А С Деревянко М Н Солощук
А.С.Деревянко, М.Н.Солощук
А В резерве ОС остаются таким
Рисунок 5.3.а. В резерве ОС остаются, таким образом, 2 ресурса. Ситуация Рисунок 5.3.а является безопасной. ОС может выделить оставшиеся два ресурса процессу P2, и этот процесс, полностью получив по своей заявке, может завершится, тогда системный резерв увеличится до 4 ресурсов. Этот резерв ОС отдаст процессу P3, он, завершившись, передаст в резерв ОС 8 ресурсов, которых будет достаточно для удовлетворения заявки процесса P1. Ситуация станет опасной, если ОС выделит ресурс какому-либо другому процессу, кроме P2 - см.Рисунок 5.3.б. В этой ситуации ОС за счет своего резерва не может полностью удовлетворить ни одну заявку.
Алгоритм Деккера
Алгоритм Деккера
Эффективное и универсальное решение проблемы взаимного исключения носит название алгоритма Деккера и выглядит для двух процессов таким образом: 1 static int right = 0; 2 static char wish[2] = { 0,0 }; 3 void csBegin ( int proc ) { 4 int competitor; 5 competitor = other ( proc ); 6 while (1) { 7 wish[proc] = 1; 8 do { 9 if ( ! wish[competitor] ) return; 10 } 11 while ( right != competitor ); 12 wish[proc] = 0; 13 while ( right == competitor ); 14 } 15 } 16 void csEnd ( int proc ) { 17 right = other ( proc ); 18 wish[proc] = 0; 19 }
Алгоритм предусматривает, во-первых, общую переменную right для представления номера процесса, который имеет преимущественное (но не абсолютное) право на вход в критическую секцию. Во-вторых, массив wish, каждый элемент которого соответствует одному из процессов и представляет "желание" процесса войти в критическую секцию. Процесс заявляет о своем "желании" войти в секцию (строка 7). Если при этом выясняется, что процесс-конкурент не выставил своего "желания" (строка 9), то происходит возврат из функции, то есть, процесс входит в критическую секцию независимо от того, кому принадлежало преимущественное право на вход. Если же в строке 9 выясняется, что конкурент тоже выставил "желание", то проверяется право на вход (строка 10). Если право принадлежит нашему процессу, то повторяется проверка "желания" конкурента (строки 8 - 10), пока оно не будет отменено. Конкурент вынужден будет отменить свое "желание", потому что он в этой ситуации перейдет к строке 11, где процесс, не имеющий преимущественного права, должен это сделать. После отмены своего желания процесс ждет, пока преимущественное право не вернется к нему (строка 12), а затем вновь повторяет заявление "желания" и т.д. (строки 6 - 13). Таким образом, процесс в функции csBegin либо повторяет цикл 7 - 14, либо выходит из функции и входит в критическую секцию (10).
При выходе из критической секции (функция csEnd) процесс передает преимущественное право входа конкуренту (строка 16) и отказывается от своего желания (строка 17).
По собственному опыту признаем, что понимание этого алгоритма дается не очень просто. Рекомендуем для лучшего его понимания записать в две колонки две копии функции csBegin, соответствующие двум процессам, и промоделировать ход их параллельного выполнения с разными скоростями и разными сдвигами в фазах выполнения между процессами.
Приведем также обобщение алгоритма Деккера на N процессов: 1 static char wish[N+1] = { 0, ..., 0 }; 2 static char claimant[N+1] = { 0, ..., 0 }; 3 static int right = N; 4 void csBegin ( int proc ) { 5 int i; 6 clainmant[proc] = 1; 7 do { 8 while ( right != proc) { 9 wish[proc] = 0; 10 if(!clainmant[right]) right=proc; 11 } 12 wish[proc] = 1; 13 for (i = 0; i<N; i++ ) 14 if ((i!=proc) && wish[i]) break; 15 } 16 while (i<N); 17 } 18 void csEnd ( int proc ) { 19 right = N; 20 wish[proc] = clainmant[proc] = 0; 21 }
Ограничимся здесь только общими замечаниями к этому алгоритму. Процессы нумеруются от 0 до N-1. Мы вводим два массива для переменных состояния, размеры массивов на 1 больше числа процессов. Последние элементы каждого из массивов соответствуют несуществующему N-му процессу, который используется как абстрактный "другой" процесс. Понятие "конкурент" здесь заменяется понятием "претендент" (clainmant). Процесс становится претендентом, входя в функцию csBegin (строка 6). В отличие от "желания", "претензия" процесса не снимается до тех пор, пока она не будет удовлетворена (строка 18). Если преимущественное право на вход в критическую секцию принадлежит другому процессу, но этот другой процесс не является претендентом, то наш процесс забирает это право себе (строки 7 - 11). При выполнении этих действий наш процесс, однако, отказывается от своего "желания", давая тем самым возможность участвовать в состязании за захват секции другим процессам (строка 9). Получив право, процесс заявляет о своем "желании" (строка 12). В последующем цикле for проверяются "желания" других процессов (строки 13 - 14). Если есть другие "желающие" то повторяется получение права и т.д. (строки 7 - 15). Если же в цикле for другие желающие не выявлены (строка 15), наш процесс входит в критическую секцию. При выходе из секции процесс сбрасывает свои "претензию" и "желание" (строка 18) и передает право несуществующему N-му процессу (строка 19).
Алгоритм Габермана Другая алгоритмическая
Рисунок 5.3.а. (Убедитесь сами, что на конечное состояние массива S не влияет последовательность, в которой ресурсы выделялись.) Три нижние строки, в которых идентификатору процесса предшествует символ '*', показывают состояние массива S для альтернативных вариантов - выделения еще одного ресурс процессу P1 или P2, или P3. Видно, что только процесс P2 может получать ресурсы, не переводя систему в опасное состояние.
Алгоритм Питерсона
Алгоритм Питерсона
Более компактная и изящная модификация алгоритма Деккера известна, как алгоритм Питерсона. Вот его вариант для двух процессов: 1 static int right; 2 static char wish[2] = { 0,0 }; 3 void csBegin ( int proc ) { 4 int competitor; 5 if ( proc == 0 ) competitor = 1; 6 else competitor = 0; 7 wish[proc] = 1; 8 right = competitor; 9 while ( wish[competitor] && ( right == competitor ); 10 } 11 void csEnd ( int proc ) { 12 wish[proc] = 0; 13 }
При входе в критическую секцию процесс заявляет о своем "желании" (строка 7) и отказывается от своего преимущественного права (строка 8). Процесс будет ожидать, если его конкурент заявил свое "желание" и имеет преимущественное право (строка 9). Если нет интереса конкурента или если независимо от интереса конкурента наш процесс имеет преимущественное право, то наш процесс входит в критическую секцию. Если наш процесс отказался от своего права в строке 8, то как же это право может к нему вернуться? Право нашего процесса может быть восстановлено конкурентом, когда последний тоже войдет в функцию csBegin своего кода и выполнит строку 8. При выходе из критической секции процесс просто снимает свой интерес, и тогда его конкурент, возможно, ожидающий в строке 8, получает возможность выхода из цикла строки 9 по первой части условия.
Общие положительные свойства алгоритмов, основывающихся на неальтернативных переключателях (Деккера и Питерсона), следующие: они корректны как для одно-, так и для многопроцессорных систем; они либеральны, так как позволяют более быстрым процессам входить в свои критические секции чаще, чем медленным; они не ограничивают количество обслуживаемых ими процессов; они позволяют процессам сколь угодно долго задерживаться вне своей критической секции.
Но: решения непросты для понимания и ошибиться в их реализации очень легко; процессы используют занятое ожидание при входе в критическую секцию.
Альтернативное имя для файла
Рисунок 7.3. Альтернативное имя для файла
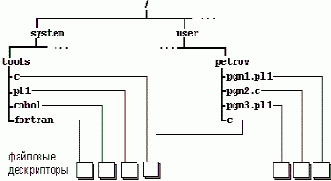
Косвенным файлом (indirect file) или символьной связью (symbolic link), или мягкой связью (soft link) называется элемент каталога, который ссылается на другой элемент каталога. Ссылка производится обычно путем указания полного символьного имени каталога. Физически символьные связи представляются файлами специального типа, содержащими ссылки. Так, в приведенном выше примере элемент каталога /users/petrov/c может содержать адрес дескриптора файла со ссылкой "/system/tools/c". Такой косвенный файл показан на Рисунке 7.3.б. При обращении к файлу по имени "/users/petrov/c" ФС в процессе поиска, дойдя до этого места, продолжит поиск по пути, который указан в ссылке. Нетрудно обеспечить и многоуровневые символьные связи. Подобно косвенным файлам, могут быть и косвенные каталоги. Принципиальное отличие косвенных файлов от алиасов - в том, что имена косвенных файлов имеют неравные права с основным именем. Только один элемент каталога (основной) ссылается на физический файл, остальные же - на элемент каталога. Поэтому удаление физического файла возможно только по основному имени, удаления же по косвенным именам удаляют только элементы каталогов. Если файл удален по основному имени, то косвенные ссылки на него, как правило, остаются в каталогах и обращения по косвенным именам приведут к ошибкам. Задача чистки каталогов от неактуальных косвенных имен может возлагаться либо на пользователей - владельцев каталогов, либо на администратора системы, в распоряжении которого должны быть соответствующие утилиты.
Раздельное хранение каталогов и дескрипторов предоставляет, как мы показали, дополнительные возможности, но и создает почву для возникновения дополнительных ошибок - "беспризорных" файлов, то есть файлов, на которые нет ссылок ни в каком каталоге. В распоряжении системного администратора должны быть утилиты, позволяющие исправлять такие ошибки (как, например, fsck и fsdb в Unix).
Внешняя память вычислительной системы может состоять из нескольких томов, каждый из которых имеет свой каталог. Если компьютер работает в составе сети, то в его пространство внешней памяти могут также включаться тома, расположенные в других узлах сети. В персональных системах пользователь при начале работы автоматически получает доступ ко всем наличным томам. В многопользовательской системе пользователю предоставляется только один определенный том (или несколько томов), а остальные должны быть подключены (mount - монтированы) пользователем явным образом. При работе с несколькими томами структура хранения информации может представлять собой "лес" или "дерево". В первом случае каждый том представляется, как отдельное дерево каталогов и полное имя файла включает в себя имя тома (OS/2, Windows, CMS). Во втором случае новый том подключается к основному и выглядит, как ветвь в общем дереве каталогов (Unix, OS/400). Если каталоги всех томов имеют одинаковую логическую структуру (а стандартной является структура иерархическая), то в одно дерево могут быть объединены даже тома, имеющие различную физическую структуру. С логической точки зрения нет разницы в том, находится ли монтируемый том на этом же компьютере или в другом узле сети. Кроме того, операция монтирования может быть реализована таким образом, чтобы давать пользователю доступ не ко всему тому (к корневому каталогу), а только к одной его ветви его дерева каталогов.
Аппаратная архитектура и поддержка ОС
1.4. Аппаратная архитектура и поддержка ОС
Существует несколько различных определений того, что следует считать аппаратной архитектурой ЭВМ, каждое из таких определений "работает" для определенного класса задач. Мы, как программисты, воспользуемся таким определением:
Аппаратной архитектурой называются те компоненты вычислительной системы, через которые программное обеспечение взаимодействует с аппаратурой.
Таким образом, в аппаратную архитектуру попадают не все компоненты компьютера, а только программно доступные - те, состоянием и действием которых программа может управлять или с которых программа может считать информацию. В состав этих средств входят: система команд процессора; регистры процессора; память; система ввода-вывода; система прерываний.
Аппаратную поддержку управления памятью и вводом-выводом мы рассматриваем отдельно (в главах 3 и 6 соответственно).
Система команд процессора - обеспечивает выполнение программой действий по обработке данных. Большинство команд в системе команд процессора имеет прикладное назначение, однако в некоторые команды из набора команд процессора предназначены для организации управления вычислительным процессом и, таким образом, непосредственно поддерживают функционирование ОС. Такие команды в современных системах являются привилегированными - это, например, команды ввода-вывода и изменения состояния системы. Современные ОС рассчитаны на наличие в вычислительной системе двух (как минимум) режимов функционирования процессора - привилегированного режима (режим ядра в терминологии Unix) и непривилегированного режима (режим процесса в Unix). Если программа, выполняющаяся в режиме ядра, может выполнять любые команды, то для программы, выполняющейся в режиме процесса, привилегированные команды запрещены. Попытка программы выполнить привилегированную команду в режиме процесса вызывает исключение (см. ниже). В системе ESA, например, таких основных состояний два (есть еще ряд промежуточных) [26], они называются "супервизор" и "задача", такие же названия они имеют в процессоре Power PC. В процессорах Intel-Pentium аналогичную роль играют уровни привилегий, они же - кольца защиты [23], причем из четырех аппаратно обеспечиваемых уровней привилегий в современных ОС используются два или три. Возможность для пользователя разрабатывать модули, работающие в режиме ядра, обычно строго регламентируется ОС. Хорошо защищенная ОС должна безоговорочно пресекать попытки процесса перейти в состояние ядра.
В число регистров процессора входят регистры общего назначения, которые в основном используются для манипулирования с прикладными данными, но также и специальные регистры, такие как регистр адреса команды, регистр флагов-признаков, регистр режима процессора и т.п. Содержимое регистра режима процессора определяет привилегированное или непривилегированное состояние процессора, команды, изменяющие содержимое этого регистра, обязательно являются привилегированными. В различных архитектурах специальные регистры могут либо представлять собой отдельные аппаратные компоненты, либо интегрироваться в более сложные аппаратные структуры.
Содержимое специальных аппаратных регистров процессора (обязательно включая регистр адреса команды) составляет вектор состояния программы/процесса. В большинстве процессорных архитектур вектор состояния может быть загружен в соответствующие регистры или считан из них в память одной или несколькими командами. Так, в процессорах Intel-Pentium имеется структура данных, называемая TSS (Task State Segment - сегмент состояния задачи), содержимое которой играет роль вектора состояния. При выполнении команд JMP или CALL, адресующих дескриптор TSS, процессор среди прочих действий сохраняет содержимое регистров в TSS текущей задачи и загружает регистры из TSS новой задачи [23]. В процессоре S/390 [26] имеется 8-байтная структура PSW (Program Status Word - слово состояния программы), содержащая значительную часть информации вектора состояния (кроме содержимого регистров общего назначения), и имеются две команды - LPSW и SPSW для загрузки и запоминания PSW соответственно.
Прерывание состоит в прекращении выполнения текущей программы и передаче управления на другую программу - программу обработки прерывания. При этом сохраняется возможность возврата в прерванную программу, в ту точку, в которой ее выполнение было прервано. При всем разнообразии аппаратных архитектур выполнение прерывания в них происходит примерно по одному сценарию: сохраняется вектор состояния прерванной программе (в стеке или в специально предназначенной для этого области оперативной памяти); в регистры процессора загружается некоторый вектор состояния, заранее "заготовленный"; в "заготовленном" векторе состояния регистр адреса команды содержит адрес программы обработки прерывания, таким образом, управление передается на программу обработки прерывания как правило, программа обработки прерывания сохраняет содержимое регистров общего назначения, а затем выполняет действия, предусмотренные для данного прерывания; после выполнения своих действий программа обработки прерывания восстанавливает содержимое регистров общего назначения прерванной программы, а затем восстанавливает ее запомненный ранее вектор состояния; прерванная программа продолжает свое выполнение с точки прерывания, даже "не заметив", что было принято и обработано прерывание.
Различаются прерывания трех типов: внешние, программные и исключения.
Внешние прерывания поступают от источников внешних по отношению к процессору. Такими источниками являются внешние устройства, другие процессоры и т.д. При помощи такого прерывания внешний источник сигнализирует о каком-либо изменении своего состояния, требующем реакции системы. Внешние прерывания являются важнейшим компонентом управления вводом-выводом. Внешнее прерывание является асинхронными, то есть, оно поступает в непредсказуемые моменты и невозможно предугадать, какой участок программного кода будет прерван внешним прерыванием. Команды процессора обладают свойством атомарности в отношении внешних прерываний: внешнее прерывание не может быть принято, пока не закончится выполнение текущей команды. При сохранении вектора состояния в нем запоминается адрес той команды, которая должна выполняться после той команды, во время выполнения которой произошло внешнее прерывание.
Программное прерывание вызывается специальной командой процессора (в Intel-Pentium мнемоника этой команды - INT, в ESA и Power PC - SVC). Выполняется программное прерывание так же, как и внешнее, но, в отличие от внешних, программные прерывания являются синхронными, так как они вызываются самой программой. Программные прерывания являются средством обращения процесса к ОС, механизмом системного вызова. Обычные команды передачи управления - типа команд CALL или JMP изменяют регистр адреса команды, но не весь вектор состояния. Прерывание же позволяет изменить весь вектор состояния, то есть, не только передать управление на другую программу, но и перевести процессор из непривилегированного режима в привилегированный.
Прерывания, называемые исключениями (exception) или ловушками (trap), вызываются ошибочными ситуациями при выполнении команды. В отличие от внешних или программных прерываний, исключения прерывают выполнение команды на середине. Вектор состояния, запоминаемый при выполнении исключения, таков, что его восстановление приводит к повторному выполнению команды, вызвавшей исключение. Исключение, например, генерируется при неправильном коде команды, при попытке выполнить привилегированную команду в не привилегированном режиме, при попытке команды обращения к недоступной области памяти и т.д. Как правило, обработка ОС прерывания-исключения приводит к принудительному аварийному завершению процесса, в котором произошло исключение (и запомненный вектор состояния уже не восстанавливается). Однако в некоторых случаях (некоторые из таких случаев рассматриваются нами в последующих главах) исключение является штатной ситуацией, "замаскированной" формой системного вызова, сигнализирующего ОС о необходимости выполнить для процесса некоторое обслуживание.
Архитектурные концепции операционных
Рисунок 1.6. Иерархия абстрактных машин в системе THE
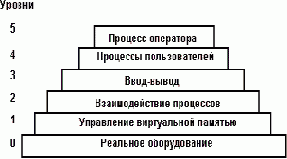
Реализация архитектуры абстрактных машин сопряжена со значительными трудностями, связанными с правильным выбором уровней и их иерархическим упорядочением. Система THE представляет только один из возможных вариантов, применимый далеко не во всех случаях. Успешность решения этой проблемы во многом зависит от выбранного метода проектирования. В первоисточнике реализация иерархии абстрактных машин производилась методом "снизу-вверх". Другие авторы (например, [11]) настаивают на реализации методом "сверху вниз". По-видимому, наиболее продуктивным является комбинированный метод, пример применения которого приведен в [10]: спецификации уровней разрабатываются "сверху вниз", а реализация ведется "снизу вверх". При любом методе проектирования обеспечиваются некоторые некоторые общие свойства уровней абстракции, важнейшие из которых следующие: каждый уровень обеспечивает некоторую абстракцию данных в системе и, располагая определенными ресурсами, либо скрывает их от других уровней, либо предоставляет другим уровням виртуальные ресурсы; на каждом уровне ничего не известно о свойствах более высоких уровней; на каждом уровне ничего не известно о внутреннем строении других уровней; связь между уровнями осуществляется только через жесткие, заранее определенные сопряжения.
Иногда иерархию абстрактных машин иллюстрируют набором концентрических окружностей (например, [30]), чтобы подчеркнуть, что каждый следующий уровень иерархии полностью скрывает все лежащие ниже него уровни и каждый уровень может обращаться только к непосредственно нижележащему уровню. Обращения, адресованные к более низким уровням, последовательно проходят все промежуточные уровни.
Популярными современными вариациями на тему иерархической архитектуры являются концепции виртуальной машины и микроядра. В обоих случаях некоторый уровень иерархии получает особый статус и служит границей между двумя основными уровнями системного программного обеспечения. Спецификации интерфейса между двумя основными уровнями четко определены, что делает их независимыми друг от друга.
В концепции виртуальной машины интерфейс процесса выглядит как интерфейс оборудования. В предельном случае, который можно наблюдать, например, в VM/ESA [34] внешние формы этих двух интерфейсов полностью совпадают. В этом случае процессу доступны все машинные команды, в том числе и привилегированные. Но эта доступность кажущаяся. На самом деле, выдача процессом привилегированной команды вызывает исключение. В большинстве ОС обработка такого исключения включает в себя аварийное завершение процесса, но в VM/ESA управление по исключению получает нижний уровень системы - CP (управляющая программа). CP определяет причину исключения и выполняет для процесса требуемую команду или моделирует выполнение этой команды на виртуальном оборудовании. У процесса создается иллюзия, что в его полном распоряжении находится реальная вычислительная система (с той, однако, поправкой, что временные соотношения выполнения некоторых команд не выдерживаются). А если так, то процесс в свою очередь может быть ОС, так называемой гостевой (guest) ОС, которая в полном объеме управляет выделенным ей подмножеством ресурсов.
