Разрядным адресом в котором
32-разрядным адресом, в котором 16 бит задают смещение в сегменте, 14 бит— номер сегмента и 2 бита используются для разных загадочных целей. При этом размер сегмента не более 64 Кбайт, а общий объем виртуальной памяти не превышает 1 Гбайта.
Разрядным адресом в котором
48-разрядным адресом, в котором смещение в сегменте занимает 32 бита. В этом случае размер сегмента может быть до 4 Гбайт, а общий объем виртуальной памяти до 244 байт. В обоих случаях сегмент может быть разбит на страницы по 4 Кбайт.
При этом сегментная часть адреса и его смещение лежат в разных регистрах, и с ними можно работать раздельно. В реальном режиме возможность такой работы порождает весь "зоопарк моделей памяти", с которыми знакомы те, кто писал на С для MS DOS. В защищенном режиме х86 большинство систем программирования выделяют программе один сегмент с 32-разрядным смещением, и программа живет там так, будто это обычная машина с 32-разрядным линейным адресным пространством. Так поступают все известные авторам реализации Unix для х86, ряд так называемых расширителей ДОС (DOS extenders), Oberon/386, Novell Netware, реализации Win32 и т. д.
[Docs sun com 816055910]) При
[docs.sun.com 816-0559-10]). При формировании имен каталогов могут использоваться макроподстановки с использованием следующих переменных.
$ISALIST— список систем команд— полезно на процессорах, поддерживающих несколько систем команд, например х86 и 8086, SPARC 32 и SPARC 64.
$ORIGIN — каталог, из которого загружен модуль. Полезно для загрузки приложений, которые имеют собственные разделяемые объекты.
SOSNAME, $OSREL — название и версия операционной системы.
$PLATFORM— тип процессора. Полезно для приложений, которые содержат в поставке бинарные модули сразу для нескольких процессоров, сетевых установок таких приложений, или сетевой загрузки в гетерогенной среде.
Понятно, что задание простого имени предпочтительнее, так как дает администратору системы значительную свободу в размещении разделяемых библиотек. Впрочем, системный редактор связей Idd позволяет изменять имена внешних ссылок и RPATH в уже построенном модуле, в частности заменяя одни файловые пути на другие, путевые имена на простые и наоборот. Благодаря этому, поставщик приложений для ОС, основанных на формате ELF, имеет гораздо меньше возможностей испортить жизнь системному администратору, чем поставщик приложений для Windows.
По стандартному соглашению, имя библиотеки обязательно содержит и номер версии (в обоих примерах это 1). В соответствии с требованиями фирмы Sun номер версии меняется, только когда интерфейс библиотеки меняется на несовместимый — убираются функции, изменяется их семантика и т. д. Из менее очевидных соображений [docs.sun.com 816-0559-10] требуется менять номер версии и при добавлении функции или переменной: ведь вновь добавленный символ может конфликтовать по имени с символом какой-то другой библиотеки.
Исправление ошибок, т. е. нарушение "bug-for-bug compatibility", основанием для изменения номера версии фирма Sun не считает. Напротив, в Linux принято снабжать разделяемые библиотеки минимум двумя, а иногда и более номерами версий — старшая (major) версия изменяется по правилам, приблизительно соответствующим требованиям Sun, а младшие (minor) — после исправления отдельных ошибок и других мелких изменений.
Благодаря этому соглашению, в системе одновременно может быть установлено несколько версий одного и того же модуля, а пользовательские программы могут ссылаться именно на ту версию, с которой разрабатывались и на совместимость с которой тестировались. Администратор может управлять выбором именно той библиотеки, на которую ссылаются конкретные модули, либо изменяя ссылки в этих модулях при помощи Idd, либо используя символические связи.
[Dz yandex ru] в конце 2000 года
[dz.yandex.ru] в конце 2000 года была серия публикаций и довольно бурная дискуссия о достоинствах и недостатках "персистентных объектов" — объектов в терминах объектно-ориентированного программирования, которые переживают перезагрузки и выключения питания системы. Для хранения таких объектов может использоваться как флэш-память, так и другие формы энергонезависимой памяти, те же жесткие диски. Владелец сайта и инициатор дискуссии, Дмитрий Завалишин, отстаивал тезис о том, что такие объекты представляют собой сокровенную мечту и своего рода Священный Грааль всего программирования и развития вычислительной техники.
Одноуровневая память в Multix
Пионером в реализации одноуровневой памяти была ОС Multix фирмы Honeywell. Эта система была разработана в конце 60-х годов и оказала огромное влияние на развитие вычислительной техники как прямо, так и посредством своего потомка Unix. Несколько машин с этой ОС эксплуатировались и были доступны через Internet (во всяком случае, отвечали на запрос ping) еще в 1997 году.
Multix предоставляла средства отображения файлов на адреса оперативной памяти наравне с более традиционными средствами ввода-вывода. Ранние версии Unix предназначались в том числе и для работы на машинах без диспетчера памяти или с виртуальной памятью на основе базовых регистров, где возможен лишь традиционный ввод-вывод. Однако современные системы этого семейства отчасти вернулись к истокам и также предоставляют этот способ доступа к файлам.
Впрочем, как отмечалось выше, предоставляемый современными Unix-системами mmap скорее представляет собой документированный внутренний интерфейс загрузчика, чем полноценное средство организации одноуровневого доступа: работа с отображенным файлом не полностью прозрачна для пользователя. Например, изменения содержимого отображенного ОЗУ и наоборот, изменения, внесенные в файл с момента отображения, необходимо синхронизовать друг с другом вручную, используя системный вызов msynch. Средства, предоставляемые для этой цели Windows NT/2000/XP, более прозрачны и просты в использовании, но тоже применяются относительно редко.
Для того чтобы понять, возможна ли полностью одноуровневая память, и если да, то в какой мере, давайте сначала установим различия между ОЗУ и наиболее распространенным типом внешней памяти, жестким магнитным Диском.
Во-первых, объем оперативной памяти в современных компьютерах измеряется десятками и сотнями мегабайт, а у систем коллективного пользования Достигает нескольких гигабайт. Характерная емкость жесткого диска начинается с нескольких гигабайт (диски меньшего объема просто не производятся) и заканчивается сотнями гигабайт. Если мы хотим адресовать все это единым образом, мы должны расширить адресное пространство. 32 бит явно недостаточно, 64 бит на ближайшие годы хватит, но рост емкости дисковых массивов идет по экспоненте.
Впрочем, расширение адресного пространства само по себе не представляет большой проблемы — мало 64 бит, сделаем 128, тем более что речь идет не об адресной шине процессора, используемой только для адресации ОЗУ а о виртуальном адресе. Современные технологии без особых проблем позволяют упаковать арифметико-логическое устройство и регистры такой разрядности в один кристалл, сделать корпус с надлежащим числом ног, печатную плату, в которую можно впаять такой корпус и автоматическую линию, которая будет распаивать корпуса по платам. Да, это будет не Spectrum, вручную не спаяешь — но и материнскую плату современного PC-совместимого компьютера вручную невозможно развести и спаять. Ну и что?
Во-вторых, оперативная память теряет свое содержимое при выключении питания, а жесткий диск — сохраняет, поэтому нередко используется еще одна характеристика дисковой памяти как противопоставление оперативной — постоянная память. Можно вспомнить и о промежуточных решениях, например о флэш-памяти и ее аналогах, которые адресуются почти как ОЗУ, а данные хранят почти как жесткий диск. Наличие промежуточных решений наводит на мысль, что особых проблем "с этой стороны ждать не приходится. На самом деле, проблема здесь есть, но обсудим мы ее чуть позже.
В-третьих, и это связано сразу с обеими вышеназванными причинами, человек снисходит до ручного наведения порядка на диске (удаления мусора и пр.) гораздо чаще, чем до выполнения той же операции в ОЗУ. Поэтому жесткие диски обычно снабжаются еще одной схемой адресации, ориентированной на использование человеком: когда вместо адреса, представляемого целым числом, используется символическое имя.
Трансляция имени в адрес (сектор, поверхность и дорожку жесткого диска) осуществляет файловая система. Вопросы организации файловых систем, каталогов и управления структурами свободной и занятой дисковой памяти обсуждаются в главе 10.
Единственная из используемых в настоящее время архитектур, предоставляющая "честную" одноуровневую память, AS/400, имеет два представления указателя, неразрешенное — с именем в качестве селектора сегмента, и разрешенное — с бинарным представлением этого селектора. Можно себе представить и другие механизмы трансляции имен в адреса, например получение указателя посредством исполнения системного вызова
void *resolve(char * object_name, int flags)
или чего-нибудь в этом роде. Особых технических проблем это не представляет, вопрос в том, надо ли это.
Изложение одного из доводов в пользу того, что это надо далеко не всегда, мы предлагаем начать издалека, а именно с весьма банального тезиса, что писать программы без ошибок человечество до сих пор не научилось и вряд ли научится в обозримом будущем. Исполнение программы, содержащей ошибки, может порождать не только обращения по неверным указателям и выход за границы массивов (наиболее разрушительные типы ошибок, от которых сегментные и страничные диспетчеры памяти предоставляют определенную защиту), но и более тонкие проблемы — фрагментацию и/или утечку свободной памяти и различные рассогласования (в СУБД применяют более точный термин — нарушения целостности данных).
Накопление этих ошибок рано или поздно приводит к тому, что программа теряет способность функционировать. Потеря этой способности может быть обнаружена и пользователем ("что-то прога глючит", "зависла"), и системой (исчерпание квоты памяти или других ресурсов, превышение лимитов роста своп-пространства или доступ по недопустимому адресу), и даже самой программой — если существуют формальные критерии целостности данных, в различных местах кода могут встречаться проверки этих критериев.
Учебники по программированию, например [Дейкстра 1978], настоятельно рекомендуют вырабатывать такие критерии и вставлять соответствующие проверки везде, где это целесообразно. Понятно, что забывать о здравом смысле и вставлять их после каждого оператора, или даже лишь перед каждой операцией, для исполнения которой требуется целостность, далеко не всегда оправдано с точки зрения производительности, так что при реальном программировании надо искать баланс.
Иногда в ходе таких проверок даже удается восстановить целостность (примеры алгоритмов проверки и восстановления структур файловой системы приводятся в главе 12), но очевидно, что далеко не всегда это возможно. В этом случае остается лишь проинформировать пользователя, что у нас "Assertion failed" (предположение нарушено) и по возможности мирно завершиться.
Сохранять при этом данные в постоянную память опасно: если мы не можем восстановиться, мы часто не можем и знать, насколько далеко зашло нарушение целостности, поэтому сохранение чего бы то ни было в таком состоянии чревато полной или частичной (что тоже неприятно) потерей информации. В частности, именно из этих соображений ОС общего назначения, обнаружив ошибку в ядре, сразу рисуют регистры на консоли (рискуя при этом целостностью файловых систем и пользовательских данных), а не предлагают пользователю предпринять какие-либо меры пс сохранению данных.
Смысл останова задачи или всей системы с последующим ее перезапуском состоит в том, чтобы заново проинициализировать структуры данных, используемые при работе программного обеспечения. Это действие можно описать ка!
"контролируемое забывание" всего плохого, что накопилось в памяти за время работы программы, и начало с более или менее чистого листа.
Сервис автоматического перезапуска в различных формах предоставляется многими приложениями, ОС и даже аппаратными архитектурами.
