[Docs sun com 805747810] Для прикладной
[docs.sun.com 805-7478-10]. Для прикладной программы потоковый драйвер не отличается от обычного символьного устройства, но отличий с точки зрения системы довольно много. Некоторые из этих отличий будут рассматриваться далее.
Unix System V Release 3 (SCO Open Desktop, SCO OpenServer), Release (SCO UnixWare, SGI Irix, Sun Solaris) и системы, испытавшие влияние OSF Unix (IBM AIX, HP/UX) используют потоковые драйверы для реализации таких важных псевдоустройств, как трубы и сокеты TCP/IP. Кроме того, потоковыми в этих системах являются драйверы сетевых адаптеров и терминальных устройств.
С другой стороны, в OS/2 и Windows NT/2000/XP существуют обширные номенклатуры типов драйверов с различными наборами функций. Так, в OS/2 используются драйверы физических устройств следующих типов: простые драйверы последовательных устройств ввода-вывода, аналогичные драйверам символьных устройств в Unix; Драйверы запоминающих устройств прямого доступа, аналогичные драйверам блочных устройств в Unix; Драйверы видеоадаптеров, используемые графической оконной системой Presentation Manager (PM); Драйверы позиционных устройств ввода (мышей и др.), также используемые РМ; Драйверы принтеров и других устройств вывода твердой копии; Драйверы звуковых устройств, используемые подсистемой "мультимедиа" MMOS/2; драйверы сетевых адаптеров стандарта NDIS, используемые сетевк программным обеспечением фирм IBM и Microsoft; драйверы сетевых адаптеров стандарта ODI, используемые программным обеспечением фирмы Novell; DMD (Device Manager Driver - - драйвер-менеджер класса устройств (в разд. 10.2 мы подробнее разберемся с назначением драйверов этог типа); различного рода "фильтры", например, ODINSUP.SYS — преобразоватеи ODI-интерфейса в NDIS.
[Partners adobe com] и протокол
[partners.adobe.com] и протокол распределенной оконной системы X Window [www.x.org] (оба протокола поддерживают как растровые образы, так и довольно богатые наборы векторных примитивов).
Нередки, впрочем, ситуации, когда нам интересна не только структура поступающих данных, но и время их поступления (в предыдущей главе мы предложили классифицировать устройства, которые могут быть использованы подобным образом, как генераторы событий) — это бывает в приложениях реального времени, а также в задачах, которые сейчас стало модно называть "задачами мягкого реального времени" — мультимедийных программах, генерирующих поток звука, синхронизованного с изображением, и, особенно, в компьютерных играх.
Для работы с таким устройством прикладная программа, так или иначе, должна зарегистрировать обработчик поступающих от устройства событии. В системах Unix такая регистрация состоит в открытии устройства для чтения, а ожидание события заключается в выполнении над этим устройством операции чтения. Для последовательных устройств ввода операция чтений разблокируется, когда с устройства поступят хоть какие-то данные (а не тогда, когда будет заполнен весь буфер), поэтому, если пришло только одно событие, мы его не пропустим. Драйверы многих устройств, способных работать в качестве генераторов событий, имеют команды ioctl, позволяющие более тонко управлять условием разблокирования функции read.
Для того чтобы во время ожидания события от генератора, заниматься еще какой-то полезной работой, предлагается либо выделить ожидающий события вызов read в отдельную нить, либо пользоваться системными вызовами lect и poll, позволяющими ожидать событий на нескольких устройствах (а также средствах межпроцессного взаимодействия) одновременно.
Другие ОС предоставляют для работы с устройствами-генераторами событий более сложные механизмы, зачастую основанные на callback (дословно — "вызов назад"; механизм взаимодействия подсистем, когда подсистема, запрашивающая сервис, передает обслуживающей подсистеме указатель на функцию, которую необходимо вызвать при наступлении определенного события).
Работа с генераторами событий требует решения еще одной задачи — хранения поступающих событий в периоды, когда пользовательская программа их не успевает обрабатывать. Необходимость относительно сложных схем работы с требуемыми для этого буферами вынудила разработчиков Unix System V Release 3 ввести еще один тип драйверов — потоковые (STREAMS)
[Www ibm com OS/2 DDK]
[www.ibm.com OS/2 DDK].
При работе с устройствами ATA/ATAPI используется более простая и возможностями структура, состоящая из драйвера IBM1S506.ADD (для неко Я рых типов адаптеров EIDE может понадобиться другой драйвер) и фильт IBMATAPI.FLT. Драйвер обеспечивает инициализацию адаптера, передачу команд и работу с жесткими дисками АТА, а фильтр — формирование кома для подключаемых к тому же адаптеру устройств ATAPI (CD-ROM и магнитооптических дисков).
На практике драйверы многих устройств используются исключительно цц преимущественно другими модулями ОС (не обязательно драйверами), а не пользовательскими программами. Например, драйверы сетевых интерфейсов взаимодействуют практически исключительно с модулями ядра, реализующими сетевые и транспортные протоколы (напрямую с сетевым интерфейсом работают разве что конфигурационные утилиты, а также анализаторы протоколов и другие контрольно-диагностические средства), а драйверы жестких дисков преимущественно исполняют запросы файловых систем.
Именно этим и отличаются блочные устройства в системах семейства Unix от символьных: в классических ОС Unix блочные устройства вообще не доступны пользовательским программам, а все операции с ними осуществляются посредством файловой системы. Это несколько упрощает логику исполнения операций — драйверу не надо заботиться об обмене данными с пользовательским адресным пространством. Кроме того, в отличие от обычных операций чтения и записи, в которых допустим обмен пакетами данных произвольного размера, блочный драйвер передает данные блоками, размер которых кратен 512 байтам.
На случай, если все-таки понадобится доступ к диску в обход файловом системы, драйвер блочного устройства создает две минорных записи для устройства — одну блочную и одну символьную, и все-таки предоставляет обычные, "символьные" операции чтения и записи. На практике, такой доступ почти всегда требуется утилитам создания и восстановления файловых систем, поэтому создание двух записей является обязательным.
Более радикально подошел к решению проблемы разработчик Linux Линус Торвальдс — в этой системе драйверы блочных устройств обязаны предоставлять символьные операции чтения и записи, но им не нужно создавать вторую минорную запись: пользователям разрешено работать с блочными устройствами (открывать, читать их и писать на них) так же, как и с символьными.
[Www ibm com OS/2 DDK] Построенный
[www.ibm.com OS/2 DDK].
Построенный нами в примере 10.3 код внешне совсем не похож на приме 10.4, но, в действительности, также представляет собой конечный автомат в качестве переменной состояния используется переменная fdd->handier, в качестве дискретных значений этой переменной — указатели на функции обрабатывающие конкретные состояния.
Архитектура драйвера
Архитектура драйвера
Типичный протокол работы с внешним устройством состоит из анализа запроса, передачи команды устройству, ожидания прерывания по завершении этой команды, анализа результатов операции и формирования ответа внешнему устройству. Многие запросы не могут быть выполнены в одну операцию, поэтому анализ результатов операции может привести к выводу о необходимости передать устройству следующую команду.
Драйвер, реализующий этот протокол, естественным образом распадается на две нити: основную, которая осуществляет собственно обработку запроса, и обработчик прерывания. В зависимости от ситуации, основная нить может представлять собою самостоятельную нить, либо ее код может исполняться в рамках нити, сформировавшей запрос.
В примере 10.1 приводится скелет функции write () драйвера последовательного устройства в системе Linux. Скелет упрощенный (в частности, никак не решается проблема реентерабельности функции foo_write. Использованный механизм синхронизации с обработчиком прерывания также оставляет желать лучшего), но имеет именно такую архитектуру, которая была описана ранее. Текст цитируется по документу [HOWTO khg], перевод комментариев и дополнительные комментарии автора.
Асинхронная модель вводавывода с точки зрения приложений
Асинхронная модель ввода-вывода с точки зрения приложений
В разд. Синхронный ввод-вывод, обсуждая асинхронную модель драйвера, мы задались вопросом: должна ли задача, сформировав запрос на ввод-вывод, дожидаться его завершения? Ведь система, приняв запрос, передает его асинхронному драйверу, который инициирует операцию на внешнем устройстве и освобождает процессор. Сама система не ожидает завершения запроса. Так должна ли пользовательская задача ожидать его?
Если было запрошено чтение данных, то ответ, на первый взгляд, очевиден:
должна. Ведь если данные запрошены, значит они сейчас будут нужны программе.
Однако можно выделить буфер для данных, запросить чтение, потом некоторое время заниматься чем-то полезным, но не относящимся к запросу, и лишь к точке, когда данные действительно будут нужны, спросить систему: а готовы ли данные? Если готовы, то можно продолжать работу. Если нет, то придется ждать (Рисунок 10.9).
Во многих приложениях, особенно интерактивных или работающих с другими устройствами-источниками событий, асинхронное чтение оказывается единственно приемлемым вариантом, поскольку оно позволяет задаче одновременно осуществлять обмен с несколькими источниками данных и таким образом повысить пропускную способность и/или улучшить время реакции на событие.
Асинхронный вводвывод
Асинхронный ввод-вывод
В системах семейства Unix драйверы блочных устройств обязательно асинхронные. Кроме того, в современных версиях системы асинхронными драйверами являются драйверы потоковых устройств. Многие другие ОС, в том числе однозадачные (такие, как DEC RT-11), используют исключительно асинхронные драйверы.
Драйвер, использующий асинхронную архитектуру, обычно предоставляет вместо отдельных функций read, write, ioctl и т. д. единую функцию, которая в системах семейства Unix называется strategy, а мы будем называть стратегической функцией (Рисунок 10.7).
Автоконфигурация
Автоконфигурация
| — В моем поле зрения появляется новый объект. Возможно, ты шкаф? — Нет — Возможно ты стол? — Нет — Каков твой номер? — Женский — Иду на вы — Иди Б. Гребенщиков |
Автоматическое определение установленных в системе устройств и их конфигурации экономит время и силы администратора при установке и перенастройке ОС. Разработчику ОС, впрочем, не следует полностью полагаться на автоконфигурацию, особенно при широком спектре оборудования, поддерживаемого системой: ошибки бывают не только в программном обеспечении, но и в аппаратных устройствах, в том числе и в той части логики контроллера, которая обеспечивает его идентификацию и автонастройку.
Автонастройка возможна только при определенной поддержке со стороны аппаратуры. Такая поддержка может обеспечиваться несколькими способами.
Приведенные рассуждения справедливы не только для устройств, имеющих адреса на системной шине, но и для устройств, подключаемых к шинам собственной адресацией, например SCSI. Количество адресов шины SCSI невелико, поэтому подсистема автоконфигурации быстро может просканировать их все. Каждое устройство SCSI должно поддерживать команду INQUIRY, в качестве ответа на которую обязано вернуть тип устройства и другую информацию, в частности, название изготовителя и модели, поддерживаемую версию протокола SCSI и др. Одна из форм команды INQUIRY позволяет также проверить, поддерживает ли устройство какую-либо другую команду из набора команд SCSI.
Одна из серьезных неприятностей, которая может возникнуть при автоконфигурации — это конфликт устройств по каким-либо ресурсам, чаще всего — адресам всех или некоторых регистров; линии запроса или вектору прерывания. Если первый конфликт разрешим только перенастройкой аппаратуры (устройства с одним и тем же адресом на шине гарантированно неработоспособны, а в некоторых случаях могут сделать неработоспособной всю шину), то второй может быть обойден сугубо программными средствами.
Действительно, ничто не мешает драйверам конфликтующих устройств разделять один вектор прерывания. При приходе запроса прерывания по этому вектору вызывается один из обработчиков. Он анализирует состояние своего устройства, и если обнаруживает, что прерывание вызвано им, обрабатывает его. Если же прерывание не его, он просто вызывает следующий обработчик.
Эта схема допускает каскадирование потенциально неограниченного количества обработчиков, с тем очевидным недостатком, что каждое дополнительное звено цепочки значительно увеличивает задержку прерывания для всех последующих драйверов.
Большинство современных ОС использует более сложный механизм обработки прерываний, когда пролог и эпилог прерывания исполняются сервисной функцией, предоставленной ядром системы, и уже эта функция вызывает собственно обработчик. Протокол обмена вызывающей функции с обработчиком может включать в себя код возврата: обработчик должен при этом сообщать, "его" это прерывание или не "его". В последнем случае необходимо вызвать следующий обработчик, и так далее.
Эта схема также допускает неограниченное каскадирование и обладает тем же недостатком, что и предыдущая, а именно — увеличивает задержку для последних обработчиков в цепочке.
В любом случае, разделение векторов прерываний требует активной кооперации со стороны обработчиков этих прерываний.
Блоксхема драйвера
Рисунок 10.5. Блок-схема драйвера

Анализ полной или сокращенной блок-схемы алгоритма методами теории графов, хотя и не может однозначно дать ответ на вопрос о его финитности, может оказать значительную помощь в оценке алгоритма, в том числе и в поиске "узких" с точки зрения финитности мест. В [Кнут 2000) приводятся примеры такого анализа для некоторых простых алгоритмов.
Алгоритмы основной массы реально применяемых программ (особенно использующих переменные состояния большого объема) имеют совершенно Необозримые блок-схемы. Отчасти это обходится декомпозицией программного комплекса на отдельные модули с более обозримой функциональностью и алгоритмом, но все-таки далеко не для всех алгоритмов представление в виде конечного автомата естественно.
Дисковый кэш
Дисковый кэш
Функции и принципы работы дискового кэша существенно отличаются от общих алгоритмов кэширования, обсуждавшихся в разд. Страничный обмен. Дело в том, что характер обращения к файлам обычно существенно отличается от обращений к областям кода и данных задачи. Например, компилятор С и макропроцессор
Драйвер IDE/ATA для Linux
Драйвер IDE/ATA для Linux
В примере 10.5 приведена основная функция обработки запроса и функция об работки прерывания, используемая при записи нескольких секторов. Обе эти функции вызываются драйвером контроллера IDE/ATA, который представляет собой диспетчер запросов к подключенным к контроллеру устройствам.