Другой вариант концепции виртуальной машины представляет интерфейс нижнего уровня системного программного обеспечения как полнофункциональный набор команд некоторой воображаемой машины. Все вышележащие уровни программного обеспечения пишутся в этом наборе команд (или компилируются в него). Программный модуль, готовый для выполнения, представляет собой двоичный код программы в командах виртуальной машины. Перевод команд виртуальной машины в команды конкретной аппаратной платформы выполняется нижележащим уровнем программного обеспечения в режиме перекомпиляции (например, AS/400 [18]) или интерпретации (например, технология Java [29]), компилятор или интерпретатор входит в состав нижнего уровня. Использование промежуточного кода в командах виртуальной машины обеспечивает переносимость программного обеспечения на другие платформы, так как все, в том числе и системное, программное обеспечения, лежащее выше уровня интерфейса виртуальной машины, является платформенно-независимым и при переносе не требует даже перекомпиляции.
Еще одна вариация на тему иерархической архитектуры - концепция микроядра. Суть ее заключается в том, что части системного программного обеспечения, которые выполняются в режиме ядра, сосредоточены на нижнем уровне иерархии, они и составляют микроядро. Объем микроядра минимизируется, что повышает надежность системы. Прочие модули ОС выполняются в режиме процесса и с точки зрения микроядра ничем не отличаются от процессов пользователя. В микроядро включаются также наиболее важные платформенно-зависимые функции с тем, чтобы обеспечить оптимизацию их выполнения и относительную независимость от платформы модулей ОС, не входящих в микроядро. Минимальный набор функций микроядра включает в себя: управление реальной памятью (это всегда платформенно-зависимая функция); переключение контекстов (но не процессов! Решение о том, какой процесс должен перейти в какое состояние, принимает планировщик, который не должен работать в режиме ядра), а в мультипроцессорных системах - и управление загрузкой процессоров; предварительная обработка аппаратных прерываний (для полной обработки прерывания перенаправляются тем процессам, которым они адресованы); обеспечение коммуникаций между всеми процессорами вне микроядра - системными и пользовательскими, в системах, изначально ориентированных на распределенную обработку - также и сетевых коммуникаций.
Архитектурная концепция микроядра также обеспечивает переносимость системного программного обеспечения верхнего уровня (хотя и с необходимостью его перекомпиляции).
Набор преимуществ, обеспечиваемых микроядром, очень велик, и в разных системах это понятие трактуется по-разному - в зависимости от того, какие требования к системе являются доминирующими. Так, описанный выше подход минимизации кода, выполняемого в режиме ядра, и повышения эффективности в полной мере реализован, например, в ОС QNX [32]. В Windows NT/200 [16] микроядром называют часть, обеспечивающую независимость от внешнего оборудования и ряд функций режима ядра, но одним микроядром эти функции не исчерпываются. В AS/400[18] часть кода, лежащую ниже интерфейса виртуальной машины тоже иногда называют микроядром, хотя для программного обеспечения, состоящего из более, чем 1 млн. строк кода на языке C++, префикс "микро" вряд ли уместен.
Еще одной тенденцией в развитии ОС является объектно-ориентированный подход к их проектированию. Как известно, основными свойствами объектно-ориентированного программирования являются инкапсуляция, полиморфизм и наследование. Из указанных свойств в объектно-ориентированных ОС в полной мере реализуется прежде всего первое. Ресурсы в таких системах представляются в виде экземпляров тех или иных классов, внутренняя структура класса недоступна вне класса, но для класса определены методы работы с ним. Наряду с повышением степени интеграции тех базовых элементов, из которых строится ОС, инкапсуляция обеспечивает также защиту ресурсов и возможность менять в новых версиях ОС или при переносе на новую платформу структуру системных объектов без изменения тех программ, которые оперируют объектами. Для каждого типа объектов определен набор допустимых операций над ним. Свойство полиморфизма состоит в том, что для различных системных классов могут быть определены одноименные операции, выполнение которых для разных классов будет включать в себя как общие, так и специфические для каждого класса действия. Важнейшей из таких операций является получение доступа к объекту, отдельно рассматриваемое нами в главе 10. Свойство наследования реализуется в объектно-ориентированных ОС лишь отчасти, в связи с чем некоторые авторы (например, [18]) считают, что правильнее называть эти ОС объектно-базированными. В системах с иерархической структурой (Windows NT, AS/400) объекты более высокого уровня могут включать в себя объекты нижних уровней, однако, производные классы не наследуют методы базовых и, следовательно, их экземпляры не могут обрабатываться как экземпляры базового класса. Нельзя, однако, говорить об этом ограничении, как о недостатке, так как оно диктуется концепцией иерархической архитектуры: каждый уровень должен оперировать только объектами своего уровня.
Архитектурные концепции построения ОС не являются взаимоисключающими. Как вы, по-видимому, заметили из приводимых примеров, существуют системы, в архитектурах которых комбинируются несколько подходов.
Важным архитектурным вопросом является оформление модулей ОС. Модули могут представлять собой процедуры или процессы. В первом случае все ядро ОС представляется как один многомодульный процесс и передача управления между модулями ОС выполняется просто командами типа CALL. Во втором случае каждый модуль представляется в виде отдельного процесса (процесса ядра), и передача управления сопровождается переключением процессов. Хотя во втором случае передача управления занимает больше времени, такой подход обеспечивает, во-первых, лучшую защиту ресурсов, используемых и управляемых ОС, а во-вторых, делает модульную структуру ОС более гибкой. Архитектура процессов ядра может совмещаться с архитектурой иерархии абстрактных машин: каждый уровень иерархии обеспечивается своим набором процессов ядра. Промежуточным случаем является подход, характерный, например, для ОС Unix: обращение процесса к ОС вызывает переключение контекста на ядро, но не переключение процессов, то есть, модули ядра выполняются в контексте вызвавшего их процесса. В тех ОС, в которых отношения между процессами строятся по схеме "предок-потомок", иерархия может непосредственно отображаться в "родственных отношениях" процессов. Что касается процедурной архитектуры, то такие отношения в ней естественным образом отображаются на вложенности вызовов процедур.
Оформление модулей ОС непосредственно связано с проблемой управления ресурсами, особенно ресурсами разделяемыми. В случае процедурного оформления управление каждым видом (классом) ресурса выполняется отдельной процедурой-монитором. Монитор является процедурой, используемой всеми функционирующими в системе процессами, и процедура эта всегда выполняется в контексте вызвавшего ее процесса. Структура монитора предотвращает конфликты при одновременном обращении к нему двух или более процессов. При оформлении модулей ОС в виде процессов ядра каждый ресурс обслуживается своим процессом-менеджером. Доступ к ресурсу из любого другого процесса выполняется через обращение к менеджеру и переключение в контекст менеджера.
Еще один важный вопрос - организация взаимодействия между модулями и здесь можно выделить две модели [14]: интерфейс процедур и интерфейс сообщений. Интерфейс процедур подразумевает непосредственное обращение вызывающего модуля к вызываемому, подобное обращению к подпрограмме в языках программирования. Обращение может быть либо действительно обращением к процедуре (команда CALL), либо сводиться к прерыванию и переключению процессов. Модель интерфейса процедур синхронная, то есть, как и при вызове подпрограммы, выполнение вызывающего модуля приостанавливается до получения результата вызова. Эта модель может быть построена на базе как процедурных модулей ОС, так и модулей-процессов. Другая модель обеспечивает взаимодействие процессов через единый системный механизм очередей. Процесс-клиент (в этой модели модули ОС должны быть именно процессами) оформляет свой запрос в виде сообщения и отправляет его процессу-серверу. Процесс-сервер получает сообщение из своей входной очереди, выполняет содержащийся в сообщении запрос и отправляет результат в виде сообщения процессу-клиенту. Процесс-клиент после отправки своего сообщения может либо продолжать выполняться, либо ожидать прихода ответного сообщения. Взаимодействие процессов, таким образом, происходит асинхронно.
Подходы, которые выбирают в современных ОС, в значительной степени определяются их назначением. Однопользовательские ОС стремятся в максимальной степени повысить быстродействие выполнения приложений. Хотя в сверхвысоком быстродействии зачастую нет функциональной необходимости, оно является существенным фактором в конкурентной борьбе. Поэтому в таких ОС проявляется тенденция к предельной минимизации числа переключений процессов и к выполнению системных вызовов в контексте процесса пользователя. Отсюда - процедурная форма модулей ядра, мониторное управление ресурсами, процедурная модель взаимодействия. С другой стороны, многопользовательские ОС, как правило, представляют модули ядра в виде процессов-менеджеров ресурсов и для взаимодействия между ними предпочитают модель сообщений. Это обеспечивает значительно лучшую защиту ресурсов, особенно в среде с высоким уровнем мультипрограммирования.
Архитектурные концепции операционных систем
Рисунок 1.5.
Б еще может разрядиться если
Рисунок 5.5. Анализ ситуации

При исследовании проблемы тупиков удобно представлять систему в виде графа. Пример такого графа показан на Рисунке 5.6.
Базовая файловая система
7.5. Базовая файловая система.
Дескриптор файла
Выше мы уже неоднократно упоминали дескриптор файла, и читатель, наверное, уже сделал правильный вывод о том, что эта структура данных является ключевой при переводе виртуального представления файла в реальное. Дескриптор однозначно связан с физическим файлом, но храниться может как вместе с файлом, так и отдельно от него. В любом случае, однако, дескриптор файла является прозрачным для процессов пользователей, он обрабатывается только ОС. Дескриптор содержит информацию о физической природе файла и информацию о его использовании и защите. Естественно, что формат дескриптора определяется спецификациями конкретной ОС, и мы можем дать только приблизительное перечисление его полей. В общем случае в дескриптор файла могут входить следующие составляющие: тип файла (файл данных, косвенный файл, каталог, файл-устройство и т.п.); тип данных файла (текст, объектный модуль, программа и т.п.); сведения об организации файла (для перехода от логической структуры к физической); размер файла; план (layout) размещения файла на устройстве внешней памяти; список прав доступа; время (создания, последней модификации, последнего доступа); счетчик алиасов файла; и т.д., и т.п.
Некоторые из входящих в состав дескриптора подструктуры данных мы рассмотрим ниже более подробно. В основном содержимое дескриптора формируется при создании файла или каталога (системные вызовы createFile, createDirectory ), некоторые поля изменяются при работе с файлом. Предоставляем читателю самому проследить, как системные вызовы, описанные выше, работают с дескрипторами файлов/каталогов.
Наиболее важным для дескриптора файла является системный вызов open , он производит активизацию дескриптора. Для файлов на устройствах внешней памяти при этом производится считывание дескриптора в оперативную память и построение его расширения, называемого дескриптором открытого файла. Для устройств, представляемых в виде виртуальных файлов, файловых дескрипторов на внешней памяти не существует, но в оперативной памяти открытие такого виртуального файла вызывает построение дескриптора открытого файла, отличающегося от дескриптора открытого файла на внешней памяти, как правило, содержимым полей, но не их форматом. Для каталогов системный вызов open не выполняется явным образом, но при выполнении функций поиска по заданному пути в логической ФС активизируются дескрипторы всех каталогов, входящих в путь.
В расширение дескриптора открытого файла в оперативной памяти могут входить: счетчик открытий файла (файл может одновременно использоваться несколькими процессами); замок (lock) разделяемого доступа; режим обработки; режим буферизации; текущее положение файлового курсора; идентификация устройства, на котором расположен файл; информация, зависящая от типа файла.
Так, например, при подключении тома к ФС в виде ветви общего дерева каталогов, в памяти создается дескриптор для псевдокаталога, которым представлен подключенный том. Этот дескриптор содержит признак, описывающий его, как "точку монтирования", и ссылку на элемент специальной системной таблицы монтирования. Элемент же таблицы содержит описание тома и указатели как на корневой каталог тома, так и обратно - на "точку монтирования", что позволяет проходить эту точку при движении по дереву в обоих направлениях.
Очевидно, что некоторые поля дескриптора должны изменяться автоматически при работе с файлом. Все изменения, выполненные в дескрипторе в ходе работы с открытым файлом, запоминаются в его копии на внешней памяти при выполнении системного вызова close .
Обычно ОС предоставляют также в составе своего API тот или иной набор системных вызовов, сводящихся к двум типам: getFileInfo, setFileInfo - получить или установить информацию о файле. Выполнение вызовов этой группы позволяет прочитать/записать значения отдельных полей файловых дескрипторов.
Управление доступом
В некоторых ОС одной из важнейших функций базовой ФС является контроль за доступом пользователей к файлам. Мы говорим "в некоторых", так как в ряде ОС проблема контроля доступа решается на общесистемном уровне, и доступ к файлам - ее частный случай. Такие ОС рассматриваются нами в главе 10, здесь же мы остановимся на случае, когда доступ к файлам контролируется базовой ФС, и рассмотрим его на примере ОС Unix.
В Unix возможны следующие режимы доступа к файлам: r - чтение, w - запись, x - выполнение. Возможны также их комбинации.
Пользователи подразделяются на следующие категории: владелец - пользователь, который создал файл; группа - пользователи, входящие в ту же группу, что владелец файла; все остальные пользователи.
Для каждого файла определяется допустимый режим доступа для каждой из этих трех групп. Так, например, если для файла доступ закодирован в виде: rwxr-x--x,
то это означает, что владелец имеет право читать, писать и выполнять файл (rwx), остальные члены группы владельца имеют право читать и выполнять файл (r-x), все другие пользователи - только выполнять (--x).
Идентификаторы владельца и группы владельца входят в состав файлового дескриптора. Для кодировки прав доступа достаточно трех 3-битных позиционных кодов, которые также включаются в дескриптор.
Каждая активизация файлового дескриптора базовой ФС включает в себя проверку прав доступа. В ходе проверки определяется идентификатор владельца процесса, открывающего файл. Этот идентификатор сравнивается с идентификатором владельца файла и с идентификатором группы владельца файла. В зависимости от результатов сравнения определяется категория пользователя, открывающего файл и выбирается соответствующий 3-битный код доступа. Режим доступа, запрашиваемый при открытии, сравнивается с кодом доступа, и при несоответствии их происходит отказ в доступе.
Как мы отмечали выше, с точки зрения базовой ФС каталоги практически ничем не отличаются от файлов, следовательно, все, что говорилось выше о правах доступа, относится и к каталогам.
Поскольку логическая ФС при поиске обращается к базовой ФС для чтения информации из каталогов, а базовая ФС производит при этом проверку прав доступа, то файл может быть доступен для данного пользователя только, если для него доступны все подкаталоги, входящие в путь к файлу.
Как определяется доступ к алиасам и косвенным файлам? Что касается алиасов, то ответ зависит от того, связываются ли права доступа с именем или с файлом. До сих пор мы говорили о том, что права доступа хранятся в файловом дескрипторе, поскольку физическому файлу соответствует единственный файловый дескриптор, права доступа к файлу по всем алиасам будут одинаковы. Возможно, однако, хранение прав доступа не в дескрипторе, а в элементе каталога, в этом случае разные алиасы могут обеспечивать разные права доступа к одному файлу. Возможны два варианта реализации прав доступа к косвенному файлу. В первом варианте в псевдодескрипторе, содержащем ссылку указываются права доступа, как для обычного файла, при соответствии конкретного режима доступа этим правам проверка прав доступа заканчивается. Во втором случае проверка прав доступа продолжается и для всех каталогов, входящих в путь, указанный в ссылке.
Базовые дисциплины планирования
2.2. Базовые дисциплины планирования
Ниже приводятся описания некоторых базовых дисциплин планирования. Эти дисциплины достаточно просты в реализации и хорошо исследованы методами как аналитического (например, [12]), так и имитационного (например, [27]) моделирования. Мы называем их базовыми, поскольку в реальных системах они служат основой для построения более сложных и гибких модификаций и комбинаций, для которых аналитические модели построить, как правило, невозможно.
FCFS (first come - first serve - первым пришел - первым обслуживается) - простейшая дисциплина, работа которой понятна из ее названия. Это дисциплина без вытеснения, то есть, процесс, выбранный для выполнения на ЦП, не прерывается, пока не завершится (или не перейдет в состояние ожидания по собственной инициативе). Как дисциплина без вытеснения, FCFS обеспечивает минимум накладных расходов. Среднее потерянное время при применении этой дисциплины не зависит от длительности процесса, но штрафное отношение при равном потерянном времени будет большим для коротких процессов. Поэтому дисциплина FCFS считается лучшей для длинных процессов. Существенным достоинством этой дисциплины, наряду с ее простотой, является то обстоятельство, что FCFS гарантирует отсутствие бесконечного откладывания процессов: любой поступивший в систему процесс в конце концов будет выполнен независимо от степени загрузки системы.
На рисунке 2.2 показан пример планирования по дисциплине FCFS для трех процессов - A, B и C. На временной диаграмме каждый прямоугольник представляет интервал времени, в течение которого процесс находится в системе. Над верхним левым углом такого прямоугольника указан идентификатор процесса, а в скобках - его длительность. Незатемненные участки соответствуют активному состоянию процесса, затемненные - состоянию ожидания. Процесс A поступает в момент времени 0 и требует для выполнения 6 единиц процессорного времени. ЦП в этот момент свободен, и процесс A сразу же активизируется. В момент времени 2 поступает процесс B, требующий 11 единиц. Поскольку ЦП занят процессом A, процесс B ожидает в очереди готовых процессов до момента 6, когда процесс A закончится и освободит ЦП. Только после этого процесс B начинает выполняться. Пока процесс B выполняется, поступают еще два процесса: C - в момент времени 8 и D - в момент 10, которые ждут завершения процесса B. Когда процесс B завершится, ЦП будет отдан процессу C, поступившему раньше, а процесс D остается в ожидании. В линейке, расположенной под временной шкалой, указаны идентификаторы процессов, активных в данный момент времени. Читатель может сам определить показатели эффективности планирования - для каждого процесса и усредненные. Следует, однако, предупредить, что к усредненным показателям надо относиться с осторожностью, так как достоверными могут считаться только результаты, полученные на статистически значимой выборке.
Бесконечное откладывание
5.4. Бесконечное откладывание
Процессы, ожидающие ресурсов, встают в очереди к этим ресурсам. Такая очередь может обслуживаться любой невытесняющей стратегией планирования. Моментом, когда менеджер ресурса принимает решение об обслуживании, является освобождение ресурса.
Единственной дисциплиной, которая гарантирует, что все процессы в очереди будут в конце концов обслужены, является FCFS. Другие методы базируются на приоритетах - внешних или вычисляемых на основании размера запроса или/и безопасности ситуации. Очередь может быть упорядочена по возрастанию размера запроса, и при освобождении ресурсов последние могут отдаваться по запросу "самого подходящего" размера. Очередь может быть упорядочена в порядке возрастания опасности выделения ресурсов, и освободившийся ресурс может отдаваться тому процессу, запрос которого самый безопасный. При упорядочении очереди, процесс, выдавший самый большой или самый опасный запрос, может надолго в ней застрять, то есть, попасть в ситуацию бесконечного откладывания. С другой стороны, применение FCFS в чистом виде может привести к снижению уровня мультипрограммирования, к опасному состоянию и даже к тупику - если процесс со слишком большим запросом окажется первым в очереди. Отчасти это противоречие может быть сглажено, если мы допустим частичное выделение ресурсов: запрос, стоящий в очереди первым получает столько ресурсов, сколько ему можно выделить, сохраняя ситуацию безопасной, остальные - отдаются следующему в очереди процессу.
Поскольку тупиковая ситуация более опасна, чем бесконечное откладывание, ОС все же отдает предпочтение критериям безопасности, следовательно, заведомо предотвратить бесконечное откладывание невозможно. Бесконечное откладывание процесса устанавливается по времени его пребывания в очереди: если процесс пребывает в очереди дольше некоторого установленного времени, то считается, что он ожидает бесконечно. В зависимости от политики ОС в отношении справедливости обслуживания и от характеристик процесса (если они известны) допустимое время ожидания может устанавливаться большим или меньшим. Если же бесконечное откладывание установлено, то для его ликвидации ОС приостанавливает выдачу ресурсов новым процессам, пока не будет обслужен отложенный процесс.
