Компоновка и загрузка
4.2. Компоновка и загрузка
Очевидно, что ни одно сколько-нибудь сложное программное изделие не может быть реализовано в виде единственного модуля. Модульность программ и данных является необходимым условием структурного программирования при применении его как нисходящего, так и восходящего вариантов. Преимущество модульного конструирования могут, однако, в полной мере проявиться только, если обеспечивается раздельная компиляция модулей. Но если результаты раздельной компиляции представляют собой также отдельные объектные модули, то должен быть этап в подготовке программы, который бы компоновал из объектных модулей единую программу, готовую к выполнению - загрузочный модуль. Кроме того, если компилятор обрабатывает каждый модуль отдельно, он не имеет возможности полностью выполнить функцию именования - в объектном модуле остаются непреобразованными обращения к процедурам и данным, определенным в других модулях. Обеспечение обращений к внешним по отношению к модулю именам называется связыванием. Операции компоновки и связывания выполняются специальными программами - компоновщиками (синоним - редактор связей, linker) и связывающими загрузчиками.
В соответствии с декларированной нами в предыдущей главе "свободой выбора" операцию связывания можно выполнять на разных этапах подготовки программы: статическое связывание этапа подготовки - выполняется компоновщиком, вызываемые модули включаются в загрузочный модуль программы; статическое связывание этапа загрузки - выполняется связывающим загрузчиком, вызываемые модули подключаются к программе уже в оперативной памяти; динамическое связывание этапа загрузки - отличается от предыдущего варианта тем, что обеспечивает совместное использование одних и тех же копий модулей в памяти разными программами; динамическое связывание этапа выполнения - загрузка модулей и установка связей происходит при выполнении программы и управляет ими сама программа.
Статическое связывание обеспечивается соглашениями о формате объектных модулей. В любых вариантах эти форматы предусматривают наличие в объектном модуле двух таблиц - таблицы входов и таблицы внешних ссылок. В первой перечисляются имена и относительные адреса в модуле тех процедур и элементов данных, к которым разрешены обращения из других модулей. Во второй - имена внешних точек, к которым имеются обращения из данного модуля, с каждым таким именем связан также список адресов внутри модуля, которые содержат обращения к этому внешнему имени. При статическом связывании создается таблица входных точек - глобальная для всей программы. По мере компоновки программы из входящих в нее модулей их входные точки заносятся в эту таблицу, а их локальные адреса в модуле заменяются адресами в общем адресном пространстве программы. Затем в каждом модуле находятся (по таблице внешних ссылок) обращения к внешним модулям и имена в этих обращениях заменяются на адреса, получаемые из глобальной таблице входных точек.
При статическом связывании может происходить также и формирование оверлейной структуры адресного пространства программы, рассмотренное в предыдущей главе.
Вспомним, что на этапе загрузки может происходить также трансляция виртуальных адресов программы в физические адреса. В этом случае загрузочный модуль должен содержать таблицу перемещений - список тех адресов в программе, которые должны быть модифицированы при загрузке базовым адресом программы. Эти операции выполняются перемещающим загрузчиком, пример такого загрузчика - загрузчик EXE-файлов в MS DOS.
Статическое связывание и загрузка выполняются системными утилитами, не входящими в ядро ОС, они не составляют основной предмет нашего рассмотрения. Алгоритмы функционирования редакторов связей и перемещающих загрузчиков подробно рассматриваются, например, в [3, 9], здесь же мы остановимся на проблемах динамического связывания, выполняемого ОС.
Современные ОС позволяют сочетать статическую компоновку с динамической. Хотя в литературе, посвященной этим ОС, возможность динамического связывания описывается как принципиально новая, на самом деле, она была впервые реализована еще в 1965 году в ОС MULTICS [21], и с тех пор ее механизмы не претерпели значительных изменений. В современных ОС модули, подключаемые к программам динамически, носят название библиотек динамической компоновки (dynamic link library), соответственно, файлы, содержащие образы таких модулей, обычно имеют расширения DLL.
Выполнение динамической компоновке иллюстрируется Рисунком 4.1. Структуры данных динамической компоновки в принципе сходны со структурами для компоновки статической. Для модуля основной программы компоновщик создает таблицу, функционально идентичную таблице внешних ссылок. В этой таблице указывается имя файла для каждого динамически подключаемого модуля и имена тех процедур в модуле, к которым имеются обращения в программе. Вызовы процедур в теле программы содержат обращения к соответствующим элементам этой таблицы. С другой стороны, при компоновке модуля, предназначенного для динамического подключения, для него создается таблица входов. При компоновке загрузчик (на этапе загрузки) или ядро ОС (на этапе выполнения) выполняет установку связей: находит в памяти или загружает в память динамически подключаемый модуль и по его таблице входов находит требуемую процедуру. Строка таблицы внешних ссылок модифицируется - теперь она содержит переход по адресу найденной процедуры. Последующие обращения к этой же входной точке уже не вызывают каких-либо дополнительных действий.
Конструкции критических секций в языках программирования
8.7. Конструкции критических секций в языках программирования
Семафоры являются удобными и эффективными примитивами, при помощи которых решаются задачи взаимного исключения и синхронизации, поэтому они широко используются во многих ОС. API ОС, обеспечивающий для пользователя работу с семафорами, мы рассмотрим в следующей главе, а здесь остановимся на некоторых возможных расширенных механизмах в системном программном обеспечении (прежде всего - в системах программирования), которые будут использовать семафоры в скрытой от пользователя форме.
Некоторые неудобства использования критических секций могут быть преодолены введением специальных конструкций в язык программирования. Например, если у нас в программе есть разделяемая переменная x, то удобно защитить ее конструкцией типа: shared int x; . . . section ( x ) { < операторы, работающие с переменной x > }
Конструкция section определяет критическую секцию. Вместо специальных "скобок критической секции" используется заголовок section и обычные операторные скобки. Последнее дает возможность проверять правильность оформления критической секции на синтаксическом уровне - на этапе трансляции программы, а не ее выполнения и предупреждает возможность появления самой распространенной ошибки программистов - непарных скобок. Определение переменной x со специальным описателем shared позволяет выявить (опять на этапе компиляции) все попытки доступа к ней вне критической секции.