Например, практически обязательным элементом современных микроконтроллеров является watchdog timer (сторожевой таймер, дословно — "сторожевая собака"), часто работающий от собственного осциллятора, а не от общего тактового генератора машины. Программа микроконтроллера должна периодически сбрасывать сторожевой таймер, иначе, досчитав до конца, он делает вывод, что программа "зависла" и инициирует системный сброс.
Именно сторожевой таймер несколько раз перезагружал бортовой компьютер посадочного модуля "Аполлона-И" и, по-видимому, спас этим жизни астронавтов и лунную программу США [NASA 182505].
Аналогичные схемы часто применяются во встраиваемых приложениях, особенно ориентированных на длительную автономную работу. Действительно, встраиваемое приложение может оказаться в весьма неприятном для человека месте, например, вблизи от активной зоны реактора или ускорителя (понятно, что для таких применений необходимо специальное исполнение микросхем, например на сапфировой подложке). В этих случаях иногда выводят кнопку системного сброса в "чистые" области многометровым кабелем. Но, скажем, для управляющего компьютера космического аппарата такое решение просто нереализуемо. Бывают и ситуации, когда выводить кнопку системного сброса наружу нежелательно по более банальным, эргономическим и т. д., соображениям, например из-за опасности случайного нажатия.
О чем-то аналогичном такому сервису часто мечтают администраторы серверов. В Новосибирском FIDO однажды вполне серьезно обсуждалась такая схема автоматизированного перезапуска: сервер каждые пять минут перепрограммирует источник бесперебойного питания на то, чтобы он через десять минут от текущего момента выключился и снова включился. В FIDO встречаются описания и более экстравагантных решений, например "деглюкатор" (устройство, включаемое в шину ISA и по запросу программы выполняющее сброс внешнего модема) или рычажный механизм, посредством которого компьютер, выдвинув поднос CD-ROM, может сам себе нажать на кнопку сброса (полезен в ситуациях, когда система еще условно работоспособна, но с высокой вероятностью может "зависнуть" при попытке нормальной перезагрузки).
Понятно, что все вышеперечисленные решения не могут заменить собой отладку и исправление ошибок в прикладных и системных программах И являются скорее последней линией обороны (если даже не действиями, предпринимаемыми от отчаяния) в борьбе с системными сбоями. Но пока человечество не научится писать программы без ошибок, возможность "привести в чувство" обезумевшую программу путем ее перезапуска остается жизненно необходимой.
Понятно также, что если программа полностью сохраняет свое состояние в постоянной памяти, ее перезапуск нам ничем не поможет: программа честно восстановит весь тот мусор, который накопился в ее сегментах и файлах данных за время предыдущей сессии, и честно воспроизведет снова тот сбой, из-за которого и потребовался рестарт.
В этом смысле крайне желательно держать под контролем перенос данных из постоянной памяти в оперативную, а особенно в обратном направлении избегая его полной "прозрачности". Каждая дополнительная точка сохранения состояния системы повышает риск воспроизведения сбоя или даже возникновения новых проблем, порожденных в файлах сохранения состояния во время чрезмерно "жесткого" перезапуска.
[Redbooks ibm com sg242222 pdf)
[redbooks.ibm.com sg242222.pdf). Пользовательские программы имеют общее адресное пространство. Первоначально это общее пространство имен, в процессе же преобразования имени в адрес бинарное представление селектора сегмента снабжается и битами доступа, которые затем обрабатываются точно так же, как в машинах Burroughs, и точно так же недоступны пользовательскому коду для модификации.
Реализации языка С для этой архитектуры допускают использование указателей только в пределах одного сегмента кода или данных, но не позволяют формировать средствами С произвольные селекторы сегментов, остальные же языки, используемые на этой платформе (Cobol, RPG, языки хранимых процедур СУБД) вообще не имеют указателя как понятия.
Еще дальше в том же направлении продвинулись разработчики фирмы Intel, создавая экспериментальный микропроцессор 1АРХ432, описанный в следующем разделе.
х86 может работать
Адресное пространство х86
х86 может работать с двумя типами адресов:
Адресное пространство VAX
Рисунок 5.7. Адресное пространство VAX
Системная таблица страниц одна во всей системе и содержится в адресных пространствах всех задач. Напротив, пользовательские таблицы у каждой задачи свои (внимательный читатель может отметить определенную параллель между этой структурой и описанным в разд. Банки памяти переключателем банков памяти, который присутствует во всех банках). Для того чтобы упростить системе управление пользовательскими таблицами дескрипторов, эти таблицы хранятся не в физическом, а в виртуальном системном адресном пространстве, и при доступе к ним происходит двойная трансляция адреса.
Ядро системы, таким образом, присутствует в адресных пространствах всех задач. Многие системные модули (например, функция для получения текущего реального времени) доступны для чтения из пользовательского режима и могут вызываться непосредственно, как обычные процедуры. Адреса точек входа этих процедур размещены в специальной таблице в начале системного адресного пространства (Рисунок 5.8). Другие системные модули (например, подсистема работы с файлами, RMS — Record Management Service (Служба управления записями)) требуют повышения уровня доступа: действительно, если одна из задач работает с файлами с ограниченным доступом, было бы неразумно позволять всем остальным задачам видеть используемые при этом системные буферы. Точки входа этих процедур размещаются в той же таблице, что и прямо вызываемые системные подпрограммы, но тела этих процедур состоят только из двух команд: переключения режима процессора и возврата.
Автору известен только один процессор,
Архитектура 1432
Автору известен только один процессор, пригодный для полноценной реализации взаимно недоверяющих подсистем: JAPX432 фирмы Intel. Вместо создания системной базы данных о множественных ссылках на объекты, специалисты фирмы Intel усложнили диспетчер памяти и соответственно алгоритм разрешения виртуальных адресов.
Виртуальный адрес в 1432 состоит из селектора объекта и смещения в этом объекте. Селектор объекта ссылается на таблицу доступа текущего домена. Домен представляет собой программный модуль вместе со всеми его статическими и динамическими данными (Рисунок 5.12). По идее разработчиков, домен соответствует замкнутому модулю языков высокого уровня, например пакету (package) языка Ada.
Блоксхема алгоритма диспетчера памяти
Рисунок 5.3. Блок-схема алгоритма диспетчера памяти
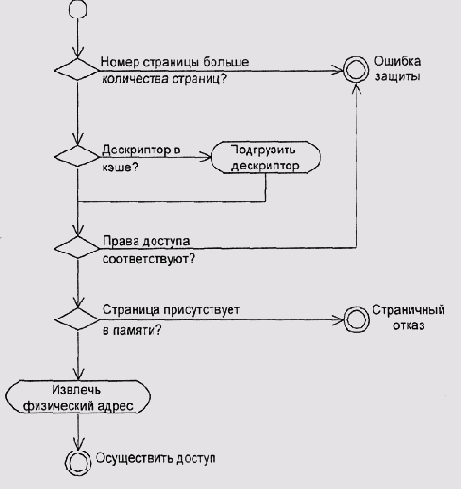
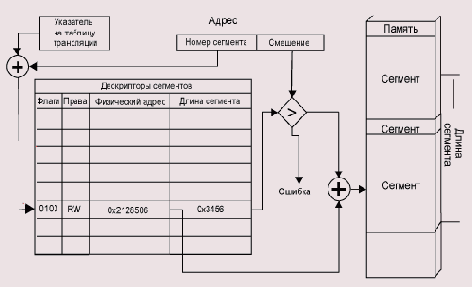
Проверить, существует ли страница page вообще. Если страницы не существует, возникает особая ситуация ошибки сегментации (segmentation violation) (понятие особой ситуации (исключения) подробнее разбирается в Разд.6). Попытаться найти дескриптор страницы в кэше. Если его нет в кэше, загрузить дескриптор из таблицы в памяти. Проверить, имеет ли процесс соответствующее право доступа к страпице Иначе также возникает ошибка сегментации. Проверить, находится ли страница в оперативной памяти. Если ее там пет, возникает особая ситуация отсутствия страницы или страничные отказ (page fault). Как правило, реакция на нее состоит в том, что вызывается специальная программа-обработчик (trap — ловушка), которая загружает требуемую страницу с диска. В многопоточных системах во время такой загрузки может исполняться другой процесс. Если страница есть в памяти, взять из ее дескриптора физический адрес phys_addr. Если мы имеем дело с сегментной адресацией, сравнить смещение в сегменте с длиной этого сегмента. Если смещение оказаюсь больше, также возникает ошибка сегментации. Произвести доступ к памяти по адресу phys_addr[offset].
Видно, что такая схема адресации довольно сложна. Однако в современных процессорах все это реализовано аппаратно и, благодаря кэшу дескрипторов и другим ухищрениям, скорость доступа к памяти получается почти такой же, как и при прямой адресации. Кроме того, эта схема имеет неоценимые преимущества при реализации многозадачных ОС.
Во-первых, мы можем связать с каждой задачей свою таблицу трансляции, а значит и свое виртуальное адресное пространство. Благодаря этому даже в многозадачных ОС мы можем пользоваться абсолютным загрузчиком. Кроме того, программы оказываются изолированными друг от друга, и мы можем обеспечить их безопасность.
Во-вторых, мы можем сбрасывать на диск редко используемые области виртуальной памяти программ — не всю программу целиком, а только ее часть. В отличие от оверлейных загрузчиков, программа при этом вообще не обязана знать, какая ее часть будет сброшена.
Другое дело, что в системах реального времени программе может быть нужно, чтобы определенные ее части никогда не сбрасывались на диск. Система реального времени обязана гарантировать время реакции, и это гарантированное время обычно намного меньше времени доступа к диску. Код, обрабатывающий событие, и используемые при этом данные должны быть всегда в памяти.
В-третьих, программа не обязана занимать непрерывную область физической памяти. При этом она вполне может видеть непрерывное виртуальное адресное пространство. Это резко упрощает борьбу с фрагментацией памяти, а в системах со страничной адресацией проблема внешней фрагментации физической памяти вообще снимается.
В большинстве систем со страничным диспетчером свободная память отслеживается при помощи битовой маски физических страниц. В этой маске вободной странице соответствует 1, а занятой — 0. Если кому-то нужна граница, система просто ищет в этой маске установленный бит. В результате виртуальное пространство программы может оказаться отображено на Физические адреса очень причудливым образом, но это никого не волнует — скорость доступа ко всем страницам одинакова (Рисунок 5.4).
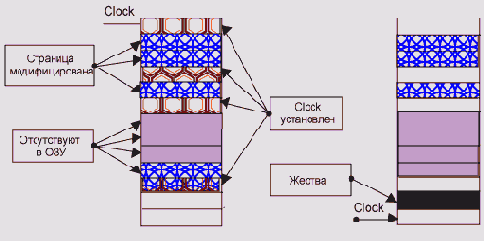
Clockалгоритм (блоксхема)
Рисунок 5.21. Clock-алгоритм (блок-схема)
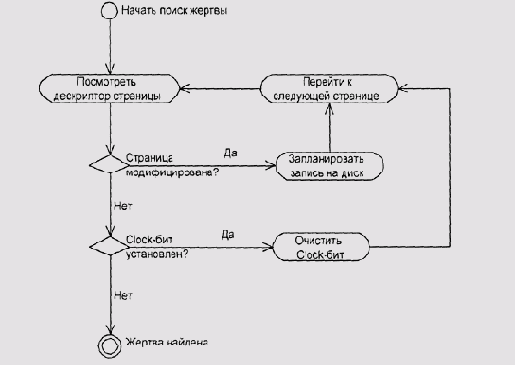
Название clock, по-видимому, происходит от внешнего сходства процесса циклического просмотра с движением стрелки часов (Рисунок 5.22). Очевидно что вероятность оказаться жертвой для страницы, к которой часто происходят обращения, существенно ниже. Накладные расходы этого алгоритма гораздо меньше, чем у LRU: вместо счетчика мы храним только один бит и изменяем его не при каждом обращении к странице, а только при первом обращении после прохода "стрелки".