Проблема тупиков до некоторой степени теряет актуальность в современных ОС, так как они имеют тенденцию к уменьшению количества неразделяемых ресурсов. Одним из способов сделать неразделяемое устройство разделяемым является буферизация, которую мы рассмотрим в следующей главе. Системные структуры данных разделяются с использованием средств взаимного исключения доступа, которым будет посвящена глава 8. Эта проблема, однако, становится все более актуальной для современных СУБД, которые обеспечивают одновременный доступ к ресурсам-данным для тысяч и десятков тысяч пользователей.
Буфер терминала для Unix
Рисунок 6.7. Буфер терминала для Unix
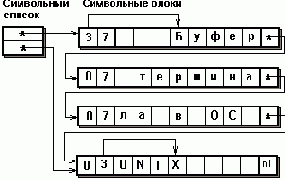
Пример буфера при N=8 показан на Рисунке 6.7. Ядро ОС хранит указатели на первый и последний блоки цепочки и ведет список свободных блоков (очередь LIFO). Ядро обеспечивает: назначение драйверу свободного блока; возвращение блока в список свободных; выбор первого символа из буфера (при этом возможно освобождение блока); добавление символа в конец буфера (при этом возможно выделение нового блока).
Буферизация
6.7 Буферизация
Хотя блокировки и не влияют на результат выполнения процесса и не отражаются на его виртуальном времени, они сказываются на реальном времени его выполнения. Для интерактивных процессов они могут стать основным фактором, определяющим время реакции процесса. Невыгодны блокировки и для ОС, так как каждая блокировка - это переключение процессов, а следовательно, накладные расходы. Одним из способов, позволяющим избежать блокировок (или, по крайней мере, уменьшить их количество), является буферизация данных. Для устройства ввода-вывода назначается буферная область в оперативной памяти. Обмен данными происходит между процессом и буферной областью, а обмен между буферной областью и устройством выполняет ОС независимо от выполнения процесса. Если, например, выполнение системного вызова write будет включать в себя только пересылку данных в оперативной памяти, то блокировка процесса на время выполнения этого вызова не нужна. Буферизация, таким образом, сглаживает различия в скоростях работы производителя и потребителя информации и позволяет избежать излишних блокировок.
Особенно существенный эффект буферизация может дать при последовательном вводе-выводе, так как при вводе ОС может предсказать, какой блок информации понадобится следующим и произвести его упреждающее чтение в буфер. Еще один полезный эффект буферизации - ОС имеет возможность сгруппировать данные в буфере и производить обмен с внешним устройством большими блоками.
Богатые вариантами средства организации ввода-вывода с использованием буферизации были впервые реализованы в OS/360[15] и унаследованы следующими поколениями ОС мейнфреймов. При синхронной организации ввода-вывода (в OS/360 - "методы доступа с очередями") буферизация прозрачна для процесса, она полностью обеспечивается ОС. При асинхронной организации ("базисные методы доступа") процесс сам может организовать буферизацию. Устройству назначается буферная область, которая форматируется как буферный пул. В методах с очередями это назначение происходит автоматически, программист может только изменить размер пула, если его не устраивает принятый по умолчанию. В базисных методах есть специальные системные вызовы для выделения, освобождения, форматирования буферного пула и связывания пула с устройством. Буферизация не обязательно означает дополнительную пересылку данных в оперативной памяти. Методы с очередями предоставляют три альтернативных режима управления буферизацией: режим пересылки - данные пересылаются в оперативной памяти между рабочей областью процесса и буфером; режим указания - данные не пересылаются; при вводе процесс получает от ОС адрес буфера, содержащего введенные данные, и может использовать его как рабочую область, при выводе процесс получает от ОС адрес свободного выводного буфера и использует его как свою рабочую область, формируя в ней данные для вывода; режим подстановки - данные не пересылаются; при вводе процесс получает от ОС адрес заполненного вводного буфера, а свою рабочую область передает во вводной буферный пул; при выводе процесс передает в выводной пул свою рабочую область, заполненную выводными данными, а взамен получает свободный буфер из пула.
Два интересных примера буферизации мы возьмем из ОС Unix.
В Unix буферизация обмена с дисковыми накопителями (кэширование) является тотальной, через кэш проходят все данные, которыми ОС и процессы обмениваются с дисками, и под кэш отводится значительная часть оперативной памяти. Кэширование дает значительный эффект и при случайном (непоследовательном) обмене, характерном для многозадачной многопользовательской ОС. В дескрипторе каждого буфера в кеше имеются поля: состояние буфера (свободен/содержит правильную информацию/грязный/заблокирован/занят в операции ввода-вывода/ожидается каким-либо процессом); адрес на внешней памяти блока информации, содержащегося в буфере; указатели, связывающие буфера в хеш-очереди (см.дальше) и в список свободных.
Список свободных буферов организован как простая FIFO-очередь: ядро ОС выбирает буфер из головы списка, освобождающийся буфер включает в конец списка. Таким образом, буфер, попавший в список свободных еще некоторое время находится в этом списке, сохраняя свое содержимое, и может быть выбран из списка, если к нему будет обращение. При обращении к дисковому вводу-выводу основным параметром является адрес блока на внешней памяти. ОС прежде всего ищет в кеше соответствующий блоку буфер и только при неудачном поиске в кеше назначает свободный буфер и производит физическое обращение к диску. Для ускорения поиска в кеше все буфера распределяются по нескольким спискам, именуемым хеш-очередями. Номер списка определяется как результат весьма простой функции хеширования, аргументом которой является адрес на внешней памяти. Применение хеширования позволяет равномерно распределить буферы по хеш-очередям. Каждый буфер может входить только в одну хеш-очередь, но также может быть включен и в список свободных. Процесс, выдавший запрос на ввод-вывод, блокируется в случаях: если буфера нет в хеш-очереди и список свободных блоков пуст; если буфер есть в хеш-очереди, но он занят.
При освобождении блока разблокируются все процессы, ждущие освобождения этого или любого блока.
Все современные ОС (OS/2, Windows 95, Windows NT) в той или иной степени применяют тотальное кэширование при обмене с дисками.
Второй пример - буферизация ввода в драйвере терминала. Задача такой буферизации - обеспечить накопление данных и возможность упреждающего ввода с терминала. Для этой буферизации характерны: последовательный ввод, сравнительно небольшие объемы данных в буфере, непостоянный объем информации, содержащейся в буфере. Буфер представляет собой цепочку блоков, каждый из которых имеет постоянную длину N. В каждом блоке имеются следующие поля: указатель на следующий блок в цепочке; смещение первого символа в поле данных; смещение последнего символа в поле данных; поле данных для хранения N символов.
Целостность данных и файловой системы
7.8. Целостность данных и файловой системы
Контроль доступа является лишь одной из составляющих защиты файлов. Другими составляющими является обеспечение сохранения или восстановления целостности информации при аппаратных сбоях и при параллельном доступе к ней. Методы защиты от потерь целостности, происходящих по причине аппаратных и программных ошибок, можно подразделить на основывающиеся на избыточности и основывающиеся на копировании.
Избыточность, поддерживаемая программно, на уровне ОС, обеспечивается, как правило, только для особо важной системной информации: дескрипторов дисков и файлов, таблиц размещения, каталогов и т.п. При записи одной и той же информации в два разных блока на диске даже, если сбой произойдет во время записи, один из блоков будет содержать корректный вариант информации - то ли до ее изменения, то ли после. Избыточность может вноситься как простым дублированием управляющих структур данных, так и внесением избыточности в сами эти структуры. Так, в структуры данных, которые связываются в списки, часто вводятся дополнительные указатели, позволяющие получить доступ к одной и той же структуре данных разными путями. Причем, при штатной работе используется только один путь, а остальные могут быть использованы для восстановления списка при нарушении указателей основного пути. Например, если сделать список свободных блоков на диске двунаправленным, то по обратным прошивкам можно восстановить этот список при потере указателя на его начало в дескрипторе диска. Другой пример: алгоритмы функционирования логической и базовой ФС не нуждаются в том, чтобы имя файла, имеющееся в элементе каталога, дублировалось в дескрипторе файла. Однако, такое дублирование чрезвычайно облегчит задачу восстановления доступа к файлам при разрушении системы каталогов.
Начнем с того, что весьма часто нарушение целостности происходит по вине пользователя - ошибочное удаление файлов или внесение в них неправильных изменений. Профилактикой этих ошибок является создание обратных копий (backup) файлов, к которым можно вернуться, если испорчена или уничтожена текущая копия. Концепция обратных копий может быть расширена до сохранения нескольких поколений версий файлов: при изменении файла создается его новая версия, а старая версия сохраняется. Создание новых версий может производиться разными способами: вручную - пользователь сам копирует файл, версию которого он хочет сохранить, под новым именем; специальными утилитами - некоторые программы (например, текстовые редакторы) автоматически создают новую версию файла, который они изменяют (BAK-файлы, хорошо известные пользователям MS DOS); общей утилитой - которая проверяет версии всех файлов (или заданной группы файлов) и создает новые версии для изменившихся файлов; автоматически - самой ОС при открытии любого файла для записи.
Множественность версий может быть прозрачна для пользователя: все версии могут иметь одинаковое имя. Один элемент каталога может содержать массив ссылок на дескрипторы разных версий, или дескрипторы версий могут быть увязаны в список. Естественно, что по умолчанию всегда выбирается последняя версия и только специальным системным вызовом обеспечивается возврат к предыдущим версиям. Количество сохраняемых версий должно ограничиваться: это может быть либо общее для всех файлов ограничение, либо устанавливаемое индивидуально для каждого файла. При превышении числом версий файла установленного предела ОС автоматически выполняет удаление самой старой версии.
Профилактикой случайного удаления файла может быть неполное удаление. Такое удаление предполагает сохранение физического файла на диске, а следовательно, и возможность его последующего восстановления. Элемент каталога, соответствующий не полностью удаленному файлу, может помечаться специальным признаком или файл может переноситься в специальный каталог для удаленных файлов. Такой подход должен обеспечиваться двумя системными вызовами - deleteFile для неполного удаления и purgeFile - для полного. Неполное удаление создает, однако, проблему дискового пространства: неполное удаление файла не освобождает места на диске. ОС может периодически проверять срок хранения не полностью удаленных файлов и физически удалять те из них, которые не были восстановлены за установленный срок, или же выполнять такую проверку только, когда дает о себе знать нехватка дискового пространства.
Средством, практически гарантирующим минимизацию потерь при порче информации, является восстановление по резервной копии. Без рекомендаций о сохранении копий своих файлов на дискетах не обходится ни одно руководство по работе на персональных компьютерах, но выполнение этих рекомендаций требует от пользователя некоторой самодисциплины, которая в массе пользователям персональных ЭВМ, увы, не свойственна. В любых неперсональных системах и при работе над любыми неперсональными проектами копирование информации является не возможностью по выбору, а необходимостью. Для хранения резервных копий применяются магнитные ленты - носители, отличающиеся большим временем доступа, но и большой емкостью и малой стоимостью. Отчасти забытые по времена "персонального бума", они сейчас опять восстанавливают свои позиции архивных носителей.
Схема копирования должна обеспечивать минимизацию времени поиска и восстановления информации как при локальных (в пределах одного или нескольких файлов) потерях, так и при полном разрушении структур ФС. Рекомендуемая схема включает в себя несколько уровней выгрузки (dump), обычно - три: полные, повторные и инкрементные выгрузки. Полная выгрузка выполняется редко (например, раз в год) и включает в себя все имеющиеся на диске файлы. Повторные выгрузки производятся несколько чаще (например, ежемесячно) в них включаются только файлы, изменившиеся со времени предыдущей повторной или полной выгрузки. Инкрементные выгрузки выполняются часто (ежедневно) и включают в себя файлы, изменившиеся со времени предыдущей инкрементной или повторной. Для возможности восстановления состояния информации на начало текущего дня при полном крахе системы необходимо сохранять: носитель последнего полного дампа; все носители повторных дампов, сделанных со времени последнего полного; все носители инкрементных дампов, сделанных со времени последнего повторного.
В таком порядке и используются носители при выполнении восстановления.
Создание архивных копий должно выполняться системными утилитами, которые могут также вести учет архивированных файлов: поддерживать на внешней памяти (и сохранять на отдельных архивных носителях) таблицу файлов с указанием для каждого файла сведений о том, когда сделана его архивная копия, и на каком носителе она находится. Наличие такой таблицы позволяет выполнить быстрое восстановление при локальных сбоях.
При наличии аппаратной избыточности в дисковой памяти ФС может (как правило, в качестве дополнительной возможности) поддерживать правила чтения/записи, обеспечивающие отказоустойчивость и возможность восстановления информации, а также повышение быстродействия дискового ввода-вывода за счет параллельной работы двух и более дисков.. Эти правила известны как технологии RAID (Redundant array of inexpensive disks - избыточный массив недорогих дисков). Определены 5 уровней технологии RAID: RAID 0 - разделение данных по дискам - отдельные блоки данных записываются на разные свободные диски. Надежная защита не обеспечивается, так как при выходе из строя одного диска все данные могут быть потеряны. RAID 1 - дублирование дисков - данные записываются на оба диска по одному и тому же каналу. При порче одного из дисков данные могут быть восстановлены по другому, но при сбое канала все данные будут потеряны. RAID 2 - разделение данных по дискам с чередованием битов и контрольной суммой - метод неэффективный как по надежности, так и по быстродействию. На практике не применяется. RAID 3 - разделение данных по дискам с чередованием битов и проверкой четности - более надежный, чем RAID 2, но столь же медленный. На практике не применяется. RAID 4 - разделение данных по дискам с чередованием блоков и проверкой четности - быстродействие выше, чем RAID 3, но все же недостаточно для практического применения. RAID 5 - разделение блоков по дискам, чередование блоков, распределенная четность - требует не менее трех дисков. Каждый следующий блок данных помещается на другом физическом диске. В массиве блоков, имеющих одинаковые физические адреса на разных дисках, один блок используется как контрольный. Размещение контрольного блока - "скользящее", как показано на Рисунок 7.5. Контрольный блок содержит результат операции XOR между содержимым блоков с тем же адресом всех остальных дисков. При потере информации на одном из дисков эта информация может быть восстановлена путем выполнения XOR между контрольным блоком и блоками всех уцелевших рабочих дисков.
"Читателиписатели" и групповые мониторы
8.9. "Читатели-писатели" и групповые мониторы
Еще одна классическая задача синхронизации называется задачей "читателей-писателей" и формулируется следующим образом. Имеется произвольное число процессов-писателей и процессов-читателей, которые совместно используют какие-то данные (обычно имеется в виду файл). В любой момент процесс-читатель может потребовать прочитать данные. В любой момент процесс-писатель может потребовать прочитать или записать данные. Чтение и запись данных - операции длительные, но конечные. В то время, когда процесс записывает данные, никакие другие читатели или писатели не должны иметь доступа к данным. Любое число процессов может читать данные одновременно. Решение должно обеспечивать целостность данных и отсутствие бесконечного откладывания процессов.
Существенные отличия этой задачи от задачи производителей-потребителей состоят в следующем: процессы чтения и записи длительные; данные представляют собой повторно используемые ресурсы, а не потребляемые, как в предыдущей задаче; требуются различные режимы доступа для чтения и записи.
Нам не удастся решить эту задачу при помощи мониторов, описанных в предыдущем разделе, так как, если мы сделаем процедуры read и write охраняемыми, то, во-первых, у нас получатся слишком большие (длительные) критические секции, а во-вторых, мы исключим параллельное выполнение читателей.
Решение может быть получено при помощи, так называемого, группового монитора. В такой монитор входят как охраняемые, так и неохраняемые процедуры. Для того, чтобы процесс получил возможность доступа к неохраняемой процедуре, он должен быть членом группы, за которой право такого доступа закреплено. Группы формируются динамически. Для прикрепления к группе процесс должен обратиться к охраняемой процедуре. Если в данный момент прикрепление к группе возможно, эта процедура прикрепит процесс к группе, если нет - заблокирует процесс до появления такой возможности. После окончания доступа процесс должен вызвать также охраняемую процедуру открепления от группы. Для задачи "читатели-писатели" предполагается такой порядок доступа процессов к данным: для читателей: startRead ( proc ); read( proc, ... ); endRead ( proc ); для писателей: startWrite ( proc ); write ( proc, ... ); endWrite ( proc ); где proc - идентификатор процесса.
Структура самого монитора в общих чертах следующая: 1 int rdCnt = 0; /* счетчик читателей */ 2 char wrFlag = 0; /* признак активности записи */ 3 /* списки - писателей и читателей */ 4 process *wrCrowd=NULL, *rdrowd=NULL; 5 /* события: МОЖНО_ЧИТАТЬ, МОЖНО_ПИСАТЬ */ 6 event mayRead, mayWrite; 7 /*== процедура регистрации читателя ==*/ 8 void guard startRead ( process *p ) { 9 rdCnt++; /* подсчет читателей */ 10 /* если идет запись - ожидать МОЖНО_ЧИТАТЬ */ 11 if ( wrFlag ) wait (mayRead); 12 /* дублирование сигнала для другого читателя */ 13 signal (mayRead); 14 /* включение в список читателей */ 15 inCrowd ( rdCrowd, p ); 16 } 17 /*== процедура открепления читателя ==*/ 18 void guard endRead ( process *p ) { 19 /* исключение из списка читателей */ 20 fromCrowd ( rdCrowd, p ); 21 /* уменьшение числа читателей, 22 если читателей больше нет - сигнализация МОЖНО_ПИСАТЬ */ 23 if ( --rdCnt==0 ) signal(mayWrite); 24 } 25 /*== процедура регистрации писателя ==*/ 26 void guard startWrite ( process *p ) { 27 /* если есть другие читатели или писатели - ждать */ 28 if ( wrFlag||rdCnt ) wait(mayWrite); 29 /* установка признака записи */ 30 wrFlag = 1; 31 /* писатель включается в оба списка*/ 32 inCrowd ( rdCrowd, p ); 33 inCrowd ( wrCrowd, p ); 34 } 35 /*== процедура открепления писателя ==*/ 36 void guard endWrite ( process *p ) { 37 wrFlag=0; /* сброс признака записи */ 38 /* исключение из списков */ 39 fromCrowd ( rdCrowd, p ); 40 fromCrowd ( wdCrowd, p ); 41 /* если есть претенденты-читатели - разрешение им */ 42 if ( rdCnt ) signal (mayRead); 43 /* иначе - разрешение на запись */ 44 else signal (mayWrite); 45 } 46 /*== процедура чтения ==*/ 47 void read ( process *p, 48 < другие параметры > ) { 49 /* если процесс не зарегистрирован читателем - отказ */ 50 if (!checkCrowd(rdCrowd, p)) <отказ>; 51 else < чтение данных >; 52 } 53 /*== процедура записи ==*/ 54 void write ( process *p, 55 < другие параметры > ) { 56 /* если процесс не зарегистрирован писателем - отказ */ 57 if (!checkCrowd(wrCrowd,p)) <отказ>; 58 else < запись данных >; 59 }
Прежде, чем процесс получит доступ к данным, он должен зарегистрироваться как читатель или как писатель. В нашем примере переменные rdCrowd и wrCrowd (строка 4) являются указателями на списки читателей и писателей соответственно, хотя можно интегрировать процессы в группы и любым другим способом. Используемые (но не определенные) нами функции inCrowd и fromCrowd обеспечивают включение процесса в группу и исключение из группы, а функция checkCrowd возвращает 1, если указанный процесс входит в группу (иначе - 0). Процедура read выполняется только для процессов, включенных в группу читателей (строки 50, 51), а write - только для включенных в группу писателей (строки 57, 58). Переменная rdCnt (строка 2) - счетчик текущего числа читателей, переменная wrFlag (строка 4) - счетчик писателей (или признак наличия писателя, так как писателей не может быть более одного). События mayRead и mayWrite (строка 9) являются разрешениями читать и писать соответственно.
Входная точка startRead (строка 8) выполняет регистрацию читателя. Это охраняемая процедура. Она наращивает счетчик читателей, но если в данный момент работает писатель, то потенциальный читатель блокируется до наступления события mayRead (строка 11). После того, как процесс будет разблокирован (или если он не блокировался вообще), он выдает сигнал mayRead (строка 13), который предназначается для другого читателя, возможно, также ждущего разрешения на чтение (можно сказать, что процесс этим восстанавливает потребленный им ресурс), и включается в список читателей. После завершения доступа читатель обращается к входной точке endRead (строка 18). Эта процедура исключает процесс из списка читателей, уменьшает счетчик читателей и, если читателей больше не осталось, сигнализирует разрешение на запись.