Структура *hwgroup представляет собой блок переменных состояний контроллера устройства. Эта структура содержит также указатель на текущий запрос к устройству. Информации, содержащейся в этих структурах, достаточно, чтобы очередная функция конечного автомата драйвера узнала все, необходимое ей для выполнения очередного этапа запроса. В данном случае конечный автомат весьма прост и состоит из многократного вызова функции ide_multiwrite, копирующей в контроллер очередной блок данных. Условием завершения автомата служат ошибка контроллера либо завершение запроса. Функции ide__dma_read, ide_dma_write, ide_read и ide_write, исполняемые машиной состояний при обработке других запросов не приводятся.
Драйверы целевых устройств SCSI и драйвер НВА
Рисунок 10.1. Драйверы целевых устройств SCSI и драйвер НВА
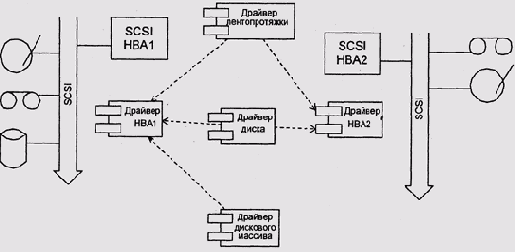
Напротив, драйвер НВА напрямую не доступен прикладным программам (в отдельных случаях, впрочем, позволяют осуществлять над этим драйвером операции ioctl), а набор функций этого драйвера отличается от символьных и блочных устройств. Порядок инициализации таких драйверов (функции _init, attach и т. д.) в целом такой же, как и у обычных драйверов.
Как правило, драйвер имеет функцию transport (например, в Solaris эта функция называется tran_start), которая осуществляет передачу целевому устройству команды, сформированной драйвером этого устройства. Если до завершения отработки предыдущей команды поступит следующая, драйвер может либо положиться на способность целевого устройства поддерживать очередь запросов, либо, если устройство этого не умеет, реализовать очередь запросов самостоятельно.
Кроме того, драйвер адаптера производит первичный анализ пришедших ответов на команды: какой из ранее переданных команд соответствует ответ, чем завершилась операция — успехом или ошибкой, пришли ли в ответ данные и если пришли, то сколько именно и куда их положить и т. д.
После завершения обработки запроса, драйвер НВА вызывает callback драйвера целевого устройства. Эта callback-процедура может сформировать следующий запрос к адаптеру (или повторную попытку, если операция завершилась восстановимой ошибкой) либо просто оповестить пользовательский процесс о завершении операции и освободить память, занятую структурой запроса и буферами данных.
Аналогичные ситуации возникают и с другими устройствами. Например, с IBM PC-совместимыми компьютерами могут работать три основных типа устройств позиционного ввода: мыши, использующие протокол обмена, совместимый с Microsoft Mouse, мыши с протоколом Logitech, планшеты дигитайзеры с протоколом Summagraphics. Устройства всех этих, а т нескольких менее распространенных типов могут подсоединяться как нимум к четырем различным периферийным портам: специальном "мышиному" разъему PS/2, к последовательной шине USB и к послсюва тельному порту RS232, причем в качестве порта RS232, может использовать ся как один из четырех стандартных портов IBM PC, так и, например. один из выходов мультипортовой платы (Рисунок 10.2).
Драйверы внешних устройств
Драйверы внешних устройств
| Когда я на почте служил ямщиком . Ко мне постучался косматый геолог, И глядя на карту на белой стене, он усмехнулся мне. Г. Самойлов |
Драйвер (driver) представляет собой специализированный программный модуль, управляющий внешним устройством. Слово driver происходит от глагола to drive (вести) и переводится с английского языка как извозчик или шофер: тот, кто ведет транспортное средство. Драйверы обеспечивают единый интерфейс для доступа к различным устройствам, тем самым устраняя зависимость пользовательских программ и ядра ОС от особенностей аппаратуры.
Драйвер не обязательно должен управлять каким-либо физическим устройством. Многие ОС предоставляют также драйверы виртуальных устройств или псевдоустройств — объектов, которые ведут себя аналогично устройству ввода-вывода, но не соответствуют никакому физическому устройству.
В виде псевдоустройств реализуются трубы в системах семейства Unix и почтовые ящики в VMS. Еще одним примером полезного псевдоустройства являются устройства /dev/null в Unix и аналогичное ему \DEV\NUL в MS DOS\Windows\OS/2. В современных системах семейства Unix в виде псевдоустройств, размещенных в псевдофайловой системе /ргос, реализован доступ к большинству параметров системы -- адресным пространствам активных процессов, статистике и параметрам настройки ядра, данным отдельных подсистем, например таблице маршрутизации сетевого протокола IP.
Прикладные программы, использующие собственные драйверы, не так уж редки - примерами таких программ могут быть GhostScript (свободно распространяемый интерпретатор языка PostScript, способный выводить программы на этом языке на различные устройства, как печатающие, так и экранные) или
Forkпроцессы в VMS
Fork-процессы в VMS
С точки зрения планировщика VMS, fork-процесс представляет собой нить с укороченным контекстом. Вместо обычного дескриптора процесса (РСВ — Process Control Block) используется UCB — Unit Control Block, блок управления устройством. Укорочение заключается в том, что эта нить может работать только с одним банком виртуальной памяти из трех, имеющихся у процессора VAX, а именно с системным (полный список банков памяти VAX приведен в главе 5); таким образом, при переключении контекста задействуется меньше регистров диспетчера памяти. Fork-процесс имеет более высокий приоритет, чем пользовательские процессы, и может быть вытеснен только более приорцтСб ным fork-процессом и обработчиком прерывания.
При использовании fork-процессов, обслуживание прерывания распадает на собственно обработчик (вызываемый по сигналу прерывания и исполняемый с соответствующим приоритетом) и код постобработки, исполняемый fork-процессом, на который не распространяются ограничения времени и который вполне может осуществить планирование следующих операций (пример 10.3).
Функции драйверов
Функции драйверов
Прежде всего, драйвер должен иметь функции, вызываемые ядром при загрузке и выгрузке модуля и при подключении модуля к конкретным устройствам. Например, в Sun Solans это перечисленные функции.
int _init(void) — инициализация драйвера. Эта функция вызывается при загрузке модуля. Драйвер должен зарезервировать все необходимые ему системные ресурсы и проинициализировать собственные глобальные переменные. Инициализация устройства на этом этапе не происходит. int probe (dev_info_t *dip) — проверить наличие устройства в системе. Во многих системах эта функция реализуется не самим драйвером, а специальным модулем-"сниффером" (sniffer — дословно, "нюхач"), используемым программой автоконфигурации. int attach (dev_info_t * dip, ddi_attach_cmd_t crtid) — инициализация копии драйвера, управляющей конкретным устройством. Эту функцию можно рассматривать как аналог конструктора объекта в объектно-ориентированном программировании. Если в системе присутствует несколько устройств, управляемых одним драйвером, некоторые ОС загружают несколько копий кода драйвера, но в системах семейства Unix функция attach просто вызывается многократно.
Каждая из инициализированных копий драйвера имеет собственный блок локальных переменных, в которых хранятся переменные состояния устройства. При вызове attach драйвер должен прочитать конфигурационный файл, где записаны параметры устройства (номенклатура этих параметров зависит от устройства и от драйвера), разместить и проинициализировать блок переменных состояния, зарегистрировать обработчики прерываний, проинициализировать само устройство и, наконец, зарегистрировать устройство как доступное для пользовательских программ, создав для него минорную запись (minor node). В ряде случаев драйвер создает для одного устройства несколько таких записей.
Например, каждый жесткий диск в Unix SVR4 должен иметь 16 записей — по две (далее мы поймем, для чего они нужны) для каждого из восьми допустимых слайсов (логических разделов, см. разд. Загрузка самой ОС) диска. Другой пример: в большинстве систем семейства Unix лентопротяжные устройства имеют две минорные записи. Одно из этих устройств при открытии перематывает ленту к началу, другое не перематывает. В действительности оба устройства управляются одним и тем же драйвером, который определяет текущий режим работы в зависимости от указанной минорной записи.
Современные Unix системы, в частности Solaris, используют отложенную инициализацию, когда для многих устройств attach вызывается только при первой попытке доступа пользовательской программы к устройству.
После того, как драйвер проинициализировался и зарегистрироват мино ную запись, пользовательские программы могут начинать обращаться к не му и к управляемым им устройствам. Понятно, что обеспечить единый ин терфейс к разнообразным категориям устройств, перечисленным в главе 9 по меньшей мере сложно. Наиболее радикально подошли к этой проблеме разработчики системы UNIX, разделившие все устройства на два класса-блочные (высокоскоростные устройства памяти с произвольным доступом в первую очередь, дисковые устройства) и последовательные или символьные устройства (всё остальное) (в действительности, у современных систем семейства Unix типов драйверов несколько больше, но об этом далее).
Над последовательными устройствами определен следующий набор операций, которые могут осуществляться прикладной программой (в простых случаях эти операции непосредственно транслируются в вызовы функций драйвера).
устройства. В некоторых случаях она может содержать и дополнительные шаги инициализации устройства — например, для лентопротяжек эта процедура может включать в себя перемотку ленты к началу. Функция возвращает целочисленный идентификатор-"ручку" (handle), часто называемый также дескриптором файла, который используется программой при всех последующих обращениях к устройству. int readfint handle, char * where, size_t how_much) — чтение данных с устройства. Если устройство приспособлено только для вывода (например, принтер), эта функция может быть не определена. int write (int handle, char * what, size_t how_much) — запись данных
на устройство. Если устройство приспособлено только для ввода, (например, перфоленточный ввод или мышь), эта функция также может быть не определена. void dose (int handle) — процедура закрытия (освобождения) устройства. int ioctitint handle, int cmd, ...) — процедура задания специальной команды, которая не может быть сведена к операциям чтения и записи. Набор таких команд зависит от устройства. Например, для растровых графических устройств могут быть определены операции установки видеорежима; для последовательных портов RS232 это могут быть команд^ установки скорости, количества битов, обработки бита четности и т. д., для дисководов — команды форматирования носителя. off r lseek<int handle, off_t offset, int whence), long seek — команда перемещения головки чтения/записи к заданной позиции. Драйверы устройств, не являющихся устройствами памяти, например модема или Принтера, как правило, не поддерживают эту функцию.
Слово long в названии функции появилось по историческим причинам: версиях Unix для 16-разрядных машин индекс позиции не мог обозначать-я словом, потому что это ограничивало бы логическую длину устройства недопустимо малым значением 65334 байт. Поэтому необходимо было использовать двойное слово, что соответствовало типу long языка С. Современные системы используют 64-разрядный off_t.
caddr_t rranap (caddr_t addr, size_t len, int prot, int flags, int handle, off_t offset) memory map — отображение устройства в адресное пространство процесса. Параметр prot задает права доступа к отображенному участку: на чтение, на запись и на исполнение. Отображение может происходить на заданный виртуальный адрес, или же система может выбирать адрес для отображения сама. Эта функция отсутствовала в старых версиях системы, но большинство современных систем семейства (BSD 4.4, ряд наследников BSD 4.3, SVR4 и Linux) поддерживают ее.
Речь идет об отображении в память данных, хранящихся на устройстве. Для устройств ввода-вывода, например, для принтера или терминала, эту функцию невозможно реализовать разумным образом. Напротив, для лент и других последовательных устройств памяти, поддерживающих функцию Iseek, отображение может быть реализовано с использованием аппаратных средств виртуализации памяти и операции read и write. Необходимость специальной функции отображения появляется у драйверов устройств, использующих большие объемы памяти, отображенной в адресное пространство системной шины, например, для растровых видеоадаптеров, некоторых звуковых устройств или страниц общей памяти (backpane memory — двухпортовой памяти, используемой как высокоскоростной канал обмена данными в многопроцессорных системах).
Механизм отображения доступных прикладной программе системных вызовов в функции драйвера относительно сложен. Этот механизм должен включать в себя следующее.
Способы, которыми эти вопросы решаются в современных операционных системах, обсуждаются в последующих разделах. А пока что мы подробнее обсудим, какие именно операции над устройством следует определить и почему.
Видно, что предлагаемый системами семейства Unix набор операций рассматривает устройство как неструктурированный поток байтов (или, ддя устройств ввода-вывода, два разнонаправленных потока — для ввода и для вывода). Такое рассмотрение естественно для устройств алфавитно-цифрового ввода-вывода и простых запоминающих устройств, например магнитных лент, однако далеко не столь естественно для более сложных устройств.
Стандартный ответ Unix-культуры в этом случае таков: любая, сколь угодно сложная структура данных может быть сериализована — преобразована в последовательный поток байтов. Например, изображение может быть превращено в последовательный поток байтов в виде растровой битовой карты или последовательности описаний графических примитивов — линий, прямоугольников и пр. Примерами такой сериализации для изображений могут являться язык PostScript
в комментариях. Параме! функции startSM
Конечный автомат драйвера OS/2
Несмотря на простоту, пример 10.4 нуждается в комментариях. Параме! функции startSM — АСВ (Adapter Control Block — блок управления адаптере! так в OS/2 называется блок переменных состояния устройства). АСЗ содержит указатель на очередь запросов IORB (Input/Output Request Block — блок запроса на ввод/вывод) и скалярную переменную state, которая указывает, в како состоянии сейчас находится обработка первого запроса в очереди. По коду этого состояния определяется, какую функцию следует вызвать. В телах этк функций, в зависимости от результата операции, происходит установка следующего значения переменной состояния и, возможно, флага ACB_WAITSTATE.
Функция startSM (Start State Machine) вызывается как из функции обработн запросов, так и из обработчика прерывания. Поэтому перед входом в собс венно автомат и после выхода из него стоит код, использующий поле nрАСЕ >UseCount как флаговую переменную, чтобы не допустить одновременного входа в автомат из обоих возможных нитей исполнения. Обратите также внимание, что макросами ENABLE и DISABLE (запрет и разрешение прерываний окружена работа с флаговой переменной, но не сам автомат.
(В качестве упражнения читателю предлагается понять, как же обеспечиваете вызов функции interruptstate, если во время прерывания основной поте драйвера все еще находился в теле автомата.