Реализация этой конструкции очевидна: переменная x защищается скрытым семафором, над которым производится P-операция при входе в секцию и V-операция - при выходе из нее.
Отчасти такая конструкция позволяет решить и проблему тупиков. Если описать в программе иерархию разделяемых переменных, то можно спокойно разрешить программисту делать вложенные критические секции и проверять правильность вложения на этапе компиляции. Этот метод, однако, не универсален: если в критической секции есть обращение к процедуре, а в последней - другая критическая секция, то правильность такого вложения компилятор проверить не сможет. Другой путь - запретить вложенные секции, но разрешить в заголовке секции указывать не одну разделяемую переменную, а целый их список. Этот вариант более прост и надежен, но он использует дисциплину залпового выделения ресурсов и, следовательно, более консервативен.
Критические секции, как языковые конструкции, обеспечивают взаимное исключение, но не синхронизацию процессов. Инструментом для синхронизации может быть оператор типа await, операндом которого является логическое выражение. Этим оператором процесс блокируется до тех пор, пока операнд не примет значение "истина". Поскольку ожидание связано с внешним событием, в логическом выражении должна участвовать хотя бы одна разделяемая переменная, следовательно, применение await может быть разрешено только в критической секции.
В качестве примера приведем решение задачи "производители-потребители" для процессов, использующих буфер, организованный в виде стека. Такая организация буфера диктует нам необходимость запретить одновременный доступ к нему любых двух процессов. 1 shared struct { 2 portion buffer [BSIZE]; 3 int stPtr; 4 } stack = { {...}, 0 }; 5 void producer ( void ) { 6 portion work; 7 while (1) { 8 < производство порции в work > 9 section ( stack ) { 10 await ( stack.stRtr < BSIZE ); 11 memcpy ( stack.buffer + stack.stPtr++, &work, sizeof(portion) ); 14 } 15 } 16 } 17 void consumer ( void ) { 18 portion work; 19 while (1) { 20 section ( stack ) { 21 await( stack.stPtr > 0 ); 22 memcpy ( &work, stack.buffer + --stack.stPtr, sizeof(portion) ); 25 } 26 < обработка порции в work> 27 } 28 }
При реализации возможности await мы должны решить проблему исключения. В приведенном выше примере процесс-производитель, заблокированный в строке 10, ждет уменьшения значения указателя стека (если стек полон). Это значение может быть уменьшено процессом-потребителем в строке 23, но эта строка находится в критической секции потребителя, а последний не может войти в свою критическую секцию, так как производитель уже вошел в свою - в строке 9. Одним из способов разрешения этого противоречия является запрещение употребления await где-либо, кроме самого начала критической секции, возможно, даже включение await-условия в заголовок секции. Исключение в этом случае начинает работать только после выхода из await. Естественно, что сама проверка условия должна выполняться как атомарная операция (защищаться скрытым семафором).
Можно разрешить await где угодно в критической секции, но на время блокировки процесса в await снимать взаимное исключение. Конечно, такой вариант дает программисту более гибкий инструмент, но перекладывает на него ответственность за целостность, так как за время, на которое исключение снимается, разделяемые данные могут быть изменены.
Еще один вопрос, который мы должны решить при реализации await: если процесс заблокировался, то в какие моменты следует проверять условие разблокирования? Вопрос непраздный, так как для вычисления условия, являющегося операндом await, необходимо активизировать контекст заблокированного процесса. Если проделывать это слишком часто, то накладные расходы на переключение неоправданно возрастают. Для варианта, в котором мы жестко привязываем await к началу критической секции, общая переменная, входящая в условие, может быть изменена только другим процессом, и ее новое значение станет доступным при выходе этого другого процесса из его критической секции. Выход другого процесса из критической секции - единственное событие, по которому имеет смысл переключаться в контекст заблокированного процесса и проверять условие в этом варианте. Если же мы разрешаем употребление await где угодно в критической секции, то добавляется еще один тип события - блокировка другого процесса в операторе await его критической секции.
Контрольные вопросы
Контрольные вопросы
Один из авторов [11] заявляет, что он не может дать определения ОС, но сразу узнает ОС, если ее увидит. В чем, по-Вашему, состоит ошибочность такого утверждения? Прокомментируйте примечания 1-3 к определению ОС, данному в разделе 1.1. Покажите их отображения на реальные ОС. Дайте определение пакетному и интерактивному режимам функционирования ОС. Какой из режимов представляется Вам более полезным? В чем сходство работы многопользовательской ОС с ОС-сервером? В чем их различия? Каковы достоинства и недостатки изоляции пользователя от реальных ресурсов? Назовите основные состояния процесса в системе и охарактеризуйте переходы между ними. Какие состояния Вы считаете необязательными? Почему ОС, называемые объекто-ориентированными, правильнее называть объектно-базированными? Назовите общие черты архитектурных концепций микроядра, виртуальной машины и иерархической ОС. В чем различия между ними? В чем достоинства архитектуры микроядра? Почему разработчики стремятся минимизировать объем микроядра? Сравните способы обращения процесса к ОС: через вызов процедур и через прерывания. В чем достоинства и недостатки этих способов?
| Назад | Оглавление | Вперед |
Логическая файловая система Каталоги
7.3. Логическая файловая система. Каталоги
Логическая ФС рассматривает файл, как единицу хранения. Удачным нам представляется сравнение логической ФС с библиотекарем, который не должен знать содержание книги (файла), но обязан уметь быстро найти требуемую книгу в книгохранилище. Как бы продолжая это сравнение, файловые справочники ОС носят названия каталогов (catalog) или оглавлений (directory).
