистровыми стеками или кэш-памятью. (Впрочем, и у VAX, и у MC68000 с Регистрами общего назначения было все в порядке, по 16 штук.)
Ко второй половине 80-х развитие технологий трансляции позволило заменить генерацию стандартных последовательностей команд более интеллектуальным и подходящим к конкретному случаю кодом. Разработанные технологии оптимизации выражений и поиска инвариантов цикла позволяли, в частности, избавляться от лишних проверок. Например, если цикл исполняется фиксированное число раз, а счетчик цикла используется в качестве индекса массива, не надо вставлять проверку границ индекса в тело цикла — достаточно убедиться, что ограничитель счетчика не превосходит размера массива. Более того, если счетчик используется только в качестве индекса, можно вообще избавиться и от него, и от индексации, а вместо этого использовать указательную арифметику. Наконец, если верхняя граница счетчика фиксирована и невелика, цикл можно развернуть (пример 2.6).
Формат команд условного перехода и вызова процессора SPARC
Рисунок 2.14. Формат команд условного перехода и вызова процессора SPARC

Команда вызова подпрограммы у SPARC также использует адресацию относительно счетчика команд, но адресное поле у нее 30-разрядное и интерпретируется как адрес слова, а не байта. При сложении смещения и счетчика команд возможные переполнения игнорируются, поэтому такой командой можно адресовать любое слово (т. е. любую команду) в 32-разрядном адресном пространстве. На первый взгляд, неясно даже, какая польза от того, что адресация производится относительно счетчика команд, а не абсолютно. Но в 64-разрядных процессорах SPARC v9 польза от этого большая — абсолютный 30-разрядный адрес позволял бы адресовать только первое гигаслово памяти, а относительное смещение адресует именно сегмент кода, в какой бы части 64-разрядного адресного пространства он бы ни находился. Программ, имеющих объем более одной гигакоманды, или даже половины гигакоманды, пока что не написано, поэтому 30-разрядного смещения практически достаточно для адресации в пределах любой современной программы.
Процессоры, не предоставляющие программисту прямого доступа к счетчику команд, зачастую все-таки дают возможность записывать в него произвольные значения при помощи специальных команд вычислимого перехода и вычислимого вызова. Команды вычислимого вызова широко используются для реализации указателей на функции из таблиц виртуальных методов в объектно-ориентированных языках. Главное применение команд вычислимого перехода -- реализация операторов switch языка C/C++ или case языка Pascal.
Формат команды микропроцессора
Рисунок 2.3. Формат команды микропроцессора SPARC (цит. по [www.sparc.com v9])

При всех недостатках первого подхода, ортогональная система команд создает специфическую проблему: увеличение количества регистров оказывается невозможным. Ведь это требует расширения битового поля номера регистра, а изменение размера битовых полей команд - это нарушение бинарной совместимости. Впрочем, в разд. Вытесняющая многозадачность мы поймем, почему даже в неортогональных системах команд расширение номенклатуры регистров практически невозможно.
Форматы команд машинного языка
Форматы команд машинного языка
Команда центрального процессора состоит из кода операции и одного или нескольких операндов (объектов, над которыми совершается операция). В зависимости от числа операндов, команды делятся на безадресные (не имеющие операндов или имеющие неявно указанные), одноадресные (производящие операцию над одним объектом или одним явно и одним или несколькими неявно указанными), двух- и трехадресные. Встречаются архитектуры, в которых есть команды и с большим числом операндов, но это экзотика.
Примеры безадресных команд без операнда.
Примеры безадресных команд с неявно указанными операндами
RETURN Возврат из подпрограммы. Выталкивает из стека адрес возврата и помещает его в счетчик команд. WDR WatchDog Reset, сброс сторожевого таймера микроконтроллера. ADD Вытолкнуть из стека два значения, сложить их и протолкнуть результат в стек. scs Skip if Carry Set, пропустить следующую команду, если бит переноса в слове состояния установлен.Примеры одноадресных команд с одним операндом
INC x INCrement, добавить к операнду 1 и сохранить результат по тому же адресу. TST х TeST, установить в слове состояния флаги знака и равенства нулю в соответствии со значением операнда.Примеры одноадресных команд с неявным операндом.
ADD x [, Асс] Сложить операнд с аккумулятором и сохранить результат в аккумуляторе. PUSH х Протолкнуть значение операнда в стек. CALL x Вызов подпрограммы, сохраняет адрес следующей команды в стеке и передает управление по указанному адресу. BNEQ х Передает управление по указанному адресу, если в слове состояния установлен флаг равенства нулю.Примеры двух- и трехадресных команд.
MOVE x, уПрисвоить значение объекта х объекту у.
ADD x, уСложить х и у, поместить результат в у.
ADD x, у, z Сложить х и у и поместить результат в z.
Четырехадресная команда:
DIV х, у, z, w
выполняет деление х на у, помещает частное в z, а остаток — в w. Шестиадресная команда:
INDEX b, I, h, s, i, a
вычисляет адрес элемента массива, расположенного по адресу b, с нижней и верхней границами индекса I и b соответственно и размером элемента s.
Операнд i — индекс элемента, а — место, куда следует поместить вычисленный адрес.
Количество адресов иногда используют и для общей характеристики системы команд. Двухадресной называют систему команд, в которой команды имеют максимум два операнда, трехадресной -- максимум три. Нередко, впрочем, вместо максимального количества операндов, адресность системы команд определяют по количеству операндов у наиболее "ходовых" команд — сложения и вычитания. Таким образом, VAX, из системы команд которого взяты примеры четырех- и шестиадресных команд, часто относят к трехадресным архитектурам.
Одноадресные системы команд обычно используют в качестве неявно заданного операнда выделенный регистр, так называемый аккумулятор, или стек. Такие архитектуры называют, соответственно, аккумуляторными и стековыми.
Одноадресную аккумуляторную архитектуру имеют микроконтроллеры семейства PIC фирмы Microchip. Большинство современных процессоров имеют двух- и трехадресные системы команд.
На примере стековой команды ADD мы видели, что многие из команд стековой архитектуры могут обойтись вообще без явно указанных операндов, однако команды проталкивания значений переменных в стек и выталкивания их оттуда все-таки необходимы, поэтому все стековые архитектуры одно-, а не безадресные.
Стеки привлекательны, во-первых, тем, что не нуждающиеся в операндах команды могут иметь очень короткий код операции (как правило, достаточно одного байта) и, во-вторых, тем, что работающая с ними программа представляет собой арифметическое выражение, записанное в обратной польской нотации — когда мы сначала пишем операнды, а потом знак операции. Например, операция а+ь в этой записи выглядит как ab+ (в программе — push a; push b; add;).
Задача преобразования привычных нам арифметических выражений в обратную польскую запись легко формализуется, поэтому стековые процессоры долгое время позиционировались как "ориентированные на языки высокого уровня". Позже, впрочем, выяснилось, что более сложная логика разбора арифметических выражений позволяет проводить разного рода оптимизации (сокращать введенные лишь для удобства записи переменные, заменять выражения, которые всегда дают одно и то же значение, на константы, выносить повторяющиеся вычисления из тела цикла и т. д.).
Аппаратно реализованные стековые архитектуры — в наше время редкость. Из относительно современных процессоров, имевших коммерческий успех, можно назвать Transputer фирмы Inmos (в настоящее время эти микропроцессоры выпускаются фирмой SGC-Thomson).
Шире всего стековая архитектура распространена в байт-кодах или, как это еще называют, системах команд виртуальных машин. Байт-код - это промежуточное представление программы, используемое интерпретатором, чтобы избежать лексического и синтаксического анализа программы на этапе исполнения. Исполнение байт-кода осуществляется не процессором, а программой-интерпретатором. Таким образом, реализуются многие современные языки программирования — многочисленные диалекты языка BASIC, Lisp, SmallTalk, Fort (этот язык любопытен тем, что сам имеет стековый синтаксис), наконец Java. Некоторые реализации интерпретаторов этих языков используют так называемую JIT-комтшяцию (Just In Time, точно в момент [исполнения]), когда перед исполнением байт-код компилируется в систему команд физического процессора. Такая технология позволяет достичь для "интерпретируемых" программ производительности, не уступающей производительности компилированного кода.
Первым промышленным применением JIT-компиляции была система AS/400 фирмы IBM. В настоящее время JIT широко используется в реати-зациях Java. JIT-компиляция привлекательна тем, что позволяет исполнять один и тот же код на разнообразных процессорах без потерь (или почти без потерь) скорости.
Форматы одно двух и трехадресной команд процессора VAX
Рисунок 2.6. Форматы одно-, двух- и трехадресной команд процессора VAX
Индексный режим адресации в системе команд SPARC
Индексный режим адресации в системе команд SPARC
SPARC позволяет использовать для вычисления адреса в командах LD, зт и JMPL как сумму двух регистров, так и сумму регистра и 13-разрядного смещения. Таким образом, эти команды реализуют либо косвенно-регистровый режим (если используется смещение и оно равно 0), либо косвенно-регистровый режим со смещением, либо базово-индексный режим без смещения. Это, конечно, беднее, чем у CISC-процессоров, но жить с таким набором вполне можно.
Индексный режим адресации VAX
Индексный режим адресации VAX
У VAX за операндом, указывающим индексный режим адресации и индексный регистр, следует еще один байт, кодирующий режим адресации и регистр, используемые для вычисления базового адреса (Рисунок 2.12). Идея разрешить многократное указание индексного регистра в одном операнде, к сожалению, не реализована.