Полный текст драйвера IDE/ATA для OS/2 включен в стандартную поставку DDK (Driver Development Kit— набор инструментов [для] разработчика драйверов), который может быть найден на сайте
LATEX который также способен печатать
LATEX, который также способен печатать на самых разнообразных устройствах. Однако эта глава посвящена преимущественно драйверам, используемым ядром ОС.
Большинство ОС общего назначения запрещают пользовательским программам непосредственный доступ к аппаратуре. Это делается для повышения надежности и обеспечения безопасности в многопользовательских системах. В таких системах драйверы являются для прикладных программ единственным способом доступа к внешнему миру.
Еще одна важная функция драйвера- это взаимоисключение доступа к устройству в средах с вытесняющей многозадачностью. Допускать одновременный неконтролируемый доступ к устройству нескольких параллельно исполняющихся процессов просто нельзя, потому что для большинства внешних устройств даже простейшие операции ввода-вывода не являются атомарными.
Например, в большинстве аппаратных реализаций последовательного порта RS232 передача байта состоит из четырех шагов: записи значения в регистр данных, записи команды "передавать" в регистр команды, ожидания прерывания по концу передачи и проверки успешности передачи путем считывания статусного регистра устройства. Нарушение последовательности шагов может приводить к неприятным последствиям — например, перезапись регистра данных после подачи команды, но до завершения передачи, может привести к остановке передачи или, что еще хуже, передаче искаженных данных и т. д.
Нельзя также забывать о неприятностях более высокого уровня — например, смешивании вывода разных процессов на печати или данных — на устройстве внешней памяти. Поэтому оказывается необходимо связать с каждым внешним устройством какой-то разграничитель доступа во времени. В современных ОС эта функция возлагается именно на драйвер. Обычно одна из нитей драйвера представляет собой процесс-монитор, выполняющий асинхронно поступающие запросы на доступ к устройству. В Unix, OS/2 и Windows NT/2000/XP этот процесс называется стратегической функцией. Подробнее этот механизм обсуждается в разд. Асинхронный ввод-вывод и Асинхронная модель ввода-вывода с точки зрения приложений.
При определении интерфейса драйвера разработчики ОС должны найти правильный баланс между противоречивыми требованиями: стремлением как можно сильнее упростить драйвер, чтобы облегчить его разработку и (косвенно) уменьшить вероятность опасных ошибок; желанием предоставить гибкий и интеллектуальный интерфейс к разнообразным устройствам.
Драйверы обычно разрабатываются не поставщиками операционной системы, а сторонними фирмами — разработчиками и изготовителями периферийного
оборудования. Поэтому интерфейс драйвера является ничуть не менее внешним, чем то, что обычно считается внешним интерфейсом ОС — интерфейс системных вызовов. Соответственно, к нему предъявляются те же требования, что и к любому другому внешнему интерфейсу: он должен быт умопостижимым, исчерпывающе документированным и стабильным — меняться непредсказуемо от одной версии ОС к другой. Идеальным варпан том была бы полная совместимость драйверов хотя бы снизу вверх, чтобы драйвер предыдущей версии ОС мог использоваться со всеми последующими версиями.
Потеря совместимости в данном случае означает, что все независимые изготовители оборудования должны будут обновить свои драйверы. Организация такого обновления оказывается сложной, неблагодарной и часто попросту невыполнимой задачей — например, потому, что изготовитель оборудования уже не существует как организация или отказачся от поддержки данного устройства.
Отказ от совместимости драйверов на практике означает "брошенное" периферийное оборудование и, как следствие, "брошенных" пользователей, которые оказываются вынуждены либо отказываться от установки новой системы, либо заменять оборудование. Оба варианта, естественно, не улучшают отношения пользователей к поставщику ОС, поэтому многие поставщики просто не могут позволить себе переделку подсистемы ввода-вывода. Таким образом, интерфейс драйвера часто оказывается наиболее консервативной частью ОС.
Многоуровневые драйверы
Многоуровневые драйверы
| Массивное тело Сабляк-Паши выглядело необычно, словно под кожей у него была одежда, а на голове, под скальпом, тюрбан.
М. Павич |
Нередка ситуация, когда драйвер не может осуществлять управление устройством полностью самостоятельно. Как пример можно рассмотреть драйвер лентопротяжного устройства конструктива -SCSI. Для выполнения любой операции над устройством такой драйвер должен сформировать команду или последовательность команд SCSI, передать ее устройству, дождаться ответа и проанализировать его.
Проблема здесь в том, что передача команды и получение ответа происходят при посредстве еще одного устройства, НВА. НВА могут быть разнотипными и нуждаются в собственных драйверах. Дополнительная проблема состоит в том, что к одному НВА скорее всего подключены несколько устройств, и, наверняка, большинство из них не является лентопротяжками, поэтому целесообразно выделение драйвера НВА в отдельный модуль и отдельную мониторную нить.
В системах семейства Unix драйверы целевых устройств SCSI представляют собой обычные символьные или блочные драйверы, с тем лишь отличием, что они не управляют своими устройствами непосредственно, а формируют команды драйверу НВА (Рисунок 10.1). Команда содержит собственно команду протокола SCSI и указатели на буферы, откуда следует взять и куда следует положить данные, передачей которых должна сопровождаться обработка команды. Передав команду драйверу НВА, драйвер целевого устройства может либо дождаться ее завершения, либо заняться чем-то другим, например обработкой следующего запроса. Во втором случае, после завершения операции НВА, будет вызван предоставленный целевым драйвером callback.
к организации многоуровневых драйверов на
Многоуровневые драйверы в OS/2
Рассмотрим еще один подход к организации многоуровневых драйверов на примере DMD (Device Manager Driver-драйвер-менеджер класса устройств)
в OS/2 [www.ibm.com OS/2 DDK] и достаточно типичной аппаратной конфцп, рации, содержащей НВА SCSI, к которому подключены пять устройств: жесткий диск, привод CD-ROM, магнитооптический диск, лентопротяжка и сканер. riD этом каждое из устройств имеет свою специфику, так что управление ими сложно свести к общему набору функций.
Жесткий и магнитооптический диски наиболее схожи между собой, так как и то и другое является запоминающим устройством большой емкости с произволь' ным доступом. Однако жесткий диск— неудаляемое устройство, а магнитооп-тический носитель можно извлечь из привода, не выключая компьютера. Это накладывает определенные требования на стратегию кэширования соответствующего устройства и требует от драйвера способности понимать и обрабатывать аппаратный сигнал о смене устройства.
Такой сигнал следует передать модулям управления дисковым кэшем и файловой системой, которые, в свою очередь, обязаны разумно обработать его: как минимум, дисковый кэш должен объявить все связанные с диском буферы неактуальными, а менеджер файловой системы должен сбросить все свои внутренние структуры данных, связанные с удаленным диском, и объяснить всем пользовательским программам, работавшим с этим диском, что их данные пропали. Другие аспекты работы с удаляемыми носителями обсуждаются в разд. Устойчивость ФС к сбоям.
CD-ROM, в свою очередь, нельзя рассматривать как удаляемый диск, доступный только для чтения: практически все CD-ROM приводы, кроме функции считывания данных, еще имеют функцию проигрывания музыкальных компакт-дисков.
Лентопротяжка и сканер вообще не являются устройствами памяти прямого доступа, а сканер даже с самой большой натяжкой нельзя рассматривать как устройство памяти.
Когда OS/2 управляет описанной аппаратной конфигурацией, оказываются задействованы пять DMD (Рисунок 10.4)
OS2DASD.DMD управляет классом запоминающих устройств прямого доступа и предоставляет стандартные функции для доступа к дискам.
OPTICAL.DMD обеспечивает управление устройствами прямого доступа с удаляемыми носителями. Основная его задача — обработка аппаратного сигнала смены носителя и оповещение других модулей системы (дискового кэша, файловой системы) об этой смене.
OS2CDROM.DMD обеспечивает специфические для приводов CD-ROM функции, например проигрывание аудизаписей.
OS2SCSI.DMD OS2ASPI.DMD — эти два модуля будут описаны далее.
Каждый из этих DMD не работает непосредственно с аппаратурой, а транслирует запросы пользовательских программ и других модулей ядра (в первую очередь, менеджеров файловых систем) в запросы к драйверу нижнего уровня. Такой подход позволяет вынести общую для класса устройств логику в DMD и не заниматься повторной реализацией этой логики в каждом новом драйвере.
Модули STREAMS
Рисунок 10.3. Модули STREAMS

Обмен данными с пользовательским процессом
Обмен данными с пользовательским процессом
Мы уже упоминали, что общение с пользовательским процессом допустимо только в одном из возможных контекстов нити ядра, а именно в пользовательском. Во всех остальных контекстах пользовательский процесс попросту не определен — точнее сказать, активный пользовательский процесс не совпадает с тем процессом, запрос которого в данный момент обрабатывается драйвером.
В этой ситуации вызов примитивов взаимодействия с этим процессом может привести к непредсказуемым результатам.
В ряде случаев вместо драйвера этот обмен осуществляют другие модули ял-ра, например процедуры пред- и постобработки запроса. Непосредственно с пользовательским адресным пространством драйвер должен общаться только в синхронной модели. В этой модели драйвер иногда оказывается вынужден решать и другие, казалось бы несвойственные ему, задачи.
Обработка сигналов драйвером в Unix
Так, в системах семейства Unix все операции ввода-вывода, а также все остальные операции, переводящие процесс в состояние ожидания, могут быть прерваны сигналом. Сигнал представляет собой примитив обработки исключений, отчасти похожий на аппаратное прерывание тем, что при обработке сигнала может быть вызвана предоставленная программистом функция-обработчик. Необработанный сигнал обычно приводит к принудительному завершению процесса.
Будучи прерван сигналом, системный вызов останавливает текущую операцию, и, если это была операция обмена данными, но данных передано не было, возвращает код ошибки EINTR, говорящий о том, что вызов был прерван и, возможно, операцию следует повторить. Код, делающий это, присутствует в примере 10.1.
Например, пользовательский процесс может использовать сигнал SIGALARM для того, чтобы установить свой собственный будильник, сигнализирующий, что операция над устройством исполняется подозрительно долго.
Если драйвер не установит своего будильника и не станет отрабатывать сигналы, посланные процессу, может возникнуть очень неприятная ситуация.
Дело в том, что в Unix все сигналы, в том числе и сигнал безусловного убийства SIGKILL, обрабатываются процедурой постобработки системного вызова. Если драйвер не передает управления процедуре постобработки, то и сигнал, соответственно, оказывается необработанным, поэтому процесс остается висеть.
Других средств, кроме посылки сигнала, для уничтожения процесса в системах семейства Unix не предусмотрено. Поэтому процесс, зависший внутри обращения к драйверу, оказывается невозможно прекратить ни изнутри, ни извне.
Автор столкнулся с этим при эксплуатации многопроцессорной версии системы SCO Open Desktop 4.0. Система была снабжена лентопротяжным устройством, подключаемым к внешней SCSI-шине. Из-за аппаратных проблем это устройство иногда "зависало", прекращая отвечать на запросы системы. Драйвер лен-топротяжки иногда правильно отрабатывал это состояние как аппаратную ошибку, а иногда тоже впадал в ступор, не пробуждаясь ни по собственному будильнику, ни по сигналам, посланным другими процессами. (По имеющимся у автора сведениям эта проблема специфична именно для многопроцессорной версии системы. По-видимому, это означает, что ошибка допущена не в драйвере, а в коде сервисных функций.) В результате процесс, обращавшийся в это время клеите, также намертво зависал, и от него нельзя было избавиться.
Из-за наличия неубиваемого процесса оказывалось невозможно выполнить нормальное закрытие системы; в частности, не получалось размонтировать файловые системы, где зависший процесс имел открытые файлы. Выполнение холодной перезагрузки системы с неразмонтированными файловыми томами
Введение в операционные систем
приводило к неприятным последствиям для этих томов. Одна из аварий, к ко торым это привело, подробно описывается в разд. Восстановление ФС после сбоя.
Ограничения для буферов ПДП
Рисунок 10.8. Ограничения для буферов ПДП

Это является дополнительным доводом в пользу того, чтобы при данными с внешним устройством копировать их в системный буфер а использовать непосредственно пользовательскую память, которая может быть размешена где угодно и с каким угодно выравниванием.
При выделении буферов для ПДП многие ОС позволяют задать огранпч ния, которым должен удовлетворять физический адрес выделенного буфера Не каждый требуемый драйверу ресурс может быть выделен немедленно Многие ОС предоставляют драйверу callback-функции, вызываемые, когда требуемый ресурс становится доступен.
Опережающее чтение
Рисунок 10.9. Опережающее чтение

При записи, казалось бы, нет необходимости дожидаться физическою вершения операции. При этом мы получаем режим, известный как отложенная запись (lazy write— "ленивая" запись, если переводить дослоцц0\ Однако такой режим создает две специфические проблемы.
Во-первых, программа должна знать, когда ей можно использовать буфер данными для других целей. Если система копирует записываемые данные из пользовательского адресного пространства в системное, то эта же проблема возникает внутри ядра; внутри ядра проблема решается использованием многобуферной схемы, и все относительно просто. Однако копирование приводит к дополнительным затратам времени и требует выделения памяти под буферы. Наиболее остро эта проблема встает при работе с дисковыми и сетевыми устройствами, с которыми система обменивается большими объемами данных (а сетевые устройства еще и могут генерировать данные неожиданно). Проблема управления дисковыми буферами подробнее обсуждается в разд. Дисковый кэш.
В большинстве современных вычислительных систем общего назначения накладные расходы, обусловленные буферизацией запросов, относительно невелики или по крайней мере считаются приемлемыми. Но в системах реального времени и/или встраиваемых контроллерах, где время и объем оперативной памяти жестко ограничены, эти расходы оказываются серьезным фактором.
Если же вместо системных буферов используется отображение данных в системное адресное пространство (системы с открытой памятью можно считать вырожденным случаем такого отображения), то ситуация усложняется. Пользовательская задача должна иметь возможность узнать о физическом окончании записи, потому что только после этого буфер действительно свободен. Фактически, программа должна самостоятельно реализовать много-буферную схему или искать другие выходы.