Файловые справочники - и это естественно - располагаются на тех же носителях, что и файлы данных. Первоначально с каждой единицей сменного носителя (пакет магнитных дисков, бобина магнитной ленты) жестко связывался свой единственный справочник и смена носителя вызывала смену справочника. Такая единица сменного носителя получила название тома (volume). Дальнейшее развитие вычислительных систем привело, с одной стороны, к увеличению объемов несменяемых носителей, так что несколько их единиц могут составлять один том, с другой, - к практике разбиения одного физического носителя на несколько логических томов. Таким образом, мы определяем том, как часть внешней памяти вычислительной системы, имеющую собственный справочник. Ниже мы рассмотрим вначале логическую структуру хранения файлов на отдельном томе, а затем - интеграцию томов.
Элемент каталога содержит, как минимум, символьное имя файла и адрес его дескриптора, иногда дескриптор файла может непосредственно входить в элемент каталога.
Прежде, чем переходить к структурам каталогов, остановимся на именовании файлов. Каждый файл имеет символьное имя, которое позволяет пользователю обращаться к данному конкретному файлу. Каждая ОС устанавливает собственные соглашения о формировании имен. Как правило, эти соглашения допускают или даже требуют разделения имени файла на составные части - компоненты. При записи символьного имени его компоненты обычно разделяются точкой. Разные ОС накладывают разные ограничения на количество и длины компонент имени - от двухкомпонентных имен с компонентами ограниченной длины до неограниченного их числа и практически неограниченной длины. Некоторые ОС резервируют одну из составляющих имени файла в качестве описателя типа информации, хранящейся в файле. Даже если ОС не предъявляет дополнительных требований к именованию, пользователи применяют составные имена файлов, как средство структурирования хранения своей информации. Для ОС, работающих с многокомпонентными именами, распространенной является практика применения "символа-джокера", обычно - "*" или "&". Употребление джокера вместо одной из компонент имени обеспечивает выполнение системных вызовов, адресованных логической ФС, как групповых операций - над всеми файлами с любыми значениями этой составляющей имени.
Каталоги файлов выполняют две функции: обеспечивают поиск файлов и структурирование хранения информации.
Простейшей структурой каталога является плоский (flat) каталог. Информация обо всех файлах сведена в одну таблицу, и поиск файла сводится к поиску в этой таблице - линейному или двоичному, если таблица упорядочена. Такая структура каталога не допускает, чтобы файлы имели одинаковые имена. Плоская структура не выполняет второй функции каталога - структурирования хранения и может быть эффективной только для ОС, работающих с томами носителей небольшого объема, когда том содержит файлы, принадлежащие одному пользователю. Если том содержит файлы, принадлежащие разным пользователям, то возможны конфликты имен - назначение разными пользователями одинаковых имен для своих файлов. Даже если такие конфликты предотвращаются (за счет многокомпонентных имен), то остается существенный недостаток: каталог открыт для чтения всем пользователям, а в некоторых случаях даже список имен файлов пользователя может быть его конфиденциальной информацией.
Простейшим решением разделения файлов между пользователями (или по другим признакам) является двухуровневая структура каталога. В этой структуре каждый пользователь имеет собственный каталог. Каталог именуется по правилам именования файлов, его имя также может быть составным. В такой структуре возникают понятия полного и локального имен файла. Полное имя файла состоит из имени каталога и имени файла в каталоге. Обычно эти имена разделяются наклонной чертой "\" или "/". Вторая часть полного имени является локальным именем файла. На томе не может быть двух файлов, имеющих одинаковые полные имена, но файлы с одинаковыми локальными именами могут находиться в разных каталогах. Для сокращения именования файлов процесс может сообщить ОС устанавливаемое по умолчанию имя каталога. Каталог, имя которого устанавливается по умолчанию называется рабочим или текущим. К файлам в текущем каталоге процесс может обращаться по локальным именам, к файлам в других каталогах - только по полным именам.
Нетрудно распространить двух- или трехуровневую структуру каталога на произвольное число уровней - каталог приобретает древовидную или иерархическую структуру. Пример такой структуры показан на Рисунке 7.2. Иерархическая структура каталогов практически исключает возможность конфликта имен. Полное имя файла складывается из перечисления через "/" всего пути (path) от корневого каталога, имеющего имя "/", до данного файла, например: /system/utility/disks/anti/test1
Логическая файловая система Системные вызовы
7.4. Логическая файловая система. Системные вызовы
В API ФС зачастую трудно установить, к какой части ФС адресован тот или иной системный вызов, так как большинство вызовов проходят обработку на всех уровнях ФС. Тем не менее, большинство системных вызовов мы рассматриваем именно вместе с логической ФС, так как существенной составляющей этих вызовов является именно работа с каталогами. Не следует, однако, забывать, что даже, если функции вызова ограничиваются только работой с каталогом, для его выполнения тоже требуется обращение к нижним уровням иерархии ФС, так как каталог - это тоже файл, который имеет свою физическую структуру и который тоже надо читать и записывать.
Для рассмотрения мы разобьем все системные вызовы на следующие группы: вызовы, работающие с каталогами; вызовы, работающие с файлами; вызовы, работающие с томами.
Вызовы, работающие с каталогами.
Установить рабочий (текущий) каталог: setCurrentDirectory(dirName)
При помощи этого вызова процесс сообщает ОС, какой каталог является для него рабочим. В дальнейшем допустимы обращения к файлам в этом каталоге по локальным именам. В ходе своего выполнения процесс может неоднократно менять свой рабочий каталог. Имя каталога dirName задается в виде символьной строки, содержащей путь, отправной точкой которого может быть либо корневой каталог, либо - текущий. Логическая ФС (совместно с нижними уровнями ФС) обеспечивает движение по этому пути. В API ОС может быть включен также информационный вызов getCurrentDirectory, возвращающий полное имя текущего каталога.