Элемент таблицы доступа состоит из
Рисунок 5.12. Домен 1432
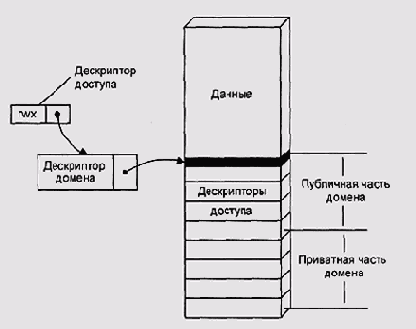
Элемент таблицы доступа состоит из прав доступа к объекту и указателя на таблицу объектов процесса. Элемент таблицы объектов может содержать непосредственную ссылку на область данных объекта — такой объект аналогичен сегменту в обычных диспетчерах памяти, однако обращение к нему происходит через два уровня косвенности. Иными словами, вместо
segment_table[seg].phys_address + offset
мы имеем
object_table[access_table[selector]].phys_address + offset.
Дополнительный уровень косвенности позволяет нам упростить отслеживание множественных ссылок на объект: вместо использования структуры данных, которую мы так и не сумели изобрести, мы можем следить только за дескриптором исходного объекта, поскольку все ссылки на объект через дескрипторы доступа вынуждены в итоге проходить через дескриптор объекта.
Более сложными сущностями являются уточнения — объекты, ссылающиеся на отдельные элементы других объектов (Рисунок 5.13). Вместо физического адреса и длины дескриптор такого объекта содержит селектор целевого сегмента, смещение уточнения в целевом объекте и его длину. При ссылке на уточнение диспетчер памяти сначала проверяет допустимость смещения, а затем повторяет полную процедуру разрешения адреса и проверки прав доступа для целевого объекта.
Операционные системы -вопросы теории
Рисунок 5.16. Global Offset Table (Глобальная таблица смещений) и Procedure Linkage Table (
Имитация clockалгоритма
Имитация clock-алгоритма
Ранние версии процессора VAX не имели аппаратно реализованного clock-бита. BSD Unix на этих процессорах реализовал clock-алгоритм, используя для этого бит отсутствия страницы.
Читателю предлагается детально представить себе алгоритм такого использования и найти отличия между этой стратегией и FIFO-алгоритмом в исполнении VAX/VMS.
Экспериментааьные исследования показывают, что реальная производительность системы довольно слабо зависит от применяемого алгоритма поиска жертвы. Статистика исполнения реальных программ говорит о том, что каждая программа имеет некоторый набор страниц, называемый рабочим множеством, который ей в данный момент действительно нужен. Размер такого набора сильно зависит от алгоритма программы, он изменяется на различных этапах исполнения и т. д.. но в большинстве моментов мы модем довольно точно указать его.
Если рабочий набор запущенных программ превосходит оперативную память, частота страничных отказов резко возрастает. При нехватке памяти программе почти на каждой команде требуется новая страница, и производительность системы катастрофически падает. Это состояние по-английски называется thrashing (общепринятого перевода для этого слова нет) и является крайне нежелательным.
В системах коллективного пользования размер памяти часто выбирают так, чтобы система балансировала где-то между состоянием, когда все программы держат свое рабочее множество в ОЗУ, и трэшингом.
Точное положение точки балансировки определяется в зависимости от соотношения между скоростью процессора и скоростью обмена с диском, а также от потребностей прикладных программ. Во многих старых учебниках рекомендуется подбирать объем памяти так, чтобы канал дискового обмена был загружен на 50% [Краковяк 1987].
Еще одно эмпирическое правило приводится в документации фирмы Amdahl: сбалансированная система должна иметь по мегабайту памяти на каждый MIPS (Million of Instructions Per Second — миллион операций в секунду) производительности центрального процессора. Если система не использует память, определенную по этой формуле, есть основания считать, что процессор также работает с недогрузкой. Иными словами, это означает, что вы купили слишком мощный для ваших целей процессор и заплатили лишние деньги.
Это правило было выработано на основе опыта эксплуатации больших компьютеров четвертого поколения, в основном на задачах управления базами данных. Скорость дисковой подсистемы в этих машинах была примерно сравнима с дисковыми контроллерами современных персональных компьютеров, поэтому в первом приближении этот критерий применим и к ПК, особенно работающим под управлением систем с виртуальной памятью — OS/2, Windows NT и системами семейства Unix. В любом случае, для выдачи рекомендаций требуется анализ смеси приложений, которая будет исполняться в системе, и других требований к ней.
В современных персональных системах пользователь, как правило, работает в каждый момент только с одной-двумя программами, и задержки в исполнении этих программ существенно снижают наблюдаемую скорость системы. Поэтому в таких системах память обычно ставят с большим запасом, так, чтобы при обычной деятельности рабочие множества программ даже близко не подходили к размеру ОЗУ. Отчасти это обусловлено тем, что в наше время динамическая память становится все дешевле и дешевле.
Конфликтующие адреса отображения DLL
Рисунок 5.14. Конфликтующие адреса отображения DLL
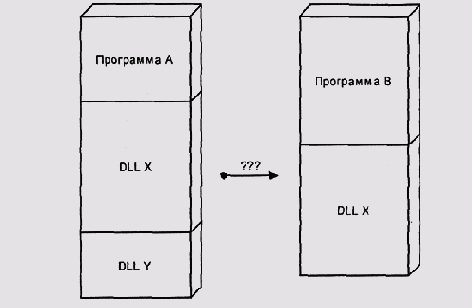
В старых системах семейства Unix, использовавших абсолютные загружаемые модули формата a.out, разделяемые библиотеки также поставлялись в формате абсолютных модулей, настроенных на фиксированные адреса. Каждая библиотека была настроена на СБОЙ адрес. Поставщик новых библиотек должен был согласовать этот адрес с разработчиками системы. Это было весьма непрактично, поэтому разделяемых библиотек было очень мало (особенно если не считать те, которые входили в поставку ОС).
Более приемлемое решение этой проблемы реализовано в OS/2 2.x и Win32 (обе эти архитектуры являются развитием систем с единым адресным пространством). Идея состоит в том, чтобы выделить область адресов под загрузку DLL и отображать эту область в адресные пространства всех процессов. Таким образом, все DLL, загруженные в системе, видны всем (Рисунок 5.15).
Очевидным недостатком такого решения (как, впрочем, и предыдущего) является неэффективное использование адресного пространства: при cколь-нибудь сложной смеси загруженных программ большей части процессов большинство библиотек будет просто не нужны. В те времена, когда эта архитектура разрабатывалась, это еще не казалось серьезной трудностью, но сейчас, когда многим приложениям становится тесно в 4 Гбайт и серверы с таким объемом оперативной памяти уже не редкость, это действительно может стать проблемой.
Копирование при модификации
Рисунок 5.24. Копирование при модификации
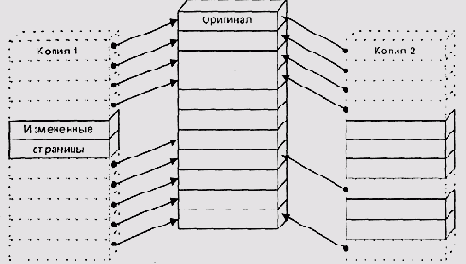
Если же используется относительная загрузка или та или иная форма сборки в момент загрузки (разделяемые библиотеки или DLL), при загрузке кода происходит перенастройка адресов. В этом случае возможны два подхода: копировать перенастроенный код в своп или производить перенастройку заново после каждого страничного отказа.
Магнитный диск и магнитный барабан
Рисунок 5.23. Магнитный диск и магнитный барабан

В своп-файл попадают только страницы, которые изменились с момента загрузки процесса. Если ОС использует абсолютную загрузку или позиии-онно-независимып код, исполняющийся код не отличается от своего образа в загрузочном файле, поэтому страницы кода вполне можно подкачивать оттуда, и нет никакой необходимости копировать их в своп. Часто при загрузке программы система помещает в память только страницу, на которую указывает стартовый адрес, а весь остальной используемый код и данные подгружаются механизмом страничного обмена.
При загрузке статически инициализированных данных обычно используется стратегия copy-on-write (копирование при модификации): первоначально страница подкачивается из файла. Если она не будет модифицирована и ее объявят жертвой, то при повторном обращении ее снова подгрузят из того же файла (Рисунок 5.24). Только если страница будет изменена, ей выделят место в своп-файле.
Обработка страничного отказа (блоксхема)
Рисунок 5.20. Обработка страничного отказа (блок-схема)
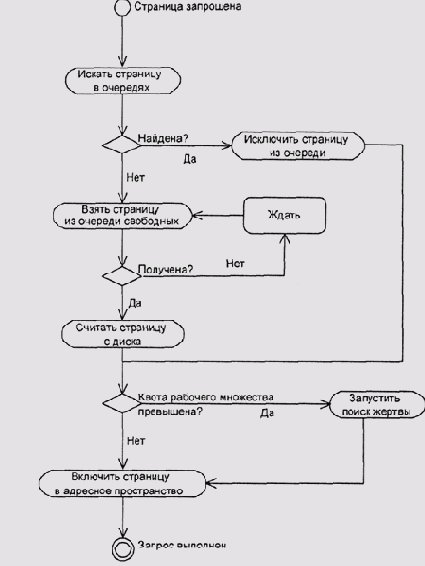
Фирма Microsoft вполне сознает ущербность принятой стратегии управления памятью и официально не рекомендует запускаыть на серверах под управлением Windows NT/2000/XP более одного приложения или ресурсоемкого сервиса.
Пул свободных страниц, в который входят как действительно свободные, так и отобранные у задач в качестве "жертв" страницы, в той или иной форме поддерживают все ОС, использующие страничный обмен, однако обычно этот пул отделяют от дискового кэша и при полной загрузке он не превосходит нескольких процентов ОЗУ. При запросах ядра и страничных отказах система выделяет страницы из этого пула, и только при падении его объема ниже некоторого предела, начинает поиск жертв в адресных пространствах активных процессов.
Шиболее справедливым будет удалять тот объект, к которому дольше всего не было обращений в прошлом LRU (Leasr Recently Used). Такой подход требует набора сведений обо всех обращениях. Например, диспетчер памяти должен поддерживать в дескрипторе каждой страницы счетчик обращений, и при каждой операции чтения или записи над этой страницей увеличивать этот счетчик на единицу. Это требует довольно больших накладных расходов — в ряде работ, например, в [Краковяк 1987], утверждается, что они будут недопустимо большими.
Остроумным приближением к алгоритму LRU является так называемый clock-алгоритм, применяемый во многих современных ОС, в том числе в системах семейства Unix. Он состоит в следующем (Рисунок 5.21).