Языки ассемблера
Языки ассемблера
Непосредственно на машинном языке в наше время не программирует практически никто. Первый уровень, позволяющий абстрагироваться от схемы кодирования команд, — это уже упоминавшийся язык ассемблера. В языке ассемблера каждой команде машинного языка соответствует мнемоническое обозначение. Все приведенные ранее примеры написаны именно на языке ассемблера, да и в тексте использовались не бинарные коды команд, а их мнемоники.
Встречаются ассемблеры, которые предоставляют мнемонические обозначения для часто используемых групп команд. Большинство таких языков позволяет пользователю вводить свои собственные мнемонические обозначения — так называемые макроопределения или макросы (macros), в том числе и параметризованные (пример 2.7).
Отличие макроопределений от процедур языков высокого уровня в том, что процедура компилируется один раз, и затем ссылки на нее реализуются в виде команд вызова. Макроопределение же реализуется путем подстановки тела макроопределения (с заменой параметров) на место ссылки на него и компиляцией полученного текста. Компиляция ассемблерного текста, таким образом, осуществляется в два или более проходов — на первом осуществляется раскрытие макроопределений, на втором — собственно компиляция, которая, в свою очередь, может состоять из многих проходов, смысл которых мы поймем далее. Часть ассемблера, реализующая первый проход, называется макропроцессором.
Команды перехода
Команды перехода
Как говорилось в начале главы, команды условного перехода — это то, что отличает фон-неймановский процессор от непроцессора или, в крайнем случае, от не фон-неймановского процессора. Большинство современных процессоров имеет обширный набор команд условного перехода по различным арифметическим условиям и их комбинациям.
Арифметические флаги выставляются в соответствии с результатами последней арифметической и логической операции. Типичный набор арифметических флагов — это бит переноса, бит нуля (выставляется, если все биты результата равны нулю), знаковый бит (если равен нулю старший бит результата) и бит переполнения. В процессорах первых поколений нередко использовался обратный подход: процессор имел всего один флаг условия перехода (так называемый ы-признак) и одну команду условного перехода, зато несколько команд сравнения, придававших этому флагу различную семантику.
Набор команд перехода, приведенный в табл. 2.1, несколько шире обычного — команды SBRC/SBRS для процессоров общего назначения нетипичны.
Микроконтроллеры PIC (по-видимому, самая экстравагантная система команд среди современных промышленно выпускаемых процессоров) имеют всего две команды, выполняющие функции команд условного перехода: BTFCS (Bit Test, Skip if Set — проверить бит и, если он установлен, пропустить следующую команду) и BTFCC (Bit Test, Skip if Clear, пропустить следую-шую команду, если бит сброшен). Объектом проверки может служить любой бит любого регистра процессора, в том числе и биты арифметических условий статусного слова. Для реализации условного перехода следом за такой командой нужно разместить команду безусловного перехода. Именно таким образом ассемблеры для этого микроконтроллера реализуют псевдокоманды условных переходов.
Короткие литералы МСбЗОхО
Короткие литералы МСбЗОхО
У процессоров семейства МС680хО литерал может иметь длину 1 или 2 байта. Кроме того, предоставляются команды ADDQ и SUBQ, которые позволяют добавить к указанному операнду или вычесть из него целое число в диапазоне от 1 до 8.
Короткие литералы VAX
Короткие литералы VAX
У процессоров семейства VAX есть режим адресации, позволяющий использовать битовое поле, которое в других режимах интерпретируется как номер регистра, в качестве 4-битового литерала. Вместе с двумя битами режима адресации этим способом можно задать 6-разрядный литерал, знаковый или беззнаковый в зависимости от контекста [Прохоров 1990].
Косвеннорегистровый режим
Косвенно-регистровый режим
В этом режиме, как и в регистровом, адресное поле не используется. Значение регистра интерпретируется как адрес операнда. Данный режим используется для разыменования указателей или для обращения к памяти по предварительно вычисленному адресу.
Некоторые процессоры, такие, как PDP-11, VAX, МСбЗОхО, имеют любопытные варианты этого режима — адресацию с постинкрементом и предек-рементом. Постинкремент означает, что после собственно адресации значение регистра увеличивается на величину адресуемого объекта. Предекремент, соответственно, означает, что регистр уменьшается на ту же величину перед адресацией.
Эти режимы могут использоваться для разнообразных целей, например для реализации операций над текстовыми строками или поэлементного сканирования массивов. Но одно из основных назначений -- это реализация стека.
Косвеннорегистровый режим со смещением
Косвенно-регистровый режим со смещением
Адрес операнда образуется путем сложения регистра и адресного поля команды. Этот режим наиболее богат возможностями и, в зависимости от стиля использования, имеет много других названий, например базовая адресация или индексная адресация. Адресное поле необязательно содержит полноценный адрес и может быть укороченным.
Команды id/st процессора SPARC, используемые в примере 2.2, реализуют косвенно-регистровую адресацию с 13-разрядным смещением.
Возможные варианты использования этого режима адресации многочисленны. Например, если смещение представляет собой абсолютный адрес начала массива, а в регистре хранится индекс, этот режим может использоваться для индексации массива. В этом случае смещение должно представлять собой полноценный адрес.
3 другом случае, в регистре может храниться указатель на структуру Данных, а смещение может означать смещение конкретного поля относительно начала структуры. Еще один вариант -- регистр хранит указатель на стековый кадр или блок параметров процедуры, а смещение -адрес локальной переменной в этом кадре или определенного параметра.
В этих случаях можно использовать (и обычно используется) укороченное смещение.
Литеральная адресация в системе команд SPARC
Литеральная адресация в системе команд SPARC
Разработчики процессоров, которых не устраивает ни одно из названных условий, вынуждены проявлять фантазию. Так, у RISC-процессоров SPARC и команда, и слово имеют одинаковую длину— 32 бита. Адресное поле такой длины в команде невозможно — не остается места для кода операции. Выход, предложенный разработчиками архитектуры SPARC, при первом знакомстве производит странное впечатление, но, как говорят в таких случаях, "не критикуйте то, что работает".
Трехадресные команды SPARC могут использовать в качестве операндов три регистра или два регистра и беззнаковую константу длиной 13 бит. Если константа, которую мы хотим использовать в операции, умещается в 13 бит, мы можем просто использовать эту возможность. На случай, если значение туда не помещается, предоставляется команда sethi const22, reg, которая имеет 22-разрядное поле и устанавливает старшие биты указанного регистра, равными этому полю, а младшие биты — равными нулю.
Таким образом, если мы хотим поместить в регистр 32-разрядную константу value, мы должны делать это с помощью двух команд: sethi %hi (value), reg; or %gO, %lo (value), reg; (в соответствии с [docs.sun.com 806-3774-10], именно так реализована ассемблерная псевдокоманда set value, reg).
С точки зрения занимаемой памяти, это ничуть не хуже, чем команда set value, reg, которая тоже должна была бы занимать 64 бита. Зато такое решение позволяет соблюсти принцип: одна команда — одно слово, который облегчает работу логике опережающей выборки команд.
Впрочем, для 64-разрядного SPARC v9 столь элегантного решения найдено не было. Способ формирования произвольного 64-битового значения требует дополнительного регистра и целой программы (пример 2.1). В зависимости от значения константы этот код может подвергаться оптимизации. Легче всего, конечно, дело обстоит, если требуемое значение помещается в 13 бит.
Литеральная и абсолютная адресация в PDP11 и VAX
Литеральная и абсолютная адресация в PDP-11 и VAX
VAX и PDP-11 не реализуют в чистом виде ни литерального, ни абсолютного режимов адресации. Вместо этого литерал или адрес помещается в программную память непосредственно за операндом и используется, соответственно, косвенно-регистровый с постинкрементом и косвенный с постинкрементом режимы со счетчиком команд в качестве регистра. При исполнении команды счетчик команд указывает на слово, следующее за текущим отрабатываемым операндом (Рисунок 2.13). Использование постинкремента приводит к тому, что счетчик увеличивается на размер, соответственно, литерала или адреса, и таким образом, процессор находит следующий операнд. Этот остроумный прием можно рассматривать как своеобразный способ реализовать команды переменной длины.
Машинные языки
Машинные языки
Центральный процессор современного компьютера — это устройство, исполняющее команды. Полный набор команд конкретного процессора называют машинным языком или системой команд (иногда систему команд называют также архитектурой, но это слово слишком перегружено различными значениями).
Различные процессоры часто имеют одну и ту же" (или слабо варьирующую) систему команд — например, процессоры Intel 80386, 486, Pentium, Pentium II, AMD Кб, Athlon и т. д. — далее в тексте книги мы будем называть все эти процессоры х86.
Процессоры, которые могут исполнять программы на одном и том же машинном языке, называются бинарно-совместимыми. Отношение бинарной совместимости не всегда симметрично: например, более новый процессор может иметь дополнительные команды — тогда он будет бинарно-совместим с более старым процессором того же семе,йства, но не наоборот. Нередко бывает и так, что более новый процессор имеет совсем другую систему команд, но умеет исполнять программы на машинном языке старого процессора в так называемом режиме совместимости — например, все процессоры семейства х86 могут исполнять программы для Intel 8086 и 80286. Некоторые ОС для х8б даже предоставляют возможность собрать единую программу из модулей, использующих разные системы команд.
Еще более обширны семейства процессоров, совместимые между собой по языку ассемблера. Такая совместимость означает всего лишь, что каждая команда одного процессора имеет полный функциональный аналог в системе команд другого, это дает возможность автоматизировать преобразование программ из одного машинного языка в другой. Так, Intel 8086 совместим по языку ассемблера с более ранними процессорами той же фирмы, 8080 и 8085.