Во-вторых, программа должна дождаться окончания операции, чтобы узнать, успешно ли она закончилась. Часть ошибок, например, попытку записи на устройство, физически не способное выполнить такую операцию, можно отловить еще во время предобработки, однако аппаратные проблемы могут быть обнаружены только на фазе исполнения запроса.
Многие системы, реализующие отложенную запись, при обнаружении аппаратной ошибки просто устанавливают флаг ошибки в блоке управления устройством. Программа предобработки, обнаружив этот флаг, отказывается исполнять следующий запрос. Таким образом, прикладная программа считает ошибочно завершившийся запрос успешно выполнившимся и обнаруживает ошибку лишь при одной из следующих попыток записи, что не совсем правильно.
Иногда эту проблему можно игнорировать. Например, если программа встречает одну ошибку при записи, то все исполнение программы считается неуспешным и на этом заканчивается. Однако во многих случаях, например, задачах управления промышленным или исследовательским оборудованием, программе необходимо знать результат завершения операции, поэтому простая отложенная запись оказывается совершенно неприемлемой.
Так или иначе, ОС, реализующая асинхронное исполнение запросов ввода-вывода, должна иметь средства сообщить пользовательской программе о физическом окончании операции и результате этой операции.
В качестве примера такого консерватизма
Подсистема ввода-вывода OS/2
В качестве примера такого консерватизма можно привести подсистему ввода-вывода OS/2. Совместный проект фирм IBM и Microsoft, OS/2 1.x разрабатывалась как операционная система для семейства персональных компьютеров Personal System/2. Младшие модели семейства были основаны на 16-разрядном процессоре 80286, поэтому вся ОС была полностью 16-битной.
Позднее разработчики фирмы IBM реализовали 32-битную OS/2 2.0, но для совместимости со старыми драйверами им пришлось сохранить 16-битную подсистему ввода-вывода. Все точки входа драйверов должны находиться в 16-битных ('USE16') сегментах кода; драйверам передаются только 16-разрядные ('far') указатели и т. д.
По утверждению фирмы IBM, они рассматривали возможность реализации также и 32-битных драйверов, но их измерения не показали значительного повышения производительности при переходе к 32-битной модели. Позднее, впрочем, суперскалярные процессоры архитектуры х86, оптимизированные Дл^ исполнения 32-разрядного кода, все-таки продемонстрировали значительный рост производительности для такого кода по сравнению с 16-разрядным, и, начиная с OS/2 4.0 32-битный интерфейс все-таки предоставляется, но без отказа от поддержки старых, 16-разрядных драйверов.
Благодаря этому сохраняется возможность использовать драйверы, разработанные еще в конце 80-х и рассчитанные на OS/2 1.x. Эта возможность оказывается особенно полезна при работе со старым оборудованием.
Напротив, разработчики фирмы Microsoft отказались от совместимости с 16-битными драйверами OS/2 1.x в создававшейся ими 32-битной версии OS/2 называвшейся OS/2 New Technology. Фольклор утверждает, что именно это техническое решение оказалось причиной разрыва партнерских отношении между Microsoft и IBM, в результате которого OS/2 NT вышла на рынок под названием Windows NT 3.1.
Подсистема вводавывода Windows 9x/ME
Подсистема ввода-вывода Windows 9x/ME
Сама фирма Microsoft, впрочем, демонстрирует почти столь же трогательную приверженность к совместимости со старыми драйверами: системы линии Windows 95/98/ME до сих пор используют весьма своеобразную архитектуру, основной смысл которой — возможность применять, пусть и с ограничениями, драйверы MS DOS.
Windows 9х и Windows 3.x в enhanced-режиме предоставляют вытесняющую многозадачность для VDM (Virtual DOS Machine— Виртуальная машина [для] DOS), однако сами используют DOS для обращения к дискам и дискетам. Ядро однозадачной DOS не умеет отдавать управление другим процессам во время исполнения запросов ввода-вывода. В результате во время обращения к диску все остальные задачи оказываются заблокированы.
У современных PC время исполнения операций над жестким диском измеряется десятыми долями секунды, поэтому фоновые обращения к жесткому диску почти не приводят к нарушениям работы остальных программ. Однако скорость работы гибких дисков осталась достаточно низкой, следовательно, работа с ними в фоновом режиме блокирует систему на очень заметные промежутки времени.
Эффектная и убедительная демонстрация этой проблемы очень проста: достаточно запустить в фоновом режиме форматирование дискеты или просто команду COPY С:\ТМР\*.* А: , если в каталоге C:\TMP достаточно много данных. При этом работать с системой будет практически невозможно: во время обращений к дискете даже мышиный курсор не будет отслеживать движений мыши, будут теряться нажатия на клавиши и т. д.
Windows 95/98/ME использует несколько методов обхода DOS при обращениях к диску, поэтому пользователи этой системы не всегда сталкиваются с описанной проблемой. Однако при использовании блочных драйверов реального режима система по-прежнему применяет DOS в качестве подсистемы ввода-вывода, и работа с дискетами в фоновых задачах также нарушает работу задач первого плана.
Если говорить о совместимости, то со многих точек зрения очень привлекательной представляется идея универсального драйвера — модуля, который без изменении или с минимальными изменениями может использоваться Для управления одним и тем же устройством в различных ОС.
К сожалению — несмотря даже на то, что, как мы увидим далее, в общих чертах архитектура драйвера в большинстве современных ОС удивительн похожа — идея эта, по-видимому, нереализуема. Даже для близкородственных ОС — например, систем семейства Unix — драйверы одного и того ж устройства не всегда могут быть легко перенесены из одной ОС в другую говоря уж о возможности использования без модификаций. Еще более удивительным является тот факт, что две линии ОС - Windows 95/98/MЕ и Windows NT/2000/XP — поставляемых одной и той же компанией Microsoft и реализующих почти один и тот же интерфейс системных вызовов — Win32 — имеют совсем разный интерфейс драйвера.
Проблема здесь в том, что интерфейс между драйвером и ядром ОС всегда двусторонний: не только прикладные программы и ядро вызывают функции драйвера, но и, наоборот, драйвер должен вызывать функции ядра. Структура интерфейсов ядра, доступных драйверу, определяет многие аспекты архитектуры ОС в целом.
В предыдущих главах мы уже обсуждали многие из ключевых вопросов: способ сборки ядра, стратегию управления памятью, способы обмена данными между ядром и пользовательскими процессами, и, наконец, механизмы межпоточного взаимодействия — между нитями самого драйвера (ниже мы увидим, что подавляющее большинство драйверов состоит как минимум из двух нитей), между драйвером и остальными нитями ядра и между драйвером и нитями пользовательских процессов.
Изложение решений перечисленных проблем составляет если и не полное описание архитектуры ОС, то, во всяком случае, значительную его часть. Так, переход от однозадачной системы или кооперативной многозадачности к вытесняющей многозадачности может потребовать не только изменения планировщика, но и радикальной переделки всей подсистемы ввода-вывода, в том числе и самих драйверов.
Таким образом, до тех пор, пока используются ОС различной архитектуры, разработка универсального интерфейса драйвера, если теоретически п возможна, то практически вряд ли осуществима.
Скелет драйвера последовательного
Пример 10.1. Скелет драйвера последовательного устройства для ОС Linux
f* Основная нить драйвера */
static int foo_write(struct inode * inode, struct file * file, char * buf, int count)
Щ
/* Получить идентификатор устройства: */
к/с в операционные систв
unsigned int minor = MINOR(inode->i_rdev); unsigned long copy size; unsigned long total_bytes_written = 0; unsigned long bytes__written;
/* Найти блок переменных состояния устройства */ struct foo_struct *foo = &foo_table[minor];
do { copy_size = (count <= FOO_BUFFER_SIZE ?
count : FOOJ3UFFER_'SIZE) ;
/* Передать данные из пользовательского контекста */ memcpy_fromfs(foo->foo_buffer, buf, copy_size);
while (copy_size) {
/* Здесь мы должны инициализировать прерывания*/
if (some_error_has_occured) { /* Здесь мы должны обработать ошибку */
current->timeout = jiffies + FOO_INTERRUPT_TIMEOUT;
/* Установить таймаут на случай, если прерывание будет пропущено */
interruptible_sleep_on (&f oo->foo_wait_queue) ;
if (some_error_has_occured) { /* Здесь мы должны обработать ошибку */
bytes_written = foo->bytes_xfered; foo->bytes_written = 0;
if (current->signal H ~current->blocked) { if (total_bytes_written + bytes__written)
return total_bytes_written + bytes_written; else
return -EINTR; /* Ничего не было записано, системный вызов был прерван, требуется повторная попытка */
O- Драйверы внешних устройств
total_byr.c5_v;r:.i.U-.r. т= bytes_written; buf += bytes_written; count -= bytes_written;
) while (count > 0) ; return total_bytes_written;
/* Обработчик прерывания */ static void foo__interrupt (int irq)
{ struct foo_struct *foo = &foo__table [foo_irq[irq] ] ;
/* Здесь необходимо выполнить все действия, которые должны быть выполнены по прерыванию.
Флаг в foo__table указывает, осуществляется операция чтения или записи. */
/* Увеличить foo->bytes_xfered на количество фактически переданных символов * /
if (буфер полон/пуст) wake_up_interruptible (&foo->foo_wait_queue) ;
}
Примечание
Примечание
Обратите внимание, что кроме инициализации устройства драйвер перед засыпанием еще устанавливает "будильник" — таймер, который должен разбудить процесс через заданный интервал времени. Это необходимо на случай, если произойдет аппаратная ошибка и устройство не сгенерирует прерывания. Если бы такой будильник не устанавливался, драйвер в случае ошибки мог бы заснуть навсегда, заблокировав при этом пользовательский процесс. В нашем случае таймер также используется, чтобы разбудить процесс, если прерывание произойдет до вызова interruptible_sleep_on основной нитью.
Многие устройства, однако, требуют для исполнения некоторых, даже относительно простых, операций, несколько команд и несколько прерываний. Так, при записи данных посредством контроллера гибких дисков, драйвер должен:
включить мотор дисковода; дождаться, пока диск разгонится до рабочей скорости (большинство контроллеров генерируют по этому случаю прерывание); дать устройству команду на перемещение считывающей головки; дождаться прерывания по концу операции перемещения; запрограммировать ПДП и инициировать операцию записи; дождаться прерывания, сигнализирующего о конце операции.Лишь после этого можно будет передать данные программе. Наивная реализация таких многошаговых операций могла бы выглядеть так (за основу по-прежнему взят код из [HOWTO khg], обработка ошибок опущена), как показано в примере 10.2.
Простой драйвер контроллера
Пример 10.2. Простой драйвер контроллера гибкого диска
/* Обработчики прерываний в зависимости от состояния */ void handle_spinup_interrupt(int irq, fdd_struct *fdd) {
if (motor_speed_ok(fdd)) wake_up_interruptible((&fdd->fdd_wait_queue);
void handle_seek_interrupt(int irq, fdd_struct *fdd) {
if (verify_track(fdd)) wake_up_interruptible((&fdd->fdd_wait_queue);
void handle_dma_interrupt(int irq, fdd_struct *fdd) {
/* Увеличить fdd->bytes_xfered на количество фактически переданных символов */
if (буфер полон/пуст) wake_up_interruptible(&fdd->fdd_wait_queue);
/* Основная нить драйвера */
static int fdd_write(struct inode * inode, struct file * file, char * buf, int count)
10. Драйверы внешних устройств
/* Получить идентификатор устройства: */ = MINOR ( inode->irdev) ;
unsigned long ccpy_size;
unsigned long total_bytes_written = 0;
unsigned long bytes_written;
int state;
/* Найти блок переменных состояния устройства */ struct fdd_struct *fdd = &fdd_table [minor] ;
do { copy_size = (count <= FDD__BUFFER_SIZE ?
count : FDD_BUFFER_SIZE) ;
/* Передать данные из пользовательского контекста */ memcpy_f rornfs (fdd->fdd_buf fer, buf, copy_size) ;
while (copy_size) { if ( !motor_speed_ok (fdd) ) { fdd->handler = handle__spinup_interrupt; turn_motor_on (fdd) ;
current->timeout = jiffies + FDD_INTERRUPT_TIMEOUT; interruptible_sleep_on (&fdd->fdd_wait_queue) ; if (current->signal & -current->blocked) { if (total_bytes_written)
return total_bytes_written; else
return -EINTR; /* Ничего не было записано, системный вызов был прерван, требуется повторная попытка */
if (fdd->current_track != CALCULATE_TRACK(file)) { fdd->handler = handle_seek_interrupt; seek_head (fdd, CALCU1ATE__TRACK (f ile) ) ; current->timeout = jiffies + FDD_INTERRUPTjriMEOUT; interruptible_sleep_on(&fdd->fdd__wait_queue); if (current->signal & ~current->blocked) ( if (total bytes written)
Введение в операционныесист^
return total_bytes_written; else
return -EINTR; /* Ничего не было записано, системный вызов был прерван, требуется повторная попытка */
fdd->handler = handle_dma_interrupt;
setup_fdd_dma(fdd->fdd_buffer+bytes_xfered, copy_size) issue_write_command(fdd) ;
current->timeout = jiffies + FDD_INTEKRUPT_TIMEOUT; interruptible_sleep_on (Sfdd->fdd_wait_queue) ;
bytes_written = fdd->bytes_xfered; fdd->bytes_written = 0;
if (current->signal & ~current->blocked) { if (total_bytes_written + bytes_written)
*
return total_bytes_written + bytes_written; else
return -EINTR; /* Ничего не было записано, системный вызов был прерван, требуется повторная попытка */
total_bytes_written += bytes_written; buf += bytes__written; count -= bytes_written;
} while (count > 0) ; return total bytes written;
/* Обработчик прерывания */ static void fdd_interrupt(int irq) { struct fdd_struct *fdd = &fdd_table[fdd_irq[irq]];
f (fdd->ha:idier != NULL) { fdd->handier(irq, fdd); fdd->handIer=MULL;
} else
{
/* He наше прерывание? */
}
}
Видно, что предлагаемый драйвер осуществляет обработку ошибок и формирование последующих команд в основной нити драйвера. Велик соблазн перенести эти функции или их часть в обработчик прерываний. Такое решение позволяет сократить интервал между последовательными командами, и, таким образом, возможно, повысить производительность работы устройства.