Писатель регистрируется/разрегистрируется через входные точки startWrite/endWrite (строки 26-36). При регистрации потенциальный писатель может быть заблокирован, если в настоящий момент зарегистрирован другой писатель или хотя бы один читатель (строка 28). Сигнал mayWrite разблокирует писателя, и он включается в обе группы (строки 32, 33), так как имеет право и читать, и писать. При откреплении писатель исключается из групп. Если за время его работы попытался зарегистрироваться хотя бы один читатель, выдается разрешение на чтение (строка 42), в противном случае - разрешение на запись для другого писателя, возможно, ждущего своей очереди (строка 44).
Цикл жизни процесса
4.3. Цикл жизни процесса
Программа, готовая к выполнению, превратится в процесс только тогда, когда ОС создаст для нее блок контекста и запись в системной таблице процессов. ОС существенно различаются по тому признаку, насколько часто они создают новые процессы и сколько процессов могут одновременно существовать в системе.
В однозадачных системах существует один процесс (или несколько процессов, только один из которых - пользовательский), который последовательно выполняет одну программу за другой.
В многозадачных ОС, осуществляющих пакетную обработку, процессов, обслуживающих пользователей, несколько, но число их либо фиксировано и устанавливается при загрузке, либо меняется оператором, и такие изменения происходят весьма редко.
Различные подходы могут применяться в интерактивных системах. Во-первых, в интерактивной системе может копироваться стратегия многозадачной системы с пакетной обработкой: с каждым терминалом связывается единственный процесс-сеанс (session). Таким образом, предельное число процессов в системе ограничивается числом терминалов. Пользователь каждого терминала работает как бы в однозадачной среде (VM). Во-вторых, для преодоления стесненности пользователя в сеансе система может позволять в ходе сеанса порождать дополнительные, фоновые (background) процессы. Такие процессы выполняют программы, не требующие в ходе выполнения взаимодействия с оператором. Фоновые процессы работают параллельно с процессом, поддерживающим интерактивную работу в сеансе. Наконец, в-третьих, система может позволять порождать любые процессы и в любом количестве. Для каждой новой выполняемой программы создается новый процесс, который уничтожается с завершением программы. Процессы могут выполняться как последовательно, так и параллельно, ограничением на количество параллельно выполняемых процессов является объем ресурсов вычислительной системы и ОС, в частности, возможные ограничения на предельный размер таблицы процессов. Подход без ограничений на число процессов иногда называют философией "дешевых" процессов. В таких системах "накладные расходы" на создание процессов минимальны и наблюдается тенденция к предельному упрощению отдельных процессов: каждый отдельный процесс реализует некоторую весьма элементарную функцию, а сложные действия реализуются как комбинации тех или иных элементарных действий.
Процессы в системе могут либо существовать как отдельные не связанные друг с другом единицы, либо образовывать какие-либо структуры. Обычно модель независимого существования процессов используется в тех ОС, которые накладывают ограничения на возможности создания процессов (такая возможность доступна только самой ОС). В тех ОС, которые разрешают процессам в свою очередь порождать новые процессы, применяется иерархическая структура связей между процессами, в которой между процессами существуют отношения "родитель-потомок". Такая структура позволяет установить четкие правила в отношении использования ресурсов и организации управления. В такой структуре все действующие процессы могут в конечном счете являться потомками (более или менее близкими) одного системного процесса.
Передача ресурсов от предка к потомку позволяет родственным процессам легко устанавливать связи друг с другом. Наиболее важными в этом отношении ресурсами являются файлы, каналы и другие средства взаимодействия (см. главу 9). В соответствии с принятыми в конкретной ОС правилами, потомок может получать либо все ресурсы родителя, либо только те, для которых установлен признак "наследуемые" (inheritance), этот признак может быть установлен либо при выделении ресурса, либо - для уже выделенного ресурса - специальным системным вызовом.
Если пользовательскому процессу дана возможность порождать потомков, то в его распоряжении должны быть соответствующие системные вызовы. Конкретные возможные вызовы мы рассмотрим ниже, но сначала остановимся на общей семантике порождающих вызовов.
Процесс-потомок может быть запущен синхронно или асинхронно с родителем. При синхронном запуске процесс-родитель блокируется до завершения процесса-потомка. Естественно, что в этом случае родитель не может влиять на выполнение потомка. При асинхронном запуске родитель и потомок продолжают выполняться параллельно и могут взаимодействовать. Если родителю теперь необходимо дождаться завершения потомка, он выдает системный вызов ожидания. Синхронный запуск не является обязательной возможностью, так как тот же эффект может быть обеспечен парой вызовов: "асинхронный запуск" - "ожидание". Для того, чтобы родитель мог воздействовать на потомка, вызов "запуск" возвращает ему идентификатор (манипулятор) порожденного процесса. Этот идентификатор используется родителем при последующих воздействиях на потомка. Поскольку потомок может в свою очередь создавать новые процессы, то есть, стать во главе целого подсемейства (поддерева) процессов, интерпретация идентификатора процесса в системных вызовах, связанных с воздействиями на него, должна быть четко определена системными соглашениями или дополнительным параметром таких вызовов. Возможные интерпретации идентификатора следующие: только тот процесс, идентификатор которого задан; процесс, идентификатор которого задан, и все его потомки; процесс, идентификатор которого задан, или любой из его потомков.
В конкретных системах могут вводиться некоторые разумные ограничения на число порождаемых процессов, связанные с предельными размерами таблицы процессов и очереди к планировщику. Может ограничиваться, например, число потомков у процесса или число процессов, принадлежащих одному пользователю.
Процесс-потомок при запуске не знает идентификатора своего родителя, но, как правило, может его получить при помощи системного вызова.
Ниже мы приводим набор системных вызовов, обеспечивающих порождение процессов и "родственные отношения" между ними.
Порождение нового процесса и выполнение в нем программы: pid = load(filename); для нового процесса создается новая запись в системной таблице процессов и блок контекста. В блоке контекста формируется описание адресного пространства процесса - например, таблица сегментов. Выполняется формирование адресного пространства - образы некоторых частей адресного пространства (сегментов) процесса (коды и инициализированные статические данные) загружаются из файла, имя которого является параметром вызова, выделяется память для неинициализированных данных. Формирование всех сегментов не обязательно происходит сразу же при создании процесса: во-первых, если ОС придерживается "ленивой" тактики, то формирование памяти может быть отложено до обращения к соответствующему сегменту; во-вторых, в загрузочный модуль могут быть включены характеристики сегментов: предзагружаемый (preload) или загружаемый по вызову (load-on-call). Новому процессу должна быть выделена также и вторичная память - для сохранения образов сегментов/страниц при свопинге. Часть вторичной памяти для процесса уже существует: это образы неизменяемых сегментов процесса в загрузочном модуле. Для более эффективного поиска таких сегментов ОС может включать в блок контекста специальную таблицу, содержащую адреса сегментов в загрузочном модуле. При выделении вторичной памяти для изменяемых сегментов все ОС обычно следуют "ленивой" тактике. Ресурсы процесса-родителя копируются в блок контекста потомка. В вектор состояния нового процесса заносятся значения, выбор которых в регистры процессора приведет к передаче управления на стартовую точку программы. Новый процесс ставится в очередь готовых к выполнению. Вызов load возвращает идентификатор порожденного процесса.
Смена программы процесса: exec (filename);
Завершается программа, выдавшая этот системный вызов, вместо нее запускается другая программа. Вызов exec может быть реализован как комбинация вызовов exit (завершить текущий процесс) и load (создать новый процесс), но может и не порождать смену процессов, а только обновлять адресное пространство (включая и блок контекста) текущего процесса. В последнем случае сохраняются также и ресурсы процесса. Идентификатор процесса не изменяется.
Расщепление процесса: pid = fork(); порождается новый процесс - копия процесса-родителя. При копировании таблицы сегментов родителя в блок контекста потомка принимаются во внимание характеристики сегментов: уникальный - сегмент может принадлежать только одному процессу, в таблицу потомка этот сегмент не копируется; разделяемый - элемент таблицы сегментов потомка совершенно идентичен элементу таблицы родителя, включая базовый адрес в реальной памяти. копируемый - для потомка выделяется новый сегмент в реальной памяти, в него копируется содержимое соответствующего сегмента родителя, и элемент таблицы сегментов потомка содержит базовый адрес нового сегмента.
Для копируемых сегментов часто применяется "ленивая" тактика копирования при записи (copy-on-write). В этом случае выделение сегмента и копирование данных откладывается, родитель и потомок используют один и тот же сегмент в реальной памяти, но в их таблицах этот сегмент помечается недоступным для записи. Совместное использование сегмента для чтения продолжается, пока один из процессов не попытается писать в него. Попытка записи вызовет прерывание-ловушку по нарушению доступа, обработчик этого прерывания обеспечит создание копии сегмента, изменит его базовый адрес в таблице потомка и снимет с сегмента защиту записи.
При выполнении вызова fork копируется также и счетчик команд процесса-родителя. Выполнение потомка, таким образом, начнется с возврата из системного вызова fork, и возникает проблема самоидентификации процесса. Процесс, вернувшийся из системного вызова fork, должен определиться, кто он - родитель или потомок? Семантика вызова fork такова, что он обычно применяется в таком контексте: if ( ( childpid = fork() ) == 0 ) < процесс-потомок >; else < процесс-родитель >;
То есть, вызов возвращает 0 процессу-потомку и идентификатор потомка - процессу-родителю.
В ОС Unix вызов fork является единственным средством создания нового процесса. Поэтому, как правило, ветвь, соответствующая процессу-потомку содержит вызов exec, меняющий программу, выполняемую потомком. Эффект в этом случае буде тот же, что и при выполнении вызова load. Применение именно такой схемы, видимо, объясняется легкостью передачи ресурсов. Ниже мы покажем структуру отношений системных и пользовательских процессов в Unix.
Ожидание завершения потомка: exitcode = waitchild(pid); процесс-родитель блокируется до завершения процесса-потомка, идентификатор которого является параметром вызова (или всего семейства, возглавляемого этом потомком, или любого из членов этого семейства). Вызов может возвращать код завершения процесса-потомка (задается вызовом exit) и идентификатор завершившегося потомка. Разумеется, применение этого вызова имеет смысл только при асинхронном запуске потомка.
Выход из процесса: exit(exitcode); приводит к освобождению занятых процессом ресурсов, в том числе, и ресурса памяти. Ресурсы, запрошенные процессом динамически, требуют явного освобождения процессом (например, процесс должен закрыть все открытые им файлы), но если процесс "забыл" это сделать, это сделает за него ОС при выполнении данного вызова. При выполнении exit также могут выполняться процедуры, заданные вызовами exitlist (см. ниже). Вызов exit не обязательно должен приводить к немедленному полному уничтожению процесса. Может сохраняться соответствующая ему запись в таблице процессов и часть блока контекста, но процесс помечается завершенным. Неполное удаление процесса объясняется тем, что после процесса остается еще некоторая информация, которая может быть востребована, статистические данные о его выполнении, код завершения (параметр вызова exit), который будет прочитан вызовом waitchild в родителе и т.п. Полное удаление процесса произойдет после того, как вся остаточная информация будет обработана.
Формирование списка выхода: exitlist(procaddr); при помощи этого вызова процесс может установить процедуру (адрес такой процедуры - параметр вызова), которая должна быть выполнена при его завершении. Процедуры выхода обычно используются для сохранения параметров программы и аккуратного закрытия каких-либо важных ресурсов при аварийном завершении программы. Процесс может сделать несколько вызовов exitlist, назначив несколько процедур выхода, которые будут выполняться в неопределенном порядке. Процедура выхода может также иметь параметр, через который ей будет передаваться причина завершения: нормальное / по сигналу / по программной ошибке / по аппаратной ошибке.
Принудительное завершение: kill(pid); завершает процесс-потомок или все семейство процессов, им возглавляемое. Выполнение этого вызова заключается в выдаче сигнала kill (механизм сигналов описывается в главе 9), по умолчанию обработка этого сигнала вызывает выполнение exit с установкой специального кода завершения.
Изменить приоритет: setPriority ( pid, priority ); изменяет приоритет потомка или всего его семейства. Приоритет может задаваться как абсолютный, так и в виде приращения (положительного или отрицательного) к текущему приоритету. Как правило, пользовательские процессы не могут изменять свой приоритет в сторону увеличения.
Получение идентификаторов: pid = getpid(mode); вызов возвращает процессу его собственный идентификатор и/или идентификатор процесса-родителя.
На Рисунке 4.2 приведена в качестве примера схема наследования процессов в ОС Unix. Корнем дерева процессов является процесс init, создаваемый при загрузке ОС. Процесс init порождает для каждой линии связи (терминала) при помощи пары системных вызовов fork-exec свой процесс getty и переходит в ожидание. Каждый процесс getty ожидает ввода со своего терминала. При вводе процесс getty сменяется (системный вызов exec) процессом logon, выполняющим проверку пароля. При правильном вводе пароля процесс logon сменяется (exec) процессом shell. Командный интерпретатор shell (подробнее мы рассмотрим его в главе 12) является корнем поддерева для всех процессов пользователя, выполняющихся в данном сеансе. При завершении сеанса shell завершается (exit), при этом "пробуждается" init и порождает для этого терминала новый процесс getty.
Дисциплины планирования требования показатели классификация
2.1. Дисциплины планирования - требования, показатели, классификация
В общем случае планирование (на любом уровне) может быть представлено, как система массового обслуживания, показанная на рисунке 2.1. Применительно к планированию процессорного времени, компоненты этой системы могут быть интерпретированы следующим образом: заявкой является процесс, обслуживающим прибором - центральный процессор (ЦП), очередь заявок - это очередь готовых процессов. Процессы-заявки поступают в очередь, при освобождении ЦП один процесс выбирается из очереди и обслуживается в ЦП. Обслуживание может быть прервано по следующим причинам: выполнение процесса завершилось; процесс запросил выполнение операции, требующей ожидания какого-либо другого ресурса; выполнение прервано системой.
Дополнительные возможности
Среди действий, которые может выполнять пользователь, есть и такие, которые не связаны с конкретным объектом, а относятся к большой группе объектов или даже ко всей системе в целом, например, выполнение тех или иных команд, создание объектов определенного типа и т.п. Возможность выполнять такие действия иногда называют полномочиями (authority), для присваивания и учета полномочий существуют специальные механизмы. Независимо от того, как представляется информация о правах доступа субъектов к объектам, список полномочий связывается обязательно с профилем пользователя, так как нет возможности связать его с объектом. Впрочем, в системах, последовательно реализующих объектно-ориентированный подход, полномочия, точнее - средства, через которые они реализуются (команды, системные вызовы) сами являются объектами, для доступа к ним назначаются права, как и для других объектов, поэтому здесь нет необходимости выделять их в отдельную категорию.
Для большинства задач управления доступом может оказаться удобной интеграция некоторого подмножества объектов и связанных с ними подмножеств возможностей в единый элемент, называемый доменом (domain). Если несколько субъектов имеют доступ к одному и тому же набору объектов, причем, с одинаковыми правами, то говорят, что субъекты работают в одном домене. Домены представляют собой удобное средство для сокращения представления информации о защите: в списке возможностей, например, перечисление ряда объектов может быть заменено идентификатором домена, который эти объекты составляют. Домены могут быть пересекающимися. Субъект может работать в нескольких доменах одновременно. Концепция доменов широко используется в современных ОС.
Различаются домены системные и специфицируемые. Системные домены являются предустановленными и неизменяемыми. С системными доменами связываются классы пользователей: принадлежность пользователя к тому или иному классу разрешает пользователю работать в том или ином домене. Обычно в системные домены входят объекты и соответствующие полномочия, позволяющие выполнять, например, управление системой. Простейший пример пользовательских классов - обычный пользователь и привилегированный (суперпользователь). Домен привилегированного пользователя охватывает все объекты системы со всеми правами доступа к ним. Предустановленный домен обычного пользователя разрешает ему доступ к такому подмножеству объектов и возможностей, оперируя которыми он не может вывести из строя ОС или повредить другим пользователям. Дополнительные права обычного пользователя обеспечиваются специфицируемыми доменами и персональными разрешениями.
Специфицируемые домены могут создаваться и конфигурироваться динамически. Во всех ОС пользователи, разделяющие специфицированный домен, объединяются в группы. ОС поддерживает список групп и с каждой группой связывает отдельный домен. В примере раздела 7.7 мы видели, что Unix различает "группу, в которую входит владелец файла". В более развитых системах защиты пользователь может включаться в несколько групп, и домены групп могут пересекаться. Состав пользователей в группе, состав и возможности домена группы могут изменяться администратором или теми, пользователями, которые имеют на это право. Группам могут даваться также и полномочия. С точки зрения представления информации о безопасности группа выступает как один пользователь, и для каждой группы создается собственная запись в базе профилей. Вместо того, чтобы в список прав включать отдельные записи для всех членов какой-то группы, в список заносится единственная запись для всей группы. Имеются обычно также и системные, предустановленные группы - такие как системные администраторы, операторы и т.п., но состав системных групп может меняться динамически.
Объединение объектов составляет группу объектов, права доступа в которой ко всем объектам одинаковы. Права могут быть разные для разных пользователей и групп, но каждый пользователь имеет одни и те же привилегии в ко отношении всех объектов группы. Так же, как и группы пользователей, группы доступа позволяют сократить объем информации по безопасности, представляя всю группу доступа как один объект.
Еще одним средством сокращения объема такой информации являются интегрированные права, сформированные из нескольких элементарных прав, например, право данных - права читать и изменять данные.
Среди стандартных прав может быть также право Exclude, явный запрет на доступ к объекту. Записи о правах Exclude размещаются первыми в списках информации о безопасности, таким образом, при поиске они находятся в первую очередь.
В разделе 10.2 мы упоминали о возможности работы в системе "гостя". "Гость" не может иметь никаких индивидуальных или групповых прав, так как он не зарегистрирован в базе профилей, но некоторые объекты в системе могут быть для него доступны. Говоря шире, в системе могут быть объекты, доступные для всех. Права доступа "для всех" называются публичными (public), они реализуются либо в специальной группе пользователей PUBLIC (гости получают идентификатор безопасности этой группы), либо специальным разделом публичных прав в списках прав объектов и групп доступа.
С учетом перечисленных компонентов системы безопасности, процедуры авторизации выполняется в следующей последовательности: поиск в индивидуальных правах пользователя; поиск в групповых правах пользователя; поиск в публичных правах.
Поиск прекращается, если на любом из этапов будут найдены права, соответствующие запрошенному доступу, доступ разрешается. Поиск прекращается, если на любом из этапов будет найдено право Exclude, доступ не разрешается. Если права, соответствующие запрошенному доступу, не найдены, доступ не разрешается. Индивидуальные права, таким образом, имеют приоритет над групповыми, а групповые - над публичными.
В ряде случаев пользователю может понадобиться выполнить какую-либо корректную задачу, включающую в себя доступ к тем системным объектам, к которым процесс права доступа не имеет. Для выполнения этой задачи ОС предоставляет в распоряжение пользователя процесса программы-утилиты, которые гарантируют корректность манипуляций с защищенными объектами. Но если такая утилита будет выполняться в контексте процесса пользователя, то есть, с его идентификатором безопасности, то в доступе ей будет отказано. Для решения этой проблемы применяется, так называемый, адаптивный доступ (adopted access). В дескрипторе исполняемого модуля - системной утилиты сохраняется признак, по которому ОС на время выполнения (только не время выполнения!) такого модуля предоставляет процессу, его вызвавшему, те же права, которые имеет создатель утилиты (привилегированный пользователь). Поскольку права предоставляются только на время выполнения утилиты, вызвавший ее пользователь этими правами воспользоваться не может.
Еще одно требование к системе безопасности - возможность контроля связанных с безопасностью событий, таких как вход в систему, попытки доступа к объектам (разрешенные или отклоненные), попытки использования полномочий и т.д. Контроль заключается в том, что информация о таких событиях сохраняется в системном журнале аудита и может быть впоследствии проанализирована системным администратором. Администратор имеет возможность задавать события и выбирать объекты, подлежащие контролю. Такой контроль обеспечивается списками контроля доступа, которые подобны спискам прав. Элемент такого списка для объекта содержит вид доступа, который подлежит протоколированию, и результат авторизации. После любого выполнении процедуры авторизации происходит поиск в списке контроля доступа, и, если найден элемент, в котором вид доступа и результат авторизации совпадают с произошедшим, в журнал аудита заносится отметка о событии (включая время и идентификатор пользователя).