Одноуровневая память
Одноуровневая память
| И каждый уже десять лет учит роли, О которых лет десять как стоит забыть Б.Гребенщиков |
Эффективное управление рабочими наборами пользовательских программ и, с другой стороны, эффективное кэширование запросов к дискам позволяют если и не скрыть полностью, то в значительной мере сгладить различие в производительности оперативной и внешней памяти компьютера. Поэтому сразу же после возникновения первых машин с виртуальной памятью начались попытки спрятать все остальные различия между этими двумя типами памяти от программиста, реализовав так называемую одноуровневую память.
Интерес к этой идее сохраняется до сих пор. Например, на сайте
Отображение файлов в память в Unix
Отображение файлов в память в Unix
Системы семейства Unix предоставляют пользователям доступ к механизмам, используемым при загрузке программ, в виде системного вызова гол-ар. Этот вызов отображает участок файла в память. Отображение возможно в двух режимах: MAP_SHARED изменения в памяти отображаются в файле— таким образом mmap можно использовать для реализации разделяемой памяти и MAP_PRIVATE (соответственно, изменения памяти в файле не отображаются — при этом измененные страницы копируются в своп-файл).
Широко используется выделение памяти при помощи отображения псевдофайла /dev/zero (файл бесконечной длины, состоящий из одних нулей) в память в режиме MAP_PRIVATE.
Даже когда место под своп-файл выделяется динамически, система обычно предоставляет возможность ограничивать его рост. У интерактивных систем
при приближении к границе емкости своп-файла система часто начинает выдавать предупреждения пользователю. Однако основным видом реакции на переполнение или превышение лимитов роста своп-файла является отказ выделять память прикладным программам. Поэтому грамотно написанные программы всегда должны проверять, нормально ли завершился запрос на выделение памяти, и по возможности разумно обрабатывать ненормальное завершение. Это нужно не только в том случае, когда программа будет переноситься в систему без виртуатьной памяти, но и во вполне штатной (хотя и относительно редкой) ситуации переполнения свопа.
Иногда, впрочем, система может выделять память (точнее, не память, а только
адресное пространство) программам без оглядки на то, сколько есть свободного свопа. Эта довольно опасная стратегия, называемая overcommit, на первый взгляд кажется бессмысленной или полезной только в очень специальных случаях, например при использовании разреженных массивов. В действительности эта стратегия оправдана и тогда, когда мы можем быть уверены, что большинство выделенных процессу страниц никогда не будут использованы, например, при широком применении стратегии copy-on-write.
Overcommit в Unix
Overcommit в Unix
В системах семейства Unix копирование при записи применяется не только при загрузке сегментов данных программ и отображений файлов в память, но и при создании задач. Системный вызов fork (подробнее обсуждался в главе 3) создает полную копию адресного пространства процесса, выполнившего этот вызов. Физического копирования, естественно, не происходит. Вместо этого система отображает память родительского процесса в адресное пространство потомка и устанавливает защиту от записи на все страницы обеих задач. Когда какая-то из задач пытается осуществить запись, соответствующая страница физически копируется и запись осуществляется уже в копию. Большинство порожденных задач исполняют системный вызов exec вскоре после создания, изменив лишь несколько переменных в своем адресном пространстве. При таком стиле работы с памятью, действительно, многие выделяемые страницы не используются никогда, а большинство из используемых только прочитываются, поэтому overcommit является стандартной стратегией выделения памяти в Unix.
Передача мандатов
Рисунок 5.11. Передача мандатов
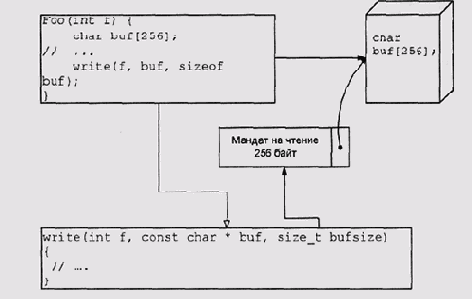
При использовании страничных и двухслойных сегментно-странпчных диспетчеров памяти мы можем отображать в чужие адресные пространства только объекты, выровненные на границу страницы и имеющие размер, кратный размеру страницы. Мы не можем избавиться от супервизора. В данном случае это должен быть модуль, ответственный за формирование мандата и размещение отображенного модуля в адресном пространстве задачи, получающей мандат.
Первая проблема является чисто технической — она приводит лишь к тому, что мы можем построить такую систему только на основе сегментного УУП, в котором размер сегмента задается с точностью до байта пли хотя бы до слова. Сегментированная память страдает от внешней фрагментации, но иногда такую цену стоит заплатить за повышение надежности.
Функции модуля, управляющего выдачей мандатов, оказываются слишком сложны для аппаратной и даже микропрограммной реализации. Этот модуль должен выполнять следующие функции.
Но еше больше проблем создает операция уничтожения мандата. Легко показать необходимость уничтожения мандата той же задачей, которая его создала.
Например, представим себе, что пользовательская программа передала какому-либо модулю мандат на запись в динамически выделенный буфер. Допустим также, что этот модуль вместо уничтожения мандата после передачи данных сохранил его — ведь наша система предполагает, что ни одному из модулей нельзя полностью доверять! Если мы вынуждены принимать в расчет такую возможность, то не можем ни повторно использовать такой буфер для других целей, ни даже возвратить память, занятую им системе, потому что не пользующийся нашим доверием модуль по-прежнему может сохранять право записи в него.
В свете этого возможность для задачи, выдавшей мандат, в одностороннем порядке прекращать его действие представляется жизненно необходимой. Отказ от этой возможности или ее ограничение приводит к тому, что задача. выдающая мандат, вынуждена доверять тем задачам, которым мандат был передан, т. е. можно не городить огород и вернуться к обычной двухуровневой или многоуровневой системе колец защиты.
Для прекращения действия мандата мы должны отыскать в нашей общесистемной базе данных все ссылки на интересующий нас объект и объявить не недействительными. При этом мы должны принять во внимание возможности многократной передачи мандата и повторной выдачи мандатов на отдельные части объекта. Аналогичную задачу нужно решать при перемещении объектов в памяти во время дефрагментации, сбросе на диск и поиске жертвы (см. разд. Поиск жертвы) для такого сброса.
Структура этой базы данных представляется нам совершенно непонятной, потому что она должна отвечать следующим требованиям.
Последнее требование непосредственно не следует из концепции взаимно недоверяющих подсистем, но диктуется простым здравым смыслом. Если мы и смиримся с двух- или более кратным увеличением потребностей в памяти, оправдывая его повышением надежности, нельзя забывать, что даже простой просмотр многомегабайтовых таблиц не может быть быстрым.
В системах, использующих страничные диспетчеры памяти, решить эти Проблемы намного проще, потому что минимальным квантом разделения Памяти является страница размером несколько килобайтов. Благодаря этому Мы смело можем связать с каждым разделяемым квантом несколько десятков байтов данных, обеспечивающих выполнение первых двух требований.
Если же минимальным квантом является байт или слово памяти, наши структуры данных окажутся во много раз больше распределяемой памяти.
Автор оставляет читателю возможность попробовать самостоятельно разработать соответствующую структуру данных. В качестве более сложного упражнения можно рекомендовать записать алгоритм работы с такой базой данных на псевдокоде, учитывая, что мы хотели бы иметь возможность реализовать этот алгоритм аппаратно или, по крайней мере, микропрограммно.
Дополнительным стимулом для читателя, решившего взяться за эту задачу, может служить тот факт, что разработчики фирмы Intel не смогли найти удовлетворительного решения.
Переключение режимов процессора VAX
Рисунок 5.6. Переключение режимов процессора VAX
Поиск жертвы
Поиск жертвы
| ..И вот мы образовались вашему приходу,- может, вы согласитесь принести себя в жертву А. Тутуола |
Естественно, для того чтобы автоматизировать процесс удаления барахла" — редко используемых данных и программ — мы должны иметь какой-то легко формализуемый критерий, по которому определяется, какие данные считаются редко используемыми.
Один критерий выбора очевиден — при прочих равных условиях, в первую очередь мы должны выбирать в качестве "жертвы" (victim) для удаления тот объект, который не был изменен за время жизни в быстрой памяти. Действительно, вы скорее удалите с винчестера саму игрушку (если у вас есть ее копия на дискетах), чем файлы сохранения!
Для ручного переноса данных очевиден и другой критерий: нужно удалять (Для блоков данных, которые не подверглись изменению за время пребывания в быстрой памяти, удаление будет состоять в уничтожении копии. Для модифицированных же блоков новое значение данных должно быть скопировано обратно в медленную память, и только после этого можно произвести собственно удаление.) то, что дольше всего не будет использоваться в будущем. Конечно, любые предположения о будущем имеют условный характер, все может неожиданно измениться. Мы делаем предположения о том, что будет использоваться, только на основании накопленной статистики обращений к страницам. Такая экстраполяция не совсем корректна логически, поэтому может оказаться целесообразным смириться с некоторой неточностью или неполнотой этой статистики.
Самая простая стратегия — выбрасывать случайно выбранный объект. При этом не надо собирать никакой статистики о частоте использования и т. д., важно лишь обеспечить равномерность распределения генерируемых псевдослучайных чисел. Очевидно, что при этом удаленный объект совершенно необязательно будет ненужным
Можно также удалять то, что дольше всего находится в памяти. Это называется алгоритмом FIFO (First In, First Out, первый вошел, первый вышел). Видно, что это уже чуть сложнее случайного удаления — нужно запоминать, когда мы что загружали.
Поиск жертвы в VAX/VMS и Windows NT/2000/XP
Поиск жертвы в VAX/VMS и Windows NT/2000/XP
В VAX/VMS и Windows NT/2000/XP применяется любопытный вариант этого алгоритма. В этих системах страница, объявленная жертвой, исключается из адресного пространства задачи (у соответствующего дескриптора выставляется бит отсутствия), но не отдается немедленно под другие нужды. Вместо этого страницы, помеченные как отсутствующие, помещаются в пул свободных страниц, который, по совместительству, используется и для дискового кэша и может занимать более половины оперативной памяти. У VAX/VMS этот пул состоит из трех очередей (Рисунок 5.19).
1. Очередь модифицированных страниц, ждущих записи на диск (по мере записи, эти страницы переходят во вторую очередь).
2. Очередь немодифицированных страниц.
3. Очередь свободных страниц (освобожденных прикладной программой или освободившихся после ее завершения).
Жертвой с равной вероятностью может быть объявлена как модифицированная, так и немодифицированная страница, однако для запросов прикладных программ и буферов дискового кэша используются только страницы из второй и третьей очередей.
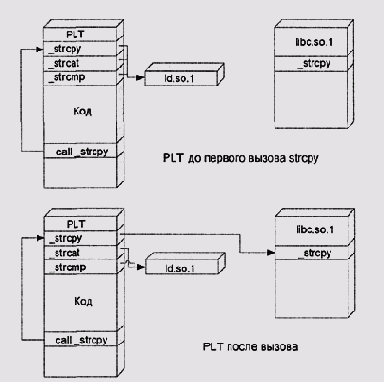
Структура PLT для процессора
Пример 5.2. Структура PLT для процессора SPARC (цитируется по [docs.sun.com 816-0559-10])
Первые две (специальные) записи PLT до загрузки программы:
.PLT0:
un imp
unimp
unimp .PLTl:
unimp
unimp
unimp
Обычные записи PLT до загрузки программы:
.PLT101:
sethi (.-.PLT0),%gl
ba,a .PLTO
пор .PLT102:
sethi (.-.PLT0),%gl
ba,a .PLTO
nop
...