Однако слишком большое время, проводимое в обработчике прерывания, нежелательно с точки зрения других модулей системы, так как может увеличить реальное время реакции для них. Особенно важно это для систем, которые выключают планировщик на время обслуживания прерываний. Поэтому многие ОС накладывают ограничения на время обслуживания прерываний, и часто это ограничение исключает возможность формирования команд и произведения других сложных действий в обработчике.
Обработчик, таким образом, должен выполнять лишь те операции, которые требуется выполнить немедленно. В частности, многим устройствам требуется так или иначе объяснить, что прерывание обработано, чтобы они сняли сигнал запроса прерывания. Если этого не сделать, после возврата из обработчика и обусловленного этим снижения приоритета ЦПУ, обработчик будет вызван опять.
Впрочем, нередко предлагается путь к обходу и этого ограничения: обработчикам прерываний разрешено создавать высокоприоритетные нити, которые начнут исполняться сразу же после того, как будут обслужены все прерывания. В дальнейшем мы будем называть эти высокоприоритетные нити fork-процессами (этот термин используется в VMS. Другие ОС, хотя и используют аналогичные понятия, часто не имеют внятной терминологии для их описания).
Более сложный драйвер
Пример 10.3. Более сложный драйвер контроллера гибкого диска
/* Обработчики прерываний в зависимости от состояния */ void schedule_seek (fdd__struct *fdd)
if ( !motor_speed_pk (fdd) ) {
fdd->handler = schedule_seek;
retry_spinup ( ) ; }
if (fdd->current_track != CALCULATEJTRACK (fdd->f ile) ) fdd->handler = schedule_command; seek_head(fdd, CALCULATE_TRACK (f ile) } ; } else
/* Мы уже на нужной дорожке */ schedule operation (fdd) ;
void schedule_operation(fdd_struct *fdd) {
if (fdd->current_track != CALCULATEJTRACK(fdd->file)) { fdd->handler = schedule_operation; retry_seek(fdd); return; }
switch(fdd->operation) ( case FDD_WRITE:
fdd->handler = handle_dma_write_interrupt; setup_fdd_dma(fdd->fdd_buffer+fdd->bytes__xfered, fdd->copy_size)
I issue_write_coromand (fdd) ; break; case FDD_READ:
fdd->handler = handle_dma_read_interrupt;
setup_fdd_dma (fdd->fdd_buf fer-t-fdd->bytes_xfered, fdd->copy_size)
issue_read_command (fdd) ;
break; /* Здесь же мы должны обрабатывать другие команды,
требующие предварительного SEEK */
void handle_dma_write_interrupt (fdd_struct *fdd)
( /* Увеличить fdd->bytes_xfered на количество фактически
переданных символов * /
if (буфер полон/пуст)
/* Здесь мы не можем передавать данные из пользовательского
адресного пространства . Надо будить основную нить * /
wake_up_interruptible (&fdd->fdd_wait_queue) ; else {
fdd->handler = handle__dma__write_interrupt;
setup_fdd__dma (fdd->fdd_buf fer+fdd->bytes_xfered, fdd->copy_size)
issue_write_corranand(fdd) ;
/* Основная нить драйвера */
static int fdd_write (struct inode * inode, struct file * file,
char * buf, int count) (
/* Получить идентификатор устройства: */ unsigned int minor = MINOR ( inode->i_rdev) ; /* Обратите внимание, что почти все переменные основной нити
"переехали" в описатель состояния устройства */ /* Найти блок переменных состояния устройства */ struct fdd struct *fdd = &fdd table [minor] ;
fdd->total_bytes_written = 0; fdd->operation = FDD_WRITE;
do { fdd->copy_size = (count <= FDD_BUFFER_SIZE ?
count : FDD_BOFFER_SIZE);
/* Передать данные из пользовательского контекста */ memcpy_fromfs(fdd->fdd_buffer, buf, copy_size);
if (!motor_5peed_ok()) (
fdd->handler = schedule_seek;
turn_motor_on(fdd); } else
schedule_seek(fdd) ;
current->timeout = jiffies + FDD_INTERRUPT__TIMEOUT; inte.rruptible_sleep_on(&fdd->fdd_wait_queue); if (current->signal & ~current->blocked) { if (fdd->total_bytes_written+fdd->bytes__written)'
return fdd->total_bytes_written+fdd->bytes_written; else
return -EINTR; /* Ничего не было записано,
системный вызов был прерван, требуется повторная попытка */
fdd->total_bytes_written += fdd->bytes_written; fdd~>buf += fdd->bytes_written; count -= fdd->bytes_written;
} while (count > 0) ; return total bytes written;
static struct tq_struct floppy_tq;
/* Обработчик прерывания */ static void fdd interrupt(int irq)
truct fdcl struct *fdd = &fdd_table [fdd_irq [irq] ] ;
Af (fdd->ha!,;;ier != NULL) {
void (Chandler)(int irq, fdd_struct * fdd) ;
f]_0ppy_tq. routine = (void *)(void *) fdd->handler;
floppy tq.parameter = (void *)fdd;
fdd->handler=NULL;
queue_task(sfloppy_tq, &tq_immediate); } else
{ /* He наше прерывание? */
}
}
Видно, что теперь наш драйвер представляет собой последовательность функций, вызываемых обработчиком прерываний. Обратите внимание, что если мы торопимся, очередную функцию можно вызывать и непосредственно в обработчике, а не создавать для нее fork-процесс посредством queue_task. Но самое главное, на что нам следует обратить внимание — последовательность этих функций не задана жестко: каждая из функций сама определяет, какую операцию вызывать следующей. В том числе, она может решить, что следующая операция может состоять в вызове той же самой функции. В примере 10.3 мы используем эту возможность для простой обработки ошибок: повтора операции, которая не получилась.
Для того чтобы понять, что же у нас получилось, какие возможности нам открывает такая архитектура и как ими пользоваться, нам следует сделать экскурс в одну из важных областей теории программирования.
Конечный автомат драйвера
Пример 10.4. Конечный автомат драйвера контроллера IDE/ATA для OS/2
VOID NEAR StartSM( NPACB npACB )
}
/* ------------------------------------------------ */
* Проверка счетчика использований АСВ*/
/* -------------------- */
/* Автомат реентрантен для каждого АСВ / *
/* ------------------------------------------------ */
DISABLE
npACB->UseCount++;
iff npACB->UseCount == 1 )
{
do
{
ENABLE
do
{
npACB->Flags &= ~ACBF_WAITSTATE;
switch (npACB->State) {
case ACBS__START :
StartState(npACB);
break;
case ACBS_INTERRUPT:
InterruptState(npACB);
break;
case ACBS_DONE:
DoneState(npACB);
break;
case ACBS_SUSPEND:
SuspendState(npACB);
break;
case ACBS_RETRY:
RetryState(npACB);
break;
case ACBS_RESETCHECK:
ResetCheck(npACB);
break/case ACBS_ERROR:
ErrorState(npACB);
break;
while ( !(npACB->Flags & ACBF WAITSTATE) );
DISABLE
I
while ( — npACB->UseCount ) ;
Фрагменты драйвера
Пример 10.5. Фрагменты драйвера диска IDE/ATA ОС Linux 2.2, перевод комментариев автора
/*
* ide_multwrite() передает приводу блок из не более, чем mcount
* секторов как часть многосекторной операции записи. *
* Возвращает 0 при успехе. *
* Обратите внимание, что мы можем быть вызваны из двух контекстов -
* контекста do_rw и контекста IRQ. IRQ (Interrupt Request,
* запрос прерывания)может произойти в любой
* момент после того, как мы выведем полное количество секторов,
* поэтому мы должны обновлять состояние _до_ того, как мы выведем
* последнюю часть данных! */
int ide_multwrite (ide_drive__t *drive, unsigned int mcount) {
ide_hwgroup_t *hwgroup= HWGROUP(drive);
'struct request *rq = &hwgroup->wrq;
do {
char *buffer;
int nsect = rq->current_nr_sectors;
if (nsect > mcount)
nsect = mcount; mcount -= nsect; buffer = rq->buffer;
rq->sector += nsect; rq->buffer += nsect « 9; rq->nr_sectors -= nsect; rq->current nr sectors -= nsect;
/* Переходим ли мы к следующему bh после этого? */ if (!rq->current_nr_sectors) {
struct buffer_head *bh = rq->bh->b_reqnext;
/* Завершиться, если у нас кончились запросы V if (!bh) {
mcount = 0; } else (
rq->bh = bh;
rq->current_nr_sectors = bh->b_size » 9;
rq->buffer = bh->b_data;
/*
* Теперь мы все настроили, чтобы прерывание
* снова вызвало нас после последней передачи. */
idedisk_output_data(drive, buffer, nsect«7); } while (mcount);
return 0;
/*
* multwrite_intr() — обработчик прерывания многосекторной записи */
static ide_startstop_t multwrite_intr (ide_drive_t *drive) {
byte stat;
ir.t i;
ide_hwgroup_t *hwgroup = HWGROUP(drive);
struct request *rq = &hwgroup->wrq;
if (OK_STAT(stat=GET_STAT(),DRIVE_READY,drive->bad_wstat)) { if (stat & DRQ_STAT) { /*
* Привод требует данных. Помним что rq -
* копия запроса. */
if (rq->nr_sectors) {
if (ide_multwrite(drive, drive->mult_count))
return ide_stopped; «
ide_set__handler (drive, &multwrite_intr, WAIT_CMD, NULL); return ide_started; }
} else { /*
* Если копирование всех блоков завершилось,
* мы можем завершить исходный запрос. */
if ( ! rq->nr__sectors) { /* all done? */ rq = hwgroup->rq; for (i = rq->nr_sectors; i > 0;){ i -= rq->current_nr_sectors; ide_end_request(1, hwgroup); } return ide stopped;
return ide_stopped; /* Оригинальный код делал это здесь (?) */
! ьнешних
[return ide_errcr(drive, "multwrite_intr", stat);
/*
i do rw disk() передает команды READ и WRITE приводу,
* используя LBA если поддерживается, или CHS если нет, для адресации
* секторов. Функция do_rw_disk также передает специальные запросы.
*/
static ide_startstop__t do_rw_disk (ide_drive_t *drive, struct request *rq, unsigned long block)
{ if (IDE_CONTROL_REG)
OUT_BYTE (drive->ctl, IDE_CONTROL_REG) ; OUT_BYTE (rq->nr_sectors, IDE_NSECTOR_REG) ; if (drive->select.b.lba) (
OUT_BYTE (block, IDE_SECTOR_REG) ;
OUT_BYTE (block»=8, IDE_LCYL_REG) ;
OUT_BYTE (block»=8, I DE_HC YL_REG ) ;
OUT_BYTE( ( (block»8) &0x0f) I drive->select . all, IDE_SELECT_REG) ; } else f
unsigned int sect, head, cyl, track;
track = block / drive->sect;
sect = block % drive->sect + 1;
ODT^BYTE (sect, IDE__SECTOR_REG) ;
head = track % drive->head;
cyl = track / drive->head;
OUT__BYTE (cyl, IDE_LCYL_REG) ;
OUT_BYTE (cyl»8, IDE_HCYL_REG) ;
OUT_BYTE (head I drive->select .all, IDE_SELECT_REG) ;
if (rq->cmd == READ) { ^#ifdef CONFIG_BLK_DEV_IDEDMA
if (drive- >using_dma && ! (HWIF (drive) ->dmaproc (ide_dma_read, drive))
return ide_started; #endif /* CONFIG_BLK_DEV_IDEDMA */
ide_set_handler (drive, iread_intr, WAIT_CMD, NULL) ; OUT_BYTE(drive->mult_count ? WIN_MULTREAD : WIN_READ, IDE COMMAND REG) ;
''—-^
return ide started;
if (rq->cmd == WRITE) (
ide_startstop_t startstop; lifdef CONFIG_BLK_DEV_IDEDMA
if (drive->using_drna && !(HWIF(drive)->dmaproc(ide dma^write,
drive)))
return ide_started; lendif /* CONFIG_BLK_DEV_IDEDMA */
OUT_BYTE(drive->mult_COUnt ? WIN_MULTWRITE : WIN_WRITE,
IDE_COMMAND_REG); if (ide_wait_stat(Sstartstop, drive, DATA_READY, drive->bad_wstat,
WAIT^DRQ)) ( printk(KERN_ERR "%s: no DRQ after issuing %s\n", drive->na:r.e,
drive->mult_count ? "MULTWRITE" : "WRITE"); return startstop;
if (!drive->unmask)
__cli(); /* только локальное ЦПУ */
if (drive->mult_count) (
ide_hwgroup_t *hwgroup = HWGROUP(drive);
/*
* Эта часть выглядит некрасиво, потому что мы ДОЛЖНЫ установить
* обработчик перёд выводом первого блока данных.
* Если мы обнаруживаем ошибку (испорченный список буферов)
* в ide_multiwrite(),
* нам необходимо удалить обработчик и таймер перед возвратом.
* К счастью, это НИКОГДА не происходит (правильно?).
* Кажется, кроме случаев, когда мы получаем ошибку... */
hwgroup->wrq = *rq; /* scratchpad */
ide_set_handler (drive, &multwrite_intr, WAIT__CMD, NULL);
if (ide_multwrite(drive, drive->mult_count)) {
unsigned long flags;
spin_lock_irqsave (&io__request_lock, flags) ;
hwgroup->handler = NULL;
del_timer(&hwgroup->timer);
spin unlock_irqrestore(&io_request_lock, flags);
return ide_stopped;
Глава 10. Драйверы внешних
} else {
ide_set_handler (drive, &write_intr, WAIT_CMD, NULL); idedisk_output_data(drive, rq->buffer, SECTOR_WORDS);
}
i return ide_started;
)
i'-printk (KERN_ERR "%s: bad command: %d\n", drive->name, rq->cmd)
ide_end_request(0, HWGROUP(drive)); return ide_stopped;
Различные типы позиционных устройств ввода
Рисунок 10.2. Различные типы позиционных устройств ввода

В этом случае также целесообразно реализовать четыре самостоятельных драйвера транспортных портов (тем более что к этим портам могут подключаться и другие устройства) и три драйвера протоколов обмена, способных работать с любым транспортным портом. Объединение этих драйверов в одном модуле может создать некоторые — довольно, впрочем, сомнительные — удобства администратору системы, в которой используется стандартная комбинация порта и мыши, но поставит в безвыходное положение администратора системы, в которой комбинация нестандартная, например, не позволяя использовать мышь, подключенную к мультипортовой плате.
