[Docs sun com 805737810] основное
[docs.sun.com 805-7378-10] основное из этих требований — не забывать о том, что ядро Solaris многопоточное, и любая из нитей ядра может быть в любой момент вытеснена [практически любой] другой нитью — высказывается на второй странице, а выводам, которые из этого следуют, посвящена целая глава.
При разработке системы с нуля это само по себе не представляет проблемы, но если мы хотели бы обеспечить совместимость с драйверами внешних устройств и другими модулями ядра предыдущих версий ОС...
Из материала предыдущей главы легко понять, что код, рассчитанный на работу в однопоточной среде или среде кооперативной многозадачности, при переносе в многопоточную среду нуждается в значительной переработке, а нередко и в перепроектировании. Таким образом, сделать из монолитной (пусть даже модульной) системы микроядерную практически невозможно.
Следует учитывать, что требование поддержки многопроцессорных машин Или приложений реального времени часто предъявляется к разработчикам через много лет после того, как были приняты архитектурные решения. о этой ситуации разработчики часто не переходят на микроядерную архитектуру полностью, а создают архитектуру гибридную (или, если применить более эстетский термин, эклектичную).
Действительно, как говорилось ранее, в чистом микроядре взаимодействия Происходят асинхронно, а в чистом монолитном ядре — синхронно.
Если некоторые из взаимодействий происходят асинхронно (что например, в многопроцессорной машине), то мы можем сказать, что система частично микроядерная. Если же некоторые из взаимодействий обязательно синхронны, мы, наверное, вынуждены будем признать, что цаи система частично монолитная, как бы странно это ни звучало.
В зависимости от того, какого рода взаимодействия преобладают, мы може выстроить целый спектр более или менее монолитных (и, напротив, боле или менее микроядерных) архитектур. На практике, большинство современных ОС общего назначения имеют гибридную архитектуру, которая не является микроядерной, и в то же время не может быть классифицирована как монолитная. Многие из архитектур и, во всяком случае, многие из ключевых принципов взаимодействия между модулями современных операционных систем были разработаны еще до того, как появилось само слово "микроядро". При этом некоторые из этих взаимодействий имеют синхронный, а некоторые — особенно взаимодействие с драйверами внешних устройств — асинхронный характер.
Во многих современных ОС широко применяется взаимодействие драйверов с остальной системой посредством очередей запросов (или событий). Такое взаимодействие отчасти стирает различия между синхронным и полностью асинхронным межмодульным взаимодействием.
Docs sun com 805737810]
docs.sun.com 805-7378-10].
Далее мы будем называть последние две категории нитей, соответственно, пользовательскими и системными, хотя и те, и другие исполняют системный код в системном адресном пространстве.
Обработчики прерываний всегда представляют собой особую статью — система практически никогда не имеет контроля над тем, когда возникают внешние события, зато практически всегда обязана обрабатывать эти события по мере их появления. Поэтому обработчики прерываний получают управление по необходимости.
В то же время, порядок получения управления пользовательскими и системными нитями в ряде ситуаций находится под контролем системы. Планировшик является частью ядра и модули системы вольны включать его и выключать по мере необходимости. Практически всегда его выключают на время работы обработчика прерывания, но некоторые системы делают это и при активизации других нитей ядра.
Полное выключение планировщика на время работы ядра фактически означает что система не реализует внутри ядра вытесняющей многозадачности. Системные и пользовательские нити в этом случае являются сопрограммами а не нитями в полном смысле этого слова.
Эта архитектура, называемая монолитным ядром, привлекательна примерно тем же, чем привлекательна кооперативная многозадачность на пользовательском уровне: любой модуль ядра может потерять управление лишь в двух случаях — при исполнении обработчика прерывания или по собственной инициативе. Благодаря этому разработчик модуля может не беспокоиться о критических секциях и прочих малоприятных аспектах доступа к разделяемым данным (кроме, разумеется, случаев, когда разделяет данные с обработчиком прерывания).
Платить за эти преимущества приходится значительными сложностями при переносе системы на многопроцессорные машины и невозможностью реализовать режим реального времени. Действительно, код ядра, написанный в расчете на кооперативную многозадачность, не может быть реентерабельным, поэтому такая система в то время, когда исполняется какая-то из ее нитей, не может обрабатывать системные вызовы. Следовательно, она не может иметь пользовательские процессы с приоритетом выше, чем у нитей ядра — а именно такие процессы нужны для поддержки приложений реального времени.
Примечание
Примечание
Те из читателей, кто когда-либо пытался реализовать обработку аппаратных прерываний под MS/DR DOS, должны быть хорошо знакомы с этой проблемой. Вопреки хакерскому фольклору, нереентерабельность ядра DOS связана вовсе не с переустановкой указателя стека при входе в обработчик прерывания 21h, а именно с тем, что ядро работает с разделяемыми данными, но не предоставляет собственных средств для взаимоисключения доступа к ним.
Впрочем, если нам не требуется реальное время и перед нами не стоит задача обеспечить равномерное распределение системных нитей между процессорами симметрично многопроцессорной машины, монолитное ядро вполне приемлемо. Большинство систем семейств Unix (фактически, все широко распространенные системы этого семейства, кроме System V R4) и Win32, OS/2 и ряд других систем общего назначения более или менее успешно ее используют.
Альтернативной монолитным ядрам является микроядро. Микроядерные системы реализуют вытесняющую многозадачность не только между пользовательскими процессами, но и между нитями ядра.
Контексты современных процессоров
Контексты современных процессоров
У современных процессоров, имеющих десятки регистров общего назначения и виртуальную память, размер контекста процесса измеряется сотнями байтов. Например, у процессора VAX контекст процессора состоит из 64 32-разрядных слов, т. е. 256 байт. При этом VAX имеет только 16 регистров общего назначения, а большая часть остальных регистров так или иначе относится к системе управления виртуальной памятью.