Как уже говорилось, асимметрия отношений совместимости обычно направлена от предыдущего поколения процессоров к следующему: более новое (как правило, более мощное) устройство совместимо со своим более старым аналогом, но не наоборот, поэтому часто говорят о совместимости снизу вверх. Это отношение позволяет нам не только классифицировать вычислительные системы по поколениям, но и выделять в разных поколениях предка и совместимых с ним потомков, а в пределах одного поколения находить "братьев" и более дальних родственников.
Прослеживание генеалогий систем команд современных процессоров — увлекательное занятие, которому посвящено немало публикаций, например (jbayko vl2.1.2]. Иногда, кроме бинарной и ассемблерной совместимостсй, при построении таких генеалогий учитывают и столь размытое понятие, как концептуальное родство — и тогда, например, процессоры Motorola 680x0 оказываются родней DEC PDP-11.
Наборы команд различных процессоров отличаются большим разнообразием, однако есть операции, которые в той или иной форме умеют выполнять все современные процессоры.
Во-первых, это арифметические операции над целыми числами в двоичном представлении. Даже в наше время многие микроконтроллеры предоставляют только операции сложения и вычитания, но процессоры современных компьютеров "общего назначения" все без исключения умеют также умножать и делить, при чем не только целые, но и "вещественные" числа (в разд. Представление рациональных чисел мы видели, чем такие числа отличаются от того, что называется вещественным числом в математическом анализе и производных от него дисциплинах). Некоторые специализированные процессоры предоставляют и более экзотические математические функции, например отдельные шаги алгоритма дискретного преобразования Фурье.
Но самая главная команда (или, точнее, самое главное семейство команд), которая и делает процессор полностью программируемым, — это команда перехода, точнее, как минимум две команды: безусловного и условного перехода. На практике большинство современных процессоров имеют по несколько команд безусловного перехода (с разными механизмами вычисления адреса точки перехода), а также до десятка, а иногда и более, команд условного перехода по различным условиям.
Межбанковый переход
Рисунок 2.15. Межбанковый переход

Развитие этой идеи приводит нас к чему-то, похожему на менеджер оверлеев (см. разд. Оверлеи (перекрытия). программный модуль, который присутствует во всех банках по одному и тому же адресу (Рисунок 2.16). Если нам нужно вызвать известную процедуру в определенном банке, мы передаем ее адрес и номер банка этому модулю, и он осуществляет сохранение текущего банка, переключение и переход. Если процедура делает возврат, она возвращает управление тому же модулю, который, в свою очередь, восстанавливает исходный банк и возвращает управление в точку вызова.
Дальнейшее развитие этой идеи приводит к мысли, что самый простой способ разместить этот код во всех банках — это усложнить схему работы селектора банков, например, всегда отображать первый килобайт адресного пространства на одни и те же физические адреса. Аппаратно это несложно: мы анализируем старшие шесть битов адресной шины процессора. Если они не равны нулю, мы подаем на старшие биты адресной шины памяти содержимое селектора банка, если же равны — нулевые биты. Примерно этим способом и расширяют память большинство микрокомпьютеров на основе 8-разрядных процессоров.
Поскольку мы вступили на путь анализа логического адреса, можно пойти и дальше: разбить адресное пространство процессора на несколько банков, каждый со своим селектором.
Microchip PIC
Microchip PIC
Микроконтроллеры семейства PIC фирмы Microchip имеют 8-разрядное АЛУ и накристалльное ОЗУ той же разрядности [www.microchip.com PICMicro]. Команды этих микроконтроллеров размещаются в ПЗУ (также накристалльном), в котором каждое слово имеет 12 бит и содержит одну команду. Аналогично БЭСМ-6, команда микроконтроллера состоит из адресного поля (которое может содержать как адрес, так и константное значение длиной 1 байт) и кода операции. Под код операции остается всего четыре бита, поэтому команд, имеющих полное адресное поле, может быть не более 16. Адресное пространство микроконтроллера составляет 8 бит, т. е. всего 256 слов кода и 256 байт данных. Однако при помощи ухищрения, называемого банковой адресацией (подробнее об этом см. в разд. Банки памяти), старшие модели семейства PIC адресуют и по несколько килобайтов как кода, так и данных.
Впрочем, для многих целей и 256 команд вполне достаточно. Самый маленький в мире Web-сервер [www-ccs.cs.umass.edu] реализован именно на основе PIC. В 512 слов кода удалось упаковать реализацию полноценных подмножеств протоколов RS232 (использованная модель микроконтроллера не имеет аппаратно реализованного последовательного порта), РРР, TCP/IP и HTTP. Web-сервер состоит из двух микросхем — собственно сервера и кристалла флэш-памяти, в котором хранятся экспортируемые сервером HTML-документы и изображения. Сервер включается в последовательный порт компьютера и получает питание от этого порта.
Разработчик сервера рекламирует его как основу (или, во всяком случае, как демонстрацию технической возможности) создания Web-интерфейсов для разнообразного бытового оборудования.
В современных компьютерах единицей адресации является байт — ячейка памяти размером 8 бит. При этом и АЛУ, и шина данных могут иметь большую разрядность (хотя, конечно, эта разрядность всегда кратна байту -8, 16, 32 или 64 бита). Разрядность АЛУ и шины данных может не совпадать: так, 18088 имел 16-разрядное АЛУ и 8-разрядную шину, MC68000 и 180386SX — 32-разрядное АЛУ и 16-разрядную шину. Что при этом понимается под "словом" - зависит от фантазии изготовителей процессора. Например, у вполне 32-разрядного VAX документация называет 16-битовую структуру словом, а 32-битовую — двойным или- длинным словом, хотя, обычно, длиной слова считается все-таки разрядность АЛУ.
При этом различные процессоры по-разному подходят к адресации слов.
Во-первых, некоторые процессоры (PDP-11, SPARC) запрещают обращения к словам, адрес которых не кратен размеру слова, и генерируют при попытках такого обращения исключительную ситуацию ошибки шины. Другие процессоры, например VAX и х86 такие обращения разрешают, но в документации есть честное предупреждение, что обращения к невыровненным словам будут минимум в два раза медленнее, чем к выровненным (Рисунок 2.4).
Микропрограммные автоматы
Микропрограммные автоматы
У фон-неймановских процессоров команды исполняются последовательно, в соответствии с порядком размещения в памяти, и только команды условных и безусловных переходов нарушают этот порядок. "Младшие родственники" фон-неймановских процессоров, микропрограммные автоматы, часто имеют более мощное средство управления последовательностью исполнения: каждая команда автомата имеет битовое поле, содержащее номер следующей по порядку исполнения команды и, таким образом, одновременно является и функциональной командой, и командой безусловного перехода. Методы реализации условных переходов в устройствах такого типа отличаются большим разнообразием.
Такая структура команды облегчает размещение программы в памяти (логически последовательные команды могут быть размещены в любых свободных участках), но приводит к значительному увеличению длины команды — и потому применима лишь в устройствах с очень небольшой длиной адреса команды, т. е. с маленькой программной памятью. Микропрограммные автоматы обычно компенсируют это ограничение сложной структурой каждой отдельной команды — длина таких команд достигает нескольких сотен битов и, в действительности, они содержат по отдельной команде для каждой из функциональных подсистем автомата. Но все равно, сложность программ для таких устройств невелика по сравнению с программами для фон-неймановских процессоров общего назначения, и их часто называют не программами, а микрокодом.
Программируемые логические матрицы (ПЛМ), микропрограммные автоматы и фон-неймановские процессоры представляют собой непрерывный спектр устройств возрастающей сложности — причем далеко не всегда можно с уверенностью отнести конкретное устройство к одной из перечисленных категорий. Простая ПЛМ не может сохранять предыдущее состояние и способна только преобразовывать текущие состояния своих входов в состояния своих выходов. Замкнув некоторые из выходов ПЛМ на некоторые из ее входов через простое запоминающее устройство (регистр) мы получаем более сложное устройство, обладающее памятью. Простые микропрограммные автоматы реализуются на основе ПЛМ и нескольких регистров. Более сложные автоматы содержат много регистров и специализированные функциональные устройства, такие, как счетчики и сумматоры.
Типичный современный фон-неймановский процессор общего назначения, такой, как Pentium VI, представляет собой сложный микропрограммный автомат, микрокод которого интерпретирует коды команд х86.
С помощью процессора, не имеющего команд перехода, нельзя реализовать алгоритм, который имел бы циклы или условные операторы. Следовательно, такой "процессор" пригоден лишь для осуществления вычислений по фиксированной формуле или генерации фиксированных последовательностей сигналов. В наше время такие функции обычно реализуются при помощи программируемых логических матриц.
Многопроходное ассемблирование
Многопроходное ассемблирование
При ассемблировании с использованием меток возникает специфическая проблема: команды могут ссылаться на метки, определенные как до, так и после них по тексту программы. Следовательно, операндом команды может оказаться метка, которая еще не определена. Адрес, соответствующий этой метке, еще неизвестен, поэтому мы должны будем, так или иначе, вернуться к ссылающейся на нее команде и записать адрес. Эта же проблема возникает и при компиляции ЯВУ: предварительное определение переменных и процедур указывает тип переменной и количество и типы параметров процедуры, но не их размещение в памяти, а именно оно нас и интересует при генерации кода.
Две техники решения этой проблемы называются одно- и двухпроходным ассемблированием [Баррон 1974].