Любые действия ОС по обеспечению безопасности (внутренние действия) не дадут желаемого эффекта, если они на будут поддержаны внешними действиями - системой организационных мероприятий, выполняемых администраторами системы, пользователями и их руководителями. Рассмотрение внешних действий по обеспечению безопасности не входит в наши задачи, упомянем только, что введение в эту область можно найти в [8, 20].
Драйвер клавиатуры
Драйвер клавиатуры.
Этот драйвер предназначен для ввода символов с клавиатуры терминала. В большинстве аппаратных архитектур нажатие любой клавиши на клавиатуре вызывает прерывание. Обработчик этого прерывания в типовом случае выполняет: чтение кода клавиши и перевод его в код символа; запоминание кодов символов в своем буфере; распознавание специальных клавиш или/и комбинаций клавиш (например, Ctrl+Break) и вызов специальных их обработчиков; обработку специальных клавиш редактирования содержимого буфера (например, Backspace).
Большинство драйверов позволяют пользователю терминала производить упреждающий ввод данных - до того, как на них поступит запрос из программы. Введенные данные становятся доступными для чтения при нажатии клавиши ввода. Код этой клавиши сохраняется в буфере как признак конца строки. При поступлении запроса на чтение данных с клавиатуры драйвер выбирает из буфера строку - до признака конца строки. Если этот признак отсутствует, то процесс, выдавший запрос, блокируется до появления законченной строки в буфере драйвера. Некоторые драйверы запоминают введенные строки в стеке и обрабатывают также специальные клавиши, позволяющие выбирать строки из стека.
Драйвер системных часов
Драйвер системных часов.
Вычислительные системы имеют один или два таймера. Обязательным является линейный таймер, генерирующий прерывания центрального процессора через фиксированные интервалы времени. Возможен также работающий независимо от линейного программируемый таймер, который генерирует однократное прерывание через заданный интервал времени от момента задания. Прерывания такого таймера иногда называются сигналом тревоги. Если программируемый таймер отсутствует, он может моделироваться при помощи интервального таймера и программных средств.
Драйвер линейного таймера осуществляет обработку его прерываний и в типовом случае может выполнять следующие действия по каждому прерыванию: модифицировать системные структуры данных службы времени и даты; увеличивать счетчик виртуального времени активного процесса; если планирование процессов ведется с квантованием времени, уменьшать счетчик кванта активного процесса и, если счетчик обратился в ноль, вызывать планировщик; если не используется программируемый таймер - уменьшать счетчик тревоги и, если он обратился в ноль, вызывать системную задачу, ожидающую этого сигнала. Линейный таймер может поддерживать целый список таких сигналов тревоги, используемых разными процессами и системными службами, временные выдержки могут задаваться для обеспечения протоколов обмена, измерения производительности системы и т.п.
Драйверы дисковых запоминающих устройств
Драйверы дисковых запоминающих устройств.
Обычной функцией такого драйвера является перевод виртуального адреса на диске в реальный (физический). Физический адрес на диске состоит из трех компонент: головка, дорожка, сектор (в дисковых архитектурах без разбиения на сектора - смещение на дорожке). Драйвер же формирует для процессов виртуальный диск, представляемый как линейная последовательность секторов, виртуальным адресом является номер сектора.
Интересной функцией дискового драйвера может быть планирование запросов на ввод-вывод с целью повышения эффективности обмена. В соответствии со структурой физического адреса доступ к данным на диске состоит из трех этапов - выборок составляющих этого адреса: выбора головки, выбора дорожки и выбора сектора. Выбор головки чтения/записи производится простым электрическом переключением практически мгновенно. Выбор дорожки - самый времяемкий этап: он требует механического перемещения головок к требуемой дорожке; время этого перемещения зависит от расстояния перемещения. Выбор сектора на дорожке требует ожидания момента, когда требуемый сектор окажется под головкой (за счет вращения диска), время выбора сектора много меньше времени выбора дорожки.
Драйвер упорядочивает очередь запросов таким образом, чтобы минимизировать среднее время поиска дорожки. Обсуждение стратегий обслуживания мы далее ведем, исходя из предположения о случайном распределении запросов по пространству диска. Обслуживание очереди по дисциплине FCFS, очевидно, приведет к хаотическому перемещению головок и в результате - к невысокой пропускной способности драйвера и значительным механическим нагрузкам на дисковод. Из дисциплин обслуживания, позволяющих повысить пропускную способность, наиболее известными являются следующие: SSTF (shortest seek time first - с наименьшим временем поиска - первый) - следующим обслуживается запрос к ближайшей дорожке; эта стратегия обеспечивает весьма высокую пропускную способность, но при высоких нагрузках с высокой вероятностью допускает бесконечное откладывание запросов, обращенных к крайним на диске дорожкам; Scan - сканирование - головка движется в одном направлении, применяя на этом направлении SSTF, то есть, обслуживается ближайший запрос на выбранном направлении, когда в этом направлении не остается запросов, направление меняется; стратегия обеспечивает высокую пропускную способность и исключает бесконечное откладывание, но при высоких нагрузках время ожидания запросов, обращенных к крайним дорожкам, существенно превышает среднее; N-Scan - многошаговое сканирование - головка движется в одном направлении, применяя на этом направлении FCFS, обслуживаются те запросы на выбранном направлении, которые поступили на момент начала движения, запросы, поступившие после этого момента, будут обслужены при обратном движении; стратегия обеспечивает лучшие показатели справедливости обслуживания при некотором увеличении среднего времени обслуживания; C-Scan - циклическое сканирование - такая модификация стратегии Scan, в которой головка движется всегда в одном направлении, а после обслуживания последнего на направлении запроса скачком перемещается к самому дальнему запросу; стратегия полностью исключает дискриминацию крайних дорожек даже при высоких нагрузках.
Авторы, приводящие результаты исследования функционирования этих стратегий на моделях [8, 27], рекомендуют стратегию Scan при малых нагрузках и C-Scan - при больших.
Совместно с любым методом сокращения времени выбора дорожки может применяться алгоритм минимизации задержки от вращения диска SLTF (shortest latency time next - с наименьшим временем задержки - первый): при наличии нескольких запросов к одной дорожке они упорядочиваются таким образом, чтобы все они могли быть обслужены за один оборот диска.
Другим примером функций, возлагаемых на драйвер дисков, может быть поддержка RAID-технологий - использование избыточных дисковых устройств для обеспечения возможности восстановления данных при сбоях. В настоящее время имеется широкий спектр реализаций RAID-технологий - от полного переноса их на аппаратуру ввода-вывода до полной реализации их в драйвере.
Другие уровни планирования
2.4. Другие уровни планирования
Выше мы сосредоточились только на краткосрочном планировании. Методы, рассмотренные нами, могут применяться и на других уровнях планирования. Не всегда, правда, можно провести четкую границу между уровнями планирования. Те или иные методы вычисления приоритета доступа к другим (кроме ЦП) ресурсам могут использоваться для формирования динамической добавки к приоритету процесса в очереди готовых процессов или/и влиять на параметры дисциплины планирования (как мы видели для ОС VM/370, где в планировании ВМ учитываются и соображения управления памятью).
В тех случаях, когда среднесрочное планирование осуществляется отдельными планировщиками соответствующих ресурсов, применяются обычно базовые дисциплины планирования без вытеснения, поскольку планируемые ресурсы часто не являются повторно используемыми. Дисциплина SJR применяется обычно к тем ресурсам, которые являются для системы узким местом, для повышения пропускной способности; дисциплина FCFS - в тех случаях, когда крайне важно избежать бесконечного откладывания. При среднесрочном планировании ведущую роль играют соображения предупреждения тупиков, рассматриваемые нами в главе 4.
Долгосрочное планирование может также рассматриваться как вариант среднесрочного: новый процесс ожидает получения ресурсов (а таким ресурсом может быть и свободная запись в системной таблице процессов). В явном виде долгосрочное планирование выполняется в системах пакетной обработки и на уровне не процессов, а заданий. Пакетное задание (batch job) - единица работы с точки зрения пользователя. Задание подразумевает выполнение одного или нескольких процессов. В долгосрочном планировании ведущую роль играют внешние приоритеты, назначаемые пользователем и администратором. Дисциплины обслуживания очереди заданий могут меняться в зависимости от характеристик потока задач, решаемых системой, от привилегий работающих в системе пользователей, от времени суток. Так, для вычислительных центров, работавших в пакетном режиме, было характерным обслуживание в дневное время коротких заданий по дисциплине SJN - чтобы обслужить максимальное число пользователей в течение рабочего дня, а в ночное время - счет длинных заданий, выбираемых по дисциплине FCFS - чтобы обеспечить минимальные потери процессорного времени.
Фиксированные разделы
3.2. Фиксированные разделы.
Эта модель памяти применяется в вычислительных системах, не имеющих аппаратных средств трансляции адресов. Процесс загружается в непрерывный участок памяти (раздел), привязка адресов выполняется при загрузке. Размер раздела равен размеру виртуального адресного пространства процесса, который, следовательно, не может превышать размера доступной реальной памяти. Процесс в ходе своего выполнения может выдавать запросы на выделение/освобождение памяти. Все эти запросы удовлетворяются только в пределах виртуального адресного пространства процесса, а следовательно - в пределах выделенного ему раздела реальной памяти.
Примером ОС, работающей в такой модели, памяти может быть OS/360, ныне уже не применяющаяся, но существовавшая в двух основных вариантах: MFT (с фиксированным числом задач) и MVT (с переменным числом задач). В первом варианте при загрузке ОС реальная память разбивалась на разделы оператором. Каждая задача (процесс) занимала один раздел и выполнялась в нем. Во втором варианте число разделов и их положение в памяти не было фиксированным. Раздел создавался в свободном участке памяти перед началом выполнения задачи и имел размер, равный объему памяти, заказанному задачей. Созданный раздел фиксировался в памяти на время выполнения задачи, но уничтожался при окончании ее выполнения.
В более общем случае для процесса может выделяться и несколько разделов памяти, причем их выделение/освобождение может выполняться динамически (пример - MS DOS). Однако, общими всегда являются следующие правила: раздел занимает непрерывную область реальной памяти; выделенный раздел фиксируется в реальной памяти; после выделения раздела процесс работает с реальными адресами в разделе.
Задача эффективного распределения памяти (в любой ее модели) сводится прежде всего к минимизации суммарного объема "дыр". Ниже мы даем определения дыр, общие для всех моделей памяти.
Дырой называется область реальной памяти, которая не может быть использована. Различают дыры внешние и внутренние. Рисунок 3.2 иллюстрирует внешние и внутренние дыры в системе OS/360.
Философ Чжуан хочет взять палочки
Рисунок 5.2. Философ Чжуан хочет взять палочки, но обнаруживает, что его правая палочка занята философом Мо. Чжуан ожидает. Тем временем философ Мэн берет свои палочки и начинает есть. Мо есть заканчивает, но Чжуан не может начать есть, так как теперь занята его левая палочка. Если Мо и Мэн едят попеременно, то Чжуан попадает в положение, которое называется голоданием (starvation) или бесконечным откладыванием.
Физическая структура файлов
7.6. Физическая структура файлов
До этого уровня ФС оперировала с виртуальными адресами в файле - относительными номерами байт или записей. Уровень физической структуры выполняет перевод реальных адресов в физические адреса на носителе. На этот уровень ложатся все задачи, связанные с управлением распределением реальной внешней памяти. Внешняя память может включать в себя как устройства произвольного доступа (в дальнейшем - диски), так и устройства последовательного доступа (в дальнейшем - ленты). Мы сосредоточимся здесь только на дисковой памяти, имея в виду то обстоятельство, что задачи управления памятью на лентах составляют лишь узкое подмножество задач, возникающих при управлении дисками.
Несколько принципиально важных положений являются общими для любых способов управления дисковой памятью. Дисковая память состоит из блоков, являющихся единицами распределения дискового пространства (например, секторов). Каждый блок имеет уникальный номер (адрес), его идентифицирующий. В каждый блок может быть записана любая информация достаточно сложной структуры, в том числе, и содержащая ссылки на другие блоки. Каждый физический диск описывается дескриптором диска, который содержит информацию о количестве и размере блоков на диске и о свободном пространстве на диске. Дисковый дескриптор записывается на известное заранее место на диске (чаще всего - в первый блок). Каждый файл в составе своего дескриптора имеет план своего размещения (layuot) на физическом пространстве диска. Информация, записываемая на диск, может быть избыточной для обеспечения возможности ее восстановления при сбоях. Дисковое пространство распределяется блоками фиксированной длины. Даже в тех дисковых архитектурах, которые допускают чтение/запись блоками переменной длины, размер единицы распределения, как правило, все равно фиксирован, например, дорожка. Возможно объединение в единицу распределения нескольких смежных блоков, такой прием носит название кластеризации (clastering), а порции распределения, состоящие из нескольких блоков, называются кластерами. Кластеризация может быть как симметричной - с заранее установленным размером кластера, так и асимметричной - с размером кластера, выбираемым для каждого распределения. Поиск на диске управляющих структур ФС и свободных блоков может оказаться слишком времяемким. Поэтому те управляющие структуры, обращение к которым происходит наиболее часто, обычно копируются в оперативную память. Это создает дополнительные проблемы, связанные с надежностью функционирования ОС. При крахе системы изменения в управляющих структурах могут не быть перенесены из кеша на внешнюю память. Специальные системные процессы ОС обычно обеспечивают периодическое сохранение управляющих структур на внешней памяти.
Выше мы указывали на наличие в файловом дескрипторе плана размещения файла. Отметим прежде всего, что поскольку дескриптор представляет собой одинаковую для всех файлов структуру данных, то размер его должен быть фиксированным. Не во всех случаях план размещения файла может иметь фиксированную длину. Если не удается добиться фиксированной длины плана, то переменная его часть может быть вынесена из файлового дескриптора. Вид представления плана зависит от способа распределения файлам дисковой памяти.
Распределение дисковой памяти может быть классифицировано как смежное или не смежное. В первом случае файлу распределяется непрерывный участок внешней памяти, во втором - файл может быть разбросан по пространству диска. Смежное распределение весьма привлекательно по нескольким причинам. Во-первых, план размещения в этом случае получается простейшим: он состоит только из номера начального блока и количества блоков. Во-вторых, и это более важно, смежное размещение обеспечивает высокую степень локализации обращений к дорожкам при обработке файла и, следовательно, высокую эффективность обмена. Однако, и недостатки смежного распределения более чем серьезны. Во-первых, как и при распределении оперативной памяти блоками переменной длины, здесь возникают все проблемы фрагментации пространства памяти (внешних дыр). Во-вторых, такое распределение требует, чтобы необходимый размер дискового пространства указывался при создании файла - эта информация не всегда может быть предоставлена пользователем, создающим файл. В-третьих, расширение файла за пределы установленного размера невозможно - для файлов с длительным сроком существования эта проблема может стать критической. Перечисленные недостатки могут быть не радикально преодолены, но несколько сглажены, если допустить, чтобы файл занимал не один, а несколько участков дискового пространства. При создании такого файла задаются требования к размеру первичного и вторичного распределения. Файлу выделяется непрерывный участок памяти в соответствии с первичным размером. Если далее оказывается, что файл не помещается в первичный участок, ему выделяется дополнительный участок (экстент - extent), размер которого задается требованием ко вторичному распределению. Экстент занимает непрерывную область на диске, но необязательно смежную с первичным участком. Затем может быть выделен второй экстент и т.д. План файла в его дескрипторе в этом случае представляется массивом пар "начальный адрес - длина", каждый элемент которого соответствует одному экстенту. Размер этого массива в дескрипторе ограничивает допустимое число экстентов.
Очевидно, что смежное распределение является негибким. Это в первую очередь послужило причиной полного отказа от него в ОС Unix и в MS DOS. Однако, в связи с увеличением объемов дисковых накопителей вопросы повышения эффективности обмена приобретают все большее значение и локализация файлов является хорошим средством повышения этой эффективности. В последнее время наметилась тенденция к размещению файлов в смежных областях диска, пусть даже и в рамках несмежной модели распределения (см., например описание ФС HPFS, NTFS, Veritas, JFS в Части II).
Практически все системы, использующие несмежную модель имеют в своем наборе утилит такие, которые производят реорганизацию дисков, переписывая файлы таким образом, чтобы они располагались в смежных блоках.
Несмежное распределение допускает, чтобы файл состоял из большого числа участков (отдельных блоков), и план файла должен описывать размещение каждого из блоков файла. Можно выделить три основных подхода к представлению плана файла в несмежной модели: списки блоков; карта размещения; списки указателей на блоки.
Метод списков блоков предполагает, что в файловом дескрипторе содержится только указатель на первый выделенный файлу блок. В самом блоке на фиксированном месте содержится указатель на второй блок, во втором - на третий и т.д. Таким образом, блоки выстраиваются в односвязный линейный список. С учетом того, что список располагается на внешней памяти, этот метод может применяться только для файлов с последовательным доступом.
Метод карты размещения хорошо известен программистам в MS DOS по Таблице размещения файлов FAT. ФС для каждого диска поддерживает таблицу, каждая строка которой описывает один блок на диске. В списки связываются не сами блоки, а соответствующие им элементы карты. Карта размещения обеспечивает достаточно простой и эффективный метод управления распределением, но сосредоточение информации о размещении всех файлов в одной структуре данных делает эту структуру узким местом ФС с точки зрения безопасности.
Метод списков указателей на блоки предполагает, наличие для каждого файла перечня номеров блоков, ему распределенных. Этот перечень записывается в отдельный блок, специально выделяемый для этой цели, а файловый дескриптор содержит указатель на этот блок. Если в блоке не хватает места для всего перечня, то последний в нем номер адресует блок, содержащий продолжение перечня и т.д. При применении этого метода "в чистом виде" список блоков, как всякий линейный список, может обрабатываться только последовательно, поэтому доступ в блокам файла, имеющим большие виртуальные номера может быть значительно замедлен. Поэтому на практике применяются различные модификации этого метода. Классическим примером такого подхода является ФС s5 первых версий ОС Unix.
Учет дискового пространства, выделенного файлу (план размещения), ведется в s5 следующим образом. Как показали исследования, на любом носителе всегда есть большое число файлов, объем которых не превышает 1 Кбайт. Для таких файлов нет никакой необходимости выделять отдельные блоки для размещения плана, а тем более - увязывать эти блоки в какие-либо списки. Поэтому непосредственно в файловом дескрипторе содержится массив из 10 номеров первых блоков файла. При размере блока 512 байт первые 5 Кбайт файла адресуются непосредственно из файлового дескриптора. Одиннадцатый элемент этого массива содержит адрес блока, в котором записано еще 128 номеров следующих блоков файла. Таким образом, доступ к следующим 64 Кбайтам файла производится путем косвенной адресации из дескриптора через этот блок адресов. Двенадцатый элемент содержит адрес блока, в котором записано еще 128 номеров блоков, каждый из которых адресует еще 128 блоков данных файла - это обеспечивает доступ к следующим 8 Мбайтам путем двухуровневой косвенной адресации. Наконец, тринадцатый элемент массива в дескрипторе обеспечивает доступ через трехуровневую косвенную адресацию еще к 2 Гбайтам файла. Структура плана размещения показана на Рисунке 7.4.
Функции управления памятью
Рисунок 3.1. Функции управления памятью
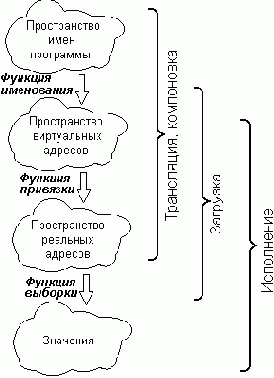
Функция именования производит отображение точки из пространства имен программы в пространство адресов в виртуальной памяти, иными словами - переводит символьные имена, используемые программистом, в виртуальные адреса.
Функция привязки производит отображение точки из пространства виртуальных адресов в пространство реальных адресов, то есть, переводит виртуальные адреса в адреса физических ячеек памяти.
Функция выборки отображает точку из пространства реальных адресов в значение, то есть, выбирает содержимое памяти по заданному адресу.
Функция именования реализуется по большей части обслуживающими программами, мы рассматриваем ее в следующей главе. Функция выборки всегда реализуется аппаратно. В данной главе нас будет интересовать прежде всего функция привязки адресов. Относительно нее конструктором ОС должен быть решен основной вопрос: на каком этапе подготовки/выполнения программы ее выполнять?