У микропроцессоров SPARC, имеющих регистровый файл объемом до нескольких килобайтов, контекст, на первый взгляд, должен быть чудовищного размера. Однако программе одновременно доступны лишь 32 регистра общего назначения, 24 из которых образуют скользящее по регистровому файлу окно. Благодаря этому факту, контекст процессора SPARC состоит только из первых восьми регистров общего назначения и служебных регистров. Регистровое окно новой нити выделяется в свободной области регистрового файла, а его передвижение обрабатывается при помощи исключений заполнения и очистки окна.
Если в системе всего несколько активных процессов, может оказаться так, что их регистровые окна постоянно "живут" в регистровом файле, поэтому объем данных, реально копируемых при переключении нитей, у SPARC не больше, чем у CISC-процессоров с небольшим количеством регистров общего назначения. Впрочем, и у SPARC, и у CISC-процессоров основную по объему часть контекста процесса составляют регистры диспетчера памяти.
На этом основано преимущество транспьютера перед процессорами традиционных и RISC-архитектур. Дело в том, что транспьютер не имеет диспетчера памяти, и у него вообще очень мало регистров. В худшем случае, при переключении процессов (в транспьютере, как и в старых ОС, нити называются процессами) должно сохраняться 7 32-разрядных регистров. В лучшем случае сохраняются только два регистра — счетчик команд и статусный регистр. Кроме того, перенастраивается регистр wptr, который выполняет по совместительству функции указателя стека, базового регистра сегмента статических данных процесса и указателя на дескриптор процесса.
Транспьютер имеет три арифметических регистра, образующих регистровый стек. При этом обычное переключение процессов может происходить только, когда этот стек пуст. Такая ситуация возникает довольно часто; например, этот стек обязан быть пустым при вызовах процедур и даже при условных и безусловных переходах, поэтому циклическая программа не может не иметь точек, в которых она может быть прервана. Упомянутые в предыдущем разделе команды обращения к линкам также исполняются при пустом регистровом стеке. Поэтому, оказывается достаточно перезагрузить три управляющих регистра, и мы передадим управление следующему активному процессу.
Операция переключения процессов, а также установка процессов в очередь при их активизации полностью реализованы на микропрограммном уровне.
Деактивизация процесса происходит только по его инициативе, когда он начинает ожидать сигнала от таймера или готовности линка. При этом процесс исполняет специальную команду, которая устанавливает его в очередь ожидающих соответствующего события, и загружает контекст очередного активного процесса. Когда приходит сигнал таймера или данные по линку, то также вызывается микропрограмма, которая устанавливает активизированный процесс в конец очереди активных.
У транспьютера также существует микропрограммно реализованный режим разделения времени, когда по сигналам внутреннего таймера активные про цессы циклически переставляются внутри очереди. Такие переключения ка уже говорилось, могут происходить только, когда регистровый стек текущег процесса пуст, но подобные ситуации возникают довольно часто.
Кроме обычных процессов в системе существуют так называемые высокопри оритетные процессы. Если такой процесс получает управление в результате внешнего события, то текущий низкоприоритетный процесс будет прерван независимо от того, пуст его регистровый стек или нет. Для того чтобы при этом не разрушить прерванный процесс, его стек и весь остальной контекст записываются в быструю память, расположенную на кристалле процессора. Это и есть тот самый худший случай, о котором говорилось ранее. Весь цикл переключения занимает 640нс по сравнению с десятками и, порой, сотнями микросекунд у традиционных процессоров [INMOS 72 TRN 203 02, Харп 1993].
Благодаря такой организации транспьютер не имеет равных себе по времени реакции на внешнее событие. На первый взгляд, микропрограммная реализация такой довольно сложной конструкции, как планировщик, снижает гибкость системы. В действительности, в современных системах планировщики имеют довольно стандартную структуру, и реализация, выполненная в транспьютере, очень близка к этому стандарту, известному как микроядро (microkernel) (см. разд. Монолитные системы или системы с микроядром).
Кооперативная многозадачность
Кооперативная многозадачность
По-видимому, самой простой реализацией многозадачной системы была бы библиотека подпрограмм, которая определяет следующие процедуры.
struct Thread; В тексте будет обсуждаться, что должна представлять собой эта структура, называемая дескриптором нити. Thread * ThreadCreate(void (*ThreadBody)(void)); Создать нить, исполняющую функцию ThreadBody. void Threadswitch(); Эта функция приостанавливает текущую нить и активизирует очередную, готовую к исполнению. void ThreadExit () ; Прекращает исполнение текущей нити. Сейчас мы не обсуждаем методов синхронизации нитей и взаимодействия
между ними (для синхронизации были бы полезны также функции void
DeactivateThread(); И void ActivateThread(struct Thread *) ;). Нас интересует только вопрос: что же мы должны сделать, чтобы переключить нити?
функция ThreadSwitch называется диспетчером или планировщиком (scheduler) и ведет себя следующим образом.
Очевидно, что функцию ThreadSwitch нельзя реализовать на языке высокого уровня, вроде С, потому что это должна быть функция, которая не возвращает [немедленно] управления в ту точку, из которой она была вызвана. Она вызывается из одной нити, а передает управление в другую. Это требует прямых манипуляций стеком и записью активизации и обычно достигается использованием ассемблера или ассемблерных вставок. Некоторые ЯВУ (Ada, Java, Occam) предоставляют примитивы создания и переключения нитей в виде специальных синтаксических конструкций.
Самым простым вариантом, казалось бы, будет простая передача управления на новую нить, например, командой безусловной передачи управления по указателю. При этом весь описатель нити (struct Thread) будет состоять только из адреса, на который надо передать управление. Беда только в том, что этот вариант не будет работать.