При двухпроходном ассемблировании, на первом проходе мы определяем адреса всех описанных в программе символов и сохраняем их в промежуточной таблице. На втором проходе мы осуществляем собственно ассемблирование — генерацию кода и расстановку адресов. Если адресное поле имеет переменную длину, определение адреса метки может привести к изменению длины ссылающегося на нее кода, поэтому на таких архитектурах оказывается целесообразным трех- и более проходное ассемблирование. При однопроходном ассемблировании, мы запоминаем все точки, из которых происходят ссылки вперед, и, определив адрес символа, возвращаемся к этим точкам и записываем в них адрес. При однопроходном ассемблировании целесообразно хранить код, в котором еще не все метки расставлены, в оперативной памяти, поэтому в старых компьютерах двухпроходные ассемблеры были широко распространены. Впрочем, современные многопроходные ассемблеры также хранят промежуточные представления программы в памяти, поэтому количество проходов в конкретной реализации ассемблера представляет разве что теоретический интерес.
Нейросети
Нейросети
Впрочем, существуют весьма сложные системы, представляющие собой набор примитивных "процессоров", не имеющих команд перехода, — речь идет о так называемых нейросетях. Идея нейросетей была позаимствована у нервных систем высших животных, которые представляют собой сложносоединенную сеть специализированных клеток, нейронов. Каждый нейрон представляет собой довольно примитивное аналоговое устройство, пороговый сумматор: он имеет много (иногда много тысяч) входов и один выход. Каждый вход нейрона имеет свой вес, возможно отрицательный. Нейрон суммирует сигналы со всех
своих входов с учетом их весов, и, если результат превосходит некоторый порог, начинает генерировать сигнал на выходе. Суммирование бывает как линейное, так и нелинейное, когда вместо самого сигнала используется некоторая монотонная его функция. Например, если в качестве функции использовать логарифм, нейрон из сумматора превратится в умножитель.
Кажущаяся примитивность одиночного нейрона компенсируется их большим количеством, сложной системой связей между нейронами и их способностью "обучаться", изменяя коэффициенты входов (веса) и пороговое значение. Биологические нейросети могут расти, создавая дополнительные соединения. Некоторые комплексы биологических нейронов имеют фиксированную структуру связей и записанные на генетическом уровне веса. Простые поведенческие реакции, обусловленные такими нейронами, называют безусловно-рефлекторными, а сложные комплексы таких реакций — инстинктом.
Нейрофизиологические исследования показывают, что, во всяком случае, первичный анализ видимого изображения (выделение контуров, объединение их в фигуры) мозг млекопитающих осуществляет как нейросеть. Есть весьма убедительные доводы в пользу того, что остальные функции мозг выполняет по тому же принципу — хотя точная анатомическая локализация многих функций восприятия, распознавания образов, мышления, памяти и координации движений до сих пор неизвестна, в мозге пока не обнаружены структуры, которые могли бы работать иначе, чем нейросеть.
Успехи биологических нейросетей поражают воображение разработчиков электронных вычислительных и управляющих систем. Даже если отвлечься от часто упоминаемых в литературе задач распознавания образов, задача координации движений в том виде, в каком ее решает мозг млекопитающих, выходит далеко за пределы возможностей самых современных вычислительных систем.
Действительно, тело млекопитающего (например, человека) с точки зрения теоретической механики представляет собой систему многих тел (туловища, головы, сочленений конечностей), связанных вязко-упругими соединениями (мышцами и сухожилиями). При этом далеко не все эти тела можно адекватно описать как твердые: тот факт, что туловище способно изгибаться и скручиваться, используется человеком почти во всех движениях и для сохранения равновесия, и для придания движению дополнительного усилия, и для других целей. Даже самая примитивная модель "палочного человечка" с жестким туловищем состоит из четырнадцати элементов: головы, туловища и четырех конечностей, каждая из которых имеет по три сочленения. Казалось бы, немного, но движение каждого из этих элементов описывается шестью переменными: перемещение центра масс по трем координатам и вращение в трех плоскостях.
Таким образом, полное движение "палочного человечка" описывается восемьюдесятью четырьмя переменными. Для адекватного описания нам надо использовать не только сами переменные, но и их первые производные по времени, линейные и угловые скорости и соответствующие им импульсы и моменты импульса, так что переменных получается 168.
Для примера, большинство задач, решаемых в ВУЗовских курсах физики и теоретической механики, описывает одно- или двухмерное движения материальных точек или одиночных твердых тел, т. е. имеет дело с двумя или четырьмя "координатами" и, соответственно, четырьмя или восемью переменными. При решении уравнений, описывающих даже такие системы, есть место подвигу. Алгоритмы же решения систем дифференциальных уравнений большой размерности содержат шаги, вычислительная стоимость которых быстро — быстрее, чем экспоненциально— растет с увеличением размерности системы. Пользуясь методами теоретической механики, можно относительно легко записать систему дифференциальных уравнений, описывающую движения "палочного человечка". Решить же эту систему ни аналитически, ни численно за приемлемое время невозможно. Причем мы еще не учли в нашей модели нелинейных вязко-упругих связей между отдельными частями тела! А человеческий мозг решает эту задачу в полном виде и в режиме реального времени, причем не только для сложных движений, таких, как танец или боевые искусства, но и для таких повседневных действий, как вставание со стула, выполнение одного шага или поднесение ложки ко рту. Следует отметить, что решение этой задачи обычно не отвлекает сколько-нибудь значительной доли вычислительных ресурсов мозга, так что мы можем без труда одновременно идти, созерцать окружающий пейзаж (распознавание зрительных образов тоже не самая вычислительно дешевая задача) и размышлять о чем-нибудь.
Относительная легкость, с которой человек осваивает новые типы движений, даже такие, которые меняют механику его тела (т. е. изменяют систему дифференциальных уравнений, которая описывает поведение тела как механической системы), — езда на велосипеде, лыжах, роликовых коньках, работа простыми инструментами — или те, которые позволяют использовать механику чего-то совсем другого (управление автомобилем или летательным аппаратом), показывает, что врожденной является способность предсказывать движение и управлять поведением сложных механических систем вообще, а не только собственного тела. Эта же легкость, возможно, свидетельствует также и о том, что при решении этих задач в мозгу не происходит ничего даже отдаленно похожего на запись и решение системы многомерных дифференциальных уравнений.
Технические нейросистемы (или, если угодно, имитации нейросистем) достигли гораздо меньших успехов. Основная сфера применения компьютерных нейро-симуляторов — поиск корреляций в статистических и экспериментальных данных. Наибольший коммерческий успех имели аппаратно реализованные папиллярные детекторы и системы автофокусировки видео- и фотокамер, задача которых — крутить объектив, пока количество четких контуров в изображении не станет максимальным. На любительских видеосъемках, а иногда и в прямом эфире коммерческого телевещания, встречаются забавные моменты, когда такой автофокус настраивает резкость совсем не на тот элемент сцены, который хочет запечатлеть оператор, а на посторонний предмет, в изображении которого много мелких элементов, — крону дерева или что-нибудь в этом роде.
В нервных системах высших животных можно выделить функциональные подсистемы, которые с определенной натяжкой сопоставляются с теми или иными модулями компьютерных ОС. Так, например, есть нейрофизиологические свидетельства, что лобные доли коры больших полушарий головного мозга млекопитающих отвечают за его способность отложить деятельность, направленную на достижение какой-то одной цели, и переключиться на что-то другое, не забывая, однако, ни о предыдущей деятельности, ни о предыдущей цели. Это неплохо коррелирует с тем фактом, что человек, у которого лобные доли развиты до беспрецедентного в животном мире размера, способен также и к построению беспрецедентных по сложности цепочек, направленных на достижение целей окольными путями. Например, какому из животных придет в голову,
что гарантированного ежедневного питания и многих других материальных вознаграждений можно достичь посредством изучения современных операционных систем? У людей, впрочем, способность строить сложные цепочки промежуточных действий и промежуточных целей иногда доходит и до патологических явлений, когда забывается начальная (или, наоборот, конечная) цель, ради которой все затевалось. В связи с этим нельзя не вспомнить знаменитую реплику Льва Троцкого: "цель — ничто, движение — все".
Лобные доли можно — как признавалось выше, с определенной натяжкой — сопоставить с планировщиком многозадачной ОС. Понятно, что натяжка здесь столь велика, что вряд ли такое сопоставление сильно поможет нам в понимании того, что же такое планировщик, и как он устроен.
Несмотря на определенное родство решаемых задач, нейросети радикально отличаются от фон-неймановских компьютеров. Главное отличие состоит в том, что нейросеть не имеет ничего даже отдаленно похожего на программу в фон-неймановском смысле. Обсуждение, а также изучение реализаций биологических нейросетей и разработка нейросетей технических — занятие очень интересное и ему посвящено несколько научных и инженерных дисциплин, но это занятие увело бы нас далеко в сторону от темы нашей книги.
Относительные переходы в системе команд SPARC
Относительные переходы в системе команд SPARC
У большинства CISC-процессоров адресное смещение в командах условного перехода ограничено одним байтом. У SPARC такие команды используют адресное поле длиной 22 бита. С учетом того факта, что команды у SPARC всегда выровнены на границу слова (4 байта), такая адресация позволяет непосредственно указать до 4М (4х220=4 194 304) команд или 16 Мбайт, т.е. целиком адресовать сегмент кода большинства реально используемых программ (Рисунок 2.14).
Переключатель банков
Рисунок 2.16. Переключатель банков

Порядок байтов в слове
Рисунок 2.5. Порядок байтов в слове
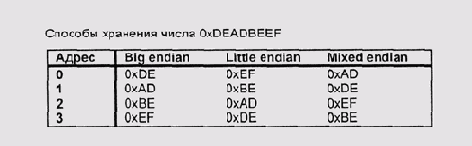
Возможные различия в порядке байтов следует принимать во внимание при разработке форматов для передачи данных по сети или сохранения в файле. Кроме того, некоторые ошибки программирования (например, неявное преобразование указателя на байт в указатель на 16- или 32-битовое целое число) относительно безобидны на машинах, у которых младший байт первый, и приводят к немедленным катастрофическим результатам на компьютерах, использующих меньший адрес для старшего байта.