Специальные записи PLT после загрузки программы:
.PLT0:
save %sp,-64,°osp
call runtime-linker
пор
.PLT1:
.word identification
unimp
unimp
...
Обычные записи PLT после настройки:
PLT101:
sethi (.-.PLT0),%g1
sethi %hi(name1),%g1
jmpl %g1+%lo(namel),%g0
PLT102:
sethi (.-.PLT0),%g1
sethi %hi (name2),%g1
jmpl %g1+%lo(name2),%g0
Таким образом, каждая пользовательская задача, загруженная в Unix, имеет собственное адресное пространство с собственной структурой (Рисунок 5.18). Некоторые участки памяти у разных задач могут совпадать, и это позволяет сэкономить ресурсы за счет их разделения. Это существенно менее глубокое разделение, чем то, что достигается в Windows, но, как мы видели в разд. Динамические библиотеки более глубокое и принудительное разделение кода чревато серьезными проблемами.
Р = ckр = c/ k
h2>р = c/ k.

Детальное обсуждение этого явления, к сожалению, не доходящее до глубинных его причин, приводится в [Кнут 200, т. 3]. Как один из результатов обсуждения предлагается концепция "самоорганизующегося файла" — для ускорения поиска в несортированном массиве предлагается передвигать записи ближе к началу массива. Если обращения к массиву распределены в соответствии с законом Зипфа, наиболее востребованные записи концентрируются в начале массива и поиск ускоряется в c/ ln N раз, где N — размер массива, а с — константа, зависящая от используемой стратегии перемещения элементов.
При произвольном доступе к данным (например, по указателям или по ключам хэш-таблицы) перемещение к началу массива не имеет столь благотворного эффекта — если только вся память имеет одну и ту же скорость доступа. Но мы видели, что разные типы запоминающих устройств резко различаются по этому параметру.
Это различие приводит нас к идее многослойной или многоуровневой памяти, когда в быстрой памяти хранятся часто используемые код или данные, а редко используемые постепенно мигрируют на более медленные устройства. В случае дисковой памяти такая миграция осуществляется вручную: администратор системы сбрасывает на ленты редко используемые данные и заполняет освободившееся место чем-то нужным. Для больших и сильно загруженных систем существуют специальные программы, которые определяют, что является малоценным, а что — нет. Управление миграцией из ОЗУ на диск иногда осуществляется пользователем, но часто это оказывается слишком утомительно. В случае миграции между кэш-памятью и ОЗУ Делать что-то вручную просто физически невозможно.
Работа clockалгоритма
Рисунок 5.22. Работа clock-алгоритма
Практически все известные автору современные диспетчеры памяти предполагают использование clock-алгоритма. Такие диспетчеры хранят в дескрипторе страницы или сегмента два бита — clock-бит и признак модификации. Признак модификации устанавливается при первой записи в страницу/сегмент, в дескрипторе которой этот признак был сброшен.
Распределение адресного пространства по физической памяти
Рисунок 5.4. Распределение адресного пространства по физической памяти

В-четвертых, система может обеспечивать не только защиту программ друг от друга, но в определенной мере и защиту программы от самой себя — например, от ошибочной записи данных на место кода или попытки исполнить данные.
В-пятых, разные задачи могут использовать общие области памяти для взаимодействия или, скажем, просто для того, чтобы работать с одной копией библиотеки подпрограмм.
Перечисленные преимущества настолько серьезны, что считается невозможным реализовать многозадачную систему общего назначения, такую как UNIX или System/390 на машинах без диспетчера памяти.
Для систем реального времени, впрочем, виртуальная память оказывается скорее вредна, чем бесполезна: наличие диспетчера памяти увеличивает объем контекста процесса (это понятие подробнее обсуждается в разд. Вытесняющая многозадачность), воспользоваться же главным преимуществом — возможностью страничного обмена — задачи реального времени в полной мере не могут. Поэтому такие системы, даже работающие на процессорах со встроенным диспетчером памяти, часто этот диспетчер не используют. Даже если виртуальная память доступна, система РВ (реального времени) обязана предоставлять средства блокировки кода и данных (не обязательно всех) пользовательского процес са в физической памяти.
Отдельной проблемой при разработке системы со страничной или сегментной адресацией является выбор размера страницы или максимального размера сегмента. Этот размер определяется шириной соответствующего битового поля адреса и поэтому должен быть степенью двойки.
С одной стороны, страницы не должны быть слишком большими, так как это может привести к внутренней фрагментации и перекачке слишком больших объемов данных при сбросе страниц на диск. С другой стороны, страницы не должны быть слишком маленькими, так как это приведет к чрезмерному увеличению таблиц трансляции, требуемого объема кэша дескрипторов и т. д.
В реальных системах размер страницы меняется от 512 байт у машин семейства VAX до нескольких килобайт. Например, х86 имеет страницу размером 4 Кбайт. Некоторые диспетчеры памяти, например у МС6801/2/30, имеют переменный размер страницы — система при запуске программирует диспетчер и устанавливает, помимо прочего, этот размер, и дальше работает со страницами выбранного размера. У процессора i860 размер страницы переключается между 4 Кбайтами и 4 Мбайтами.
С сегментными диспетчерами памяти ситуация сложнее. С одной стороны, хочется, чтобы один программный модуль помешался в сегмент, поэтому сегменты обычно делают большими, от 32 Кбайт и более. С другой стороны, хочется, чтобы в адресном пространстве можно было сделать много сегментов. Кроме того, может возникнуть проблема: как быть с большими неразделимыми объектами, например хэш-таблицами компиляторов, под которые часто выделяются сотни килобайт.
В результате ряд машин предоставляет двухступенчатую виртуальную память — сегментную адресацию, в которой каждый сегмент, в свою очередь, разбит на страницы. Это дает ряд мелких преимуществ, например, позволяет давать права доступа сегментам, а подкачку с диска осуществлять постранично. Таким образом, организована виртуальная память в IBM System 370 и ряде других больших компьютеров, а также в х86. Правда, в последнем виртуальная память используется несколько странным образом.
Разделяемые библиотеки
Разделяемые библиотеки
Ранее мы упоминали разделяемые библиотеки как одно из преимуществ страничных и сегментных диспетчеров памяти перед базовыми и банковыми. При базовой адресации образ каждого процесса должен занимать непрерывные области как в физическом, так и в логическом адресном пространстве. В этих условиях реализовать разделяемую библиотеку невозможно. Но и при использовании страничной адресации не все так просто.
Использование разделяемых библиотек и/или DLL (в данном случае разница между ними не принципиальна) предполагает ту или иную форму сборки в момент загрузки: исполняемый модуль имеет неразрешенные адресные ссылки и имена библиотек, которые ему нужны. При загрузке эти библиотеки подгружаются и ссылки разрешаются. Проблема здесь в том, что при Подгрузке библиотеки ее нужно переместить, перенастроив абсолютные адресные ссылки в ее коде и данных (см. главу 3). Если в разных процессах библиотека будет настроена на разные адреса, она уже не будет разделяемой (Рисунок 5.14)! Если разделяемые библиотеки могут иметь неразрешенные ссылки на другие библиотеки, проблема только усугубляется — к перемещаемым ссылкам добавляются еще и внешние.
Разделяемые библиотеки ELF
Рисунок 5.18. Разделяемые библиотеки ELF

Разделяемые объекты ELF идентифицируются по имени файла. Исполняемый модуль может ссылаться на файл как по простому имени (например, libc.so.1), так и с указанием пути (/usr/lib/libc.so.1). При поиске файла по простому имени редактор связей ищет его в каталогах, указанных в переменной среды LD LIBRARY_PATH, в записи RPATH заголовка модуля и, наконец, в каталогах по умолчанию, перечисленных в конфигурационном файле /var/ld/ld.config (именно в таком порядке,
Редактор связей времени исполнения
Рисунок 5.17. Редактор связей времени исполнения
В свете этого, например, системный
Реестр Win32
В свете этого, например, системный реестр Win32, не имеющий адекватных средств восстановления и самоконтроля, представляет собой если и не сознательную диверсию, то, во всяком случае, недостаточно продуманное техническое решение — из-за него многие проблемы, для исправления которых в более продуманных с этой точки зрения системах достаточно перезагрузки или очистки конфигурационного файла, в Win32 приходится решать переустановкой ОС.
Да, Windows NT предоставляет некоторые средства резервного копирования реестра — "восстановительную" дискету и "последнюю хорошую (last known good) конфигурацию", но эти средства неудобны для повседневного использования, а "последняя хорошая конфигурация" и просто неадекватна: тот факт, что с данным содержимым реестра мы дошли до окошка с именем и паролем, это, конечно, определенное достижение и повод этот реестр сохранить — но ни в коем случае не повод затирать предыдущую (теперь уже предпоследнюю) "хорошую" конфигурацию!
Если говорить именно о настройках ОС, радикальнее всего эта проблема решена в современных версиях FreeBSD (свободно распространяемой системе семейства Unix), в которой все файлы настройки ОС и системных сервисов включены в систему контроля версий, обеспечивающую полный или частичный откат на неограниченное число модификаций назад. Собственно, это может быть реализовано в любой ОС, которая хранит свою конфигурацию в текстовом формате, стандартными средствами контроля версий, используемыми для разработки программного обеспечения, — CVS и др. В свете вышеприведенных рассуждений, полезно разделять оперативные и хранимые объекты не только по способу адресации, но и по представлению данных. Эти представления должны удовлетворять различным и не всегда совместимым требованиям: при выборе внутреннего, оперативного представления данных основные критерии — это скорость, удобство доступа и умопостижпмость кода, который будет с этими данными работать, а для „нешнего, хранимого представления — прежде всего легкость проверки и, если это возможно, восстановление целостности данных. При разработке внешнего формата данных желательно также принять во внимание соображения межмашинной совместимости — возможные различия в порядке байтов и даже битов в целочисленных значениях, особенности представления чисел с плавающей точкой, различия кодировки текста и так далее.
Если хранимое и оперативное представления объектов различны, одноуровневая память для нас скорее вредна, чем бесполезна: прежде чем программа сможет работать с объектом, она должна преобразовать его во внутреннее представление (в объектно-ориентированных языках это может делать один из конструкторов объекта). Эту процедуру обычно оказывается целесообразно совместить со считыванием внешнего представления объекта из файла. "Прозрачная" же для пользовательской программы запись данных во внешний формат бывает и просто опасна — нередко для обеспечения целостности данных оказывается необходим контроль над порядком записи тех или иных полей и структур.
Объединение оперативной и долговременной памяти, таким образом, оказывается применимо лишь в тех ситуациях, когда нам, во-первых, удалось разработать модель данных, одновременно удовлетворяющую требованиям, предъявляемым и к оперативному, и к хранимому представлениям, и во-вторых, когда нас не беспокоит опасность нарушения нашей модели данных из-за неполного их сохранения в момент системного сбоя (или когда мы имеем какие-то средства предотвращения этой опасности).
Безусловно, средства для отображения файлов в память лучше иметь, чем не иметь. К тому же их можно использовать и для других целей, кроме собственно организации одноуровневого доступа к данным — для загрузки программ, выделения памяти или эмуляции сегментов данных, разделяемых между задачами и даже между машинами (при доступе к файлу по сети).