Программист может писать программу, сразу привязывая ее к заведомо известным адресам физической памяти, - это называется программированием в абсолютных адресах. Такое программирование выполняется в специфических случаях, например, для программ, записываемых в ПЗУ. Даже в таких случаях программист часто пользуется символическими именами, возлагая задачу перевода имен в физические адреса на транслятор. Полученная таким образом программа называется абсолютной или неперемещаемой. Она может выполняться только, будучи загруженной по определенному адресу оперативной памяти.
Все прикладные программы и подавляющее большинство системных программ являются перемещаемыми. Это значит, что в программе, подготовленной к выполнению (в том образе программы, который хранится на внешней памяти), обращения к памяти настроены на виртуальные адреса, не привязанные пока к адресам реальной памяти.
Выполнение функции привязки адресов может быть перенесено на этап загрузки. Простейшим вариантом такой системы трансляции является тот, в котором виртуальный адрес представляет собой смещение относительно начала программы, а при загрузке программы в память ко всем виртуальным адресам прибавляется начальный адрес области, в которую программа загружена. Другой вариант - виртуальная адресация производится относительно содержимого некоторого базового регистра, в который при загрузке заносится базовый адрес. Программы, подготовленные таким образом, называются перемещаемыми при загрузке - они могут быть загружены в любую область оперативной памяти, но после загрузки должны оставаться на том же месте в памяти.
Наконец, привязка адресов может делаться уже на этапе выполнения программы. Программа (процесс) обращается к памяти только по виртуальным адресам, а перевод виртуального адреса в реальный производится только при обращении по этому адресу. Между двумя обращениями по одному и тому же виртуальному адресу процесс может быть перемещен операционной системой в другую область реальной памяти. Системные средства, ответственные за привязку адресов, будут "знать" о произведенном перемещении и при втором обращении привяжут тот же виртуальный адрес к новому реальному адресу. Поскольку виртуальный адрес не изменился, то перемещение оказалось совершенно прозрачным для процесса, такие процессы называются перемещаемыми динамически. При такой трансляции адресов привязка выполняется при каждом обращении к памяти, то есть, очень часто. Поэтому естественным решением является выполнение этой функции на аппаратном уровне. Аппаратура переводит виртуальные адреса в реальные, используя некоторые таблицы трансляции. Подготовка таблиц трансляции адресов - операция, выполняемая для процесса одноразово, модификация их производится также нечасто (при перемещении процесса), поэтому задача формирования и модификации таблиц трансляции возлагается на ОС.
Отметим, что иногда виртуальной памятью называют именно эти свойства аппаратуры вычислительной системы и вытекающие из них возможности для процессов работать с виртуальным адресным пространством большего размера, чем размер имеющейся в системе реальной памяти. Мы же следуем более широкой интерпретации [13]: виртуальная память это то адресное пространство, в котором разрабатывается процесс. Такое понимание соответствует определению ОС "с точки зрения пользователя", которое мы дали в разделе 1.4. В данном случае ОС скрывает от процесса организацию низкоуровневого ресурса (реальной памяти) и конструирует ресурс более высокого уровня (виртуальная память), более удобный в обращении. Такая интерпретация не принимает во внимание, на каком этапе - загрузки или выполнения - производится трансляция адресов, и имеется ли в системе аппаратная поддержка этой трансляции. В частном случае размер виртуальной памяти может быть и меньше реальной.
Разработка программ, работающих в виртуальном адресном пространстве, имеет целый ряд преимуществ, которые можно сгруппировать по трем основным направлениям. Удобство для программиста. Программист имеет в своем распоряжении виртуальную память, представляющую собой адресное пространство либо совершенно плоское - с адресами, линейно возрастающими от 0 до максимального значения, либо сегментированное в соответствии с потребностями задачи. При этом он не заботится о том, как будет размещен его процесс в реальной памяти, ОС может отобразить виртуальную память в реальную даже таким образом, что смежные участки виртуального адресного пространства будут отображаться в несмежные участки реальной памяти. Каждый процесс разрабатывается в собственном адресном пространстве, независимом от пространств других процессов. Реорганизация памяти. Системные средства управления памятью могут выбрать такое отображение виртуальной памяти в реальную, которое обеспечит максимально эффективное использование ресурса реальной памяти. В случае, когда обеспечивается динамическая трансляция адресов, реорганизация ресурса реальной памяти может производиться и в ходе выполнения процесса, причем совершенно прозрачно для последнего. Защита. Процесс никак не может обратиться за пределы своего виртуального адресного пространства. Если ОС обеспечивает отображение таким образом, что виртуальные пространства двух любых процессов не могут перекрывать друг друга в реальной памяти, то никакой процесс не будет иметь доступа к адресному пространству другого процесса.
При наличии аппаратной поддержки системы виртуальной памяти позволяют работать с виртуальными адресными пространствами, размер которых превышает доступный размер оперативной памяти. Это достигается за счет хранения части программ и данных на внешней (дисковой) памяти и управления миграцией данных между оперативной и внешней памятью. Современные вычислительные системы следуют тенденции вводить кэширование между двумя этими уровнями памяти. В ОС Unix, например, тотальное кэширование обеспечивается самой ОС для любого обмена с дисками, следовательно, работает оно и для данных, перемещаемых при управлении памятью. В вычислительных системах ESA имеется два аппаратных промежуточных уровня памяти: расширенная память, которая включается в пространство реальных адресов, но используется только как буфер обмена и собственная буферная память дискового запоминающего устройства. (Расширенная память, может быть выполнена как на тех же элементах, что и основная оперативная память, так и на специальных - не столь быстродействующих, но дешевых).
Многоуровневая память строится обычно по иерархическому принципу. Это означает, что для каждого следующего уровня время доступа больше, чем для предыдущего: t[i] > t[i-1], и объем больше: V[i] > V[i-1]. Последнее обстоятельство делает возможным дублирование информации на уровнях: если данные имеются на i-ом уровне, то их копии сохраняются и на всех уровнях с большими номерами. Обозначим через h[i] отношение присутствия - вероятность того, что данные, запрошенные на i-ом уровне памяти, уже имеются на этом уровне. Если мы имеем n уровней памяти, то для n-го уровня отношение присутствия равно 1 и среднее время доступа tav[n] совпадает с t[n]. Для всех уровней с меньшими номерами среднее время доступа может быть определено рекурсивно: tav[i] = h[i] * t[i] + ( 1 - h[i] ) * tav[i-1].
На программном уровне мы не можем воздействовать ни на t[i], ни на V[i], которое в значительной степени определяет и h[i]. Но мы можем влиять на величину h[i], выбирая для хранения на уровне с меньшим номерам только те данные, обращение к которым производится наиболее часто.
В общем случае проектирование менеджера памяти в составе ОС требует выбора трех основных стратегий: стратегии размещения: какую область реальной памяти выделить процессу? как вести учет свободной/занятой реальной памяти? стратегии подкачки: когда размещать процесс (или часть его) в реальной памяти? стратегии вытеснения: если реальной памяти не хватает для удовлетворения очередного запроса, то у какого процесса отобрать ранее выделенный ресурс реальной памяти (или часть его)?
Ниже мы рассмотрим способы реализации этих стратегий для различных моделей памяти. Порядок рассмотрения будет соответствовать принципу "от простого к сложному" и в основном отображать также и историческое развитие моделей памяти: фиксированные разделы - модель, не использующая аппаратную трансляцию адресов; односегментная виртуальная память - развитие фиксированных разделов для аппаратной трансляции адресов. модели виртуальной памяти, использующие развитые средства аппаратной трансляции адресов; многосегментная; страничная; комбинированная сегментно-страничная. модели виртуальной памяти, представляющие собой возврат к простым моделям, но на более высоком уровне: плоская; одноуровневая.
Основные понятия
Глава 1
Основные понятия
Планирование процессов
Глава 2
Планирование процессов
В предыдущей главе мы определили три уровня планирования, теперь остановимся более подробно на стратегиях или дисциплинах планирования. Многие дисциплины применимы на любых уровнях планирования, но мы сосредоточим внимание прежде всего на планировании краткосрочном или планировании процессорного времени. Процессорное время является ключевым ресурсом любой вычислительной системы, и наличие или отсутствие этого ресурса в распоряжении процесса отличает активное состояние процесса от остальных его состояний. Дисциплины распределения этого ресурса в значительной степени определяют эффективность функционирования всей системы в целом.
Управление памятью
Глава 3
Управление памятью
Порождение программ и процессов
Глава 4
Порождение программ и процессов
В первой главе мы дали строгое определение понятия процесса. Прикладной программист, однако, разрабатывает не "процесс", а "программу", не задумываясь обычно над тем, как и какие механизмы ОС обеспечат ее представление в виде процесса. Ряд авторов (например, [8, 9]) нестрого определяют процесс как "программу в стадии выполнения". Такое определение, "адаптированное" для уровня прикладного программиста, в ряде случаев может считаться справедливым и весьма удобным, так как соответствует интуитивному пониманию этого термина.
Программа превращается в процесс в тот момент, когда ОС создает для нее блок контекста. Блок контекста отвечает за состояние процесса и представляет процесс в состязаниях за обладание ресурсами. Блок контекста, однако, не определяет содержание процесса. Содержательная часть процесса представляется для ОС другой структурой - адресным пространством процесса. Ядро ОС не обрабатывает содержимое адресного пространства, а только отвечает за размещение его в памяти.
В первых двух разделах данной главы мы рассматриваем начальное формирование содержимого адресного пространства - этапы компиляции, компоновки и загрузки. Эти этапы в терминах функций управления памятью (Рисунок 3.1) выполняют функцию именования. Как правило, эти этапы выполняются не ядром ОС, а утилитами, задолго до создания блока контекста процесса. Таким образом, на этих этапах мы имеем дело не с процессом, а с программой. Два следующих раздела рассматривают управление адресным пространством программы при ее превращении в процесс.
Монопольно используемые ресурсы
Глава 5
Монопольно используемые ресурсы
Управление вводомвыводом
Глава 6
Управление вводом-выводом
Файловые системы
Глава 7
Файловые системы
Параллельное выполнение процессов
Глава 8
Параллельное выполнение процессов
Системные средства взаимодействия процессов
Глава 9
Системные средства взаимодействия процессов
В предыдущей главе мы уже фактически затронули эту тему, однако, средства, которые мы рассматривали, в основном ограничивались теми, которые реализуются самим программистом или компилятором. Здесь мы сосредоточимся на тех средствах, использование которых поддерживается API ОС.
Защита ресурсов
Глава 10
Защита ресурсов
Интерфейс пользователя
Глава 11
Интерфейс пользователя
До сих пор мы рассматривали взаимодействие с ОС, выполняемое из программы при помощи вызовов API - интерфейса прикладного программиста. Теперь рассмотрим взаимодействие вне программы - через команды, вводимые с клавиатуры терминала в интерактивных системах или поступающие во вводном потоке в пакетных системах. В первом случае, как правило, новая команда вводится после выполнения предыдущей, и сама новая команда или ее параметры могут выбираться в зависимости от результатов этого выполнения. Во втором случае задается сразу целая последовательность команд, и возможные отклонения от последовательного их выполнения должны задаваться явным образом. Из таких различий в технологии взаимодействия пользователей с системой вытекают естественные различия в интерактивных и пакетных командных языках, но по мере расширения командных языков они имеют тенденцию к сближению: в интерактивные командные языки включаются возможности задания последовательностей команд, а в пакетные - более гибкие средства управления последовательностью выполнения.
Граф ресурсов и процессов
Рисунок 5.6. Граф ресурсов и процессов

Графы такого рода содержат вершины двух типов - процессы (показаны окружностями) и классы ресурсов (показаны прямоугольниками), в последних указывается число ресурсов в классе. Дуги графа могут соединять только разнотипные вершины. Направленность дуг означает: от ресурса к процессу - ресурс выделен данному процессу, от процесса к ресурсу - процесс запрашивает ресурс. Признаком тупика является наличие в графе петли - такого пути, который начинается и заканчивается в одной вершине и из которого нет выхода. Так, на
Иерархическая модель файловой системы
7.1. Иерархическая модель файловой системы
Файл есть именованная совокупность данных. Это определение относится к виртуальному файлу - каким он представляется пользователю. Определение виртуального файла не конкретизирует, где именно, на каких носителях находятся данные, из каких элементов эта совокупность состоит и каковы отношения между элементами. Отсутствие детализации в определении виртуального файла делает его удобной универсальной метафорой любых внешних по отношению к процессу данных. В ОС Unix впервые было введено представление всех внешних устройств, как виртуальных файлов. Это представление прочно укоренилось и в современных ОС имеется тенденция более широкого использования файловой метафоры. В таких системах, например, имена всех внешних по отношению к процессу именованных данных (семафоры, каналы-транспортеры, очереди т.д.) формируются по соглашениям именования файлов.
Понятие же физического файла связывают с данными, хранящимися на внешней памяти. Устройства внешней памяти предназначены для длительного хранения данных. Файл, созданный на внешней памяти, может существовать на ней сколь угодно долго, пока не будет уничтожен явно заданной операцией уничтожения. Характерным является то, что файл продолжает существовать и после завершения создавшего его процесса, данные файла могут быть многократно прочитаны, модифицированы, полностью заменены этим же или другим процессом. Физический файл есть набор записей на устройстве внешней памяти, сгруппированных таким образом, чтобы управлять доступом к ним, их чтением и модификацией.
Файловой системой (ФС) называется та часть ОС, которая обеспечивает перевод виртуального представления файла в физическое. Этот перевод выполняется поэтапно, что позволяет представить ФС в виде иерархической модели, показанной на Рисунке 7.1.
Рисунок 7.1. Иерархическая модель файловой системы
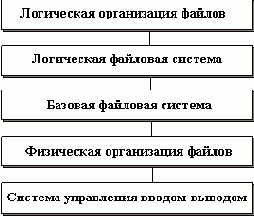
Подсистема логической организации файлов обеспечивает API процессов в соответствии с той логической структурой, которую имеет виртуальный файл.
Логическая ФС выполняет перевод символьного имени файла в некоторый внутрисистемный идентификатор файла. Этот перевод включает в себя поиск по справочникам. Идентификатор обычно представляет собой некоторую простую структуру данных, адресующую дескриптор файла, который используется на следующем уровне иерархии.
Базовая ФС выполняет открытие и закрытие файлов и сопровождение открытых файлов. Базовая ФС находит по идентификатору дескриптор файла - системную структуру данных, содержащую информацию о местонахождении файла, его характеристиках и состоянии. При открытии файла этот уровень создает расширенный дескриптор файла, отслеживающий в ходе работы процессов с файлом его текущее состояние. Базовая ФС, возможно, также контролирует соблюдение прав доступа к файлу.
Подсистема физической организации файлов выполняет перевод виртуальных файловых адресов в реальные адреса на носителях. Этот уровень отслеживает размещение файлов на внешней памяти и управляет распределением пространства внешней памяти.
Система управления вводом-выводом (СУВВ) занимается формированием управляющих воздействий на устройства внешней памяти, их выполнением и обработкой прерываний. Этот уровень обеспечивается драйверами устройств, рассмотренными нами в предыдущем разделе, поэтому здесь мы этот уровень рассматривать не будем. Отметим только, что управление устройствами (любыми, а не только устройствами внешней памяти) является вырожденным случаем иерархической модели, в котором отсутствуют уровень логической ФС, а функции физической организации и управления вводом-выводом реализованы в драйвере.
В следующих разделах мы рассмотрим подробнее уровни ФС, двигаясь сверху вниз по иерархии.
Иерархическое выделение
Иерархическое выделение.
Все классы ресурсов разбиваются по уровням с номерами от 1 до N, каждый уровень содержит только один класс. Процесс имеет право запрашивать ресурсы только из классов с более высокими номерами, чем у тех, которыми он уже владеет. Эта стратегия также предотвращает возникновение тупиков. В каждый момент времени в системе один или несколько процессов имеют класс закрепленных за ними ресурсов выше, чем у других. Эти процессы, обладающие ресурсами высокого уровня, могут беспрепятственно выполняться и завершиться без блокировки. Следовательно, в каждый момент времени имеется хотя бы один способный к выполнению процесс. Если не будут поступать новые процессы, то все процессы, уже имеющиеся в системе, в конце концов завершатся - тупик отсутствует. Хотя в иерархической стратегии процесс ограничен в последовательности запросов и возможна ситуация, в которой он должен удерживать за собой ресурс более длительное время, чем это действительно необходимо, эта стратегия позволяет достичь неплохой эффективности, особенно при правильном распределении ресурсов по уровням. Целесообразно более высокие уровни назначать более дефицитным и более дорогостоящим ресурсам; как правило, и использование таких ресурсов является более скоротечным. Иерархическую стратегию применяет, например, OS/390 применительно к некоторым системным структурам данных.
Иерархическая стратегия является самой либеральной из стратегий, предотвращающих возникновение тупиков без дополнительной информации. Более либеральные стратегии предотвращения требуют предварительного знания о характеристиках процессов.
Интерфейс процесса
6.6 Интерфейс процесса
Как мы уже отметили выше, ОС конструирует для процессов виртуальные устройства высокого уровня. Характерным примером таких устройств являются файлы. Процесс может работать с каждым файлом, как с отдельным устройством, хотя на самом деле файл представляет собой лишь часть дискового пространства. В ОС Unix концепция файла была впервые введена как универсальная метафора устройства. Это позволяет свести все многообразие управления вводом-выводом к единой форме системных вызовов. Ниже приведен набор системных вызовов для работы с устройствами, являющийся практически общепринятым.
Открыть устройство: devHandle = open(devNname, mode)
Этот вызов сообщает драйверу, что процесс будет работать с данным устройством. Вызов является частным случаем вызова getResource, и при его выполнении могут производиться действия по предупреждению или обнаружению тупиков. Процесс может быть заблокирован, если требуемое устройство занято. Могут проверяться права доступа данного процесса к данному устройству. На устройстве могут выполняться какие-то специфические для устройства действия - начальные установки. Параметр mode определяет направление обмена данными с устройством: чтение, запись, чтение/запись, запись в конец. Никакие другие операции с устройством невозможны, если для него не выполнена операция открытия. Манипулятор (handle), возвращаемый системным вызовом open, служит идентификатором открытого устройства во всех последующих операциях с ним.
Закрыть устройство: close(devHandle)
Вызов сообщает драйверу, что процесс закончил работу с устройством. Ресурс-устройство открепляется от процесса, разблокируются другие процессы, ожидающие освобождения этого устройства. На устройстве могут выполняться специфические заключительные операции.
Читать данные из устройства в память: read(devHandle, vAddr, counter)
Это запрос на передачу данных из устройства, идентифицируемого манипулятором devHandle, в задаваемую виртуальным адресом vAddr область адресного пространства процесса. Если на устройстве нет того объема информации, который задан счетчиком counter, может быть передан меньший объем. Вызов обычно возвращает действительный объем переданной информации.
Писать данные из памяти в устройство: write(devHandle, vAddr, counter)
Запрос на передачу данных из заданной области виртуальной адресного пространства процесса на устройство.
Позиционировать устройство: seek(devHandle, position)
Запрос на установку устройства в заданную позицию. Применяется для устройств, имеющих внутреннюю адресацию. По умолчанию вызовы read и write устанавливают устройство в позицию, следующую за прочитанными или записанными данными.
Управление вводом-выводом: ioctl(devHandle, command, parameters)
Запрос на выполнение специфических для устройства операций, не вписывающихся в перечисленные выше системные вызовы. Операция определяется командой command, например: чтение, запись, управление и т.п. Третий параметр задает дополнительные параметры, специфичные для каждой операции.
При реализации системных вызовов read и write перед разработчиком ОС возникает вопрос: блокировать или не блокировать процесс, выдавший системный вызов? Возможна синхронная и асинхронная организация ввода-вывода. При синхронной организации процесс, выдавший запрос на чтение/запись данных, требующий физического обмена данными с устройством, безусловно блокируется. Когда процесс возобновляется, он может быть уверен, что данные, которые он запросил (read), уже находятся в его рабочей области, и он может их использовать, а данные, которые он передал (write), уже пересланы, и он может записывать в область, в которой они находились, другую информацию. Альтернативной является асинхронная организация ввода-вывода, при которой системный вызов read/write только инициирует операцию, далее процесс продолжает выполняться параллельно со вводом-выводом. Параллельное выполнение позволяет повысить эффективность работы как самого процесса, так и всей системы, так как снимает необходимость в переключении процессов, но синхронизация все равно необходима. Если, например, процесс запросил ввод данных, то прежде, чем он начнет их использовать, он должен убедиться, что ввод завершился. Ответственность за такую синхронизацию перекладывается на процесс. Для предоставления процессу возможности синхронизировать свои действия с выполнением операций ввода-вывода ОС обеспечивает процессу виртуальные прерывания, поддерживаемые системными вызовами, описываемыми далее.