Формирование 64разрядного
Пример 2.1. Формирование 64-разрядного значения на SPARC v9, цит. по [docs.sun.com 806-3774-10]
! reg — промежуточный регистр, rd — целевой.
sethi %uhi(value), reg
or reg, %ulo(value), reg
sllx reg,32,reg ! сдвиг на 32 бита
sethi %hi(value), rd
or rd, reg, rd
or rd, %lo(value), rd
"Короткие литералы" разного рода нередко используются и в других процессорах, особенно имеющих большую разрядность. Действительно, большая часть реально используемых констант имеет небольшие значения, и выделение под каждую такую константу 32- или, тем более, 64-разрядного значения привело бы к ненужному увеличению кода.
Обращение к переменной
Пример 2.2. Обращение к переменной на процессоре SPARC
| sethi %hi(var), %g1 | ! | помещаем старшие биты адреса в %g1 |
| Id [%gl+%lo(var)], %11 | ! | загружаем значение в %11 |
| inc %11 | ! | производим операцию |
| st %11, [%gl+%lo(var)] | ! | сохраняем результат. |
В модулях, содержащих много обращений к переменным, рекомендуется выделить для этой цели регистр и использовать смещения относительно него — как, кстати, и сделано в приведенном примере. Но это уже совсем не абсолютная адресация.
Использование стека
Пример 2.3. Использование стека для хранения промежуточных значений
void swap(int &a, int &b) {
int t;
t=a;
a=b;
b=t;
}
;Для простоты мы не рассматриваем механизм передачи параметров
; и считаем, что они передаются в регистрах А и В
.GLOBL swap
swap:
POSH (A)
MOVE (B) , (A)
POP (B)
RET.
Одно из основных назначений стека в регистровых архитектурах — это сохранение адреса возврата подпрограмм. Кроме того, если принятое в системе соглашение о вызовах подпрограмм предполагает, что вызываемая процедура должна сохранить все или некоторые регистры, которые использует сама, стек обычно применяют и для этого.
Неортогональные процессоры, такие, как х86, часто предоставляют специальные команды PUSH и POP, работающие с выделенным регистром SP (Stack Pointer), который не может быть использован для других целей.
Формирование использование
Пример 2.4. Формирование, использование и уничтожение стекового кадра. Код на языке С и результат его обработки GNU С 2.7.2.1 (комментарии автора)
#include <stdio.h>
# include <strings.h>
/* Фрагмент примитивной реализации сервера SMTP (RFC822) */
int parse_line(FILE * socket)
{
/* Согласно RFC822, команда имеет длину не более 4 байт,а вся строка — не более 255 байт V char cmd[5], args [255]; fscanf (socket, "%s %s\n", cmd, args);
if (stricmpfcmd, "HELO")==0) {
fprintf (socket, "200 Hello, %s, glad to meet you\n", args);
return 200;
)
/* etc */
fprintf (socket, "500 Unknown command %s\n", cmd);
return 500;
.file "sample" gcc2_compiled. : _ gnu_compiled_c : .text LCO:
.ascii "%s %s\12\0" LCI:
.ascii "HELCAO" LC2:
.ascii "200 Hello, %s, glad to meet you\12\0" LC3:
.ascii "500 Unknown command %s\12\0"
.align 2, 0x90 .globl _parse_line _parse_line:
; x86 имеет для этой цели специальную команду enter, но она может ; формировать кадры размером не более 255 байт. В данном случае кадр ; имеет больший размер, и его необходимо формировать вручную.
pushl %ebp ; Сохраняем указатель кадра
; вызвавшей нас подпрограммы.
movl %esp, %ebp ; Формируем указатель нашего кадра
subl $264,%esp ; И сам кадр. ; Конец пролога функции
leal -264 (%ebp) , %еах ; Помещаем в стек указатель на args • pushl %eax
leal -8 (%ebp) , %еах ; ... на cmd
pushl %eax
pushl $LCO ; на строковую константу
; Наши собственные параметры тоже адресуются относительно кадра. movl 8(%ebp),%eax ; Параметр socket мы тоже проталкиваем pushl %eax ; в стек
call fscanf ; Вызов (параметры в стеке) addl $16,%esp ; очищаем стек
; в языке С переменное количество параметров, поэтому вычищать их из
; стека должна вызывающая процедура. Вызываемая просто не знает,
; СКОЛЬКО ИХ бЫЛО.
pushl $LC1
leal -8(%ebp),%eax
pushl %eax
call _stricmp
addl $8,%esp
movl %eax,%eax ; выключенная оптимизация в действии :)
; А ведь недалеки времена, когда компиляторы только такое и умели ; генерировать.
testl %eax,%еах
jne L14
leal -264(%ebp),%еах
pushl %eax
pushl $LC2
movl 8(%ebp),%eax
pushl %eax
call _fprintf
addl $12,%esp
; Обратите внимание, что компилятор не стал генерировать второй эпилог ; функции на втором операторе return.
movl $200,%eax
jmp L13
» Выравнивание потенциальных точек перехода на границу слова полезно: » процессор не будет тратить дополнительный цикл шины на чтение » невыровненной команды. Для выравнивания используется команда NOP ; (код операции 0x90).
align 2,0x90 L14:
leal -8(%ebp),%еах
Pushl %eax
Pushl $LC3
movl 8(%ebp),%eax pushl %eax
call _fprintf
addl ?12,%esp
movl $500,%eax
jmp L13
.align 2,0x90 L13:
; Команда leave совершает действия, обратные прологу функции: ; Она эквивалентна командам: move %ebp, %esp; pop %ebp. ; Размер кадра явным образом не указывается, поэтому ограничений ; на этот размер в данном случае нет.
leave
ret
Реализация условного
Пример 2.5. Реализация условного перехода с длинным смещением
Beq distant_label ; Перейти, если равно
; реализуется как
Bneq $1 ; Перейти, если не равно
Jmp distant_label
; У команд безусловного перехода обычно используется длинное смещение
; или абсолютный адрес
$1:
Эквивалентные преобразования
Пример 2.6. Эквивалентные преобразования программы
/* Пример возможной стратегии оптимизации.
* Код, вставляемый компилятором для проверки границ индекса,
* выделен при помощи нестандартного выравнивания. */
int array[100];
int bubblesort(int size) ) int count; do {
count=0;
for(i=l; i<100; i++) {
if (i<0 || i>100) raise(IndexOverflow); if (i-l<0 || i-l>100) raise(IndexOverflow); if (array[i-1]<array[i]) { if (i<0 || i>100) raise(IndexOverflow);
int t=array[i];
if (i<0 || i>100) raise(IndexOverflow); if (i-l<0 || i-l>100) raise(IndexOverflow);
array[i]=array[i-1];
if (i-l<0 II i-l>100) raise(IndexOverflow); array[i-1]=t; count++; I
while (count != 0) ;
// оптимизированный внутренний цикл может выглядеть так: register int *ptr=array; register int *limit=ptr; register int t=*ptr++;
if (size<100) limit+=size; else limit+=100;
while (ptr<limit) { if (t<*ptr) { ptr[-l]=*ptr;
*ptr++=t; count++; ) else t=*ptr++;
}
if (size>100) raise (IndexOverf low) ;
По мере распространения в мини- и микрокомпьютерах кэшей команд и данных, а также конвейерного исполнения команд, объединение множества действий в один код операции стало менее выгодным с точки зрения производительности.
Это привело к радикальному изменению взглядов на то, каким должен быть идеальный процессор, ориентированный на исполнение откомпилированного кода. Во-первых, компилятору не нужна ни бинарная, ни даже ассемблерная совместимость с чем бы то ни было (отсюда "рациональность"). Во-вторых, ему требуется много взаимозаменяемых регистров — минимум тридцать два, а на самом деле чем больше, тем лучше. В-третьих, сложные комбинированные команды усложняют аппаратуру процессора, а толку от них все равно нет, или мало.
Коммерческий успех процессоров, построенных в соответствии с этими взглядами (SPARC, MIPS, PA-RISC) привел к тому, что аббревиатура
USC стала употребляться к месту и не к месту — например, уже упоминавшийся Transputer (имевший регистровый стек и реализованный на Уровне системы команд планировщик, т. е. являющийся живым воплощением описанного ранее CISC-подхода) в документации называли RISC-процессором, фирма Intel хвасталась, что ее новый процессор Pentium построен на RISC-ядре (что под этим ни подразумевалось?) и т. д.
Пример использования
Пример 2.7. Пример использования макроопределений
; Фрагмент драйвера LCD для микроконтроллера PIC
; (с) 1996, Дмитрий Иртегов.
;
Реализация литеральной адресации
Рисунок 2.13. Реализация литеральной адресации через постинкрементную адресацию счетчиком команд

Использование счетчика команд в косвенно-регистровом режиме со смещением позволяет адресовать код и данные относительно адреса текущей команды. Такой режим адресации называется относительным. Программный модуль, в котором используется только такая адресация, позиционно независим: его можно перемещать по памяти, и он даже не заметит факта перемещения, если только не получит управление в процессе самого перемещения, или не будет специально проверять адреса на совпадение. Впрочем, почти такого же эффекта можно достичь базовой адресацией.