В современных системах семейства Unix многоэтапная обработка запросов штатно поддерживается потоковыми драйверами: система предоставляет специальные системные вызовы push и pop, позволяющие добавлять дополнительные драйверы, обслуживающие поток. Дополнительные могут преобразовывать данные потока (например, символы протокола мыши в координаты курсора и нажатия и отпускания кнопок) или обрабатывать запросы ioctl [docs.sun.com 805-7478-10].
В частности, в современных системах семейства Unix драйверы терминальных устройств должны уметь обрабатывать достаточно обширный набор запросов ioctl и выполнять ряд важных функций по управлению заданиями [Хевиленд/Грэй/Салама 2000]. В монолитных системах эти функции обязан реализовать сам драйвер устройства (хотя ядро и облегчает создателю драйвера эту работу, предоставляя библиотеку сервисных функций — см. [Максвелл 2000]), в то время как в системах, имеющих потоковые драйверы, драйвер устройства может ограничиться решением своей собственной задачи — обеспечением обмена данными с устройством, а все сложные терминальные сервисы, если это необходимо, предоставляются простым добавлением к потоку драйвера модуля терминальной дисциплины (Рисунок 10.3).
Развертывание циклов в графе состояния
Рисунок 10.6. Развертывание циклов в графе состояния

С другой стороны, ряд даже довольно сложных алгоритмов естественным образом описывается автоматами с небольшим числом состояний, которые могут быть закодированы одной скалярной переменной состояния или стеком таких переменных. Такие автоматы находят применение в самых разнообразных задачах: лексическом и синтаксическом разборе контекстно-свободных и многих типах контекстно-связанных языков [Кормен/ Пейзерсон/Ривест 2000 1, реализации сетевых протоколов, задачах корпоративного документооборота (Керн/Линд 2000] и др. В частности, легко понять, что обсуждаемый нами алгоритм драйвера относится именно к этой категории алгоритмов.
Два основных подхода к реализации конечных автоматов — это развернутые (unrolled) автоматы и автоматы общего вида. Примером развернутого конечного автомата является код основной нити примера 10.2. Понятно, что развертыванию поддаются только автоматы с весьма специфической — линейной или древовидной — структурой графа состояний, и если в процессе уточнения требований мы выясним, что структура автомата должна быт более сложной, нам придется полностью реорганизовать код.
Автомат общего вида выглядит несколько сложнее, но, научившись распознавать его конструкцию, легко разрабатывать такие программы по задан ной блок-схеме и, наоборот, восстанавливать граф состояний по коду программы. Главным преимуществом грамотно реализованного конечного автомата является легкость модификации: если граф переходов измените нам надо будет изменить код только тех узлов, которые затронуты изменением.
Примеры реализации конечных автоматов такого типа на процедурном языке программирования приводятся во многих учебниках программированию например [Грогоно 1982). Чаще всего реализация состоит из цикла, условием выхода из которого является достижение автоматом финального состояния, и размещенного в теле цикла оператора вычислимого перехода с переменной состояния в качестве селектора. Конечный автомат, похожий на эту классическую реализацию, приведен в примере 10.4.
Сервисные функции
Сервисные функции
Набор сервисных функций, доступных драйверу, обычно представляет собой подмножество стандартной библиотеки того языка высокого уровня, на котором обычно пишутся драйверы. В большинстве современных ОС это С. При выборе этого подмножества используется простой критерий: удаляются или заменяются на более или менее ограниченные все функции, которые так или иначе содержат в себе системные вызовы. Так, функции memcpy или sprintf вполне можно оставить, malloc придется заменить на эквивалент (в ядре Linux эта функция называется kmaiioc), a fwrite драйверу вряд ли понадобится, особенно если учесть, что работа многих драйверов начинается до того, как будет смонтирована хоть одна файловая система.
Важную роль среди сервисных функций занимают операции, часто исполняемые одной командой, но такой, которую компиляторы ЯВУ в обычных условиях не генерируют. Это, прежде всего, операции обращения к регистрам ввода-вывода в машинах с отдельным адресным пространством ввода-вывода, а также команды разрешения и запрещения прерываний. На С такие операции реализуются в виде макроопределений, содержащих ассемблерную вставку.
Правила кодирования драйверов во многих ОС требуют, чтобы даже на машинах с единым адресным пространством обращения к регистрам устройств происходили посредством макросов. Такой код может быть легко портнро-ван на процессор с отдельным адресным пространством. В наше время, когда одни и те же устройства и одни и те же периферийные шины подключаются к различным процессорам, портирование драйверов между различными процессорами осуществляется весьма часто.
При портировании драйвера разработчик должен также принимать во внимание различия в порядке байтов устройства и текущего процессора. Для приведения этого параметра в соответствие обычно предоставляются функции или макросы перестановки байтов как в одном слове, так и в блоках значительного размера.
Сервисы ядра доступные драйверам
Сервисы ядра, доступные драйверам
Следует провести различие между системными вызовами и функциями ядра, доступными для драйверов. Наборы системных вызовов и драйверных сервисов совершенно независимы друг от друга. Как правило, системные вызовы недоступны для драйверов, а драйверные сервисы — для пользовательских программ.
Системный вызов включает в себя переключение контекста между пользовательской программой и ядром. В системах с виртуальной памятью во время такого переключения процессор переходит из "пользовательского" режима, в котором запрещены или ограничены доступ к регистрам диспетчера памяти, операции ввода-вывода и ряд других действий, в "системный", в котором все ограничения снимаются. Обычно системные вызовы реализуются с использованием специальных команд процессора, чаше всего — команды программного прерывания.
Драйвер же исполняется в "системном" режиме процессора и, как правило, в контексте ядра, поэтому для вызова сервисов ядра драйверу не надо делать никаких переключений контекста. Практически всегда такие вызовы реализуются обычными командами вызова подпрограммы.
Еще одно важное различие состоит в том, что, исполняя системный вызов, программисту не надо заботиться о его реентерабельности: ядро либо обеспечивает подлинную реентерабельность, либо создает иллюзию рентабельности благодаря тому, что исполняется с более высоким приоритетом, чем все пользовательские программы. Напротив, доступные драйверам сервисы ядра делятся на две группы — те сервисы, которые можно вызывать из обработчиков прерываний и те, которые нельзя.
Сервисы, доступные для обработчиков прерываний, должны удовлетворят двум требованиям: они должны быть реентерабельными и завершаться за гарантированное время. Например, выделение памяти может потребовать сборки мусора или даже поиска жертвы для удаления в адресных пространствах пользовательских задач. Кроме того, выделение памяти требует работы с разделяемым ресурсом (пулом памяти ядра) и его достаточно сложно реализовать реентерабельным образом, поэтому обработчикам прерываний очень редко разрешают запрашивать память.
Копирование данных между пользовательским и системным адресными пространствами может привести к возникновению страничного отказа, время обработки которого может быть непредсказуемо большим.
Далее, для краткости, мы будем называть доступные для обработчиков прерываний сервисы реентерабельными, хотя для них важна не только реентерабельность, но и завершение в течение фиксированного времени. В предыдущих разделах мы упоминали некоторые категории сервисов, предоставляемых драйверам. Эти сервисы включают в себя (приведенный список не является исчерпывающим) следующие.
Некоторые из групп этих функций будут подробнее описаны далее.
Синхронный и асинхронный вводвывод в RSX11 и VMS
Синхронный и асинхронный ввод-вывод в RSX-11 и VMS
Например, в системах RSX-11 и VAX/VMS фирмы DEC для синхронизации используется флаг локального события (local event flag). Как говорилось в разд. Семафоры, флаг события в этих системах представляет собой аналог двоичных семафоров Дейкстры, но с ним также может быть ассоциирована процедура AST. Системный вызов ввода-вывода в этих ОС называется QIC (Queue Input/Output [Request] — установить в очередь запрос ввода-вывода) и имеет две формы: асинхронную QIO и синхронную QIOW (Queue Input/Output and Wait— установить запрос и ждать [завершения]). С точки зрения подсистемы ввода-вывода эти вызовы ничем не отличаются, просто при запросе QIO ожидание конца запроса выполняется пользовательской программой "вручную", а при QIOW выделение флага события и ожидание его установки делается системными процедурами пред- и постобработки.
В ряде систем реального времени, например, в OS-9 и RT-11, используются аналогичные механизмы.
Напротив, большинство современных ОС общего назначения не связываются с асинхронными вызовами и предоставляют прикладной программе чисто синхронный интерфейс, тем самым вынуждая ее ожидать конца операции.
Возможно, это объясняется идейным влиянием ОС Unix. Набор операций ввода-вывода, реализованных в этой ОС, стал общепризнанным стандартом де-факто и основой для нескольких официальных стандартов. Например, набор операций ввода-вывода в MS DOS является прямой копией Unix; кроме того, эти операции входят в стандарт ANSI на системные библиотеки языка С и стандарт POSIX.
Современные системы семейства Unix разрешают программисту выбирать между отложенной записью по принципу Fire And Forget (выстрелил и забыл) и полностью синхронной, используя вызов fcntl с соответствующим кодом операции.
Если все-таки нужен более детальный контроль над порядком обработки запросов, разработчикам предлагается самостоятельно имитировать асинхронный обмен, создавая для каждого асинхронно исполняемого запроса свою нить. Эта нить тем или иным способом сообщает основной нити о завершении операции. Для этого чаще всего используются штатные средства межпоточного взаимодействия — семафоры и др. Грамотное использование нитей позволяет создавать интерактивные приложения с очень высоким субъективным временем реакции, но за это приходится платить усложнением логики программы. В Windows NT/2000/XP существует средство оргащ, зации асинхронного ввода-вывода — так называемые порты завершения (операции) (completion ports). Однако это средство не поддерживается в Windows 95, поэтому большинство разработчиков избегают использования портов завершения.
Синхронная модель ввода-вывода проста в реализации и использовании и, как показал опыт систем семейства Unix и его идейных наследников, вполне адекватна большинству приложений общего назначения. Однако, как уже было показано, она не очень удобна (а иногда и просто непригодна) для задач реального времени. Следует также иметь в виду, что имитация асинхронного обмена при помощи нитей не всегда допустима: асинхронные запросы исполняются в том порядке, в котором они устанавливались в очередь, а порядок получения управления нитями в многозадачной среде не гарантирован. Поэтому, например, стандарт POSIX.4 требует поддержки наравне с нитями и средств асинхронного обмена с вызовом callback при завершении операции.
Синхронный вводвывод
Синхронный ввод-вывод
Самым простым механизмом вызова функций драйвера был бы косвенный вызов соответствующих процедур, составляющих тело драйвера, подобно тому, как это делается в MS DOS и ряде других однозадачных систем.
В системах семейства Unix драйвер последовательного устройства исполняется в рамках той нити, которая сформировала запрос, хотя и с привилегиями ядра. Ожидая реакции устройства, драйвер переводит процесс в состояние ожидания доступными ему примитивами работы с планировщиком. В примере 10.1 это interruptibie_sieep_on. В качестве параметра этой функции передается блок переменных состояния устройства, и в этом блоке сохраняется ссылка на контекст блокируемой нити.
Доступные прикладным программам функции драйвера исполняются в пользовательском контексте — в том смысле, что, хотя драйвер и работает в адресном пространстве ядра, но при его работе определено и пользовательское адресное пространство, поэтому он может пользоваться примитивами
Обмена данными С НИМ (в примере 10.1 это memcpy_from_fs).
Обработчик прерывания наоборот работает в контексте прерывания, когда пользовательское адресное пространство не определено. Поэтому, чтобы при обслуживании прерывания можно было получить доступ к пользовательским данным, основная нить драйвера вынуждена копировать их в буфер в адресном пространстве ядра.
Синхронная модель драйвера очень проста в реализации, но имеет существенный недостаток, приведенный в примере 10.1, — драйвер нереентерабелен. Обращение двух нитей к одному устройству приведет к непредсказуемым последствиям (впрочем, для практических целей достаточно того, что среди возможных последствий числится нарушение целостности данных и последующая паника регистров на экране). Предсказуемость последствий обеспечивается включением в контекст устройства семафора, установкой этого семафора при входе в функцию foo_write и снятием его при выходе. Семафор имеет очередь ожидающих его процессов, и, таким образом, реентрантно (т. е. во время обработки предыдущего аналогичного запроса) приходящие запросы будут устанавливаться в очередь.
Альтернативный подход к организации ввода-вывода состоит в том, чтобы возложить работу по формированию очереди запросов не на драйвер, а на функцию предобработки запроса. При этом первый запрос к драйверу, какое-то время бывшему неактивным, может по-прежнему осуществляться в нити процесса, сформировавшего этот запрос, но все последующие запросы извлекаются из очереди fork-процессом драйвера при завершении предыдущего запроса. Такой подход называется асинхронным.
Примечание
Примечание
Здесь возникает интересный вопрос: если запрос обрабатывается асинхронно, то обязана ли пользовательская программа ожидать окончания операции? Вообще говоря, не обязана, но этот вопрос подробнее будет обсуждаться в разд. Асинхронная модель ввода-вывода с точки зрения приложений.
Спулинг
Спулинг
| Гигабайттебе в спул. Популярное ругательство |
Термин спулинг (spooling) не имеет общепринятого русского аналога. В соответствии с программистским фольклором, слово это происходит от аббревиатуры Simultaneous Peripherial Operation Off-Line. Эту фразу трудно дословно перевести на русский язык; имеется в виду метод работы с внешними устройствами вывода (реже — ввода) в многозадачной ОС или многомашинной среде, при котором задачам создается иллюзия одновременного доступа к устройству. При этом, однако, задачи не получают к устройству прямого доступа, а работают в режиме offline (без прямого подключения). Выводимые данные накапливаются системой, а затем выводятся на устройство так, чтобы вывод различных задач не смешивался.