Ждать завершения операции на устройстве: wait(devHandle, delay)
Вызов блокирует процесс - переводит его в состояние ожидания до тех пор, пока не поступит виртуальное прерывание, сигнализирующее о завершении операции на устройстве, определяемом devHandle. Если операция к моменту вызова уже завершилась, процесс не блокируется. Параметр delay задает максимально допустимое время, которое процесс может ожидать. Если это время выходит, системный вызов wait заканчивается, возвращая признак ошибки. Это время может быть установлено и бесконечно большим.
Установить обработчик виртуального прерывания от устройства: setHandler(devHandle, procAddr)
Возможность, предоставляемая этим вызовом, обеспечивает полное сходство виртуального прерывания с реальным. При поступлении виртуального прерывания от устройства выполнение процесса прерывается и управление передается на процедуру с адресом procAddr, которую процесс назначил обработчиком виртуального прерывания. Все обработчики виртуальных прерываний должны соответствовать несложным системным спецификациям. Обычно обработчик имеет параметры, через которые ему передается дополнительная информация о виртуальном прерывании. Еще раз подчеркнем, что речь здесь идет именно о виртуальных, а не о реальных прерываниях. Виртуальное прерывание обеспечивается не аппаратными средствами, а моделируется для процесса операционной системой.
Асинхронная организация ввода-вывода предоставляет пользователю больше возможностей для повышения эффективности выполнения процесса, но вместе с тем, и больший простор для ошибок. Характерной, например, может быть такая ошибка, появление которой должно быть предусмотрено в ОС. При записи данных, например, правильной является такая последовательность системных вызовов: write...wait...write...wait... ,
то есть, следующий блок информации не выводится, пока не будет закончен вывод предыдущего. Что произойдет, если последовательность вызовов будет такой: write...write...wait...wait... ?
Если ОС связывает с операцией ввода вывода двоичный флаг, то первый вызов write установит этот флаг в состояние "занято", второй не изменит значение флага. Окончание первой операции вывода сбросит флаг в "свободно", что будет обработано первым вызовом wait, окончание второй операции вывода не повлияет на состояние флага, и второй вызов wait в любом случае найдет флаг в состоянии "свободно". Момент окончания второй операции, таким образом, будет утерян. ОС должна либо расценивать подобную последовательность вызовов как ошибку процесса, либо поддерживать ее, создавая для каждой операции свой флаг.
Интерфейсы устройств
6.2. Интерфейсы устройств
Здесь мы рассматриваем взаимодействия ОС с устройствами, лежащие на уровне "интерфейса оборудования" - вспомните Рисунок 1.2.
При всем многообразии внешних устройств ЭВМ и способов управления ими их программные интерфейсы могут быть сведены к трем основным моделям, определяющимся способом подключения устройств к ЭВМ: регистры устройств; контроллеры ввода-вывода; прямой доступ к памяти; каналы ввода-вывода; процессоры ввода-вывода.
Устройство может быть подключено к процессору через регистры устройства, как показано на Рисунке 6.1. Такое подключение применяется для устройств, которые имеют простое управление, и обмен с ними ведется небольшими порциями данных (байт, слово, двойное слово). Устройство может иметь большое число регистров, которые, однако, сводятся к трем основным типам: регистры состояния - для передачи в процессор информации о состоянии, регистры управления - для передачи на устройство команд, регистры данных - для обмена данными между процессором и устройством. Регистры управления и состояния, как правило, являются однонаправленными, регистры данных могут быть как одно-, так и двунаправленными. Регистры устройств являются расширением адресного пространства ЭВМ. Расширение это может быть как явным - с доступом при помощи команд работы с памятью типа MOV, так и неявным - с отдельной адресацией портов ввода-вывода и доступом при помощи специальных команд типа IN/OUT.
Ядро и процессы
1.5. Ядро и процессы
Прежде чем приступать к изложению основного материала этого раздела, сделаем несколько общих замечаний о принципах управления ресурсами и о представлении их в нашем пособии.
Ядром (kernel) называется часть ОС, выполняющая некоторый минимально необходимый набор функций по управлению ресурсами. Дополнительные функции управления ресурсами выполняются вспомогательными модулями - утилитами. Точное определение ядра дать трудно, так как оно по-разному понимается в разных ОС. В "старых", не работавших с виртуальной памятью системах под ядром обычно понималась часть системы, резидентная в оперативной памяти. В современных ОС ядро резидентно в виртуальной памяти, и это также может служить его классификационным признаком. Более узкое определение, трактующую ядро как часть ОС, которая работает в привилегированном режиме, представляется нам более подходящей для определения микроядра (см. раздел 1.6).
На ядро, как правило, возлагаются такие основные функции: обработка прерываний; создание и уничтожение процессов; переключение процессов из одного состояния в другое; управление памятью; синхронизация и взаимодействие процессов; поддержка операций ввода-вывода (не всегда); учет работы системы и использования ресурсов пользователями; и т.д.
Для ОС процесс представляется блоком контекста процесса (вспомните примечание 3 к определению процесса). Блок контекста содержит информацию о процессе, необходимую для ОС, например: идентификатор пользователя-владельца процесса; информацию для планирования процесса на выполнение; информацию об оперативной и вторичной памяти; информацию о других выделенных процессу ресурсах; информацию об открытых устройствах и файлах; учетную информацию.
Обязательной составляющей блока контекста является вектор состояния процессора. Вектор состояния обязательно хранится в оперативной памяти. Другие составляющие блока контекста могут храниться в разных местах памяти и даже вытесняться на внешнюю память. Действия ОС по управлению процессами сводятся к манипуляциям с блоками контекста процессов и с отдельными полями этих блоков.
Вспомним теперь примечание 1 к определению процесса: процесс в системе может находиться в различных состояниях. Количество состояний процесса разное в разных ОС (так, в ОС Unix различают 9 возможных состояний процесса), но все они сводятся к трем основным, показанным на
Классификация и предварительный обзор операционных систем
1.2. Классификация и предварительный обзор операционных систем
В изданиях, упомянутых выше, классификация совмещается с историческим обзором, показывающим, как со временем увеличивались ресурсы вычислительных систем и соответственно усложнялись функции управления ими. Наряду с этим, нам представляется интересным провести классификацию также и в одном (сегодняшнем) временном срезе.
Мы будем классифицировать ОС по количеству пользователей и количеству задач (процессов), одновременно управляемых системой. Чем вызывается стремление увеличить эти показатели?
Доводы за многопользовательский режим составляют две группы. Во-первых, возьмем на себя смелость утверждать, что сегодня персональный компьютер возможен только как игрушка. Профессиональный программист или пользователь ЭВМ не может сегодня работать на персональном компьютере - он может (и должен) работать на сколь угодно интеллектуальном персональном терминале в глобальной компьютерной сети. Естественно, что стоимость обработки данных в такой сети может быть существенно снижена при концентрации программ и данных, относящихся к одному, например, проекту или предприятию, в одном узле этой сети с обеспечением доступа к ним всех пользователей этой информации. Во-вторых, в 70-е годы состояние средств вычислительной техники и их программного обеспечения позволило специалистам вывести правило о том, что при линейном возрастании стоимости вычислительной системы ее возможности возрастают в квадрате [8]. В середине 80-х годов это правило было нарушено из-за значительного снижения стоимости ПЭВМ за счет их массового производства, но в настоящее время технологии производства компонентов больших ЭВМ (мейнфреймов) по стоимостному показателю сравнялись с ПЭВМ [22, 28], и это правило вновь становится актуальным. Но более мощную вычислительную систему один пользователь будет просто не в состоянии загрузить - отсюда и необходимость в многопользовательском режиме.
Многозадачность (синоним: мультипрограммирование - "режим работы, предусматривающий поочередное выполнение двух или более программ одним процессором" [4]) при ее возникновении была обусловлена стремлением наиболее полно использовать ресурсы. При работе системы в пакетном режиме целью, к которой стремится ОС, является повышение пропускной способности - обслуживание как можно большего числа заданий в единицу времени. Поскольку аппаратная архитектура большинства вычислительных систем допускает параллельное функционирование центрального процессора и каналов ввода-вывода, очевидным представляется программное решение, использующее это распараллеливание: один процесс выполняется на центральном процессоре, в то время как другой (другие) работает с каналом (каналами) ввода-вывода. С заменой перфокарточных и перфоленточных устройств ввода на терминалы стал активно развиваться интерактивный режим. Понятие "задание" (job) сменяется понятием "сеанс" (session). В отличие от задания, в котором исходные данные готовились до начала выполнения программы и вводились в ЭВМ вместе с программой, в сеансе эти данные вводятся уже в ходе выполнения, зачастую они просто не могут быть подготовлены заранее. Пока в одном сеансе происходит подготовка и ввод данных, система может обслуживать другие сеансы. Поскольку ввод данных, выполняемый оператором или пользователем, - процесс очень медленный, уровень мультипрограммирования (количество параллельно выполняемых процессов) в такой системе значительно повышается. При управлении ресурсами в интерактивном режиме на передний план выдвигается цель справедливого обслуживания: обеспечение минимальной дисперсии времени ответа системы на ввод данных пользователем и приемлемого времени ожидания ответа.
Разновидностью интерактивного режима можно считать вычисления в режиме клиент/сервер [25]. В этом режиме управление каким-либо ресурсом (например, базой данных) осуществляется отдельным процессом (возможно, и отдельным компьютером в сети) - сервером. Приложения-клиенты - для получения доступа к ресурсу обращаются к серверу. При любой обработке данных имеются три основных уровня манипулирования данными, как показано на рисунке 1.2: хранение данных; бизнес-логика, т.е. выборка и обработка данных для нужд прикладной задачи; представление данных и результатов обработки конечному пользователю.
Команда testAndSet и блокировки
8.4. Команда testAndSet и блокировки
Взаимное исключение при помощи переменных-переключателей базируется на атомарности обращений к памяти. Как мы показали выше, это делает решение универсальным как для одно-, так и для многопроцессорных систем. Но большинство архитектур компьютеров имеет в составе своей системы команд специальные команды с расширенной атомарностью обращений к памяти, при помощи которых можно реализовать взаимное исключение и быстрее, и проще. Общее название таких команд - testAndSet - проверить и установить. Действия такой команды могут быть описаны функцией: int atomic testAndSet ( char *lock ) { char var; var = *lock; *lock = 1; return var; }
(Здесь и далее мы, следуя правилам языка С, в котором параметры передаются по значению, вынуждены передавать в функции указатели, чтобы функции могли изменять значения параметров).
Команда проверяет (возвращает) значение некоторой переменной, а затем устанавливает ее значение в 1. Введенный нами описатель функции atomic показывает, что функция непрерываемая, во время ее выполнения никакой другой процесс не имеет доступа к той памяти, с которой работает функция (к переменной lock). Функция, как мы видим, выполняет два обращения к переменной lock, но оба они выполняются как одна транзакция.
Возможно, первые включения команд типа testAndSet в системы команд диктовались иными соображениями, но сейчас возможность выполнения подобных команд является обязательной для процессоров, претендующих на возможность использования в многопроцессорных комплексах. В микропроцессорах Intel-Pentium, например, имеются следующие команды, которые представляют собой "вариации на тему" testAndSet: XCHG - перестановка; BTS - проверка и установка бита; BTR - проверка и сброс бита; BTC - проверка бита и установка противоположного значения; CMPXCHG - сравнить и заменить; XADD - заменить и сложить. Так, для реализации "канонической" функции testAndSet при помощи команды XCHG нужны две команды: MOV al,1 XCHG al,lock
Переменная lock устанавливается в 1, а ее прежнее значение сохраняется в регистре AL.
Непрерываемость операций с памятью при использовании этих команд в многопроцессорных системах обеспечивается сигналом LOCK#, появляющимся на выходе микропроцессора. Причем команда XCHG, когда она использует операнд, расположенный в памяти, активизирует сигнал LOCK# автоматически. Для других названных команд активизация этого сигнала может явным образом задаваться программистом - при помощи префикса LOCK.
Наличие в арсенале программиста команды testAndSet позволяет ему организовать простую и надежную защиту критической секции при помощи переменной-замка: 1 void csBegin ( char *lock ) { 2 while ( testAndSet( lock ) ); 3 } 4 void csEnd ( char *lock ) { 5 *lock = 0; 6 }
Команда testAndSet (строка 2) будет возвращать 1 до тех пор, пока другой процесс находится в критической секции, защищенной замком. Как только этот другой процесс выйдет из критической секции и установит замок в 0 (строка 5), наш процесс тут же вновь установит его в 1 и выйдет из цикла. Вследствие атомарности testAndSet никакой другой процесс не сможет изменить состояние замка между теми моментами, когда наш процесс считает его нулевое значение и установит его значение в 1.
Каждый ресурс (например, каждая разделяемая переменная), к которому происходит совместный доступ, может быть защищен своим замком. Это обеспечит запрет только конфликтующих критических секций, позволяя разным процессам одновременно использовать разные разделяемые ресурсы.
При наличии двух и более групп ресурсов, со своим замком каждая, возможны тупики. Как мы помним из главы 5, наиболее либеральной политикой их предотвращения, не требующей априорной информации, является иерархическая - ее рекомендуется применять и в данном случае.
Замки, обеспечиваемые командой testAndSet, обладают, следовательно, такими свойствами: они применимы для любого числа процессов и любого числа процессоров; они просты для понимания и для верификации; они либеральны, так как не запрещают другим процессам выполняться и даже одновременно входить в неконфликтующие критические секции; они допускают бесконечное откладывание, так как выбор процесса, допускаемого к замку, определяется оборудованием, а мы ничего не знаем о его критериях арбитража; они используют занятое ожидание.
Командные файлы и язык процедур
Принцип пользователя диктует необходимость короткого обращения к часто выполняемым последовательностям команд. Простым и эффективным решением этой задачи является запись такой последовательности в текстовый файл и обращение к ней в дальнейшем по имени файла. Мы будем называть такие файлы командными файлами. В интерактивных системах их иногда также называют пакетными файлами (batch file), а в пакетных - файлами процедур JCL. Командный интерпретатор должен при вводе команды-обращения к такому файлу распознать тип файла (иногда признак обращения к командному файлу требуется указать в самой команде) и далее считывать и интерпретировать команды из файла.
В простейшем случае командный файл содержит неизменяемую последовательность команд и является просто аббревиатурой этой последовательности. Но сервис, обеспечиваемый инвариантными последовательностями, явно недостаточен. Например, для программиста типичным является "сценарий" работы, состоящий из многократного повторения таких шагов: редактирование исходного модуля; компиляция; компоновка; выполнение.
Каждый шаг связан с вызовом новой программы, следовательно, с новой командой. Очевидно, что при записи такого сценария в командный файл мы должны обеспечить для него хотя бы один параметр - имя исходного модуля. Параметры являются совершенно необходимым свойством для командных файлов. Параметры нетрудно обрабатывать простой текстовой подстановкой.
Очевидно также, что в том же сценарии не имеет смысла компоновать, а тем более выполнять программу, если при компиляции в ней обнаружены ошибки. Отсюда - необходимость управлять последовательностью выполнения команд в командном сценарии. Простейшим вариантом такого управления является включение в команду условия ее выполнения, более сложный и гибкий вариант - условный переход на ту или иную команду. В условии выполнения или перехода должен анализироваться код завершения одной или нескольких предыдущих команд. Общепринятым является успешное завершение программ и команд с кодом 0. Код завершения может формироваться программой, выполняющей команду, как параметр системного вызова exit и восприниматься процессом-родителем (командным интерпретатором) в системном вызове wait.
Параметры и условия являются тем набором средств, который обеспечивает минимальный необходимый сервис. Некоторые ОС на этом и останавливаются. Другие же идут дальше. "Пионером" в этой области (как и во многих других) является ОС Unix. Это неудивительно, так как Unix воплощает "философию дешевых процессов", а для того, чтобы скомпоновать из "дешевых" процессов сложные действия, нужны развитые средства интеграции. Просматривая публикации по ОС Unix в хронологическом порядке, можно наблюдать, как языковые средства shell наращивались новыми алгоритмическими возможностями, все более приближая его к процедурному языку программирования. В итоге shell обладает полным набором средств процедурного программирования (операций и операторов), включая манипулирование с переменными shell-программы, условный оператор, оператор множественного выбора, операторы циклов, оператор обработки исключительных ситуаций, а также возможность создания и вызова функций.
По иному пути пошла фирма IBM, в середине 80-х годов представившая в составе ОС CMS (гостевой ОС в среде ОС виртуальных машин VM/370) реструктурированный расширенный язык процедур - REXX (Restructured EXtended eXecutor language) [31]. Разработчики этого языка пошли не по пути наращивания командного языка алгоритмическими возможностями, а по пути включения в мощный алгоритмический язык (за основу был взят язык PL/1) средств выполнения команд. Подход оказался настолько продуктивным, что за прошедшее с тех пор время REXX практически не претерпел изменений и сейчас входит в базовый комплект поставки не только CMS VM/ESA, но всех ОС фирмы. Наряду со средствами процедурного программирования, "унаследованными" от PL/1 в REXX включен в качестве базовых операций языка ряд операций расширенной обработки строк и большое количество встроенных функций, также прежде всего связанных с обработкой строк, которыми компенсируется отсутствие того богатого набора утилит, который имеется в Unix. Кроме того, в REXX имеется возможности (эти возможности системно-зависимые) работы с текстовыми файлами и обмена данными через очереди или перенаправление ввода-вывода не только в файлы, но и в буферы, подобные программным каналам - pipe, но со структурой дека (очереди с двумя концами). Вообще область применения REXX шире, чем только применение его в качестве командного интерпретатора ОС. Целый ряд продуктов системного и промежуточного программного обеспечения IBM использует REXX как интерпретатор своих команд. Оператор ADDRESS задает имя программы-среды, в которую передается команда.
Оба типа развитых командных языков наряду с одинаковыми алгоритмическими возможностями обладают также еще одним принципиально важным общим свойством - они являются языками интерпретирующего типа. Командный файл REXX или sell не требует компиляции. Эта означает, что полный анализ такого файла не производится (или производится только в первом приближении), и интерпретатор выполняет его команда за командой, "не заглядывая" вперед. Переменные командного файла имеют единственный тип - "строка символов" и основные манипуляции над ними представляют собой строковые операции. При выполнении арифметики строковые данные прозрачно преобразуются в числовые, а результат операции вновь преобразуется в строку. При выполнении каждого очередного оператора командного файла производится подстановка вместо переменных shell- или REXX-программы их значений. В обоих языках предусмотрены средства "экранирования", защищающие строковые литералы от интерпретации их как переменных. Строка, полученная после выполнения подстановки, интерпретируется как оператор командного языка или - если это невозможно - как команда ОС (или другой целевой среды). В REXX имеется возможность даже сформировать символьную строку в переменной REXX-программы, а затем выполнить ее как оператор языка.
Таки образом, командные языки ОС обладают всеми возможностями языков программирования, и, в принципе, пригодны для создания не только командных процедур, но и некоторых программ обработки данных. Выполнение командных файлов в режиме интерпретации, конечно, делает такие программы менее эффективными, чем программы, написанные на языках компилирующего типа, но создает в них некоторые дополнительные возможности и вырабатывает некоторый особый стиль программирования.
Командный язык и командный процессор
11.1. Командный язык и командный процессор
Команды представляют собой инструкции, сообщающие ОС, что нужно делать. Команды могут восприниматься и выполняться либо модулями ядра ОС, либо отдельным процессом, в последнем случае такой процесс называется командным интерпретатором (оболочкой - shell). Набор допустимых команд ОС и правил их записи образует командный язык (CL - control language).
Большинство запросов пользователя к ОС состоят из двух компонент, показывающих: какую операцию следует выполнить и в каком окружении (environment) должно происходить выполнение операции. Могут различаться внутренние и внешние операции-команды. Выполнение внутренних операций производится самим командным интерпретатором, выполнение внешних требует вызова программ-утилит. Наличие в составе командного языка внутренних команд представляется совершенно необходимым для тех случаев, когда командный интерпретатор является отдельным процессом. Среди команд имеются такие, в которых выполняются системные вызовы, изменяющие состояние самого командного интерпретатора, если для них интерпретатор будет создавать новые процессы, то изменяться будет состояние нового процесса, а не интерпретатора. Примеры таких команд: chdir - изменение рабочего каталога для интерпретатора, wait - интерпретатор должен ждать завершения порожденного им процесса и т.п. Программы-утилиты (их загрузочные модули) записаны в файлах на внешней памяти. При их вызове порождаются процессы, и утилиты выполняются в контексте этих процессов. Вызов и выполнение программ-утилит ничем не отличаются от вызова и выполнения приложений. Командный интерпретатор порождает процессы-потомки и выполняет в них заданные программы, используя для этого те же самые системные вызовы, которые мы рассмотрели в главе 4. Задание операции в командном языке, таким образом, может иметь вид имени программного файла, который должен быть выполнен.