Действительно, каждая из нитей исполняет программу, состоящую из вложенных вызовов процедур. Для того чтобы нить нормально продолжила исполнение, нам нужно восстановить не только адрес текущей команды, но и стек вызовов (см. разд. Косвенно-регистровый режим со смещением). Поэтому мы приходим к такой архитектуре.
Микроядро QNX
Микроядро QNX
Классическая реализация микроядра, QNX, состоит из вытесняющего планировщика и примитивов гармонического межпоточного взаимодействия, средств для обмена сообщениями send и receive. Эти примитивы, конечно же, сами по себе не могут быть реализованы реентерабельным образом, однако они просты, содержат очень мало кода, исполняются быстро, и на время их исполнения система просто запрещает прерывания.
Все остальные модули системы с точки зрения микроядра представляют соб полностью равноценные нити. То, что некоторые из этих нитей исполняю в пользовательском, а другие — в привилегированном режиме доступа микC" ядру совершенно неинтересно и не влияет на их приоритет и класс планировани QNX разрабатывался для приложений реального времени, в том числе и лл использования во встраиваемых микропроцессорных системах; но, благодап компактности и фантастической производительности, эта ОС иногда заменяв системы общего назначения. Микроядро QNX действительно заслуживает на звания микро, поскольку занимает всего 12 килобайт кода и полностью входит в кэш первого уровня даже старых процессоров архитектуры х86. Все остальные модули ядра — драйверы внешних устройств, файловых систем, сетевых протоколов, имитация API систем семейства Unix — динамически загружаются и выгружаются и не являются обязательными (если, конечно, приложение не требует сервисов, предоставляемых этими модулями). Благодаря этому ОС может использоваться во встраиваемых приложениях с весьма небольшим объемом ПЗУ.
Микроядро транспьютера
Микроядро транспьютера
Другим примером классического микроядра является транспьютер. Микропрограммно реализованное микроядро транспьютера содержит планировщик с двумя уровнями приоритета и средства для передачи данных по линкам.
Другие системы микроядерной архитектуры, например
Микроядро Unix SVR4
Другие системы микроядерной архитектуры, например Unix System \/ Release 4.x (на этом ядре построены такие ОС, как Sun Solaris, SCO UnixWare, SGI Irix), предоставляют нитям ядра гораздо больше примитивов межпроцессного взаимодействия — в частности, мутексы. Ядро у этих систем в результате получается не таким уж "микро", но нашему определению это никоим образом не противоречит.
Важно подчеркнуть, что приведенное определение не имеет отношения к ряду других критериев, которые иногда (например, в дискуссиях в публичных компьютерных сетях, а нередко и в публикациях в более или менее серьезных журналах) ошибочно принимают за обязательные признаки микроядерной архитектуры. Отчасти эта путаница, возможно, создавалась целенаправленно, потому что в середине 90-х "микроядро" стало популярным маркетинговым слоганом, и поставщикам многих ОС монолитной или эклектичной архитектуры захотелось получить свою долю выгоды от возникшей шумихи.
Способ сборки ядра (динамическое или статическое связывание ядра с дополнительными модулями) и возможность динамической загрузки и выгрузки модулей без перезагрузки системы к микроядерности не имеют никакого отношения. Вполне микроядерная SCO UnixWare по умолчанию предлагает собирать ядро в единый загрузочный файл /stand/unix (хотя, впрочем, и поддерживает динамическую загрузку модулей). Напротив, не то, что монолитная, а кооперативно многозадачная Novell Netware замечательным образом умеет загружав и выгружать на ходу любые модули, в том числе и драйверы устройств (выгружать, разумеется, лишь при условии, что модуль никем не используется).
Один из корней этих заблуждений состоит в том, что в большинстве других контекстов антонимом "монолитной" архитектуре считается архитектура модульная. Таким образом, любой признак, свидетельствующий о том, что ядро ОС имеет модульную структуру, считается признаком микроядерности. В данном случае, однако, дихотомия "монолитность/микроядерность" говорит не о наличии или отсутствии в ядре более или менее автономных модулей или подсистем, а о принципах взаимодействия между этими модулями или подсистемами или, точнее, об одном аспекте этого взаимодействия: о том, что в монолитных ядрах взаимодействие происходит синхронно или преимущественно синхронно, а в микроядре — асинхронно.
Совсем уж наивно было бы отказывать Solaris в праве называться микроядерным на том основании, что файл /kernel/genunix у этой системы имеет размер около 900 килобайт. Ведь, кроме собственно микроядра — планировщика нитей и примитивов взаимодействия между ними — этот файл содержит также диспетчер системных вызовов, систему динамической подгрузки других модулей ядра (см. разд. Загрузка самой ОС) и ряд других обязательных подсистем. Микроядро концептуально очень привлекательно, но предъявляет к разработчикам модулей ядра известные требования. Например, в документе
Монолитные системы и системы с микроядром
Монолитные системы и системы с микроядром
| Не бывет монолитных программ, бывают плохо структурированные Реплика с семинара по ООП Ходовая часть танка работает в экстремальных условиях и с трудом поддается модернизации |
Исполняя системный вызов, пользовательская программа передает управление ядру. С понятием ядра — комплекса программ, исполняющихся в привилегированном (системном) режиме процессора, — мы уже сталкивались в разд. Системы с базовой виртуальной адресацией и главе 5. Практически во всех современных системах ядро представляет собой единый процесс — единое адресное пространство. Но организация взаимодействия между нитями этого процесса в различных системах устроена по-разному.