Многие современные процессоры такого режима адресации для данных не предоставляют, зато почти все делают нечто подобное для адресации кода. А именно, во всех современных процессорах команды условного перехода используют именно такую адресацию: эти команды имеют короткое адресное поле, которое интерпретируется как знаковое смещение относительно текущей команды.
Дело в том, что основное применение условного перехода — это реализация условных операторов и циклов, в которых переход осуществляется в пределах одной процедуры, а зачастую всего на несколько команд вперед или назад. Снабжать такие команды длинным адресным полем было бы расточительно и привело бы к ненужному раздуванию кода.
Условные переходы на большие расстояния в коде встречаются относительно редко, и чаще всего их предлагают реализовать двумя командами (пример 2.5).
Регистровое окно SPARC
Регистровое окно SPARC
RISC-процессор SPARC
Регистровый файл SPARC в виде
Рисунок 2.11. Регистровый файл SPARC в виде кольцевого буфера. Регистры CANSAVE и CANRESTORE (цит. по [www.sparc.com v9])

Когда же программа пытается сдвинуть свое окно за описанные границы (в ситуации, изображенной на рис 2.11 это может произойти после вызовов четырех вложенных процедур или после возврата из двух процедур — текущей и соответствующей окну w7), генерируются исключительные состояния заполнения окна (window fill) и сброса окна (window spill). При этом вызывается системная процедура, которая освобождает окна из интервала OTHERWIN, сбрасывая их содержимое в стековые кадры соответствующих процедур и при заполнении восстанавливает содержимое принадлежащего нам окна из соответствующего кадра.
В многозадачной системе заполнение и сброс окна может произойти в любой момент, поэтому пользовательская программа всегда должна иметь по стековому кадру на каждое из используемых ею регистровых окон, а указатель на этот кадр должен всегда лежать в %sp соответствующего окна. При этом очень важно, чтобы создание стекового кадра и сдвиг регистрового окна производились одной командой.
Регистровый стек процессора SPARC
Рисунок 2.9. Регистровый стек процессора SPARC

Для этого вызванная процедура уменьшает (если стек растет вниз) указатель стека на количество байтов, достаточное, чтобы разместить переменные. Адресация этих переменных у некоторых процессоров (например, у PDP-11) происходит относительно указателя стека, а у большинства — например, у МС680хО и VAX, с большим количеством регистров или у х86, указатель стека которого нельзя использовать для адресации со смещением — для этой цели выделяется отдельный регистр (Рисунок 2.10, пример 2.4).
Регистры
Регистры
Процессор соединен с банками памяти шиной, по которой за один раз передается только одно целое число. Иногда разрядность этой шины тоже называют разрядностью процессора. Тогда 16-разрядный i8088 оказывается 8-разрядным, 32-разрядные MC68000 и 180386SX -- 16-разрядными, а младшие модели современных 64-разрядных RISC-процессоров — 32-разрядными. Для разработчиков аппаратуры такая классификация имеет смысл, а разработчиков программного обеспечения она может ввести в заблуждение.
Арифметико-логическое устройство процессора обычно не может оперировать данными, непосредственно размешенными в оперативной памяти: для выполнения арифметической операции нужен доступ одновременно к трем ячейкам памяти, хранящим операнды и результат.
Для решения этой проблемы любой процессор имеет один или несколько регистров — специализированных запоминающих устройств, обычно вмещающих целое число или адрес. Все процессоры имеют как минимум шесть регистров — регистр для адреса текущей команды (счетчик команд), регистр флагов, где хранятся коды арифметических условий и, кроме того, много другой служебной информации (часто этот регистр называют словом состояния процессора), три буферных регистра АЛУ и буферный регистр, в котором хранится текущая команда (Рисунок 2.1).
У современных процессоров количество регистров
Рисунок 2.2. Регистры общего назначения в системе команд х86

У современных процессоров количество регистров измеряется сотнями, а иногда и тысячами. Например, вместо буфера на одну только текущую команду, все без исключения современные процессоры имеют так называемую очередь предварительной выборки команд. У микроконтроллеров PIC и Atmel то, что в спецификациях указано как ОЗУ (у младших моделей 128 или 256 байт, а у старших — много килобайт), фактически представляет собой регистры.
Режимы адресации
Режимы адресации
Операнды команд могут быть как регистрами, так и ячейками памяти. Некоторые архитектуры, например PDP-11 и VAX, допускают произвольное сочетание регистров и ячеек памяти в одной команде. В частности, допустимы команды пересылки из памяти в память и арифметические операции, оба (у двухадресной PDP-11) или все три (у трехадресного VAX) операнда которых расположены в памяти. В других архитектурах, например в х86 и МС680хО только один операнд команды может размещаться в памяти, а второй всегда обязан быть регистром (впрочем, оба эти процессора имеют и отдельные команды память-память, например инструкции групповой пересылки данных). У RISC-процессоров арифметические операции разрешены только над регистрами, а для обращений к памяти выделены специальные команды LD (LoaD, загрузить) и ST (Store, сохранить).
В зависимости от подхода, применяемого в конкретной системе команд, архитектуры подразделяются на память-память, регистр-память и регистр-регистр. Архитектура регистр-регистр привлекательна тем, что позволяет сделать длину команды фиксированной (адресное поле могут иметь только команды LD/ST и команды вызова и перехода) и за счет этого упростить работу дешифратора и логики предварительной выборки команд. При небольшой длине адреса (как у старых компьютеров и современных микроконтроллеров) этим преимуществом обладают и архитектуры регистр-память.
Напротив, процессоры с большим адресным пространством и архитектурами память-память и регистр-память вынуждены иметь команды переменной длины. У процессоров VAX длина команды меняется от одного (безадресная команда) до 61 байта (шестиадресная команда, все операнды которой используют самый сложный из допустимых режимов адресации). Впрочем, пределом экстравагантности в этом смысле является Intel 432, команды которого имели длину, некратную байту. Адресация команд в 1432 происходила с точностью до бита.
По мере роста адресного пространства адресные поля команд, обращающихся к памяти, занимают все большую и большую долю кода. Это является дополнительным стимулом к замене, где это возможно, обращений к памяти на обращения к регистрам. Благодаря этому же, код активно использующих регистры RISC-процессоров, несмотря на гораздо большую длину кодов команд (если у х86 наиболее широко используемые операции кодируются двумя байтами, то у типичного RISC все команды имеют длину 4 байта), ненамного превосходит по объему эквивалентный код для CISC-процессоров. По мере перехода к 64-разрядным адресам, выигрыш в объеме кода может стать преимуществом RISC-архитектур.
На основе сказанного выше, у читателя могло сложиться впечатление, что единственным способом указания адреса операнда в памяти является помещение этого адреса в адресное поле команды. В действительности это не так, или, точнее, не всегда так — в зависимости от режима адресации, адрес операнда может вычисляться различными, иногда довольно сложными способами, с учетом значений одного или нескольких регистров, и как с использованием адресного поля, так и без него.
Большинство современных процессоров поддерживает многочисленные режимы адресации. Как и при работе с регистрами, это может реализоваться двумя путями: ортогональным, когда режим адресации кодируется битовым полем в коде команды, и неортогональным, когда различные режимы адресации соответствуют разным командам.
Поскольку различные режимы адресации могут как использовать адресное поле, так и не использовать его, чтобы реализовать ортогональную систему с командами фиксированной длины, нужно проявить незаурядную фантазию.
Режимы адресации SPARC
Режимы адресации SPARC
У процессоров SPARC адресацию осуществляют лишь четыре группы команд — LD (загрузка слова из памяти в регистр), ST (сохранение значения регистра в памяти), JMPL (переход по указанному адресу и сохранение текущего адреса в регистре) и команды условного перехода. Все остальные команды манипулируют регистрами и константами. Команда длиной 32 бита имеет три битовых поля: два задают 5-разрядные номера регистров, третье — либо регистр, либо 13-разрядное целое число (см. Рисунок 2.3). Команды LD, SP и JMPL имеют такой же формат и позволяют использовать в качестве адреса либо сумму двух регистров, либо регистра и 13-разрядного значения, интерпретируемого как знаковое число в двоично-дополнительной кодировке. Это перекрывает далеко не все перечисленные далее режимы адресации. Многие распространенные режимы адресации на SPARC приходится реализовать с помощью нескольких команд.
Даже классические полностью ортогональные архитектуры — PDP-11, VAX, MC680xO — имеют по крайней мере одно отклонение от полной ортогональности: режим адресации коротким смещением относительно счетчика команд (см. разд. Адресация с использованием счетчика команд, используемый в этих архитектурах в командах условного перехода и недоступный в других командах.
Режимы адресации VAX
Режимы адресации VAX
У процессоров VAX операнды команд кодируются одним байтом. Старшие 4 бита операнда указывают режим адресации, младшие— номер регистра. Если режим предполагает использование адресных полей, эти поля следуют за операндом. При некоторых режимах возможно использование нескольких адресных полей и длина одного операнда, таким образом, может доходить до 10 байт (Рисунок 2.6).
Сложные режимы адресации
Сложные режимы адресации
реди промышленно выпускавшихся процессоров самым богатым набором экзотических режимов адресации обладает VAX. Кроме всех вышеперечисленных, предлагаются следующие. Косвенный с постинкрементом: регистр содержит адрес слова, которое является адресом операнда. После адресации регистр увеличивается на 4. Косвенный со смещением (не путать с косвенно-регистровым со смещением!): регистр со смещением адресует слово памяти, которое содержит адрес операнда — удобен для разыменования указателя без его загрузки в регистр.