Создать подкаталог: createDirectory(dirName)
При помощи этого вызова процесс может создать новый подкаталог. Обычно имя каталога dirName задается локальным и новый подкаталог создается в текущем каталоге, но может быть допущено и задание полного имени. Этот вызов может рассматриваться как специальный случай вызова createFile.
Удалить подкаталог: removeDirectory(dirName)
Конструктор ОС должен особо определить реакцию системы на применение этого вызова к непустому каталогу - то ли завершать в этом случае вызов с ошибкой, то ли удалять каталог со всем его содержимым.
Вызовы, работающие с файлами.
Создать файл: createFile(fileName, parameters)
Вызов создает новый физический файл в текущем каталоге, если имя задано в локальной форме, или в другом, если задано полное имя. Другие параметры - parameters - задают атрибуты, заносимые в дескриптор создаваемого файла.
Создать алиас: createAlias(fileName, aliaseName)
Вызов создает новый элемент каталога, ссылающийся на тот же дескриптор физического файла.
Создать косвенный файл: createIndirect(fileName, indirectName)
Вызов создает новый элемент каталога, ссылающийся на старый элемент каталога.
Удалить файл: deleteFile(fileName)
Вызов удаляет элемент каталога, соответствующий заданному имени. Если имя является именем косвенного файла или если у файла имеются альтернативные имена, то удаляется только элемент каталога, в противном случае - уничтожается также и физический файл, и его дескриптор.
Переместить файл: moveFile(oldName, newName )
Вызов перемещает файл в другой каталог. Одно из имен может быть локальным (то есть, исходный или целевой каталог может быть текущим), другое - обязательно должно быть полным. Данная операция не требует перемещения физического файла или его дескриптора, а только элемента каталога. Вызов может быть реализован, как комбинация двух вызовов, описанных выше: createAlias - в новом каталоге и deleteFile - в старом. Как частный случай этого вызова может рассматриваться вызов renameFile - переименовать файл - но в целях повышения эффективности его реализация может быть выполнена путем исправления данных в элементе каталога, остающемся на том же месте.
Копировать файл: copyFile(oldName, newName )
Вызов копирует файл в другой каталог или в тот же каталог под новым именем. В отличие от вызова moveFile, копируется физический файл - данные файла и файловый дескриптор, а для копии создается новый элемент каталога. Далее старый файл и копия существуют независимо друг от друга.
Вызовы, работающие с томами.
Монтировать том: mount(entrName, extName)
Вызов подключает к ФС новый том. entrName задает идентификацию тома в ФС - это логическое имя тома или имя подкаталога, которым представляется том в едином дереве каталогов. extName идентифицирует том вне ФС - это может быть адрес устройства, на котором том установлен, сетевой адрес узла при удаленном доступе и т.п.
Снять том: unMount (entrName )
Вызов отключает от ФС ранее монтированный том.
Логическая организация файлов Интерфейсы
7.2. Логическая организация файлов. Интерфейсы
Вне зависимости от логической структуры виртуального файла для получения процессом доступа к данным файла должен быть выполнен системный вызов open: handle = open(fileName, mode)
Здесь fileName - символьное имя, идентифицирующее файл для пользователя, соглашения об именовании файлов обсуждаются в следующем разделе. Режим - mode - задает способ обработки файла (чтение, запись, запись в конец, чтение/запись, синхронное/асинхронное выполнение операций ввода/вывода, параметры буферизации, возможность совместного использования файла процессами т.д.). Возвращаемый манипулятор handle используется процессом для идентификации файла во всех последующих операциях с ним.
Системный вызов: close(handle)
закрывает файл, то есть, заканчивает работу процесса с файлом. Как правило, ОС обеспечивает при завершении процесса автоматическое закрытие всех открытых им файлов.
Синтаксис и семантика системных вызовов, связанных с чтением/ записью и поиском данных в файле, зависит от логической структуры файла. Логические структуры виртуальных файлов прежде всего можно подразделить на байториентированные и записеориентированные.
Байториентированные файлы представляются как линейная последовательность байт, без какого-либо дополнительного структурирования. API байториентированных файлов обеспечивается тремя основными системными вызовами: read(handle,vAddr, byteCounter) write(handle, vAddr, byteCounter) seek (handle, offset, form)
Здесь vAddr - адрес той области в виртуальном адресном пространстве процесса, с которой происходит обмен. За одну операцию обмена читается или пишется заданное byteCounter количество байт. К байториентированным файлам обеспечивается произвольный доступ, для чего вводится понятие файлового курсора - номера того байта файла, который будет читаться/записываться следующим. По умолчанию при открытии файла курсор устанавливается на начало файла и сдвигается при каждой операции read/write на byteCounter. Но системный вызов seek дает процессу возможность установить курсор в произвольную позицию, причем смещение offset может задаваться как от начала файла, так и от его конца или от текущей позиции курсора (это задается параметром from). Возможен также сервисный системный вызов, возвращающий текущее положение курсора. Системный вызов read должен адекватно реагировать на попытку чтения данных за концом файла. Стандартным решением является возврат этим вызовом числа прочитанных байт - при достижении конца файла возвращаемое значение будет меньше, чем byteCounter.
Безусловно, байториентированная организация является наиболее универсальной из всех возможных, так как на неструктурированную последовательность байт приложение может наложить любую собственную логическую структуру. Приведем пример, наверняка известный читателю: MS DOS поддерживает только байториентированную организацию файлов, но системы программирования Pascal (приложения в MS DOS) обеспечивают работу с файлами, состоящими из записей - тип данных file of ... . Байториентированные файлы являются единственной логической файловой структурой, поддерживаемой ОС Unix, и "с подачи" этой системы они включены в стандарт на переносимость ОС.
Альтернативной файловой организацией является записеориентированная. Записеориентированные файлы поддерживает фирма IBM в нескольких поколениях своих ОС для ЭВМ средней и большой мощности. В таких файлах единицей обмена является запись - порция данных, состоящая из одного или нескольких байт и, возможно, имеющая свою внутреннюю структуру. Имеется целый ряд методов логической организации записеориентированных файлов.