Три основные группы нитей, исполняющихся в режиме ядра, — это, во-первых, обработчики прерываний, во-вторых — обработчики системных вызовов со стороны пользовательских процессов и, в-третьих, — нити, исполняющие различные внутренние по отношению к системе работы, например, управление дисковым кэшем. В документации фирмы Sun нити этих трех групп в ядре Solaris называются, соответственно, исполняющимися в контексте прерывания (interrupt context), в пользовательском контексте (user context) и в контексте ядра (kernel context, или контексте системы) [
Планировщики с приоритетами
Планировщики с приоритетами
В многозадачных системах часто возникает вопрос: в каком порядке исполнять готовые процессы? Как правило, бывает очевидно, что одни из процессов важнее других. Например, в системе может существовать три процесса, имеющих готовые к исполнению нити: процесс — сетевой файловый сервер, интерактивный процесс — текстовый редактор и процесс, занимающийся плановым резервным копированием с диска на ленту. Очевидно, что хотелось бы в первую очередь разобраться с сетевым запросом, затем — отреагировать на нажатие клавиши в текстовом редакторе, а резервное копирование может подождать сотню-другую миллисекунд. С другой стороны, мы должны защитить пользователя от ситуаций, в которых какой-то процесс вообше не получает управления, потому что система постоянно занята более приоритетными заданиями.
Действительно, вы запустили то же самое резервное копирование, и сели играть в тетрис или писать письмо любимой женщине, а после получаса игры обнаружили, что ни одного байта не скопировано — процессор все время был занят.
Самым простым и наиболее распространенным способом распределения процессов по приоритетам является организация нескольких очередей в соответствии с приоритетами. При этом процесс из низкоприоритетной очереди получает управление тогда и только тогда, когда все очереди с более высоким приоритетом пусты.
Кооперативный переключатель
Пример 8.1. Кооперативный переключатель потоков
Thread * thread_queue_head;
Thread * thread_queue_tail;
Thread * current_tread;
Thread * old__thread;
void TaskSwitch () { old_thread=current_thread; add_to_queue_tail(current_thread); current_thread=get_from_queue_head(); asm { .
move bx, old_thread
push bp
move ax, sp
move thread_sp[bx], ax
move bx, current_thread
move ax, rhread_sp[bx]
pop bp
}
return;
}
Если система программирования предполагает, что при вызове функции должны сохраняться определенные регистры (как, например, С-компиляторы для х86 сохраняют при вызовах регистры SI и DI (ESI/EDI в 1386)), то они также сохраняются в стеке. Поэтому предложенный нами вариант также будет автоматически сохранять и восстанавливать все необходимые регистры.
Понятно, что кроме указателей стека и стекового кадра, struct Thread должна содержать еще некоторые поля. Как минимум, она должна содержать указатель на следующую активную нить. Система должна хранить указатели на описатель текущей нити и на конец списка. При этом ThreadSwitch переставляет текущую нить в конец списка, а текущей делает следующую за ней в списке. Все вновь активизируемые нити также ставятся в конец списка. При этом список не обязан быть двунаправленным, ведь мы извлекаем элементы только из начала, а добавляем только в конец.
Часто в литературе такой список называют очередью нитей (thread queue) или очередью процессов. Такая очередь присутствует во всех известных автору реализациях многозадачных систем. Кроме того, очереди нитей используются и при организации очередей ожидания различных событий, например, при реализации семафоров Дейкстры.
Планировщик, основанный на Threadswitch, т. е. на принципе переключения по инициативе активной нити, используется в ряде экспериментальных и учебных систем. Этот же принцип, называемый кооперативной многозадачностью, реализован в библиотеках языков Simula 67 и Modula-2. MS Windows 3.x также имеют средство для организации кооперативного переключения задач — системный вызов GetNextEvent.
Часто кооперативные нити называют не нитями, а сопрограммами — ведь они вызывают друг друга, подобно подпрограммам. Единственное отличие такого вызова от вызова процедуры состоит в том, что такой вызов не ие-рархичен — вызванная программа может вновь передать управление исходной и остаться при этом активной.
Основным преимуществом кооперативной многозадачности является простота отладки планировщика. Кроме того, снимаются все коллизии, связанные с критическими секциями и тому подобными трудностями — ведь нить может просто не отдавать никому управления, пока не будет готова к этому.
С другой стороны, кооперативная многозадачность имеет и серьезные недостатки.
Во-первых, необходимость включать в программу вызовы Threadswitch усложняет программирование вообще и перенос программ из однозадачных или иначе организованных многозадачных систем в частности.
Особенно неприятно требование регулярно вызывать Threadswitch для вычислительных программ. Чаще всего такие программы исполняют относительно короткий внутренний цикл, скорость работы которого определяет скорость всей программы. Для "плавной" многозадачности необходимо вызывать Threadswitch из тела этого цикла. Делать вызов на каждом шаге Цикла нецелесообразно, поэтому необходимо будет написать код, похожий на приведенный в примере 8.2.
Внутрений цикл программы
Пример 8.2. Внутрений цикл программы в кооперативно многозадачной среде
int counter; // Переменная-счетчик,
while(condition) {
// Вызывать ThreadSwitch каждые rate циклов.
counter++;
if (counter % rate == 0) ThreadSwitch();
.... // Собственно вычисления j
}
Условный оператор и вызов функции во внутреннем цикле сильно усложняют работу оптимизирующим компиляторам и приводят к разрывам конвейера команд, что может очень заметно снизить производительность. Вызов функции на каждом шаге цикла приводит к еще большим накладным расходам и, соответственно, к еще большему замедлению.
Во-вторых, злонамеренная нить может захватить управление и никому не отдавать его. Просто не вызывать ThreadSwitch, и все. Это может произойти не только из-за злых намерений, но и просто по ошибке.
Поэтому такая схема оказывается непригодна для многопользовательских систем и часто не очень удобна для интерактивных однопользовательских.
Почему-то большинство коммерческих программ для Win16, в том числе и поставлявшиеся самой фирмой Microsoft, недостаточно активно использовали вызов GetNextEvent. Вместо этого такие программы монопольно захватывали процессор и рисовали известные всем пользователям этой системы "песочные часы". В это время система никак не реагирует на запросы и другие действия пользователя кроме нажатия кнопки
Функция переключения
Пример 8.3. Функция переключения контекста в ядре Linux/x86
/* Фрагмент файла \arch\i386\kernel\process.c.