Видно, что этот метод работы отчасти напоминает простую отложенную запись, но основная задача здесь не только и не столько повышение производительности, сколько разделение доступа к медленному внешнему устройству.
Чаще всего спулинг применяется для работы с печатающими устройствами, а для промежуточного хранения данных используется диск. Многие почтовые системы применяют механизм, аналогичный спулингу: если получатель не готов принять письмо, или линия связи с получателем занята, либо вообще разорвана, предназначенное к отправке письмо помещается в очередь. Затем, когда соединение будет установлено, письмо отправляется.
Классический спулинг реализован в ОС семейства Unix. В этих ОС вывод задания на печать осуществляется командой lpr. Эта команда копирует предназначенные для печати данные в каталог /usr/spoo!/lp, возможно, пропуская их при этом через программу-фильтр. Каждая порция данных помешается в отдельный файл. Имена файлов генерируются так, чтобы имя каждого вновь созданного файла было "больше" предыдущего при сравнении ASCII-колов. За счет этого файлы образуют очередь.
Системный процесс-демон (daemon) ipd (или lpshed в Unix System V) периодически просматривает каталог. Если там что-то появилось, а печатающее устройство свободно, демон копирует появившийся файл на устройство. По окончании копирования он удаляет файл, тем или иным способом уведомляет пользователя об окончании операции (в системах семейства Unix чаще всего используется электронная почта) и вновь просматривает каталог. Если там по-прежнему что-то есть, демон выбирает первый по порядку запрос и также копирует его на устройство.
Тот же механизм используется почтовой системой Unix- программой sendmail, только вместо каталога /usr/spool/lp используется /usr/spool/mail.
Этот механизм очень прост, но имеет один специфический недостаток: демон не может непосредственно ожидать появления файлов в каталоге, как можно было бы ожидать установки семафора или другого флага синхронизации. Если бы демон непрерывно сканировал каталог, это создавало бы слишком большую и бесполезную нагрузку системы. Поэтому демон пробуждается через фиксированные интервалы времени; если за это время ничего в очереди не появилось, демон засыпает вновь. Такой подход также очень прост, но увеличивает время прохождения запросов: запрос начинает исполняться не сразу же после установки, а лишь после того, как демон в очередной раз проснется.
В OS/2 и Win32 спулинг организован отчасти похожим образом с той разницей, что установка запроса в очередь может происходить не только командой PRINT, но и простым копированием данных на псевдоустройство LPT[1-9|. В отличие от систем семейства Unix как программа PRINT, так и псевдоустройства портов активизируют процесс спулинга непосредственно при установке запроса. Графические драйверы печатающих устройств в этих системах также используют спул вместо прямого обращения к физическому порту.
Novell Netware предоставляет специальный механизм для организации спулинга — очереди запросов. Элементы очереди в этом случае также хранятся на диске, но прикладные программы вместо просмотра каталога могут пользоваться системными функциями GetNextMessage и PutMessage. Вызов GetNextMessage блокируется, если очередь пуста; таким образом, нет необходимости ожидать пробуждения демона или специальным образом активизировать его — демон сам пробуждается при появлении запроса. Любопытно, что почтовая система Mercury Mail для Novell Netware может использовать для промежуточного хранения почты как очередь запросов, так и выделенный каталог в зависимости от конфигурации.
Стратегическая функция и очередь запросов
Рисунок 10.7. Стратегическая функция и очередь запросов

IRP содержит:
код операции (чтение, запись или код SPFUN— специальная функция, подобная ioctl в системах семейства Unix); адрес блока данных, которые должны быть записаны, или буфера, куда данные необходимо поместить; информацию, используемую при постобработке, в частности, идентификатор процесса, запросившего операцию.В зависимости от кода операции драйвер запускает соответствующую подпрограмму. В VAX/VMS адрес подпрограммы выбирается из таблицы FDT (Function Definition Table). Подпрограмма инициирует операцию и приостанавливает процесс, давая системе возможность исполнить другие активные процессы. Затем, когда происходит прерывание, его обработчик инициирует fork-процесс, исполняющий следующие этапы этого запроса. Завершив один запрос, fork-процесс сообщает об этом процедурам постобработки (разбудив соответствующий процесс) и, если в очереди еще что-то осталось, начинает исполнение следующего запроса.
В качестве параметра стратегическая функция получает указатель на структуру запроса, в которой содержатся код требуемой операции и блок данных. При этом возникает сложный вопрос, а именно — в каком адресном пространстве размещается этот блок?
На первый взгляд, идеальным решением было бы размещение этого блока сразу в пользовательском адресном пространстве. Проблема здесь в том, что стратегическая функция — особенно при обработке не первого запроса в очереди — исполняется не в пользовательском контексте, когда можно применять примитивы обмена данными с адресным пространством задачи,в контексте fork-процесса, а то и в контексте прерывания, когда адресное пространство пользователя не определено.
Возможны два варианта решения этой проблемы: хранить в структуре запроса иноке и указатель на пользовательское адресное пространство, либо все-таки копировать данные в адресное пространство системы на этапе предобработки, и обратно в пользовательское на этапе постобработки запроса. Драйвер в этом случае не должен беспокоиться ни о каком копировании, зато разработчик ОС получает дополнительную головную боль в виде логики управления буферами в адресном пространстве системы и выделения памяти для них.
Буферизация запросов и формирование очереди к блочным устройствам в Unix осуществляется специальным модулем системы, который называется дисковым кэшем. Принцип работы дискового кэша будет обсуждаться в разд. Дисковый кэш. Очереди запросов к потоковым устройствам имеют меньший объем, поэтому выделение памяти для них осуществляется обычным kmalloc.
Таблица переходов может рассматриваться
Таблица переходов может рассматриваться как матричное представление диаграммы переходов.
Блок-схемы (Рисунок 10.5) являются обычным способом визуализации графов переходов и используются для описания алгоритмов с 60-х годов. Любой алгоритм, исполняющийся на фон-неймановском компьютере с конечным объемом памяти (а также любой физически исполнимый алгоритм), может быть описан как конечный автомат и изображен в виде блок-схемы.
У конечных автоматов с ограниченным числом допустимых значений входов, граф переходов всегда конечен, хотя и может содержать циклы (замкнутые пути) и контуры (совокупности различных путей, приводящих к одной и той же вершине). Понятно, что для автомата с графом, содержащим циклы, невозможно гарантировать финитности — завершения работы за конечное время. Как известно, задача доказательства финитности алгоритма, хотя и решена во многих частных случаях, в общем случае алгоритмически неразрешима [Минский 1971].
Применительно к драйверам внешних устройств, циклический граф может соответствовать повторным попыткам выполнения операции после ее не-'удачи. Понятно, что на практике количество таких попыток следует ограничивать. Самый простой способ такого ограничения — введение счетчика попыток. Формально после этого состояния с различными значениями счетчика превращаются в наборы состояний, а граф переходов становится ациклическим (Рисунок 10.6), но для достаточно большого количества повторений опять-таки необозримым, поэтому на практике часто используют сокращенную блок-схему, в которой состояния с разными значениями счетчика цикла изображаются как одно состояние.
Таймеры
Таймеры
Ядро обычно предоставляет два типа таймеров — часы реального времени, указывающие астрономическое время (драйверу это время обычно интересно только для сбора статистики) и собственно таймеры — механизмы, позволяющие отмерять интервалы времени.
Таймеры интересны драйверам с нескольких точек зрения. Один из важных способов их использования приведен в примере 10.1: если устройство из-за какой-либо ошибки не сгенерирует прерывания, наивный драйвер может остаться в состоянии ожидания навсегда. Чтобы этого не происходило, драйвер должен устанавливать будильник, который' сообщит основному потоку, что устройство подозрительно долго не отвечает.
Таймеры используются также как альтернатива непрерывному опросу устройства при исполнении длительных операций, например сброса устройства, если использование прерываний почему-либо нежелательно или невозможно. Если говорить именно о-сбросе, автору не известно ни одного устройства, которое генерировало бы прерывание при завершении этой операции.
ТЕХ рассматривают входные и выходные
ТЕХ рассматривают входные и выходные файлы как потоки данных. Входные файлы прочитываются строго последовательно и полностью, от начала до конца. Аналогично, выходные файлы полностью перезаписываются, и перезапись тоже происходит строго последовательно. Попытка выделить аналог рабочей области при таком характере обращений обречена на провал независимо от алгоритма, разве что рабочей областью будут считаться все входные и выходные файлы.
Тем не менее кэширование или, точнее, буферизация данных при работе с диском имеет смысл и во многих случаях может приводить к значительному повышению производительности системы. Если отсортировать механизмы повышения производительности в порядке их важности, мы получим следующий список. 1. Размещение в памяти структур файловой системы — каталогов, FAT пли таблицы инодов (эти понятия подробнее обсуждаются в главе И) и т. д. Это основной источник повышения производительности при использовании дисковых кэшей под MS/DR DOS. 2. Отложенная запись. Само по себе откладывание записи не повышает скорости обмена с диском, но позволяет более равномерно распределить по времени загрузку дискового контроллера. 3 Группировка запросов на запись. Система имеет пул буферов отложенной записи, который и называется дисковым кэшем. При поступлении запроса на запись, система выделяет буфер из этого пула и ставит его в очередь к драйверу. Если за время нахождения буфера в очереди в то же место на диске будет произведена еще одна запись, система может дописать данные в имеющийся буфер вместо установки в очередь второго запроса. Это значительно повышает скорость, если запись происходит массивами, не кратными размеру физического блока на диске. 4 Собственно кэширование. После того, как драйвер выполнил запрос, буфер не сразу используется повторно, поэтому какое-то время он содержит копию записанных или прочитанных данных. Если за это время произойдет обращение на чтение соответствующей области диска, система может отдать содержимое буфера вместо физического чтения. 5. Опережающее считывание. При последовательном обращении к данным чтение из какого-либо блока значительно повышает вероятность того, что следующий блок также будет считан. Теоретически опережающее чтение должно иметь тот же эффект, что и отложенная запись, т. е. обеспечивать более равномерную загрузку дискового канала и его работу параллельно с центральным процессором. На практике, однако, часто оказывается, что считанный с опережением блок оказывается никому не нужен, поэтому эффективность такого чтения заметно ниже, чем у отложенной записи. 6. Сортировка запросов по номеру блока на диске. По идее, такая сортировка должна приводить к уменьшению времени позиционирования головок чтения/записи (см. разд. Производительность жестких дисков). Кроме того, если очередь запросов будет отсортирована, это облегчит работу алгоритмам кэширования, которые производят поиск буферов по номеру блока.
Кэширование значительно повышает производительность дисковой подсистемы, но создает ряд проблем, причем некоторые из них довольно неприятного свойства.
Первая из проблем — та же, что и у отложенной записи. При использовании отложенной записи программа не знает, успешно ли завершилась физическая запись. При работе с дисками один из основных источников ошибок — физические ошибки диска. Однако многие современные файловые системы поддерживают так называемый hotfixing (горячую починку) — механизм, обеспечивающий динамическую замену "плохих" логических блоков на "хорошие", что в значительной мере компенсирует эту проблему.
Вторая проблема гораздо серьезнее и тоже свойственна всем механизмам отложенной записи: если в промежутке между запросом и физической записью произойдет сбой всей системы, то данные будут потеряны. Например, пользователь сохраняет отредактированный файл и. не дождавшись окончания физической записи, выключает питание — содержимое файла оказывается потеряно или повреждено. Другая ситуация, до боли знакомая всем пользователям DOS/Windows З.х/Windows 95: пользователь сохраняет файт и в это время система зависает — результат тот же. Аналогичного результата можно достичь, не вовремя достав дискету или другой удаляемый носите-ц, из привода (чтобы избежать этого, механика многих современных дисководов позволяет программно заблокировать носитель в приводе).
Очень забавно наблюдать, как пользователь, хотя бы раз имевший неприятный опыт общения с дисковым кэшем SMARTDRV, копирует данные с чужого компьютера на дискету. Перед тем, как извлечь ее из дисковода, он оглядывается на хозяина машины и с опаской спрашивает: "У тебя там никаких кэшей нет?". В эпоху MS DOS авторам доводилось наблюдать такое поведение у нескольких десятков людей.
Если откладывается запись не только пользовательских данных, но и модифицированных структур файловой системы, ситуация еще хуже: системный сбой может привести не только к потере данных, находившихся в кэше, но и к разрушению файловой системы, т. е. в худшем случае, к потере всех данных на диске.
Методы обеспечения целостности данных при системном сбое подробнее обсуждаются в разд. Устойчивость ФС к сбоям. Находившиеся в кэше данные при фатальном сбое гибнут всегда, но существуют способы избежать.повреждения системных структур данных на диске без отказа от использования отложенной записи.
Третья проблема, связанная с дисковым кэшем, — это выделение памяти под него. Уменьшение кэша приводит к снижению производительности дисковой подсистемы, увеличение же кэша отнимает память у пользовательских процессов. В системах с виртуальной памятью это может привести к увеличению дисковой активности за счет увеличения объема подкачки, что ведет к снижению как дисковой, так и общей производительности системы. Перед администратором системы встает нетривиальная задача: найти точку оптимума. Положение этой точки зависит от следующих параметров:
При этом зависимость количества страничных отказов от объема памяти, доступной приложениям, имеет существенно нелинейный вид. Это же утверждение справедливо для связи между размером дискового кэша и соответствующей экономией обращений к диску. Таким образом, задача подбора оптимального размера кэша — это задача нелинейной оптимизации. Самое неприятное, что ключевой исходный параметр — характер обращений к диску — не количественный, а качественный; точнее сказать, его можно измерить лишь при помощи очень большого числа независимых количественных параметров.
Во многих ситуациях невозможно теоретически оценить положение оптимальной точки, и единственным способом оказывается эксперимент: прогон типичной для данной машины смеси заданий при различных объемах кэша. При этом нужно иметь возможность различать дисковую активность, связанную с обращениями к файлам и со страничным обменом. Большинство современных ОС предоставляют для этой цели различные инструменты системного мониторинга. Чаше, однако, объем кэша выставляется на глаз, а к дополнительной настройке прибегают, только если производительность оказывается слишком низкой.