Важно еще подчеркнуть, что разделение представлений данных на внешние и внутренние не обязано полностью соответствовать способу их хранения — в ОЗУ или на диске. Кроме хранения оперативных данных в своп-пространстве и разного рода "виртуальных дисков" можно привести и более радикальный пример: таблицы, индексы и прочие файлы данных сервера реляционной СУБД представляют собой, скорее, оперативное представление данных, РОЛЬ же хранимого представления в данном случае играют форматы, Используемые для экспорта и резервного копирования содержимого таблиц.
Благодаря этому примеру становится понятнее, почему единственная из коммерчески применяемых в настоящее время систем с одноуровневой адресацией — AS/400 — ориентирована на использование в качестве сервера СУБД. В литературе, особенно в рекламной, даже встречается ее описание "аппаратного сервера баз данных".
Примечание
Примечание
Вообще, описание специализированных компьютеров как "аппаратное что-то там"— нередко встречающийся, остроумный и довольно эффективный маркетинговый прием. Понятно, что чем более короткий и однозначный ответ дает технический специалист на вопросы "принимающих решения", тем легче ему будет обосновать конкретный выбор. Поэтому наравне с грамотным и исчерпывающим описанием технических достоинств, хорошее рекламное описание должно в явном или неявном виде содержать и варианты ответов на многие распространенные вопросы со стороны нетехнического персонала.
Так, если начальник спрашивает администратора: "Вот, купим мы этот компьютер — моя секретарша сможет на нем в Lines играть?", тот может ему ответить: "А это не компьютер, это аппаратный... " маршрутизатор (Cisco), сервер СУБД (AS/400), веб-сервер (попытки продавать такие серверы на основе Linux делались, но большого успеха не имели), нужное подставить.
Сегментная и страничная виртуальная память
Сегментная и страничная виртуальная память
В системах с сегментной и страничной адресацией виртуальный адрес имеет сложную структуру. Он разбит на два битовых поля: селектор страницы (сегмента) и смещение в нем. Соответственно, адресное пространство оказывается состоящим из дискретных блоков. Если все эти блоки имеют фиксированную длину и образуют вместе непрерывное пространство, они называются страницами (Рисунок 5.1).
Сегментная виртуальная память
Рисунок 5.2. Сегментная виртуальная память
Такая адресация реализуется аппаратно. Процессор имеет специальное устройство, называемое диспетчером памяти или, как его называли в старой русскоязычной литературе, УУП (Устройство Управления Памятью, ср. MMU — Memory Management Unit). В некоторых процессорах, например в MC68020 или MC68030 или в некоторых RISC-системах, это устройство реализовано на отдельном кристалле; в других, таких как х86 или современные RISC-процессоры, диспетчер памяти интегрирован в процессор.
В PDP-11 сегментов всего восемь, поэтому дескрипторы каждого из них размещаются в отдельном регистре (на самом деле, регистров не восемь, а шестнадцать — восемь для пользовательского адресного пространства и восемь для системного). На 32-разрядных машинах количество сегментов измеряется тысячами, а страниц — иногда и миллионами, поэтому приходится прибегать к более сложной схеме.
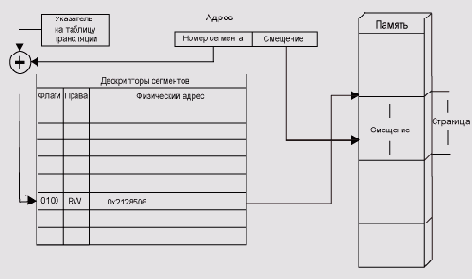
Диспетчер памяти содержит регистр — указатель на таблицу трансляции. Эта таблица размещается где-то в ОЗУ. Ее элементами являются дескрипторы каждой страницы/сегмента. Такой дескриптор содержит права доступа к странице, признак присутствия этой страницы в памяти и физический адрес страницы/сегмента. Для сегментов в дескрипторе также хранится его длина.
Большинство реальных программ используют далеко не все адресное пространство процессора, соответственно таблица трансляции не обязательно держит все допустимые дескрипторы. Поэтому практически все диспетчеры памяти имеют еще один регистр — ограничитель длины таблицы трансляиии. Страницы или сегменты, селектор которых превосходит ограничитель, не входят в виртуальное адресное пространство процесса. Как правило, диспетчер памяти имеет также кэш (cache) дескрипторов — быструю память с ассоциативным доступом. В этой памяти хранятся дескрипторы часто используемых страниц. Алгоритм доступа к памяти по виртуальному адресу page: off set состоит из следующих шагов (Рисунок 5.3).
Сегменты страницы и системные вызовы
Сегменты, страницы и системные вызовы
| О, порождение Земли и Тьмы, мы приказываем тебе отречься...- твердым, повелительным тоном начал Гальдер. Смерть кивнул. — ДА, ДА, ЗНАЮ Я ВСЕ ЭТО. ВЫЗЫВАЛИ-ТО ЧЕГО'' Т. Пратчетт |
Реализовав страничную или сегментную виртуапьную память, мы сталкиваемся с той же проблемой, о которой шла речь в разд. Системы с базовой виртуальной адресацией: пользовательские программы не имеют доступа к адресным пространствам друг друга и к таблице дескрипторов, но ведь им надо иметь возможность вызывать системные сервисы и передавать им параметры!
Один из основных способов решения этой проблемы сродни методу, применяемому в системах с базовой адресацией: вводятся два режима работы процессора, "системный" и "пользовательский", в которых используются разные таблицы дескрипторов. Переключение из пользовательского режима в системный осуществляется специальной командой, которая вызывает определенную процедуру в системном адресном пространстве.
Известную сложность при этом представляет передача параметров: как отмечалось выше, пользовательское адресное пространство может быть отображено на физические адреса весьма причудливым образом. Для разрешения указателя в этом адресном пространстве нам либо необходимо анализировать пользовательскую таблицу дескрипторов вручную, либо каким-то способом временно переключить диспетчер памяти на использование этой таблицы.
Большинство процессоров с диспетчером памяти предоставляют команд, копирования данных из пользовательского адресного пространства в системное и обратно. Конечно же. доступны эти команды только из системного режима.
Некоторые архитектуры предоставляют и более изощренные способы pеализации системных вызовов и передачи управления между системой и прикладной программой.
Сегменты страницы и системные вызовы (продолжение)
Сегменты, страницы и системные вызовы (продолжение)
Аппаратные схемы тонкого разделения доступа к адресному пространству не имели большого успеха не только из-за высоких накладных расходов, но и из-за того, что решали не совсем ту проблему, которая реально важна. Для повышения надежности системы в целом важно не обнаружение ошибок и даже не их локализация с точностью до модуля сама по себе, а возможность восстановления после их возникновения. Самые распространенные фатальные ошибки в программах — это ошибки работы с указателями и выход индекса за границы массива (в наш сетевой век ошибки второго типа более известны как "срыв буфера"). Эти ошибки не только часто встречаются, но и очень опасны, потому что восстановление после них практически невозможно. Ошибки работы с указателями еще можно попытаться устранить, искоренив само понятие указателя. Примерно этой логикой продиктован запрет на формирование указателей в машинах Burroughs, именно из этих соображений в Java и некоторых других интерпретируемых языках указателей вообще нет. Однако искоренить понятие индексируемого массива уже не так легко. д ошибки индексации присуши всем компилируемым языкам, начиная с Fortran и Algol 60. Вставка проверок на границы индекса перед каждой выборкой элемента массива создает накладные расходы, но тоже не решает проблемы: ошибка все равно обнаруживается не в момент совершения (в тот момент, когда мы вычислили неверный индекс), а позже, когда мы попытались его использовать. В момент индексации обычно уже невозможно понять, какой же элемент массива имелся в виду. Программе остается только нарисовать на экране какое-нибудь прощальное сообщение вроде "Unhandled Java Exception", и мирно завершить свой земной путь. Понятно, что реакция пользователя на подобное сообщение будет ничуть не более адекватной, чем на хрестоматийное "Ваша программа выполнила недопустимую операцию — General Protection Fault" (впрочем, кто знает, может быть, такая реакция и является самой адекватной?). Прогресс в решении этой проблемы лежит уже в сфере совершенствования технологий программирования, и вряд ли может быть обеспечен усложнением диспетчеров памяти. Уровень же надежности, обеспечиваемый современными ОС общего назначения с разделением памяти, по-видимому, оптимален в том смысле, что улучшения в сфере защиты памяти могут быть достигнуты лишь ценой значительных накладных расходов без принципиального повышения наработки на отказ.
Слово состояния процессора VAX
Рисунок 5.5. Слово состояния процессора VAX

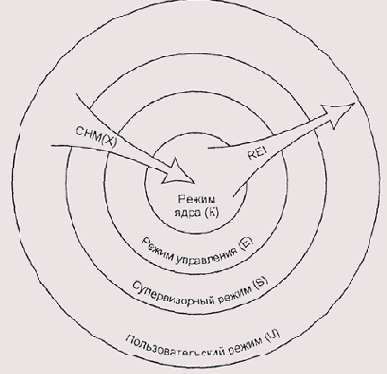
Все допускаемые этими правилами комбинации прав могут быть закодированы при помощи четырех бит в дескрипторе страницы (табл. 5.1). Переключение режимов осуществляется командами СНМК, СНМЕ, CHMS и CHMU. Эти команды помещают слово состояния процессора и счетчик команд в стек, соответствующий новому режиму, сохраняют предыдущий режим в специальном поле слова состояния (зачем нужно сохранять режим в двух местах, мы поймем чуть позже), устанавливают новый режим и, наконец, передают управление по фиксированному адресу, аналогично команде SYSCALL в системах с двумя уровнями доступа. Передача управления по фиксированному адресу позволяет нам защититься от бесконтрольного повышения уровня доступа, а все предыдущие операции дают возможность вернуться на предыдущий уровень доступа с одновременной передачей управления, используя специальную команду REI, которая восстанавливает и счетчик команд, и слово состояния. Команды СHМ(Х) обычно используются для повышения уровня доступа, a REI может использоваться только для его понижения или возврата на тот же уровень (Рисунок 5.6).
Страничная виртуальная память
Рисунок 5.1. Страничная виртуальная память, а неиспользуемым частям блоковыыы
Если длина каждого блока может задаваться, соответствуют "дыры" в виртуальном адресном пространстве, такие блоки называются сегментами (Рисунок 5.2). Как правило, один сегмент соответствует коду или данным одного модуля программы. Со страницей или сегментом могут быть ассоциированы права чтения записи и исполнения.
Страничный обмен
Страничный обмен
Подкачка, или свопинг (от англ, swapping — обмен) — это процесс выгрузки редко используемых областей виртуального адресного пространства программы на диск или другое устройство массовой памяти. Такая массовая память всегда намного дешевле оперативной, хотя и намного медленнее.
Во многих учебниках по ОС приводятся таблицы, аналогичные табл. 5.2.
В этой архитектуре для проверки
Рисунок 5.9. Структура адреса процессора i80286
В этой архитектуре для проверки прав доступа к сегменту в предыдущем режиме работы не нужны специальные команды, достаточно проверки селектора сегмента.