* Сохранение и восстановление регистров общего назначения
* и сегментных регистров CS, DS и S3 осуществляется при входе в ядре *и при выходе из него соответственно. */
/*
* switch_to(х,у) должна переключать задачи с х на у *
* Мы используем fsave/fwait, поэтому исключения [сопроцессора]
* сбрасываются в нужный момент времени (пока вызов со стороны
* fsave или fwait обрабатывается), и не могут быть посланы
* другому процессу. Отложенное сохранение FP более не имеет
* смысла на современных ЦПУ и это многое упрощает (SMP и UP
* [uniprocessor, однопроцессорная конфигурация] теперь
* обрабатываются одинаково).
Раньше мы использовали аппаратное переключение
* контекста. Причина, по которой мы больше так не делаем
* становится очевидна, когда мы пытаемся аккуратно восстановиться
* из сохраненного состояния, которое стало недопустимым
* (в частности, висящие ссылки в сегментных регистрах).
* При использовании аппаратного переключения контекста нет способа
* разумным образом выйти из плохого состояния [контекста]. *
* То, что Intel документирует аппаратное переключение контекста как
* медленное — откровенная ерунда, этот код не дает заметного ускорения.
* Однако здесь есть некоторое пространство для улучшения, поэтому
* вопросы производительности могут рано или поздно оказаться актуальны.
* [В данном случае], однако, нам важнее, что наша реализация * обеспечивает большую гибкость.
*/ void __switch_to(struct task_struct *prev_p, struct task_struct *next_p)
(
struct thread_struct *prev = &prev_p->thread, Д *next = &next_p->thread;
struct tss_struct *tss = init_tss + smp_processor_id();
unlazy_fpu (prev__p) ;
/*
* Перезагрузить espO, LOT и указатель на таблицу страниц: */
tss->espO = next->espO;
/*
* Сохранить %fs и %gs. He нужно сохранять %ез и %ds,
* потому что при исполнении в контексте ядра это
* всегда сегменты ядра. */
asm volatile("movl %%fs,%0":"=m" (* (int *)&prev->fs)); asm volatile("movl %%gs,%0":"=m" (*(int *)&prev->gs));
* Восстановить Its и Ч
loadsegment(fs, next->fs); loadsegment(gs, next->gs);
/*
* Если это необходимо, перезагрузить отладочные регистры */ if (next->debugreg[7]){
loaddebug(next, 0};
loaddebug(next, 1);
loaddebug(next, 2);
loaddebug(next, 3);
/* не 4 и 5 */
loaddebug(next, 6);
loaddebug(next, 7);
if (prev->ioperm || next->iopenn) { if (next->ioperm) {
*
/*
* Копирование четырех линий кэша .... не хорошо, но
* и не так уж плохо. У кого-нибудь есть идея лучше?
* Оно воздействует только на процессы, использующие iopermO.
* [Размещение этих TSS в области 4K-tlb и игры с виртуальной
* памятью для переключения битовой маски ввода/вывода на
* самом деле неприемлемы.] */
memcpy(tss->io_bitmap, next->io_bitmap,
IO_BITMAP_SIZE*sizeof(unsigned long)); tss~>bitmap = IO_BITMAP_OFFSET; } else /*
* Смещение битовой маски, указывающее за пределы ограничителя "- - >
* порождает контролируемое SIGSEGV, если процесс пытается
* использовать команды обращения к портам. Первый вызов
* sys_ioperm() устанавливает битовую маску корректно. */
tss->bitmap = INVALID 10 BITMAP OFFSET;
Примечание
Примечание
Планировщик должен полностью сохранять контекст процесса. Это значительно усложняет жизнь разработчикам процессоров: добавив процессору лишний регистр (как служебный, так и общего назначения), мы рискуем потерять совместимость со всеми ОС для нашего процессора, реализующими вытесняющую многозадачность. Наличие команд сохранения контекста не решает этой проблемы — ведь ОС должна выделять память под сохраняемый контекст, а для этого необходимо знать его размер.
Именно поэтому, в частности, процессоры SPARC и х86 реализуют "мультимедийные" расширения систем команд (групповые операции над 8-битными целыми числами) с использованием уже существовавших регистров арифметического сопроцессора, а не дополнительных регистров.
Как правило, оказывается неудобным сохранять контекст именно в стеке. Тогда его сохраняют в какой-то другой области памяти, чаще всего в дескрипторе процесса. Многие процессоры имеют специальные команды сохранения и загрузки контекста. Для реализации вытеснения достаточно сохранить контекст текущей нити и загрузить контекст следующей активной нити из очереди. Необходимо предоставить также и функцию переключения нитей по их собственной инициативе, аналогичную ThreadSwitch или, точнее, DeactivateThread.
Обычно вместо DeactivateThread система предоставляет высокоуровневые примитивы синхронизации, например семафоры или примитивы гармонического взаимодействия. Вызов DeactivateThread оказывается скрытым внутри таких высокоуровневых функций.
Вытесняющий планировщик с разделением времени ненамного сложнее кооперативного планировщика — и тот, и другой реализуются несколькими десятками строк на ассемблере. В работе (Прохоров 1990| приводится полный ассемблерный текст приоритетного планировщика системы VAX/VMS, занимающий одну страницу (автору неизвестно, не нарушает ли авторские права фирмы DEC публикация этого текста). Впрочем, планировщики, рассчитанные на многопроцессорные машины, часто бывают несколько сложнее (пример 8.4).
функция планировщика. Это очень простой
Пример 8.4. Планировщик Linux 2.5
/*
* 'schedule!)' — функция планировщика. Это очень простой и
* приятный планировщик: он не совершенен, но несомненно работает
* в большинстве случаев.
* The goto is "interesting".