Возникает вполне естественное желание возложить подбор размера кэша на саму систему, т. е. менять размер кэша динамически в зависимости от рабочей нагрузки. Кроме упрощения работы администратора, такое решение имеет еще одно большое преимущество: система начинает "автомагически" подстраиваться под изменения нагрузки.
Но далеко не все так просто. Если объем памяти в системе превосходит потребности прикладных программ, то динамический дисковый кэш может формироваться по очень простому "остаточному" принципу — все, что не пригодилось приложениям, отдается под кэш. Однако оперативная память до сих пор относительно дорога и представляет собой дефицитный ресурс, поэтому наибольший практический интерес представляет ситуация, когда памяти не хватает даже приложениям, не говоря уже о кэше. Тем не менее и в этой ситуации кэш некоторого объема бывает нужен.
Разумной политикой была бы подстройка кэша в зависимости от количества страничных отказов: если число отказов становится слишком большим, система уменьшает кэш; если же число отказов мало, а идут интенсивные обращения к диску, система увеличивает кэш. Получается саморегулирующаяся система с отрицательной обратной связью. Однако, если вдуматься, то видно, что вместо одной произвольной переменной (объема статического кэша) мы вынуждены ввести как минимум три:
На практике, часто также вводятся параметры, ограничивающие минимальный и максимальный размеры кэша.
Оптимальные значения этих переменных зависят практически от тех же самых параметров, что и объем статического кэша, но подбор значений экспериментальным путем оказывается значительно сложнее, потому что вместо одномерной нелинейной оптимизации мы вынуждены занимать трехмерной нелинейной оптимизацией.
Кроме того, читатель, знакомый с теорией управления, должен знать чт неудачный подбор параметров у системы с отрицательной обратной связь может приводить к колебательному процессу вместо саморегуляции, в дм куссиях USENET news приводились примеры развития таких колебаний динамическом кэше системы Windows NT при компиляции большого проекта в условиях недостатка памяти.
Вполне возможно, что низкая производительность Windows NT/2000/XP на машинах с небольшим количеством памяти объясняется вовсе не низким качеством реализации и даже не секретным сговором между фирмой Microsoft и производителями оперативной памяти, а просто плохо сбалансированным динамическим кэшем.
Терминальный интерфейс в Unix
Терминальный интерфейс в Unix
На практике иногда — особенно при использовании многоуровневых драйверов — оказывается возможным перенести отдельные функции работы с устройствами в контекст пользовательского процесса. Одна из относительно удачных попыток такого переноса была осуществлена в 70-е годы при разработке экранного редактора vi, для ОС Unix (которая тогда еще была единственным представителем того, что потом превратилось в весьма обширное семейство ОС).
По замыслу разработчиков этот редактор должен был работать с большим количеством разных видеотерминалов, использовавших различные несовместимые системы команд для перемещения курсора и редактирования текста в буфере терминала и столь же несовместимые схемы кодирования специальных клавиш (стрелочек, функциональных клавиш и пр.). Как и в примере с мышами, разные терминалы могли подключаться к компьютеру через различные типы последовательных портов: "токовую петлю", позднее — RS232 и др.
Как в обсуждавшемся в разд. Многоуровневые драйверы примере с мышами, в этом случае тоже было естественно разделить драйвер терминала на драйвер порта и модуль, занимающийся генерацией команд и анализом приходящих от терминала кодов расширенных клавиш. Вместо разработки отдельного модуля, решающего вторую часть задачи, была создана системная база данных для систем команд разных терминалов. Эта база данных представляет собой текстовый файл с именем /etc/termcap (terminal capabilities — возможности терминала).
Файл /etc/termcap состоит из абзацев. Заголовок абзаца представляет собой имя терминала, а текст состоит из фраз вида Name=value, разделенных символом ':'. Name представляет собой символическое имя того или иного свойства, a value— его значение. Чаще всего это последовательность символов, формирующих соответствующую команду, или генерируемых терминалом при нажатии соответствующей клавиши. Кроме того, это может быть, например, ширина экрана терминала, измеренная в символах.
Для работы с терминальной базой данных позднее было создано несколько библиотек подпрограмм — низкоуровневая библиотека termcap и высокоуровневый пакет curses.
Для терминалов описанный подход оказался если и не идеальным, то, во всяком случае, приемлемым. Но, например, для графических устройств он не подошел — системы команд различных устройств оказались слишком непохожими и не сводимыми к единой системе "свойств".
Первым приближением к решению этой проблемы стало создание слециали рованных программ-фильтров. При использовании фильтров пользовательская программа генерирует графический вывод в виде последовательности команд некоторого языка. Фильтр принимает эти команды, синтезирует на их основе изображение и выводит его на графическое устройство. Вся поддержка различных устройств вывода возлагается на фильтр, пользовательская програма должна лишь знать его входной язык.
Самым удачным вариантом языка графического вывода в наше время считавется PostScript—язык управления интеллектуальными принтерами, разработанный фирмой Adobe. PostScript предоставляет богатый набор графических примитивов, но основное его преимущество состоит в том, что это полнофункциональный язык программирования с условными операторами циклами и подпрограммами.
Первоначально этот язык использовался только для управления дорогими моделями лазерных принтеров, но потом появились интерпретаторы этого языка способные выводить PostScript на более простые устройства. Наиболее известной программой этого типа является GhostScript— программа, реализованная в рамках проекта GNU и доступная как freeware. GhostScript поставляется в виде исходных текстов на языке С, способна работать во многих операционных системах; практически во всех ОС семейства Unix, OS/2, MS/OR DOS и т. д. и поддерживает практически все популярные модели графических устройств, принтеров, плоттеров и прочего оборудования.
Аналогичный подход используется в оконной системе X Window. В этой системе весь вывод на терминал осуществляется специальной программой-сервером. На сервер возлагается задача поддержки различных графических устройств. В большинстве реализаций сервер исполняется как обычная пользовательская программа, осуществляя доступ к устройству при помощи функций ioctl "установить видеорежим" и "отобразить видеопамять в адресное пространство процесса".
В обоих случаях "драйвер" оказывается разбит на две части: собственно драйвер, исполняющийся в режиме ядра, который'занимается только обменом данными с устройством, и программу, интерпретирующую полученные данные и/или формирующую команды для устройства. Эта программа может быть довольно сложной, но ошибка в ней не будет фатальной для системы, так как она исполняется в пользовательском кольце доступа. Проше всего происходит загрузка драйверов в системах, в которых ядро собирается в статический загрузочный модуль. В них драйвер просто присоединяется редактором связей к образу ядра и без каких-либо дополнительных усилии оказывается в памяти в процессе загрузки системы.
В системах с динамической подгрузкой модулей ядра, драйвер представляет собой перемещаемый загрузочный или объектный модуль, иногда того же формата, что и стандартные объектные или загрузочные модули в системе, а иногда и специализированного. В этом случае ядро должно содержать редактор связей, возможно являющийся функциональным подмножеством полноценного системного линкера.
Связывание кода драйвера с используемыми им функциями ядра обычно производится редактором связей в момент подключения модуля к образу ядра при статической сборке и в момент подгрузки модуля при сборке лирической. Однако связывание кода ядра с функциями драйвера, как правило, производится иным образом. Дело в том, что к ядру может подключаться переменное и, в большинстве систем, практически неограниченное количество драйверов. В этом случае обычно оказывается более удобным поддерживать таблицу точек входа зарегистрированных в системе драйверов.
Два основных подхода к формированию такой таблицы — это использование таблицы точек входа в качестве обязательного элемента формата драйвера, либо регистрация точек входа в системной таблице функциями инициализации драйвера.
Введение в конечные автоматы
Введение в конечные автоматы
Конечный автомат (в современной англоязычной литературе используется также более выразительное, на взгляд автора, обозначение, не имеющее хорошего русского эквивалента — state machine, дословно переводимое как машина состояний) представляет собой устройство, имеющее внутреннюю память (переменные состояния), а также набор входов и выходов. Объем внутренней памяти у конечных автоматов, как следует из названия, конечен. Автоматы с неограниченным объемом внутренней памяти называются бесконечными автоматами, нереализуемы и используются только в теоретических Построениях (Минский 1971].
Однако некоторые разновидности теоретически бесконечных автоматов — например, стековые — могут быть реализованы в форме автоматов с практически неограниченной памятью — например, достаточно глубоким стеком — и находят практическое применение, например при синтаксическом анализе языков со вложенными структурами [Кормен/Лейзерсон/Ривест 2000].
Работа автомата состоит в том, что он анализирует состояния своих входов, и, в зависимости от значений входов и своего внутреннего состояния, изменяет значения выходов и внутреннее состояние. Правила, в со ответствии с которыми происходит изменение, описываются таблицей или диаграммой переходов. Диаграмма переходов представляет собой граф, вершины которого соответствуют допустимым состояниям внутренних переменных автомата, а ребра — допустимым переходам между ними. Переходы между вершинами направленные: наличие перехода из А в В не означает, что существует переход из В в А. Наличие перехода в обоих направлениях символизируется двумя ребрами, соединяющими одну пару вершин. Такой граф называется ориентированным [Кормен/Лейзерсон/Ривест 2000].
Выделение памяти
Выделение памяти
Алгоритмы выделения памяти, в том числе и пригодные для использования в ядре ОС, подробно обсуждались в главе 4. Кроме того, мы уже упомянули тот печальный факт, что в контексте прерывания система обычно не позволяет запрашивать ресурсы. Важно остановиться еще на двух аспектах проблемы.
go-первых, ядро ОС обычно размешается в физической памяти и не подвергается страничному обмену, поэтому память ядра представляет собой более дефицитный ресурс, чем виртуальная память, доступная прикладным программам. Разработчик модуля ядра должен иметь это в виду и не прибегать к экстравагантным схемам управления буферами, которые иногда применяются в прикладных программах. Управлению большими объемами буферов, в частности дисковым кэшем, в книге посвящен разд. Дисковый кэш.
Во-вторых, в ряде случаев, драйвер не может удовлетвориться любым участком физического ОЗУ: например, некоторые старые контроллеры ПДП или периферийной шины не могут адресовать всю физическую память. Так, контроллер ПДП шины ISA имеет 24-разрядный адрес и способен, таким образом, адресовать только младшие 16 Мбайт ОЗУ (Рисунок 10.8). Некоторые контроллеры ПДП требуют выравнивания буфера, чаще всего на границу страницы.
Взаимодействие между DMD и ADD
Рисунок 10.4. Взаимодействие между DMD и ADD в OS/2 (в качестве примера драйвера файловой системы приведен модуль JFS.IFS)

В данном случае, запросы предыдущих трех драйверов исполняет четвертый DMD: OS2SCSI.DMD. Этот DMD преобразует запросы к устройствам в команды SCSI и передает эти команды драйверу ADD (Adapter Device Driver — драйверу устройства-адаптера), т. е. собственно драйверу НВА. От ADD требуется только умение передавать команды на шину SCSI, обрабатывать и осуществлять диспетчеризацию пришедших на них ответов, т. е. он функционально аналогичен драйверу НВА в системах семейства Unix.
Пятый DMD— OS2ASPI.DMD— обеспечивает сервис ASPI (Advanced SCSI Programming Interface — продвинутый интерфейс для программирования SCSI). Он дает возможность прикладным программам и другим драйверам формировать произвольные команды SCSI и таким образом осуществлять доступ к устройствам, которые не являются дисками. Сервисом ASPI пользуются драйверы лентопротяжки и сканера
Загрузка драйверов
Загрузка драйверов
Чаще всего драйверы размещаются в адресном пространстве ядра системы, исполняются в высшем кольце защиты и имеют доступ для записи к сегментам данных пользовательских программ, и, как правило, к данным самого ядра. Это означает, что ошибка в драйвере может привести к разру-пользовательских программ и самой ОС.
атобы избежать этого, пришлось бы выделять каждому драйверу свое адресов пространство и обеспечивать обмен данными между драйвером, ядром и пользовательской программой посредством статических разделяемых буферов или динамического отображения блоков данных между разными адресными пространствами. Оба решения приводят к значительным накладным оасходам, а второе еще и предъявляет своеобразные требования к архитектуре диспетчера памяти (подробнее эта проблема обсуждалась в разд. Взаимно-недоверяющие подсистемы).
Запросы к драйверу
Запросы к драйверу
Обработку запроса можно разделить на три фазы: предобработку, исполнение запроса и постобработку. Пользовательская программа запрашивает операцию, исполняя соответствующий системный вызов. В ОС семейства Unix это может быть, например, системный вызов write (int file, void * buffer, size_t size) .
Предобработка выполняется модулем системы, который, как правило, исполняется в нити процесса, сформировавшей запрос, но имеет привилегии ядра. Фаза предобработки включает в себя.
Выполнив запрос, драйвер активизирует программу постобработки, котопя анализирует результат операции, предпринимает те или иные действия по восстановлению в случае неудачи, копирует или отображает полученные данные в пользовательское адресное пространство и оповещает пользовательский процесс о завершении запроса.
Некоторые системы на этой фазе также ыыпроизводят преобразование введенных данных. В качестве примера можно вновь привести системы семейства Unix, которые при вводе с терминала выполняют трансляцию символа перевода строки и ряд других операций редактирования, например, стирание последнего введенного символа по запросу пользователя. Разбиение потока терминальных данных на строки в этих системах также происходит на фазе постобработки.
В той или иной форме эти три фазы обработки запроса ввода-вывода присутствуют во всех многопоточных и даже многих однопоточных системах.
Запросы к драйверу в VMS
Запросы к драйверу в VMS
В операционной системе VAX/VMS драйвер получает запросы на ввод-вывод из очереди запросов. Элемент очереди называется IRP (lnput[Output] Request Packet — пакет запроса ввода-вывода). Обработав первый запрос в очереди, драйвер начинает обработку следующего. Операции над очередью запросов выполняются специальными командами процессора VAX и являются атомарными. Если очередь пуста, основная нить драйвера завершается. При появлении новых запросов система вновь запустит ее.