Стек на основе массива
Рисунок 2.7. Стек на основе массива

Стек Стек или магазин — это структура
Стек
Стек, или магазин — это структура данных, над которой мы можем осуществлять две операции: проталкивание (push) значения и выталкивание (pop). Значения выталкиваются из стека в порядке, обратном тому, в котором проталкивались: LIFO (Last In, First Out, первый вошел, последний вышел). Стековые структуры находят широкое применение при синтаксическом разборе арифметических выражений и алголоподобных языков программирования [Кормен/Лейзерсон/Ривест 2000].
Самая простая реализация стека — это массив и индекс последнего находящегося в стеке элемента (Рисунок 2.7). Этот индекс называется указателем стека (SP - Stack Pointer). Стек может расти как вверх, так и вниз [(Рисунок 2.8). Широко применяются также реализации стеков в виде односвяз-|ных списков.
Стеки растущие вверх и вниз
Рисунок 2.8. Стеки, растущие вверх и вниз

При реализации стека скалярных значений удобно использовать непрерывную область памяти в качестве массива, регистр SP в качестве указателя и режимы адресации с постинкрементом и предекрементом при реализации команд проталкивания и выталкивания.
Действительно, команда
MOVE x, -(SP)
приведет к тому, что указатель стека уменьшится на размер х, и мы положим х в освободившуюся память. Напротив, команда
MOVE (SP)+, у
приведет к получению значения и продвижению указателя стека в обратном направлении. Поэтому первая команда имеет также мнемоническое обозначение
PUSH х
а вторая
POP у
Если мы поместим несколько значений в стек командой PUSH, команда POP вытолкнет их из стека в обратном порядке. Стек можно использовать для хранения промежуточных данных (см. пример 2.3) и при реализации арифметических выражений — например, команда
ADD (SP)+, (SP)
в точности воспроизводит описанную выше семантику безадресной команды ADD стековой архитектуры. Впрочем, безадресной команде ADD операнды не нужны, а в данном случае они просто не используются, но никуда не исчезают. Команда получается длиннее: у типичной стековой архитектуры команда сложения занимает 1 байт, у PDP-11 ее имитация занимает 2 байта, а у VAX — целых три. Поэтому, если мы хотим использовать стековую технику генерации кода, лучше использовать предназначенный для этого процессор.
Стековые кадры в системе команд SPARC
Стековые кадры в системе команд SPARC
Микропроцессоры SPARC также не могут обойтись без стекового кадра. Во-первых, не всегда локальные переменные процедуры помещаются в восьми 32-разрядных локальных регистрах. Именно такая процедура приведена в примере 2.4. Во-вторых, нередки ситуации, когда в качестве параметров надо передать по значению структуры, для которых 6 регистров-параметров тоже не хватит. В-третьих, глубина регистрового файла ограничена и при работе рекурсивных или просто глубоко вложенных процедур может исчерпаться. В-четвертых, в многозадачной системе регистровый файл может одновременно использоваться несколькими задачами. Все эти проблемы решаются при помощи создания стекового кадра [www.sparc.com v9].
Для этой цели используются регистры Isp (о6) и %fp (i6). Команда save %sp, -96 %sp делает следующее: она складывает первые два операнда, сдвигает стековый кадр и помещает результат сложения в третий операнд. Благодаря такому порядку исполнения отдельных операций, старый %sp становится %fp, а результат сложения помещается уже в новый %sp.
Самую важную роль стековые кадры играют при обработке переполнений регистрового файла. Регистровый файл SPARC представляет собой кольцевой буфер, доступность отдельных участков которого описывается привилегированными регистрами CANSAVE и CANRESTORE. Окна, находящиеся между значениями этих двух регистров, доступны текущей программе (Рисунок 2.11). На рисунке показано состояние регистрового файла, в котором текущий процесс может восстановить один стековый кадр (CANRESTORE=1) и сохранить три (CANSAVE=3). Регистр OTHERWIN указывает количество регистровых окон, занятых другим процессом. Регистровое окно w4 на рисунке (обозначенное как перекрытие) занято лишь частично. Текущее окно, частично занятое окно и участки регистрового файла, описанные перечисленными регистрами, в сумме должны составлять весь регистровый файл, так чтобы соблюдалось отношение CANSAVE + CANRESTORE + OTHERWIN = NWINDOWS - 2, Где NWINDOWS- количество окон (на рисунке регистровый файл имеет 8 окон, т. е. 128 регистров).
Стековый кадр
Рисунок 2.10. Стековый кадр

Примечание
Примечание
Обратите внимание, что программа из примера 2.4 содержит серьезнейшую ошибку. В комментариях сказано, что команда обязана иметь длину не более 4 байт, а вся строка вместе с аргументами не более 255. Если программа-клиент на другом конце сокета (сетевого соединения) соответствует RFC822 [RFC822], так оно и будет. Но если программа требованиям этого документа не соответствует, нас ждет беда: нам могут предложить более длинную команду и/или более длинную строку. Последствия, к которым это может привести, будут более подробно разбираться в главе 12.
Но вернемся к стековым кадрам.
Стековый кадр Стековый кадр является
Стековый кадр
Стековый кадр является стандартным способом выделения памяти под локальные переменные в алголоподобных процедурных языках (С, C++, Pascal) и других языках, допускающих рекурсивные вызовы.
Семантика рекурсивного вызова в алголоподобных языках требует, чтобы каждая из рекурсивно вызванных процедур имела собственную копию локальных переменных. В SPARC это достигается сдвигом регистрового окна по регистровому файлу (Рисунок 2.9), но большинство других процессоров такой роскоши лишены и вынуждены выделять память под локальные переменные в стеке, размещаемом в ОЗУ.
Команды условного
Таблица 2.1. Команды условного перехода микроконтроллеров семейства AVR, цит. по [www.atmel.com]
| Команда | Описание | Условие перехода |
| SBRC Rr, b | Пропустить, если бит в регистре сброшен | if (Rr(b)=0) PC = PC + 2 or 3 |
| SBRS Rr, b | Пропустить, если бит в регистре установлен | if (Rr(b)=1) PC = PC + 2 or 3 |
| SBIC P, b | Пропустить, если бит в регистре В/В сброшен | if (I/0(P,b)=0) PC = PC + 2 or 3 |
| SBIS P, b | Пропустить, если бит в регистре В/В установлен | if (I/0(P,b)=l) PC = PC + 2 or 3 |
| BRBS s, k | Перейти, если статусный флаг установлен | if (SREG(s) =1) PC = PC+k + 1 |
| BRBC s, k | Перейти, если статусный флаг сброшен | if (SREG(s) =0) PC = PC+k + 1 |
| BREQ k | Перейти, если равно | if (Z = 1} PC = PC + k + 1 |
| BRNE k | Перейти, если не равно | if (Z=0) PC = PC + k + 1 |
| BRCS k | Перейти, если перенос установлен | if (C = 1) PC = PC + k + 1 |
| BRCC k | Перейти, если перенос сброшен | if (C = 0) PC = PC + k + 1 |
| BRSH k | Перейти, если равно или выше | if (C = 0) PC = PC + k + 1 |
| BRLO k | Перейти, если ниже | if (C = 1) PC = PC.+ k + 1 |
| BRMI k | Перейти, если минус | if (N = 1) PC = PC + k + 1 |
| BRPL k | Перейти, если плюс | if (N = 0) PC = PC + k + 1 |
| BRGE k | Перейти, если больше или равно, знаковое | if (N XOR V= 0) PC = PC+ k + 1 |
| BRLT k | Перейти, если меньше, знаковое | if (N XOR V= 1) PC = PC + k + 1 |
| BRHS k | Перейти, если полубайтовый перенос установлен | if (H = 1) PC = PC + k + 1 |
| BRHC k | Перейти, если полубайтовый перенос сброшен | if (H = 0) PC = PC + k + 1 |
| BRTS k | Перейти, если Т-флаг установлен | if (T = 1) PC = PC + k + 1 |
| BRTC k | Перейти, если Т-флаг сброшен | if (T = 0) PC = PC + k + 1 |
| BRVS k | Перейти, если флаг переполнения установлен | if (V = 1) PC = PC + k + 1 |
| BRVC k | Перейти, если флаг переполнения сброшен | if (V = 0) PC = PC + k + 1 |
| BRIE k | Перейти, если прерывания разрешены | if (1 = 1) PC = PC + k + 1 |
| BRID k | Перейти, если прерывания запрещены | if (1 = 0) PC = PC + k + 1 |
Таблица знакогенератора 5 байт/символ
Таблица знакогенератора: 5 байт/символ.
; W содержит код символа. Пока символов может быть
; только 50, иначе возникнет переполнение.
; Scanline содержит номер байта (не строки!)
; Сначала определим макрос, а то устанем таблицу сочинять. ; Необходимо упаковать 7 скан-строк по 5 бит в 5 байт.