*
* ЗАМЕЧАНИЕ!! Задача 0 является 'пустой' задачей, которая вызывается
* когда ни одна другая задача не может выполняться. Она не может быть
* "убита" и не может "спать". Информация о состоянии в task[0] никогда
* не используется.
*/
asmlinkage void schedule(void)
{
struct schedule_data * sched_data;
struct task_struct *prev, *next, *p;
struct list_head *tmp;
int this__cpu, c;
if (!current->active_mm) BUG(); need_resched_back: prev = current; this_cpu = prev~>processor;
if (in_interrupt())
goto scheduling_in_interrupt;
release_kernel_lock(prev, this_cpu);
/* Выполнить административную работу здесь, пока мы не держим
* ни одной блокировки.
*/
if (softirq_active(this_cpu) & softirq_mask(this_cpu))
goto handle_softirq; handle_softirq_back:
/*
* 'shed data" защищена неявно, тем фактом, что мы можем исполнять
* только один процесс на одном ЦПУ. */
sched__data = & aligned_data[this_cpu].schedule_data;
spin_lock_irq (&runqueue__lock) ;
/* Переместить исчерпанный процесс RR в конец [очереди] */ if (prev->policy == SCHED_RR)
goto move_rr_last; pove_rr_back:
switch (prev->state) { case TASKJLNTERRUPTIBLE:
if (signal_pending (prev) ) { prev->state = TASK_RUNNING; break; } default:
dei_f rom_runqueue (prev) ; case TASK_RUNNING: ;
}
prev->need_resched = 0;
/*
* это собственно планировщик: */
repeat_schedule : /*
* Выбрать процесс по умолчанию. . . */
next = idle_task(this_cpu) ; с = -1000;
if (prev->state == TASK_RUNNING) goto still_running;
still_running_back :
list_for_each (tmp, srunqueue_head) {
p = list_entry (tmp, struct task_struct, run_list) ; if (can_schedule (p, this_cpu) ) {
int weight = goodness (p, this_cpu, prev->active_mm) ; if (weight > c)
с = weight, next = p;
/* Следует ли перевычислить счетчики? */
if (!c)
goto recalculate; /*
* с этого момента ничто ке может помешать нам
* переключиться на следующую задачу, отметить этот
* факт в sched_data. */
sched_data->curr = next; tifdef CONFIG_SMP
riext->has_cpu = I;
next->processor = this_cpu; lendif
spin_unlock__irq (&runqueue_lock) ;
if (prev == next) goto same_process;
ttifdef CONFIG_SMP /*
* Поддерживать значение 'last schedule' для каждого процесса
* (его необходимо пересчитать лаже если мы планируем тот же
* процесс). Сейчас это значение используется только в SMP, и оно
* приблизительно, поэтому мы не обязаны поддерживать его,
* пока захвачена блокировка runqueue. */
sched_data->last_schedule = get_cycles();
/*
* Мы снимаем блокировку планировщика рано (это глобальная
* блокировка), поэтому мы должны защитить предыдущий процесс
* от повторного планирования во время switch_to(). */
ttendif /* CONFIG_SMP */
kstat.context_swtch++; /*
* Переключение контекста воздействует на три процесса:
prev
.. ==> (last => next)
* Это 'prev' , 'далеко предшествующий' размещенному в стеке 'next1,
* но функция switch_to() устанавливает prev на (только что
* работавший) процесс 'last'.
* Описание несколько запутанно, но не лишено глубокого смысла,
*/
prepare_to_switch ( ) ;
{
struct mm struct *mm = next->mm;
struct mm_struct *oldmm = prev->active_mm;
if ( !mmi (
if (next->active_mm) BUG ( ) ;
next->active_mm = oldmm;
atomic_inc (&oldmm->mra_count) ;
enter_lazy_tlb (oldmm, next, this_cpu) ; } else {
if (next->active_mm != mm) BUG ( ) ;
switch_mm(ol<±nm, mm, next, this__cpu) ;
if ( !prev->irin) (
prev->active_mm = NULL; mmdrop (oldmm) ;
/*
* Этот оператор только переключает состояние регистров
* и стека. */
switch_to(prev, next, prev); __schedule_tail(prev);
same_process:
teacquire_kernel__lock (current) ; if (current->need_resched) goto need reached back;
recalculate: {
struct task_struct *p;
spin_unlock_irq (&runqueue_lock) ;
read_lock (&tasklist_lock) ;
for_each_task (p)
p->counter = (p->counter » 1) + NICE_TO_TICKS (p->nice)
read_unlock (&tasklist__lock) ;
spin_lock_irq (&runqueue_lock) ; } goto repeat_schedule;
still_running:
с = goodness (prev, this_cpu, prev->active_mm) ; next = prev;
goto still_running_back;
handle_sof tirq: do_softirq ( ) ; goto handle_softirq_back;
move_rr_last :
if ( !prev->counter) (
prev->counter = NICE_TO_TICKS (prev->nice) ; move_last_runqueue (prev) ; } goto move_rr_back;
scheduling_in_interrupt :
printk ("Scheduling in interrupt\n") ;
BUG ( ) ;
return;
Этот алгоритм гарантирует, что любой
Рисунок 8.1. Приоритеты и возраст в OS/9
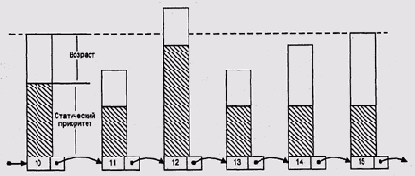
Этот алгоритм гарантирует, что любой низкоприоритетный процесс рано или поздно получит управление. Если же нам нужно, чтобы он получал управление раньше, то мы должны просто повысить его приоритет.
Кроме того, можно запретить исполнение процессов со статическим приоритетом ниже заданного. Это может уменьшить загрузку процессора и, например, позволит высокоприоритетным процессам обработать увеличившийся поток внешних событий. Понятно, что такой запрет можно вводить только на небольшое время, чтобы не нарушить справедливое распределение процессора.