80286, хотя и предоставлял почти полноценную сегментную адресацию, не имел сегментных отказов, поэтому использовать все преимущества виртуальной памяти на этом процессоре было невозможно. Вторым недостатком было отсутствие режима совместимости с 8086 — не существовало возможности создать такую таблицу трансляции, которая бы воспроизводила специфическую структуру адресного пространства этого процессора. Отчасти это было обусловлено и использованием битов в селекторе сегмента для задания прав доступа. Обе ОС, которые разрабатывались для этого процессора,— Win16 и OS/2 1 .х — большого успеха не имели.
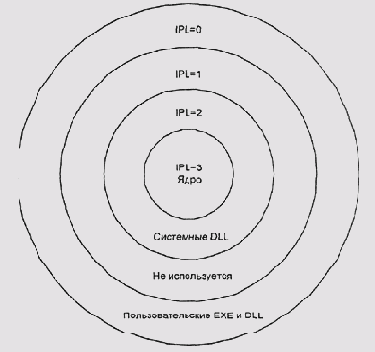
OS/2 использует три режима доступа: пользовательский, системные DLL и собственно ядро, из четырех, предоставляемых архитектурой х86 (Рисунок 5.10).
Windows NT (которая начинала свою карьеру как OS/2 New Technology) первоначально проектировалась как переносимая ОС. Требование переносимости на RISC-архитектуры с двумя уровнями привилегий заставило разработчиков отказаться от уровня системных DLL. Позже фирма Microsoft постепенно отказалась от поддержки всех аппаратных архитектур, кроме х86 (дольше всех они держались за DEC Alpha), но двухуровневая структура доступа так и осталась в новых версиях этой системы — Windows 2000/XP.
Коды защиты для различных
Таблица 5.1. Коды защиты для различных режимов доступа процессора VAX. Цитируется по [Прохоров, 1990]
| Код | Kernel | Executive | Supervisor | User |
| 0000 | - | - | - | - |
| 0001 | Не предсказуем | |||
| 0010 | RW | - | - | - |
| 0011 | R | - | - | - |
| 0100 | RW | RW | RW | RW |
| 0101 | RW | RW | - | - |
| 0110 | RW | R | - | - |
| 0111 | R | R | - | - |
| 1000 | RW | RW | RW | - |
| 1001 | RW | RW | R | - |
| 1010 | RW | R | R | - |
| 1011 | R | R | R | - |
| 1100 | RW | RW | RW | R |
| 1101 | RW | RW | R | RW |
| 1110 | RW | R | R | R |
| 1111 | R | R | R | R |
R — право чтения, W — право записи,------отсутствие прав.
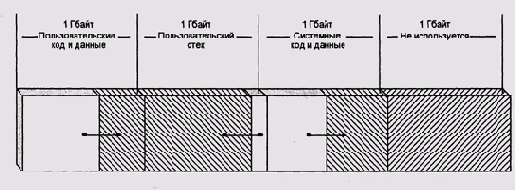
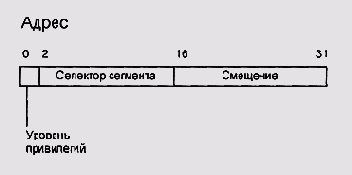
32-битное адресное пространство процессора VAX разбито на четыре части, каждая объемом по гигабайту. Первый гигабайт адресов предназначен для кода и данных пользовательской программы, второй — для пользовательского стека, третий — для системы, четвертый не используется (Рисунок 5.7). Каждая из частей имеет собственный указатель на таблицу дескрипторов страниц. Важно отметить, что деление адресного пространства на таблицы не обязательно связано с правами доступа на отдельные страницы — в системной таблице могут быть страницы, доступные для записи из пользовательского режима (на практике этого никогда не бывает, но на уровне диспетчера памяти контроля за этим не реализовано), а в пользовательской — страницы, доступные только ядру.
Сравнительные характеристики
Таблица 5.2. Сравнительные характеристики и стоимость различных типов памяти
| Тип памяти | Время доступа | Цена 1 Мбайта (цены 1995 г.) | Способ использования |
| Статическая память | 15 нc | $200 | Регистры, кэш-память |
| Динамическая память | 70 нc | $30 (4 Мбайт SIMM) | Основная память |
| Жесткие магнитные диски | 1-10 мс | $3 (1.2Gb HIDE) | Файловые системы, устройства свопинга |
| Магнитные ленты | Секунды | $0.025 (8mm Exabyte) | Устройства резервного копирования |
При разработке системы всегда есть желание сделать память как можно более быстрой. С другой стороны, потребности в памяти очень велики и постоянно растут.
Примечание
Примечание
Существует эмпирическое наблюдение, что любой объем дисковой памяти будет полностью занят за две недели.
Очевидно, что система с десятками гигабайтов статического ОЗУ будет иметь стоимость, скажем так, совершенно не характерную для персонапь-ных систем, не говоря уже о габаритах, потребляемой мощности и прочем. К счастью, далеко не все, что хранится в памяти системы, используется одновременно. В каждый заданный момент исполняется только часть установленного в системе программного обеспечения, и работающие программы используют только часть данных.
Эмпирическое правило "80—20", часто наблюдаемое в коммерческих системах обработки транзакций, гласит, что 80% операций совершаются над 20% файла [Heising 1963]. В ряде работ, посвященных построению оптимизирующих компиляторов, ссылаются на правило "90-10" (90% времени исполняется 10% кода) — впрочем, есть серьезные основания сомневаться в том, что в данном случае соотношение именно таково [Кнут 2000, т. 3].
В действительности, удивительно большое количество функций распределения реальных дискретных величин (начиная от количества транзакций на строку таблицы и заканчивая распределением богатства людей или капитализации акционерных обществ) подчиняются закону Парето [Pareto 1897]:
Таблица процедурного связывания)
Таблица процедурного связывания) (Рисунок 5.16). Каждый разделяемый модуль имеет свои собственные таблицы. Порожденный компилятором код определяет адреса этих таблиц, зная их смещение в разделяемом объекте относительно точки входа функции (см. примеры 3.7 и 5.1)
Точки входа системных подпрограмм VAX/VMS
Рисунок 5.8. Точки входа системных подпрограмм VAX/VMS
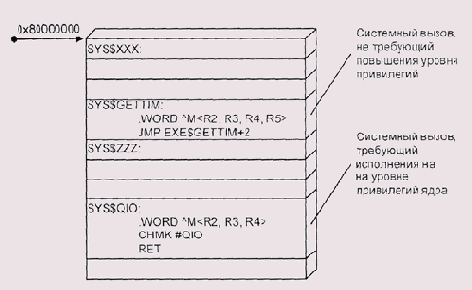
Процедура, работающая в "повышенном" (более привилегированном) режиме процессора, имеет полный доступ ко всем данным режимов с более низким уровнем доступа. Благодаря этому мы можем передать привилегированной процедуре указатель, и она доберется до наших данных простым разрешением этого указателя, без каких бы то ни было специальных команд.
Впрочем, при таком подходе возникает определенная проблема. Поскольку система и пользователь находятся в одном адресном пространстве, пользователь может "подсунуть" системе указатель на страницу, к которой сам не имеет доступа — например, попросить считать нечто из файла в системный сегмент данных. Для исключения таких ситуаций VAX предоставляет команды PROBSR и PROBEW, которые проверяют, существует ли доступ к указанной странице в предыдущем режиме работы процессора. Как мы помним, предыдущий режим сохраняется не только в стеке, но и в слове состояния процесса, и нужно это именно для таких проверок.
Видно, что обойтись без специальных команд все-таки не удалось. К тому же платой за принятое в VAX техническое решение оказалось сокращение полезного адресного пространства задачи в два, а на самом деле даже в четыре (кому нужен стек размером 1 Гбайт?) раза. В 70-е годы, когда разрабатывался VAX, это еще не казалось проблемой.
Управление свопфайлом
Управление своп-файлом
Для хранения образов модифицированных страниц система должна выделить какое-то пространство на диске. Для этого может использоваться как раздел диска, так и файл, место для которого выделяется наравне с файлами данных. Большинство современных систем может использовать как тот, так и другой методы, и поддерживает динамическое подключение и отключение своп-файлов и своп-разделов.
При наличии в системе нескольких дисков рекомендуется разделить своп-пространство между всеми (или хотя бы между менее используемыми) дисками. Дело в том, что операции чтения и записи требуют времени на позиционирование считывающей головки. Пока один накопитель передвигает головку, второй вполне может передавать данные. Понятно, что линейного роста производительности с увеличением числа дисков таким способом не получить: всегда есть вероятность, что все требуемые данные окажутся на одном диске, да еще и находятся в разных местах, но все равно выигрыш в большинстве случаев оказывается значительным.
В те времена, когда компьютеры были большими, для свопа часто использовались не диски, а специальные устройства, магнитные барабаны. В отличие от диска, который имеет одну или, реже, несколько головок чтения-записи, барабан имел по одной головке на каждую дорожку. Конечно, это повышало стоимость устройства, но полностью исключало потери времени на позиционирование (Рисунок 5.23).
в близком направлении продвинулись разработчики
Уровни доступа 80286
Чуть дальше в близком направлении продвинулись разработчики 80286: у этого процессора уровень доступа определяется старшими двумя битами селектора сегмента (Рисунок 5.9). Код, исполняющийся в сегменте с уровнем доступа 2, имеет доступ ко всем сегментам своего и более низких уровней. Межсегментный переход с повышением уровня доступа возможен лишь через сегменты со специальным дескриптором, так называемые шлюзы (gate).
Системы семейства Unix используют х86
Рисунок 5.10. Уровни доступа в OS/2
Системы семейства Unix используют х86 как нормальную 32-разрядную машину с двухуровневым доступом: пользовательской задаче выделяется один сегмент, ядру— другой. 4-х гигабайтового сегмента х86, разбитого на страницы размером по 4 Кбайт, достаточно для большинства практических целей. Например, в Linux системный вызов исполняется командой int 8Oh. Селектор пользовательского сегмента помещается в регистр FS. Для доступа к этому сегменту из модулей ядра используются процедуры memcpy_from_fs и memcpy_to_fs.
Многоуровневый доступ, основанный на концепции колец, не имеет принципиальных преимуществ по сравнению с двумя уровнями привилегий. Как и в двухуровневой системе, пользовательские модули вынуждены полностью доверять привилегированным, привилегированные же модули не могут защититься даже от ошибок в собственном коде. Самое лучшее, что может сделать Windows XP, обнаружив попытку обращения к недопустимому адресу в режиме ядра, — это нарисовать на синем экране дамп регистров процессора. В OS/2, фатальная ошибка в привилегированных модулях, исполняемых во втором кольце защиты, не обязательно приводит к остановке ядра, но подсистема, в которой произошла ошибка, оказывается неработоспособна. Если испорчен пользовательский интерфейс или сетевая подсистема, система в целом становится бесполезной и нуждается в перезагрузке.
Кроме того, разделение адресных пространств создает сложности при разделении кода и данных между процессами: разделяемые объекты могут оказаться отображены в разных процессах на разные адреса, поэтому в таких объектах нельзя хранить указатели (подробнее см. разд. Разделяемые библиотеки). Стремление обойти эти трудности и создать систему, в которой сочетались бы преимущества как единого (легкость и естественность межпроцессного взаимодействия), так и раздельных (защита процессов друг от друга) адресных пространств, многие годы занимало умы разработчиков аппаратных архитектур.