Последовательные файлы - файлы, ориентированные на обработку запись за записью - от первой записи до последней. Синтаксис и семантика системных вызовов read и write для таких файлов такие же, как и для байториентированных, но объем данных задается количеством записей, а не байтов. Произвольное позиционирование файлового курсора для последовательных файлов невозможно, но система может предоставлять системные вызовы для сдвига на запись вперед или назад. Последовательные файлы могут состоять из записей фиксированной или переменной длины. В последнем случае либо длина входит в состав записи, как одно из ее полей, либо запись содержит специальный код - признак конца записи.
Файлы прямого доступа - предполагается, что для каждой записи файла имеется логическая идентификация или ключ (key). Доступ производится к произвольной записи файла с указанием ее ключа. Системные вызовы для чтения записи имеют вид: keyRead (handle, key, vAdd) keyWrite (handle, key, vAdd)
Выполнение такого вызова включает в себя позиционирование файлового курсора на запись, определяемую ключом key, и собственно обмен. (Каким образом ключ может использоваться при поиске записи в файле, мы специально рассмотрим ниже.) Ключ может входить в состав записи, как одно из ее полей (например, поле фамилии в списке личного состава), или не содержаться в составе записи (например, ключ - порядковый номер записи).
Файлы комбинированного доступа допускают как прямой доступ по ключу (keyRead/keyWrite), так и последовательный (read/write) в порядке возрастания ключей. Системный вызов, например, для чтения по ключу 'Коваль' обеспечит считывание записи, относящейся к сотруднику Ковалю, последующие системные вызовы последовательного чтения будут считывать записи, относящиеся к сотрудникам, следующим за Ковалем в принятом (например, в алфавитном) порядке.
Какой организации отдать предпочтение - байт- или записеориентированной? Как мы уже отмечали, байториентированная организация гибче, но при ней задача структурирования файла перекладывается на приложения - а задача эта не всегда простая. Фирма IBM, не желая с одной стороны отказываться от преимуществ записеориентированной организации, а с другой - желая обеспечить совместимость своих ОС со стандартами, обеспечивает поддержку обеих структур, и такое решение представляется нам оптимальным.
Интересной, хотя пока несколько экзотической формой являются файлы отображаемого доступа. Такие файлы при открытии отображаются в виртуальное адресное пространство процесса. Операция open может возвращать дескриптор сегмента в виртуальной памяти, и в дальнейшем все манипулирование с данными файла будет выполняться, как манипулирование с данными в памяти. Хотя такое решение является весьма элегантным, его реализация требует значительного расширения разрядности представления виртуального адреса и реализуется пока только в 64-разрядных клонах Unix.
Матрица доступа
Рисунок 10.2. Матрица доступа

Как видно даже из рисунка 10.2, в матрице присутствует избыточность - пустые клетки, так как некоторые объекты недоступны для некоторых субъектов. В многопользовательских системах же с большим количеством как объектов, так и субъектов, во-первых, размер матрицы может быть чрезвычайно большим, во-вторых, сама матрица наверняка будет очень сильно разрежена. Поэтому матричное представление прав доступа является неэффективным. Матрица может быть представлена либо в виде списков привилегий (privileges list), либо в виде списков управления доступом (rights list). Списковые структуры позволяют экономить память за счет исключения из матрицы позиций с пустыми значениями доступа.
В первом случае в системе существует таблица субъектов, и с каждым элементом этой таблицы связывается список объектов, к которым субъект имеет доступ (Рисунок 10.3).
Многосегментная модель
3.4. Многосегментная модель
Расширим модель, рассмотренную в предыдущем разделе на случай N сегментов.
Виртуальное пространство процесса разбивается на сегменты, которые нумеруются от 0 до N-1. Виртуальный адрес, таким образом, состоит из двух частей: номера сегмента и смещения в сегменте. Эти части могут либо представляться по отдельности каждая, либо упаковываться в одно адресное слово, в котором определенное число старших разрядов будет интерпретироваться как номер сегмента, а оставшаяся часть - как смещение. В первом случае сегменты могут размещаться произвольным образом в виртуальном адресном пространстве. Во втором случае создается впечатление плоского адресного пространства с адресами от 0 до максимально возможного при данной разрядности виртуального адреса, но в этом пространстве могут быть дыры - виртуальные адреса для процесса недоступные - из-за отсутствия соответствующих сегментов или из-за сегментов, длина которых меньше максимально возможной.
Количество сегментов и максимальный размер сегмента ограничивается аппаратурой - разрядностью полей адресного слова. При выделении процессу реальной памяти каждый сегмент размещается в непрерывной области реальной памяти, но сегменты, смежные в виртуальной памяти, могут попадать в несмежные области памяти реальной. Теперь для процесса уже недостаточно одного дескриптора сегмента - он должен иметь таблицу таких дескрипторов в составе своего блока контекста. Аппаратный регистр дескриптора сегмента превращается в регистр адреса таблицы дескрипторов, он хранит указатель на таблицу дескрипторов активного процесса и перезагружается при смене активного процесса. Вычисление реального адреса аппаратурой несколько усложняется, как показано на Рисунке 3.5: выбирается сегментная часть виртуального адреса, она служит индексом в таблице дескрипторов; по индексу выбирается запись той таблицы, адрес которой находится в регистре адреса таблицы дескрипторов; выбранная запись является дескриптором сегмента, часть виртуального адреса, соответствующая смещению, сравнивается с полем длины в дескрипторе; если смещение в сегменте не превышает его длины, вычисляется реальный адрес как сумма базового адреса из дескриптора сегмента и смещения из виртуального адреса.
Примерная структура аппаратно поддерживаемого дескриптора сегмента приведена на Рисунке 3.6. Подчеркиваем, что данная структура не является обязательной, для всех компьютерных архитектур, мы привели лишь наиболее распространенный ее вариант и использовали наиболее часто употребляемые имена полей.