Возможна и более тонкая регулировка — системный вызов, который запрещает увеличивать возраст процесса больше заданного значения. То есть, процесс, стоя в очереди, может достичь этого максимального возраста, после чего он по-прежнему остается в очереди, но его возраст уже не увеличивается.
Получающаяся в результате схема распределения времени процессора отчасти похожа на двухслойную организацию VAX/VMS, когда исполнение процессов со статическим приоритетом, превышающим границу, не может быть прервано низкоприоритетным процессом.
Приоритеты процессов в транспьютере
Приоритеты процессов в транспьютере
Простейшим случаем такой организации является транспьютер, имеющий две очереди. В транспьютере при этом планировщик не может отобрать управление у высокоприоритетного процесса. В этом смысле низкоприоритетные задачи вынуждены полагаться на "порядочность" высокоприоритетных, т. е. на то, что те освобождают процессор в разумное время.
Отчасти похожим образом организован планировщик системы VAX/VMS. Он имеет 32 приоритетных очереди, из которых старшие 16 называются процессами реального времени, а младшие — разделенного.
При этом процесс реального времени исполняется всегда, когда готов к исполнению, и в системе нет более приоритетных процессов. ОС и процессы разделенного времени также вынуждены полагаться на его порядочность. Поэтому привилегия запускать такие процессы контролируется администратором системы.
Легко понять, что разделение времени обеспечивает более или менее справедливый доступ к процессору для задач с одинаковым приоритетом. В случае транспьютера, который имеет только один приоритет и, соответственно, одну очередь для задач разделенного времени, этого оказывается достаточно. Однако современные ОС как общего назначения, так и реального времени, имеют много уровней приоритета. Для чего это нужно и как достигается в этом случае справедливое распределение времени процессора?
Дело в том, что в системах такого типа приоритет процессов разделенного времени является динамической величиной. Он изменяется в зависимости от того, насколько активно задача использует процессор и другие системные ресурсы.
В системах с пакетной обработкой, когда для задачи указывают верхнюю границу времени процессора, которое она может использовать, часто более короткие задания идут с более высоким приоритетом. Кроме того, более высокий приоритет дают задачам, которые требуют меньше памяти. В системах разделенного времени часто оказывается сложно заранее определить время, в течение которого будет работать задача. Например, вы отлаживаете программу. Для этой цели вы запускаете символьный отладчик и начинаете исполнять вашу программу в пошаговом режиме. Естественно, что вы не можете даже приблизительно предсказать как астрономическое время отладки, так и время центрального процессора, занятое при этом. Поэтому обычно такие системы не ограничивают время исполнения задачи и другие ре-сУрсы и вынуждены прогнозировать поведение программы в будущем на основании ее поведения в прошлом.
Так, если программа начала вычисления, не прерываемые никакими обращениями к внешней памяти или терминалу, мы можем предположить, что она будет заниматься такими вычислениями и дальше. Напротив, если программа сделала несколько запросов на ввод-вывод, следует ожидать, что она и дальше будет активно выдавать такие запросы. Предпочтительными для системы будут те программы, которые захватывают процессор на короткое время и быстро отдают его, переходя в состояние ожидания внешнего или внутреннего события. Таким процессам система стремится присвоить более высокий приоритет. Если программа ожидает завершения запроса на обращение к диску, то это также выгодно для системы — ведь на большинстве машин чтение с диска и запись на него происходят параллельно с работой центрального процессора.
Таким образом, система динамически повышает приоритет тем заданиям, которые освободили процессор в результате запроса на ввод-вывод или ожидание события и, наоборот, снижает тем заданиям, которые были сняты по истечении кванта времени. Однако приоритет не может превысить определенного значения — стартового приоритета задачи.
При этом наиболее высокий приоритет автоматически получают интерактивные задачи и программы, занятые интенсивным вводом-выводом. Во время выполнения таких программ процессор часто оказывается свободен, и управление получают низкоприоритетные вычислительные задания. Поэтому системы семейства UNIX и VAX/VMS даже при очень высокой загрузке обеспечивают как приемлемое время реакции для интерактивных программ, так и приемлемое астрономическое время исполнения для пакетных заданий. Благодаря наличию класса планирования реального времени, эти же ОС можно использовать и в задачах реального времени таких, как управление атомным реактором.
Система VMS повышает приоритет также и тем задачам, которые остановились в ожидании подкачки страницы. Это сделано потому, что если программа несколько раз выскочила за пределы своего рабочего набора (т. е. потребовала еще страницу, когда ее рабочий набор весь занят), то она, скорее всего, будет делать это и далее, а процессор на время подкачки она освобождает.
Нужно отметить, что процесс разделенного времени может повысить свой приоритет до максимального в классе разделения времени, но никогда не сможет стать процессом реального времени. А для процессов реального времени динамическое изменение приоритетов обычно не применяется.
Реализация многозадачности на однопроцессорных компьютерах
Реализация многозадачности на однопроцессорных компьютерах
В предыдущей главе мы упоминали о возможности реализовать параллельное (или, точнее, псевдопараллельное) исполнение нескольких потоков управления на одном процессоре. Понятно, что такая возможность дает значительные преимущества. В частности, это позволяет разрабатывать прикладные программы, которые могут исполняться без переделок и часто даже без перенастроек и на одно-, и на симметричных многопроцессорных машинах. Кроме того, многопоточность полезна и сама по себе, хотя и сопряжена с определенными неудобствами (перечисленными в предыдущей главе) при реализации взаимодействия параллельных нитей.