CharDef macro scanl, scan2, scan3, scan4, scanS, зсапб, scan7 ; Следующий символ
RetLW (scan? & Oxlc) » 2
RetLW ((scan5 E, 0x10) » 4) + ((зсапб S Oxlf) « 1) + ((scan7 & 0x3) «
6)
RetLW ((scan4 & Oxle) » 1) + ((scanb & Oxf) « 4)
RetLW ((scan2 & 0x18) » 3) + ((зсапЗ & Oxlf) « 2) + ( (scan4 & Oxl) « 7)
RetLW (scanl & Oxlf) + ( (scan2 & 0x7) « 5)
endm
FetchOneScanline IFNDEF NoDisplay
ClrF PCLATH
AddWF PCL, 1
NOP ; else
RetLW 0 endif
; А вот идет собственно таблица:
Nolist
; О
CharDef В'OHIO',В110001',В'10001',В'10001',В'10001',В'10001',В'01110' ; 1
CharDef В'00100',В'01100',В'00100',В'00100',В100100',В'00100',В'01110' ; 2
CharDef В'OHIO',В'10001',В'00001',В'00010',В100100',В'01000',В'11111' ; 3
CharDef В'01110',В'10001',В'00001',В'00110',В100001',В110001',В'OHIO' ; 4
CharDef В'00010',В'00110',В'01010',В'10010',В'11111',В'00010', В'00010' ; 5
CharDef В'11111',В'10000',В'11110',В'00001',В'00001',В110001',В1OHIO' ; б
CharDef В'OHIO1,840001' ,В' 10000',В' НПО' ,В' 10001' ,В'10001' ,В'OHIO1 ; 7
CharDef В'11111',В'00001',В'00010',В'00100',В'01000',В'01000',В'01000'
; 8
CharDef В'OHIO', В'10001' ,В'10001' ,В'OHIO' , В'10001', В'10001' ,В'OHIO' ; 9
CharDef В'OHIO', В'10001', В'10001' ,В'01111' ,В'00001' ,В'10001' ,В'OHIO' 4 Зэк Х(,
Constant CharacterA = Oxa
CharDef В ' 00100 ', В ' 01010 ', В ' 10001', В110001' ,841111' , В' 10001' ,В' 10001' Ifndef NO_ALPHABET ; В Constant CharacterW = Oxb
CharDef В'11110',В'10001',B'10001',В'11110' ,В'10001' ,В'10001' ,В'11110' else ; Р — для аона
CharDef В' 11110 ',840001', В '10001', В '10001', В' 11110 ',840000', В '10000' endif ; С
CharDef В'01110',В'10001',В'10000',ВЧОООО',В'10000',В110001',В'01110' ; о
CharDef В' 11110 ',В' 10001 ',В' 10001 ',В' 10001 ',840001', В' 10001 ',841110' ; Е
CharDef B'lllll' ,ВЧ0001', В'10000', В'11110 ' ,В'10000', В'10001' ,В'11111' ; F
CharDef В'11111',В'10001',В'10000',В'11110',В'10ЮОО',В'10000',В'10000'
; пробел Constant SPACE_CHARACTER = 0x10
CharDef В'00000',В'ООООО',В'ООООО',В'00000',В'00000',В100000',В'00000'
Constant DASH_CHARACTER = Oxll
CharDef В'00000',В'00000',В'00000',В'11111',В'00000',В'ООООО',В'ООООО'
List
Макропроцессор, кроме раскрытия макросов, обычно предоставляет также директивы условной компиляции — в зависимости от условий, те или иные участки кода могут передаваться компилятору или нет. Условия, конечно же, должны быть известны уже на этапе компиляции. Например, в зависимости от типа целевого процессора одна и та же конструкция может реализоваться как в одну команду, так и эмулирующей программой. В зависимости от используемой операционной системы могут применяться разные системные вызовы (это чаще случается при программировании на языках высокого уровня), или в зависимости от значений параметров макроопределения, макрос может порождать совсем разный код.
Макросредства есть не только в ассемблерах, но и во многих языках высокого уровня (ЯВУ). Наиболее известен препроцессор языка С. В действительности, многие средства, предоставляемые языками, претендующими на большую, чем у С, "высокоуровневость" (что бы под этим ни подразумевалось), также реализуются по принципу макрообработки, т. е. при помощи текстовых подстановок и компиляции результата: шаблоны (template) C++, параметризованные типы Ada и т. д.
Умелое использование макропроцессора облегчает чтение кода и увеличивает возможности его повторного использования в различных ситуациях. Злоупотребление же макросредствами (как, впрочем, и многими другими мощными и выразительными языковыми конструкциями) или просто бестолковое их применение может приводить к совершенно непонятному коду и трудно диагностируемым ошибкам, поэтому многие теоретики программирования выступали за полный отказ от использования макропроцессоров.
Современные методы оптимизации в языках высокого уровня — проверка константных условий, разворачивание циклов, inlme-функции — часто стирают различия между макрообработкой и собственно компиляцией.
Кроме избавления программиста от необходимости запоминать коды команд, ассемблер выполняет еще одну, пожалуй, даже более важную функцию: он позволяет снабжать символическими именами (метками) или (символами) команды или ячейки памяти, предназначенные для данных. Значение этой возможности для практического программирования трудно переоценить.
Рассмотрим простой пример из жизни: мы написали программу, которая содержит команду перехода (бывают и программы, которые ни одной команды перехода не содержат, но это вырожденный случай). Затем, в процессе тестирования этой программы или уточнения спецификаций мы поняли, что между командой перехода и точкой, в которую переход совершается, необходимо вставить еще два десятка команд. Для вставки необходимо пересчитать адрес перехода. На практике, вставка даже одной только инструкции часто затрагивает и приводит к необходимости пересчитывать адреса множества команд перехода, поэтому возможность автоматизировать этот процесс крайне важна.
Важное применение меток — организация ссылок между модулями в программах, собираемых из нескольких раздельно компилируемых файлов. Изменение объема кода или данных в любом из модулей приводит к необходимости пересчета адресов во всех остальных модулях. В современных программах, собираемых из сотен отдельных файлов и содержащих тысячи индивидуально адресуемых объектов, выполнять такой пересчет вручную невозможно. Способы автоматического решения этой задачи обсуждаются в разд. Сборка программ.
Фаза сопоставления символов с реальными адресами присутствует и при компиляции языков высокого уровня — компилятор генерирует символы не только для переменных, процедур и меток, которые могут быть использованы в операторе goto, но и для реализации "структурных" условных операторов и циклов. Нередко в описании компилятора эту фазу так и называют — ассемблирование.
Многие компиляторы как старые, так и современные, например, популярный компилятор GNU С, даже не выполняют фазу ассемблирования самостоятельно, а вместо этого генерируют текст на языке ассемблера и вызывают внешний ассемблер. Средства межпроцессного взаимодействия современных ОС позволяют передавать этот промежуточный текст, не создавая промежуточного файла, поэтому для конечного пользователя эта деталь реализации часто оказывается незаметной.
Компиляторы, имеющие встроенный ассемблер, такие, как Microsoft C/C++ или Watcom, часто могут генерировать ассемблерное представление порождаемого кода. Это бывает полезно при отладке или написании подпрограмм на ассемблере, которые должны взаимодействовать с откомпилированным кодом.
Типичная структура микропроцессора
Рисунок 2.1. Типичная структура микропроцессора

Из этих регистров программисту доступны только счетчик команд и слово состояния процессора, да и то не всегда. (Под доступностью программисту в данном случае мы подразумеваем возможность указывать регистры в качестве явных и неявных операндов команд).
Регистры, доступные программисту для хранения данных, называются регистрами общего назначения (Рисунок 2.2). Кроме них, процессор обычно имеет множество других регистров. Некоторые из них интересны только проектировщикам аппаратуры, с другими — например, регистрами диспетчера памяти — мы еще встретимся в следующих главах.
Для доступа к регистрам процессору не нужно занимать внешнюю шину Данных, да и цикл доступа к регистру обычно очень короток и совпадает с циклом работы АЛУ. Следовательно, чем больше у процессора регистров, тем быстрее он может работать с оперативными данными. В те времена, когда компьютеры были большими, стремление к увеличению количества регистров упиралось в стоимостные и электротехнические ограничения. У компьютеров первых поколений для реализации регистров использовались отдельные транзисторы или микросхемы малой степени интеграции, Поэтому они стоили гораздо дороже (в расчете на один бит памяти), потребляли гораздо больше энергии и рассеивали гораздо больше тепла, чем ферритовая память. Переход на современные кристаллы высокой интеграции изменил положение, но не принципиально: триггеры, которые используются для реализации регистров, по перечисленным параметрам всегда хуже, чем исполненное по той же технологии динамическое ОЗУ. Поэтому компьютеры первых поколений обычно имели лишь несколько регистров, а мини- и микрокомпьютеры 70-х и начала 80-х прошлого века — не более нескольких десятков.
Выровненные и невыровненные обращения к словам
Рисунок 2.4. Выровненные и невыровненные обращения к словам

Во-вторых, есть разногласия в том, как следует адресовать (или, как следует интерпретировать при арифметических операциях) байты одного слова — по какому адресу находятся старшие 8 битов, а по какому — младшие? У одних Процессоров (IBM/390, MC68000, SPARC) — старший байт располагается по меньшему адресу (big endian), у других (VAX, x86) - по большему (little etidian). Встречаются и процессоры со смешанным порядком байтов, когда, например, из двух байтов полуслова по меньшему адресу расположен младший, а из двух полуслов по меньшему адресу расположено старшее (Рисунок 2.5). Некоторые современные процессоры, например PowerPC, MIPS, SPARC V9 могут работать и с тем, и с другим порядком байтов, причем иногда даже в пределах одной программы.
Вырожденные режимы адресации
Вырожденные режимы адресации
К этой группе относятся режимы, в которых доступ к операнду не содержит адресации как таковой.
Первым из таких режимов является операнд-регистр. Режим этот концептуально крайне прост и в дополнительных комментариях не нуждается.
Второй режим — операнд-константа. В документаииях по многим процессорам этот режим называют литеральной (literal) и немедленной (immediate) адресацией.
Казалось бы, трудно придумать более простой и жизненно необходимый режим. Однако полноценно реализовать такие операнды можно используя либо команды переменной длины, либо команды, которые длиннее слова (чаще всего это бывает у процессоров гарвардской архитектуры, например, уже упоминавшегося PIC).