Модель виртуальных коммуникационных портов
9.3. Модель виртуальных коммуникационных портов
Большинство средств взаимодействия процессов соответствуют концепции коммуникационных портов - виртуальных устройств, через которые процессы обмениваются данными. Как устройства, коммуникационные порты могут "вписываться" в файловую систему в качестве специальных файлов. Такое сведение средств взаимодействия к файловой модели в общем случае обеспечивает три преимущества: возможность единообразных операций со средствами взаимодействия и с файлами; возможность доступа к удаленным средствам как к удаленным файлам; возможность использования единых средств контроля доступа для файловой системы и для коммуникаций.
Концепция коммуникационных портов, однако, в реальных ОС выдерживается далеко не строго. Реально манипулирование далеко не со всем средствам взаимодействия между процессами возможно свести к однотипным операциям. Доступ к удаленным средствам решается методами сетевых модулей ОС. Разграничение доступа в полном объеме мы наблюдали только в AS/400, и то не в рамках файловой системы, а в контексте общей объектно-ориентированной структуры этой системы. Тем не менее, тенденция к модели портов в той или иной степени наблюдается в современных ОС, прежде всего, в части именования средств взаимодействия. В этом разделе мы рассмотрим общие свойства средств взаимодействия, называя их виртуальными коммуникационными портами.
Виртуальный коммуникационный порт представляет собой ресурс ОС. Он, разумеется, имеет и физическое представление - структуры данных, области памяти, скрытые семафоры и т.п. Порты, как ресурсы, конструируемые ОС, не имеют жесткого ограничения по количеству - новые порты могут создаваться по мере надобности и уничтожаться, когда необходимость в них отпадает. При использовании порта несколькими процессами один процесс создает порт, а другие - получают доступ к уже существующему порту.
Как и при работе со всяким ресурсом, процесс должен получить доступ к этому порту - открыть его. Системный вызов открытия коммуникационного порта (или его создания) возвращает процессу манипулятор, который процесс использует как идентификатор порта во всех последующих операциях с ним. Порт используется одновременно, как минимум, двумя процессами, поэтому важно, чтобы манипуляторы у процессов-корреспондентов, взаимодействующих через этот порт, связывались с одним и тем же физическим представлением порта. Возможны два варианта: либо все использующие порт процессы имеют один и тот же манипулятор порта, либо для каждого процесса этот манипулятор индивидуальный. В любом случае ОС поддерживает в ядре таблицу открытых портов (точнее - несколько таких таблиц - по одной для каждого типа средств взаимодействия процессов). В качестве манипулятора может использоваться либо указатель на элемент этой таблицы - тогда манипулятор будет одинаковым для разных процессов, либо указатель на элемент индивидуальной таблицы, входящей в состав контекста процесса, а уже элемент таблицы процесса содержит ссылку на общесистемную таблицу. Очевидно, что второй вариант более надежен, так как исключает случайный доступ к порту. Даже в тех случаях, когда ОС выдает один и тот же манипулятор нескольким процессам, она требует, чтобы процесс выполнил системный вызов получения доступа к ресурсу.
Для доступа двух процессов к одному и тому же физическому представлению порта в вызове открытия порта необходимо указать параметры, позволяющие системе это физическое представление найти. С точки зрения идентификации порты могут быть именованными или неименованными.
Именованный порт имеет внешнее имя. Системный вызов открытия именованного порта требует указания этого имени в качестве параметра вызова. Пользователи-разработчики взаимодействующих процессов заранее договариваются об используемых именах портов. Система именования портов и открытия именованных портов аналогична файловой системе. Имена средств взаимодействия формируются по соглашениям именования файлов и могут выглядеть, как имена файлов, расположенных в специальных каталогах, например: каталог \shrmem - для общих областей памяти, каталог \sem - для системных семафоров, \pipe - для каналов, \queues - для очередей.
Неименованный порт внешнего имени не имеет. При создании такого порта системный вызов возвращает его манипулятор - и это единственное, чем располагает процесс для идентификации порта. Манипулятор порта почти наверняка будет разным при разных выполнениях одной и той же программы. Для установления связи между процессами процесс-создатель порта должен передать процессу-корреспонденту манипулятор созданного им порта. Процесс-корреспондент в системном вызове открытия порта указывает идентификатор процесса-создателя и манипулятор порта у процесса-создателя, а в ответ получает манипулятор того же порта для себя. Передача манипулятора процессу-корреспонденту может производиться как передача ресурса от предка к потомку или (если процессы не связаны родством) через именованный порт. Как правило, неименованные порты используются для связи между процессами - предком и потомком, в этом случае потомок наследует от предка уже открытый коммуникационный порт. Неименованные порты используются для связи между независимыми процессами.
В связи с использованием портов несколькими процессами возникает проблемы закрытия портов. Закончив работу с портом, процесс выполняет системный вызов закрытия. В ОС поддерживается общесистемная таблица портов и обязательным для системы требованием является закрытие при завершении процесса всех портов, которые процесс "забыл" закрыть явным образом. Если с портом работают два процесса, и один из них закрыл порт, а другой обращается к этому порту, то для последнего процесса этот системный вызов заканчивается с признаком ошибки - и это единственно возможное решение. Еще одна проблема - уничтожение физического представления портов. Она может решаться двумя путями: либо порт уничтожается, когда он закрывается последним из использующих его процессов, либо он уничтожается - специальным системным вызовом или простым закрытием - тем процессом, который его создал. Последний случай более привлекательный с точки зрения упорядочения доступа, но он может порождать больше ошибок, когда процессы-корреспонденты обращаются к уже несуществующему порту.
Средства взаимодействия, рассматриваемые нами ниже, являются частными случаями модели виртуальных коммуникационных портов.