Например, машины фирмы Burroughs предоставляли пользователю и системе единое адресное пространство, разбитое на сегменты (единую таблицу дескрипторов сегментов). При этом возникает вопрос: если все задачи используют одну таблицу, как может получиться, что разные задачи имеют разные права на один и тот же сегмент?
Решение этого вопроса состоит в том, что права доступа кодируются не дескриптором, а селектором сегмента. Таким образом, разные права доступа на один сегмент — это, строго говоря, разные адреса. Понятно, что такое разделение работает лишь постольку, поскольку пользовательская программа не может формировать произвольные селекторы. В компьютерах Burroughs это достигалось теговой архитектурой: каждое слово памяти снабжалось дополнительными битами, тегом (tag), который определял тип данных, хранимых в этом слове, и допустимые над ним операции. Битовые операции над указателями не допускались. Благодаря этому задача не могла сформировать не только произвольные права доступа, но и вообще произвольный указатель.
Аналогичным образом реализована защита памяти в AS/400
Уточнение
Рисунок 5.13. Уточнение
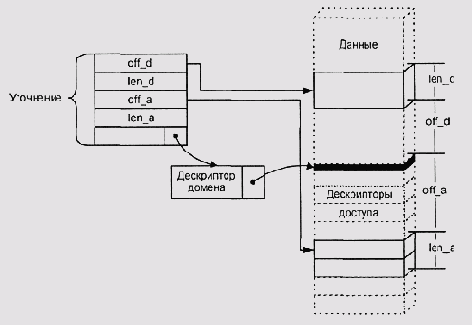
Целевой объект также может оказаться уточнением, и диспетчер памяти будет повторять процедуру до тех пор, пока не дойдет до объекта, ссылающегося на физическую память. Более подробно этот механизм описан в работе [Органик 1987].
Уточнения позволяют решить проблему выдачи мандатов— мандат реализуется как уточнение исходного объекта (например, сегмента данных модуля в котором выделен буфер), а программе-получателю передается даже не само уточнение, а лишь дескриптор доступа к нему. Для прекращения действия мандата достаточно удалить дескриптор уточнения. После этого все переданные другим модулям дескрипторы доступа будут указывать в пустоту, т. е. станут недействительными. Задачи же перемещения в памяти и сброса объектов на диск решаются путем изменения физического адреса или признака п(в|рутствия целевого объекта; для этого не требуется прослеживать цепочку уточнений.
Однако накладные расходы, связанные с реализацией этого сложного механизма, оказались очень большими. Процессор i432 остался экспериментальным и не получил практического применения. Трудно сказать, какой из факторов оказался важнее: катастрофически низкая производительность системы (автору не удалось найти официальных заявлений фирмы Intel по этому поводу, но народная мудрость утверждает, что экспериментальные образцы i432 с тактовой частотой 20 МГц исполняли около 20 000 операций в секунду) или просто неспособность фирмы Intel довести чрезмерно сложный кристалл до массового промышленного производства. Так или иначе, едва ли не единственной практической пользой, извлеченной из этого амбициозного проекта, оказалось тестирование системы автоматизированного проектирования, использованной впоследствии при разработке процессора 80386 и сопутствующих микросхем.
После завершения проекта I432 других попыток полностью реализовать взаимно недоверяющие подсистемы не делалось — изготовители коммерческих систем, по-видимому, сочли эту идею непродуктивной, а исследовательским организациям проекты такого масштаба просто не по плечу.
Виртуальная память и режимы процессора VAX
Виртуальная память и режимы процессора VAX
Например, миникомпьютеры VAX имеют четыре режима работы процессора (в порядке возрастания прав доступа): режим пользователя (User), режим супервизора (Supervisor), режим исполнителя (Executive) и режим ядра (Kernel) Режим работы определяется битами 22 и 23 в слове состояния процессора (Рисунок 5.5). Каждый из режимов имеет собственный указатель стека. Операционная система VAX/VMS использует три из доступных режимов (пользовательский, исполнительный и ядра), a BSD Unix - только два.
Каждая страница адресного пространства может иметь различные права доступа для разных режимов. При этом соблюдаются следующие правила.
1. Допустимы только права чтения и записи. 2. Право записи всегда выдается вместе с правом чтения. 3. Каждый более привилегированный режим всегда имеет те же права, которые имеют менее привилегированные режимы, плюс, возможно, какие-то еще. Такая организация доступа называется кольцами защиты.Виртуальная память VAX/VMS
Рисунок 5.19. Виртуальная память VAX/VMS
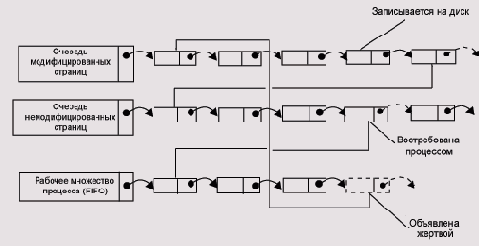
Обрабатывая страничный отказ, система не обращается к диску за содержимым требуемой страницы, а сначала пытается найти ее в одной из очередей пула. Если страница там, ее без дальнейших вопросов включают в адресное пространство задачи (Рисунок 5.20).
Такой алгоритм порождает много лишних страничных отказов, но обеспечивает большую экономию обращений к диску. У VAX/VMS эта стратегия сочетается с управлением объемом пула страниц: у каждого пользователя есть квота на объем рабочего множества запущенных им программ. При превышении квоты ОС и осуществляет поиск жертвы среди адресных пространств задач этого пользователя. При разумном управлении этими квотами система обеспечивает весьма хорошие показатели даже при небольших объемах оперативной памяти.
Windows NT (и более поздние версии этой системы, 2000/ХР) пытается управлять пулом свободных страниц динамически, не предоставляя администратору никаких средств для прямой настройки. Поэтому на нехватку ОЗУ или нетипичный режим использования памяти эта система реагирует резким падением производительности. По-видимому, это падение обусловлено развитием автоколебаний в динамической настройке пула свободных страниц.
Так, автору удавалось привести в неработоспособное состояние Windows 2000 Wokrstation с 256 Мбайт ОЗУ, всего лишь открыв по ошибке для редактирования в far файл объемом 64 Мбайт. Файл не превосходил 1/4 доступной оперативной памяти. Тем не менее, машина "впала в кому", не реагируя даже на <Ctrl>+<Alt>+<Del>, и находилась в этом состоянии достаточно долго для того,чтобы собрать вокруг нее консилиум системных администраторов и, в конце концов, решить, что проще нажать на кнопку системного сброса.
Взаимно недоверяющие подсистемы
Взаимно недоверяющие подсистемы
| — Вы куда? — У меня там портфель! — Я вам его принесу! — Я вам не доверяю. У меня там ценный веник. ("Ирония судьбы или с легким паром!") Г. Горин |
С точки зрения безопасности, основной проблемой систем с кольцами защиты является неспособность таких систем защитить себя от ошибок в модулях, исполняющихся в высшем кольце защиты. В свете этого, очень привлекательной концепцией представляется идея взаимно недоверяющих подсистем.
Согласно этой концепции, пользовательская задача не должна предоставлять системе доступа ко всем своим данным. Вместо этого задача должна выдавать мандат на доступ к буферу или нескольким буферам, предназначенным для обмена данными. Все акты обмена данными как между пользовательской задачей и системой, так и между двумя пользовательскими задачами или двумя модулями системы, также осуществляются при помощи передачи мандатов.
Например, при исполнении системного вызова int read (int file, void * buf, size_t size) программа должна передать системе мандат на право записи в буфер buf размером size байт (Рисунок 5.11). При этом буфер будет отображен в адресное пространство подсистемы ввода/вывода, но эта подсистема не получит права записи в остальное адресное пространство нашей задачи. Впрочем, этот подход имеет две очевидные проблемы.
Менее очевидный, но более серьезный
Рисунок 5.15. Загрузка DLL в OS/2 и Win32
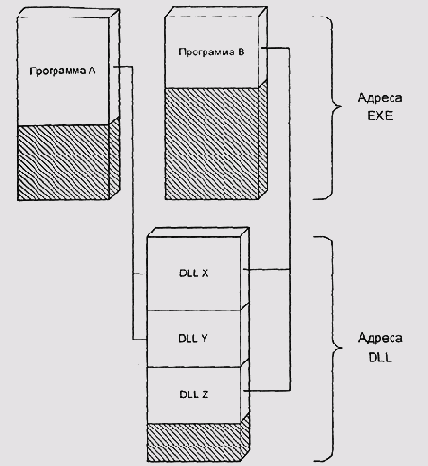
Менее очевидный, но более серьезный недостаток состоит в том, что эта архитектура не позволяет двум приложениям одновременно использовать Две разные, но одноименные DLL — например, две разные версии стандартной библиотеки языка С. Поэтому либо мы вынуждены требовать от всех разделяемых библиотек абсолютной (bug-fbr-bug) совместимости версий, либо честно признать, что далеко не каждая смесь прикладных программ будет работоспособна. Первый вариант нереалистичен, второй же создает значительные неудобства при эксплуатации, особенно если система интерактивная и многопользовательская.
Лишенное обоих недостатков решение предлагают современные системы семейства Unix, использующие загружаемые модули формата ELF. Впрочем, для реализации этого решения пришлось, ни много, ни мало, переделать компилятор и научить его генерировать позиционно-независимый код (см. разд. Позиционно-независимый код).
Разделяемые библиотеки формата ELF
Исполняемые модули формата ELF бывают двух типов: статические — полностью самодостаточные, не использующие разделяемых объектов, и динамические — содержащие ссылки на разделяемые объекты и неразрешенные символы. И статические, и динамические модули являются абсолютными. При создании образа процесса система начинает с того, что отображает старчески собранный исполняемый объект в адресное пространство. Статический модуль не нуждается ни в какой дополнительной настройке и может начать исполнение сразу после этого.
Для динамического же загрузочного модуля система загружает так называемый интерпретатор, или редактор связей времени исполнения (run-time linker), no умолчанию ld.so.1. Он исполняется в контексте процесса и осуществляет подгрузку разделяемых объектов и связывание их с кодом основного модуля и друге другом.
При подгрузке разделяемый объект также отображается в адресное пространство формируемого процесса. Отображается он не на какой-либо фиксированный адрес, а как получится, с одним лишь ограничением: сегменты объекта будут выровнены на границу страницы. Не гарантируется даже, что адреса сегментов будут одинаковы при последовательных запусках одной и той же программы.
Документ [HOWTO Library] без обиняков утверждает, что в разделяемых объектах можно использовать только код, компилированный с ключом -? рте. Документ [docs.sun.com 816-0559-10] менее категоричен:
"Если разделяемый объект строится из кода, который не является позиционно-независимым, текстовый сегмент скорее всего потребует большое количество перемещений во время исполнения. Хотя редактор связей и способен их обработать, возникающие вследствие этого накладные расходы могут вести к серьезному снижению производительности".
Как уже говорилось в разд. 3.5, используемый в разделяемых объектах код не является истинно позиционно-независимым: он содержит перемещаемые и даже настраиваемые адресные ссылки, такие, как статически инициализованные указатели и ссылки на процедуры других модулей. Но все эти ссылки размещены в сегменте данных. Используемые непосредственно в коде ссылки собраны в две таблицы, GOT (Global Offset Table, Глобальная таблица смещений) и PL Т (Procedure Linkage Table,