Примечание
Примечание
Внимательный читатыыель может обратить внимание на некоторую терминологическую непоследовательность, появляющуюся в этой главе. В соответствии с принятой в главе 3 терминологией, правильно было бы говорить о многоните-вости (дословный перевод английского термина multithreading), но это слово, хотя и состоит только из славянских корней, звучит очень уж не по-русски, термин же многозадачность прижился в компьютерной лексике давно и прочно, поэтому мы будем его употреблять наравне с правильным термином многопоточность
RESET или клавиш <CTRL>+<ALT>+<DEL>
RESET или клавиш <CTRL>+<ALT>+<DEL>.
В-третьих, кооперативная ОС не может исполняться на симметричной многопроцессорной машине, а приложения, написанные в расчете на такую ОС, не могут воспользоваться преимуществами многопроцессорности.
Простой анализ показывает, что кооперативные многозадачные системы пригодны только для учебных проектов или тех ситуаций, когда программисту на скорую руку необходимо сотворить многозадачное ядро. Вторая ситуация кажется несколько странной — зачем для серьезной работы может потребоваться быстро сделанное ядро, если существует много готовых систем реального времени, а также общедоступных (freeware или public domain) в виде исходных текстов реализаций таких ядер?
Любопытно реализовано динамическое изменение приоритета
Управление приоритетами во OS-9
Любопытно реализовано динамическое изменение приоритета в OS-9. В этой ОС каждый процесс имеет статически определенный приоритет и возраст
(age) — количество просмотров очереди с того момента, когда этот процесс в последний раз получал управление. Обе эти характеристики представлены 16-разрядными беззнаковыми числами. Процесс может повысить или понизить свой приоритет, исполнив соответствующий системный вызов, но система по собственной инициативе никогда не меняет его. При этом управление каждый раз получает процесс с наибольшей суммой статического приоритета и динамически изменяющегося возраста (Рисунок 8.1 — в изображенной на рисунке ситуации будет выбран процесс 12). Если у двух процессов такие суммы равны, то берется процесс с большим приоритетом. Если у них равны и приоритеты, то берется тот, который оказался ближе к началу очереди.
Вытесняющая многозадачность
Вытесняющая многозадачность
Все вышесказанное подводит нас к идее вызывать ThreadSwitch не из пользовательской программы, а каким-то иным способом. Например, поручить вызов такой функции прерыванию от системного таймера. Тогда мы получим следующую схему.
Каждой нити выделяется квант времени. Если нить не освободила процессор в течение своего кванта, ее снимают и переставляют в конец очереди. При этом все готовые к исполнению нити более или менее равномерно получают управление.Этот механизм, называемый time slicing или разделение времени, реализован в микрокоде транспьютера и практически во всех современных ОС. Общим названием для всех методов переключения нитей по инициативе системы является термин вытесняющая (preemptive) многозадачность. Таким образом, вытесняющая многозадачность противопоставляется кооперативной, в которой переключение происходит только по инициативе самой задачи. Разделение времени является частным случаем вытесняющей многозадачности. В системах с приоритетами, вытеснение текущей задачи происходит не только по сигналам таймера, но и в случае, когда по каким-то причинам (чаше всего из-за внешнего события) активизируется процесс, с приоритетом выше, чем у текущего.
При этом вопрос выбора кванта времени является нетривиальной проблемой. С одной стороны, чрезмерно короткий квант приведет к тому, что большую часть времени система будет заниматься переключением потоков. С другой стороны, в интерактивных системах или системах реального времени слишком большой квант приведет к недопустимо большому времени реакции.
В системе реального времени мы можем объявить нити, которым надо быстро реагировать, высокоприоритетными и на этом успокоиться. Однако нельзя так поступить с интерактивными программами в многопользовательской или потенциально многопользовательской ОС, как UNIX на настольной машине х86 или Sun.
Из психологии восприятия известно, что человек начинает ощущать задержку ответа при величине этой задержки около 100 мс. Поэтому в системах разделенного времени, рассчитанных на интерактивную работу, квант обычно выбирают равным десяткам миллисекунд. В старых системах, ориентированных на пакетную обработку вычислительных задач, таких как ОС ДИСПАК на БЭСМ-6, квант мог достигать десятых долей секунды или даже секунд. Это повышает эффективность системы, но делает невозможной или, по крайней мере, неудобной — интерактивную работу. Многие современные системы подбирают квант времени динамически для разных классов планирования и приоритетов процесса.
Системы реального времени обычно имеют два класса планирования — реального и разделенного времени. Класс планирования, как правило, дается не отдельным нитям, а целиком процессам. Процессы реального времени не прерываются по сигналам таймера и могут быть вытеснены только активизацией более приоритетной нити реального времени. Нити реального времени высочайшего приоритета фактически работают в режиме кооперативной многозадачности. Зато нити процессов разделенного времени вытесняются и друг другом по сигналам таймера, и процессами реального времени по мере их активизации.
Вытесняющая многозадачность имеет много преимуществ, но если мы про сто будем вызывать описанный в предыдущем разделе ThreadSwitchпо прерываниям от таймера или другого внешнего устройства, то такое переключение будет непоправимо нарушать работу прерываемых нитей.
Действительно, пользовательская программа может использовать какой-тл из регистров, который не сохраняется при обычных вызовах. Поэтому, например, обработчики аппаратных прерываний сохраняют в стеке все используемые ими регистры. Кстати, если наша функция ThreadSwitch будет сохранять в стеке все регистры, то произойдет именно то, чего мы хотим. ThreadSwitch вызывается по прерыванию, сохраняет регистры текущей нити в текущем стеке, переключается на стек новой нити, восстанавливает из ее стека ее регистры, и новая нить получает управление так, будто и не теряла его.
Полный набор регистров, которые нужно сохранить, чтобы нить не заметила переключения, называется контекстом нити или, в зависимости от принятой в конкретной ОС терминологии, контекстом процесса. К таким регистрам, как минимум, относятся все регистры общего назначения, указатель стека, счетчик команд и слово состояния процессора. Если система использует виртуальную память, то в контекст входят также регистры диспетчера памяти, управляющие трансляцией виртуального адреса (пример 8.3).