Мониторы
8.8. Мониторы
Монитор представляет собой набор информационных структур и процедур, которые используются в режиме разделения. Некоторые из этих процедур являются внешними и доступны процессам пользователей, их имена представляют входные точки монитора. Пользователь не имеет доступа к информационным структурам монитора и может воздействовать на них, только обращаясь ко входным точкам. Монитор, таким образом, воплощает принцип инкапсуляции данных. В терминах объектно-ориентированного программирования ресурс, обслуживаемый монитором, представляет собой объект, а входные точки - методы работы с этим объектом. Особенностью монитора, однако, является то, что в его состав входят, так называемые, "процедуры с охраной", которые не могут выполняться двумя процессами одновременно.
Не являясь средством более мощным или гибким, чем рассмотренные выше примитивы, мониторы, однако, представляют значительно более удобный инструмент для программиста, избавляя его от необходимости формировать критические секции, обеспечивая более высокий уровень интеграции данных и предупреждая возможные ошибки во взаимном исключении.
Если в задаче "производители-потребители" процессы программируются пользователем, то вид этих процессов может быть таким: 1 #include <monitor.h> 2 /*== процесс-производитель (может быть отдельным модулем) ==*/ 3 void producer ( void ) { 4 portion work; 5 while (1) { 6 < производство порции в work > 7 putPortion ( &work ); 8 } 9 } 10 /*== процесс-потребитель (может быть отдельным модулем) ==*/ 11 void consumer ( void ) { 12 portion work; 13 while (1) { 14 getPortion ( &work ); 15 < обработка порции в work> 16 } 17 }
Обратим внимание на то, что процессы, во-первых, никоим образом не заботятся о разделении данных, во-вторых, не используют никакие общие данные. Такая "беззаботная" работа процессов, однако, должна быть поддержана монитором, входные точки которого описаны в файле monitor.h, а определение его имеет такой вид: 1 /*== монитор производителей-потребителей (отдельный модуль) ==*/ 2 #define BSIZE ... 3 /* буфер */ 4 static portion buffer [BSIZE]; 5 /* индексы буфера для чтения и записи*/ 6 static int rIndex = 0, wIndex = 0; 7 /* счетчик заполнения */ 8 static int cnt = 0; 9 /* события НЕ_ПУСТ, НЕ_ПОЛОН */ 10 static event nonEmpty, nonFull; 11 /*== процедура занесения порции в буфер ==*/ 12 void guard putPortion ( portion *x ) { 13 /* если буфер полон - ожидать события НЕ_ПОЛОН */ 14 if ( cnt == BSIZE ) wait (nonFull); 15 /* запись порции в буфер */ 16 memcpy ( buffer + wIndex, x, sizeof(portion) ) ; 17 /* модификация индекса записи */ 18 if ( ++wIndex == BSIZE ) wIndex = 0; 19 cnt++; /* подсчет порций в буфере */ 20 /* сигнализация о том, 21 что буфер НЕ_ПУСТ */ 22 signal (nonEmpty); 23 } 24 /*== процедура позучения порции из буфера ==*/ 25 void guard getPortion ( portion *x ) { 26 if ( cnt == 0 ) wait (nonEmpty); 27 memcpy ( x, buffer + rIndex, sizeof(portion) ) ; 28 if ( ++rIndex == BSIZE ) rIndex = 0; 29 cnt++; 30 signal (nonFull); 31 }
В реализации монитора нам пришлось прибегнуть к некоторым новым обозначениям. Во-первых, функции монитора даны с описателем guard (охрана). Это означает, что они должны выполняться в режиме взаимного исключения. В литературе часто употребляется образное сравнение мониторов с комнатой, в которой может находиться только один человек. Такая комната показана на Рисунке 8.2. Если человек (процесс) желает войти в комнату (охраняемую процедуру монитора), то он становится во входную очередь к двери 1, в которой он ожидает (блокируется) до тех пор, пока комната (монитор) не освободится. Дверь 1 (вход) отпирается только в том случае, если комната пуста, пропускает только одного человека и запирается за ним. Дверь 2 (выход) не заперта, когда она открывается, отпирается и дверь 1.
Может быть обеспечен если мы
Рисунок 8.1, может быть обеспечен, если мы введем массив done, каждый элемент которого свяжем с определенным событием. События пронумерованы и номер события является параметром функции, сигнализирующей о завершении события - finish и функции ожидания события - waitFor: 1 static char done[9] = {0,0,0,0,0,0,0,0,0}; 2 void finish ( int event ) { 3 done[event] = 1; 4 } 5 void waitFor ( int event ) { 6 while ( ! done[event] ); 7 }
Теперь работа процессов может быть синхронизирована таким образом (функциями типа WorkX() представлена работа, выполняемая процессом X): 1 processA() { 2 /* работа процесса A */ 3 workA(); 4 /* отметка о завершении процесса A */ 5 finish(0); 6 } 7 processB() { 8 /* ожидание завершения процесса A */ 9 waitFor(0); 10 /* работа процесса B */ 11 workB(); 12 /* отметка о завершении процесса B */ 13 finish(1); 14 } 15 . . . 16 processE() { 17 /* ожидание завершения процесса B */ 18 waitFor(1); 19 /* ожидание завершения процесса D */ 20 waitFor(3); 21 /* работа процесса E */ 22 workE(); 23 /* отметка о завершении процесса E */ 24 finish(4); 25 } 26 . . .
Можно сократить запись, например, так (используя естественную последовательность, заложенную в строках графа): 1 processABC() { 2 workA(); finish(0); 3 workB(); finish(1); 4 workC(); finish(2); 5 } 6 processDEF() { 7 waitFor(0); workD(); finish(3); 8 waitFor(1); workE(); finish(4); 9 waitFor(2); workF(); finish(5); 10 } 11 processGHI() { 12 waitFor(3); workG(); finish(6); 13 waitFor(4); workH(); finish(7); 14 waitFor(5); workI(); finish(8); 15 }
или иным образом (запишите самостоятельно) - с использованием последовательности в столбцах.