Окружением или средой (далее эти слова используются как синонимы) называется то, что отличает одно выполнение программы от другого. Например, при выполнении программы-компилятора должны быть определены следующие компоненты выполнения: какую программу следует выполнить; откуда программа должна взять исходные данные; куда программа должна поместить результат компиляции; где находятся библиотеки системы программирования; должен или не должен формироваться листинг; должны ли выдаваться предупреждения о возможных ошибках; и т.д., и т.п.
Только первая из перечисленных составляющих задает саму программу, остальные составляют окружение. Окружение конкретного выполнения может формироваться одним из следующих способов или их комбинациями: командами установки локального окружения; параметрами программы; командами установки глобального окружения.
Окружение может быть локальным или глобальным. В первом случае параметры окружения устанавливаются только для данного конкретного выполнения данной конкретной программы-процесса и теряются по окончании выполнения. Во втором случае параметры окружения сохраняются и действуют все время до их явной отмены или переустановки.
Команды для установки локальных параметров окружения применяются обычно в системах, работающих в пакетном режиме. В таких системах основным понятием является задание - единица работы с точки зрения пользователя. Выполнение задания состоит из одного или нескольких шагов. Каждый шаг задания включает в себя оператор JCL (job control language - язык управления заданиями) вызова программы и операторов установки локальной среды. Интерпретатор JCL сначала вводит все операторы, относящиеся к шагу задания, и лишь затем их выполняет. Тот же способ может применяться и в интерактивных системах - в этом случае команды установки параметров локальной среды должны предшествовать команде вызова.
Параметры программы также задают локальную среду выполнения. Они являются дополнениями к команде вызова, вводятся в той же командной строке, что и команда вызова, или являются параметрами оператора вызова в JCL. Формы задания параметров можно, по-видимому, свести к трем вариантам: позиционные, ключевые и флаговые. Возможны также и их комбинации. Позиционная форма передачи параметров программе похожа на общепринятую форму передачи параметров процедурам: параметры передаются в виде списка значений, интерпретация значения зависит от его места в списке. При передаче параметров в ключевой форме задается обозначение (имя) параметра и его значение; имя от значения отделяется специфицированным разделителем. Иногда другой специфицированный разделитель ставится перед именем как признак ключевой формы. Флаговая форма применяется для параметров, которые могут иметь только логические значения типа "да"/"нет"; такой параметр обычно кодируется одним определенным для него символом, иногда перед ним ставится специфицированный разделитель. Для флагового параметра информативным является само его задание в команде вызова: если параметр не задан, применяется его значение по умолчанию, если задан - противоположное значение.
Ниже приводятся примеры передачи параметров: позиционная форма: pgm1 data1.dat data2.dat list pgm2 10,33,p12.txt ключевая форма: pgm1 fille1=data1.dat,file2=data2.dat,list=yes pgm2 /bsize:10 /ssize:33 /name:p12.txt флаговая форма: pgm1 /1 /2 /p pgm2 s,m,l комбинированная форма: pgm1 data1.dat data2.dat #bsize=10 #ssize=33 #l #f
Наиболее универсальным типом, который позволяет передать программе любые параметры, является строка символов. Некоторые CL требуют сформировать такую строку при вызове явным образом в виде строковой константы с использованием соответствующих символов-ограничителей, в других эта задача выполняется командным интерпретатором. Программа сама интерпретирует свою строку параметров, выполняя ее лексический разбор. В реальных системах суммарный размер строки параметров обычно имеет некоторые разумные ограничения. Иногда командный интерпретатор выполняет предварительный лексический разбор строки параметров, выделяя из нее "слова", разделенные пробелами, и передавая программе параметры в виде массива строк переменной размерности.
Каким образом параметры могут быть переданы программе? Можно назвать такие возможные механизмы передачи параметров: если командный интерпретатор выполняется как процесс, то он может послать процессу-программе параметры в виде сообщения; если командный интерпретатор является ядром ОС, то он копирует параметры в системную область памяти, и программа может получить их при помощи специального системного вызова; если командный интерпретатор участвует в порождении процесса-программы (а это обычно так и бывает, независимо от того, является интерпретатор модулем ядра или процессом), то параметры могут быть записаны в адресное пространство нового процесса сразу при его создании.
В языках программирования, однако, механизм передачи параметров прозрачен для программиста, доступ к параметрам обеспечивает компилятор и в любом случае программа получает значения параметров уже в своем адресном пространстве. Так, в языке C для главной функции программы предопределен прототип:: int main(int argn, char *argv[]);
где argn - число строк-параметров, argv - указатель на массив строк-параметров.
Для установки глобального окружения применяются команды типа set. Операндами такой команды могут быть символьные строки, задающие в ключевой форме значения параметров окружения. Например: set tempdir=d:\util\tmp set listmode=NO, BLKSIZE=1024
Переменные окружения могут быть системными или пользовательскими. Системные имеют зарезервированные символьные имена и интерпретируются командным интерпретатором либо другими системными утилитами. Например, типичной является системная переменная окружения path, значение которой задает список каталогов для поиска программ командным интерпретатором. Пользовательские переменные создаются, изменяются и интерпретируются пользователями и приложениями. Чтобы окружение могло быть использовано, в системе должны быть средства доступа к нему. На уровне команд - это должна быть команда типа show, выводящая на терминал имена и значения всех переменных глобального окружения, на уровне API - системный вызов getEvironment, возвращающий адрес блока глобального окружения.
Для внутреннего представления глобального окружения в ОС возможны два варианта: либо хранить в системе единую таблицу со значениями всех переменных окружения, либо для каждого процесса создавать собственную копию такой таблицы. Чаще используется второй вариант, который обеспечивает, во-первых, лучшую защиту глобального окружения, а во-вторых, возможность варьировать окружения для разных процессов, используя глобальное окружение отчасти как локальное. Очень удобным является этот вариант для систем с иерархической структурой отношений между процессами: в этом случае глобальное окружение является частью наследства, передаваемого от предка к потомку. Системные вызовы, связанные с порождением новых процессов, должны обеспечивать возможность передавать потомку как точную копию глобального окружения родителя, так и оригинальное окружение, специально созданное родителем для потомка.
Внутреннее представление глобального окружения - всегда текстовое, представленное в ключевой форме, как в команде set. Это объясняется тем, что окружение интерпретируется прикладными процессами, а именно текстовый тип может быть интерпретирован наиболее гибким образом.
В ОС, применяющих "философию дешевых процессов", (см. главу 4), предполагается выполнение сложных действий как результата совместной (последовательной или параллельной) работы нескольких простых процессов. Поэтому командный язык должен включать в себя средства интеграции процессов. К числу таких средств относятся: командные списки; переадресация системного ввода-вывода; конвейеризация; параллельное выполнение.
Командные списки представляют собой простое перечисление в одной командной строке нескольких команд. Например, результат выполнения такой командной строки: pgm1 param11 param12; pgm2; pgm3 param31
будет таким же, как при последовательным выполнении трех строк: pgm1 param11 param12 pgm2 pgm3 param31
Командные списки представляют более удобную форму, но не открывают никаких новых возможностей.
Процессы вводят данные из файла системного ввода, с которым по умолчанию связана клавиатура, а выводят - в файл системного вывода, по умолчанию - на экран терминала. Переадресация ввода дает возможность использовать в качестве входных данных программы данные, заранее записанные в файл, причем программа вводит и интерпретирует эти данные как введенные с клавиатуры. Переадресация вывода сохраняет данные, которые должны выводиться на экран, в файле. Примеры: pgm1 < infile pgm2 > outfile
Соединение командного списка с переадресацией ввода-вывода обеспечивает конвейеризацию. В примере: pgm1 param11 param12 | pgm2 | pgm3 param31
выходные данные программы pgm1 направляются не на экран, а сохраняются и затем используются, как входные для программы pgm2. Выходные данные последней в свою очередь используются как входные для pgm3.
В ОС с "философией дешевых процессов" допускается параллельное выполнение любого количества процессов. В обычном режиме командный интерпретатор готов к приему следующей команды только после окончания выполнения предыдущей. Специальная команда запуска программы или какой-либо признак в командной строке (например, символ-амперсанд в конце ее) может применяться в качестве указания командному процессору вводить и выполнять следующую команду, не дожидаясь окончания выполнения предыдущей. Так, последовательность командных строк: pgm1 param11 param12 & pgm2 & pgm3 param31
может привести к параллельному выполнению трех процессов (если программа pgm1 не закончится прежде, чем будет введена третья строка).
Ниже приведен программный текст, представляющий в значительно упрощенном виде макет командного интерпретатора shell ОС Unix (синтаксис и семантика системных вызовов в основном тоже соответствуют этой ОС). Из этого примера можно судить о том, как shell реализует некоторые из описанных выше возможностей. 1 int fd, fds [2]; 2 int status, retid, numchars=256; 3 char buffer [numchars], outfile[80]; 4 . . . 5 while( read(stdin,buffer,numchars) ) { 6 <синтаксический разбор командной строки> 7 if (<не внутренняя команда>) { 8 if(<командная строка содержит &>) amp=1; 9 else amp=0; 10 if( fork() == 0 ) { 11 if( < переадресация вывода > ) { 12 fd = create(outfile,<режим>); 13 close(stdout); 14 dup(fd); 15 close(fd); 16 } 17 if(<переадресация ввода>) { 18 <подобным же образом> 19 } 20 if(<конвейер>) { 21 pipe (fds); 22 if ( fork() == 0 ) { 23 close(stdin); 24 dup(fds[0]); 25 close(fds[0]); 26 close(fds[1]); 27 exec(pgm2, <параметры> ); 28 } 29 else { 30 close(stdout); 31 dup(fds[1]); 32 close(ds[1]); 33 close(fds[0]); 34 } 35 } 36 exec(pgm1, <параметры>); 37 } 38 if ( amp == 0 ) retid = wait(&status); 39 } 40 } 41 . . .
Наш макет рассчитан на интерпретацию командной строки, содержащей либо вызов одной программы (pgm1), либо конвейер из двух программ (pgm1|pgm2). Макет также обрабатывает переадресацию ввода-вывода и параллельное выполнение.
Тело shell представляет собой цикл (5 - 39), в каждой итерации которого из файла стандартного ввода вводится (5) строка символов - командная строка. Далее shell выполняет разбор командной строки, выделяя и распознавая собственно команду (или команды), параметры и т.д. Если (7) распознанная команда не является внутренней командой shell (обработку внутренних команд мы не рассматриваем), а требует выполнения какой-то программы - безразлично, системной утилиты или приложения - то shell проверяет наличие в командной строке признака параллельности и соответственно устанавливает значение флага amp (8, 9). Затем shell порождает новый процесс (10) и весь следующий блок (11 - 37) выполняется только в процессе-потомке. Если shell распознал в команде переадресацию системного вывода (11), то выполняются соответствующие действия (11 - 16). Они состоят в том, что shell создает файл, в который будет перенаправлен поток вывода и получает его манипулятор (12). Затем закрывается файл системного вывода (13). Системный вызов dup (14) дублирует манипулятор fd в первый свободный манипулятор таблицы файлов процесса. Поскольку только что освободился файл системного вывода, манипулятор которого - 1, дублирование произойдет именно в него. Теперь два элемента таблицы файлов процесса - элемент с номером 1 и элемент с номером fd адресуют один и тот же файловый дескриптор - дескриптор только что созданного файла. Но элемент fd сразу же освобождается (15), и теперь только манипулятор 1, который интерпретируется в программе как манипулятор системного вывода, адресует новый файл. Мы предлагаем читателю самостоятельно запрограммировать действия shell при переадресации ввода (17-19). (Для справки: манипулятор системного ввода - 0.)
Если в командной строке задан конвейер (20), то процесс-потомок прежде всего создает канал (21). Параметром системного вызова pipe является массив из двух элементов, в который этот вызов помещает манипуляторы канала: fds[0] - для чтения и fds[1] - для записи. Затем процесс-потомок порождает еще один процесс (22). Следующий блок (23 - 27) выполняется только во втором процессе-потомке. Этот потомок переадресует свой стандартный ввод на манипулятор чтения канала (23 - 25). Манипулятор записи канала освобождается за ненадобностью (26). Затем второй потомок загружается программой, являющейся вторым компонентом конвейера (27). Следующий блок (28 - 34) выполняется только в первом потомке: он переадресует свой стандартный вывод на манипулятор записи канала и освобождает манипулятор чтения канала.
Системный вызов exec (36) выполняется в первом потомке (он является единственным, если конвейер не задан), процесс загружается программой, являющейся первым компонентом конвейера или единственным компонентом командной строки. Обратите внимание на то, что из функции exec нет возврата. При ее вызове выполняется новая программа, с завершением которой завершается и процесс. Процесс-родитель, который все время сохраняет контекст интерпретатора shell, после запуска потомка проверяет (38) флаг параллельного выполнения amp. Если этот флаг не установлен, то родитель выполняет вызов wait, блокирующий shell до завершения потомка. (Этот вызов возвращает идентификатор закончившегося процесса, а в параметре - код завершения, но в нашем макете эти результаты не обрабатываются). Если флаг параллельности установлен, то shell начинает следующую свою итерацию, не дожидаясь завершения потомка.
При разработке командного интерпретатора необходимо следовать "принципу пользователя", который может быть сформулирован так: те операции, которые часто выполняются, должны легко вызываться. Для более полного воплощения этого принципа в командный интерпретатор могут быть встроены сервисные возможности. Можно привести такие примеры этих возможностей: установки по умолчанию - относятся прежде всего к параметрам глобального окружения, обычно эти установки записываются в отдельный файл - командный файл (cм. следующий раздел) начальной загрузки типа AUTOEXEC.BAT или в пользовательский профиль; встроенные сокращенные формы команд; в некоторых интерпретаторах применяется метод автоматического завершения: пользователь, введя первые символы команды, нажимает определенную клавишу и интерпретатор выводит в командную строку остаток команды; интеграция команд - введение в состав CL сложных команд, эквивалентных цепочке простых команд, иногда пользователь имеет возможность создавать в командном интерпретаторе собственные интегрированные команды, но чаще такая возможность реализуется через командные файлы; сохранение истории - веденные командные строки запоминаются в стеке и по определенной клавише содержимое стека выбирается в командную строку.
В тех ОС, где командный интерпретатор является процессом, имеется возможность запуска вторичного интерпретатора. Эта возможность является очень удобной, если при работе в среде какого-либо приложения возникает необходимость выполнить команды ОС, но завершать приложение из-за этого нежелательно. Приложение является процессом-потомком командного интерпретатора. Оно порождает новый процесс (потомок приложения), в котором запускается еще одна копия интерпретатора, как показано на Рисунке 11.1. (Новый процесс-интерпретатор может разделять сегмент кодов с первичным интерпретатором). Теперь весь ввод в командную строку обрабатывается этим вторичным интерпретатором. Вторичный интерпретатор может запустить другое приложение и т.д. Вторичный интерпретатор запускается в синхронном режиме, и при его завершении (команда exit) продолжает работать запускавшее его приложение.
Компиляция
4.1. Компиляция
Этот этап реализуется не ОС, а системами программирования, которые представляют собой "системы, образуемые языком программирования, компиляторами или интерпретаторами программ, представленных на этом языке, соответствующей документацией, а также вспомогательными средствами для подготовки программ в форме, пригодной для выполнения" [4]. Системы программирования представляют собой предмет изучения отдельного курса, им посвящена обширная литература, здесь мы остановимся только на тех их аспектах, которые имеют отношение к ОС и аппаратным средствам вычислительной системы.
Основным функциональным назначением системы программирования является генерация объектного кода программы (машинных команд). Компиляторы предварительно формируют структуру виртуального адресного пространства: определяют состав сегментов и формируют содержимое (образы) кодовых сегментов и сегментов инициализированных статических данных.
Система программирования создает также дополнительный интерфейс между программистом и ОС. Состав и спецификации этого интерфейса могут быть либо стандартными для языка, либо определяться конкретной системой программирования. Везде в этом пособии мы описываем системные вызовы ОС, как некоторые процедуры или функции высокоуровневого языка программирования. В конкретных системах программирования набор таких процедур составляет библиотеки системных вызовов, эти процедуры обеспечивают передачу вызовов ОС в той форме, в какой они специфицированы для данной ОС (например, в виде программного прерывания с передачей параметров через регистры общего назначения). Многие процедуры систем программирования включают в себя интегрированный системный сервис - выполнение в составе одной процедуры нескольких системных вызовов с некоторой обработкой их результатов. Можно говорить о том, что системы программирования продолжают тенденцию виртуализации ресурсов: они формируют на базе примитивов, обеспечиваемых системными вызовами ОС, ресурсы более высокого уровня, доступные через средства системы программирования. Так, работая на языке высокого уровня, мы имеем в своем распоряжении виртуальную ЭВМ, в которой "система команд" представлена операциями, операторами и стандартными процедурами языка, а адресация выполняется в пространстве символьных имен. Некоторые языки или их конкретные системы программирования могут включать в себя и более сложные средства управления ресурсами, такие как: буферизацию ввода/вывода (см. главу 6), работу с файлами сложной логической структуры (см. главу 7), средства синхронизации и взаимодействия процессов (см. главу 8) и т.д.
С целью получения наиболее эффективного объектного кода компиляторы могут выполнять оптимизацию обрабатываемой программы. Можно выделить три стадии такой оптимизации: системно-независимая оптимизация; системно-зависимая, но аппаратно-независимая оптимизация; аппаратно-зависимая оптимизация.
Ни одна из указанных стадий не является строго обязательной. На первой стадии выполняется оптимизация логической структуры программы и ее виртуальной памяти. К оптимизационным процедурам этого этапа можно отнести: оптимизацию циклов, устранение избыточных вычислений, преобразование индексных выражений, сокращение числа переменных и т.п. Эти методы требуют не пооператорного просмотра, а анализа всей программы или ее участка. Такая оптимизация может осуществляться либо на уровне исходного языка, либо на уровне некоторого промежуточного языка. Подавляющее большинство современных языков высокого уровня воплощает принципы структурного программирования [6], а это означает, что с одной стороны, эффективность алгоритма зачастую приносится в жертву его ясности, но с другой, - что логическая структура программы получается строгой и, следовательно, легко анализируемой и оптимизируемой. Общность принципов структурного программирования для разных языков позволяют также формировать единое промежуточное представление разноязыковых программ и применять оптимизационные процедуры, не зависящие от языка.
Системно-зависимая стадия оптимизации связана прежде всего с дисциплинами управления памятью в ОС. Если компилятор "знает", какие алгоритмы управления памятью (например, страничного обмена) применяет ОС, он может "помочь" ОС. Поскольку компилятор, в отличие от ОС, обладает возможностью глобального анализа программы, он может предсказывать будущую потребность в тех или иных страницах памяти, влиять на размер и состав рабочего набора процесса. Компилятор может также перестроить программу таким образом, чтобы повысить степень локализации обращений к памяти и тем самым снизить интенсивность страничного обмена.
Роль аппаратно-зависимой оптимизации все более возрастает с развитием процессорных архитектур. Мы уже отмечали, что на компилятор, таким образом, возлагается задача расположения команд программы в такой последовательности, чтобы обеспечить максимальную загрузку конвейерных линий. Рассмотрим пример возможного дальнейшего развития этой идеи.
Недостатком современных суперскалярных процессоров является необходимость для процессора в каждом цикле анализировать поток команд, чтобы определить, какие конвейерные линии могут быть использованы. Это является препятствием как для увеличения числа линий, так и для сокращения времени цикла. Перспективной для RISС-процессоров, по-видимому, является идея упаковки нескольких простых команд в одну большую команду фиксированной длины. Такая команда называется VLIW (very long instruction word - очень длинное командное слово). Составляющие VLIW-команды должны выполняться строго последовательно, сами VLIW-команды могут выполняться параллельно. Процессор, таким образом, просто загружает очередную VLIW-команду в очередную конвейерную линию, не занимаясь анализом командного потока. Задача формирования VLIW-команд с оптимизацией их под данную платформу ложится на компилятор. На сегодняшний день подобные подходы применяются, например, в процессорах фирмы Hewlett-Packard и процессоре Itanium фирмы Intel.