Находятся в глобальном тупике
5.3. Тупики: предупреждение, обнаружение, развязка
Борьба с тупиками включает в себя три задачи: предупреждение тупиков - какую стратегию распределения ресурсов выбрать, чтобы тупики не возникали вообще? обнаружение тупиков - если не удалось применить стратегию, предупреждающую тупики, то как обнаружить возникший тупик? развязка тупиков - если тупик обнаружен, то как от него избавиться?
Возможные стратегии распределения ресурсов располагаются между двумя полюсами - от самых либеральных до самых консервативных. Чем либеральнее стратегия, тем "охотнее" ОС удовлетворяет запросы на ресурсы. Но за слишком либеральную стратегию приходится расплачиваться возможностью возникновения тупика. Консервативные стратегии делают тупики невозможными в принципе, задачи обнаружения и развязки при применении таких стратегий не ставятся, но плата за это - частые отказы в выделении ресурсов, следовательно, снижение уровня мультипрограммирования, а следовательно, - и снижение пропускной способности. Ниже мы будем рассматривать стратегии предотвращения, двигаясь от консервативного полюса к либеральному в таком порядке: последовательное выделение; залповое выделение; иерархическое выделение; выделение по предварительным заявкам.
Нити
4.4. Нити
Философия дешевых процессов подразумевает, что процесс может быть создан легко и быстро. С одной стороны, это позволяет в максимальной степени обеспечивать распараллеливание работ по решению нескольких задач или внутри одной задачи. Но с другой стороны, если ОС выполняет большой объем работ по управлению ресурсами, то создание нового процесса и выделение ему ресурсов не может обойтись без значительных "накладных расходов". Преодоление этого противоречия было найдено в концепции "нитей" (thread, часто переводится также как "поток"), реализованной в большинстве современных ОС и зафиксированной в стандартах POSIX и DCE. Нитью называется отдельная ветвь выполнения процесса. Процесс может состоять из одной или нескольких нитей, которые совместно используют ресурсы процесса, но являются самостоятельными объектами при планировании процессорного времени. Таким образом, нити одного процесса могут выполняться параллельно. Концепция не оговаривает, какие именно ресурсы являются общими, а какие - локальными для нити. В большинстве современных ОС помимо ресурса процессорного времени и вектора состояния процесса, нить имеет собственный: вектор состояния, приоритет, стек (в стеке же размещаются и локальные переменные).
Прочие же ресурсы: общие переменные, файлы, средства взаимодействия и т. д. - являются общими для нити и породившего ее процесса.
Любой процесс состоит из одной или нескольких нитей. Первая нить - основная - порождается системой при запуске процесса. Основная нить может порождать дочерние нити вызовом типа: tid = createThread(thr_addr, stack).
Параметрами вызова являются: thr_addr - адрес нити; stack - адрес стека, выделяемого для нити (стек может также назначаться системой по умолчанию). Вызов возвращает идентификатор нити.
В программе (на языке C, например) нить выглядит как обычная функция. Вышеприведенный вызов передает управление на эту функцию и далее выполнение функции происходит параллельно с выполнением основной программы. Поскольку при порождении каждой новой нити выделяется отдельный стек, одна и та же функция может выполняться в составе двух и более параллельных нитей. При порождении новая нить наследует приоритет породившей ее, но далее этот приоритет может быть изменен. Отношения между основной и дочерней нитями похожи на отношения между процессами - родителем и потомком, рассмотренные в предыдущем разделе.
Для управления выполнением нитей в рамках одного процесса обычно в составе API ОС имеются системные вызовы, позволяющие приостановить выполнение нити и вновь разрешить ее выполнение: suspendThread(tid); resumeThread(tid);
Отметим две особенности, связанные с возможностью порождения нитей, которые создают некоторые дополнительные трудности для пользователей и для ОС. Во-первых, - трудность для пользователей - поскольку нити разделяют общие ресурсы процесса, на программиста ложится задача обеспечить корректность совместного использования ресурсов (см. главы 8 и 9). Во-вторых, - трудность для ОС - усложняется задача планировщика процессорного времени: теперь единицей планирования становится не процесс, а нить и планировщик должен обеспечивать справедливость распределения ЦП как между процессами, так и между нитями в каждом процессе.
Обедающие философы
5.2. Обедающие философы
Классической уже стала неформальная постановка задачи распределения ресурсов, носящая название "проблемы обедающих философов" и показанная на Рисунке 5.1.
Обедающие философы Тупик
Рисунок 5.1. Обедающие философы. Тупик
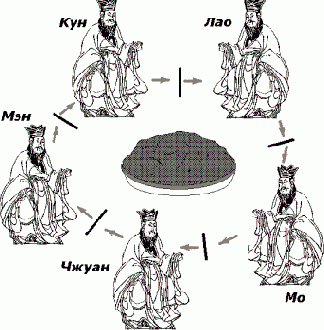
Пять философов сидят за круглым столом, в центре которого стоит блюдо с рисом. Между каждой парой философов лежит палочка для еды, палочек, следовательно, тоже пять. Для того, чтобы начать есть, философ должен взять две палочки - слева и справа от себя. Таким образом, если один из философов ест, его соседи справа и слева лишены такой возможности, так как им недостает палочек. Каждый философ "работает" по зацикленному алгоритму: сначала он некоторое время думает, затем берет палочки и ест, затем опять думает и т.д. Временные интервалы мышления и еды случайны, действия философов, следовательно, не синхронизированы. Ничего не говорится в условии о том, каким образом философ берет палочки, - наша задача как раз и состоит в том, чтобы обеспечить такую стратегию выделения палочек, которая бы исключала тупики и бесконечное откладывание.
Если мы установим, что каждый философ должен взять одну палочку и не выпускать ее из рук до тех пор, пока не возьмет вторую палочку, то мы можем получить ситуацию, показанную на
Объектноориентированная модель доступа и механизмы защиты
10.2. Объектно-ориентированная модель доступа и механизмы защиты
В главе 7 мы рассмотрели модель управления доступом применительно к файловой системе. Управление доступом к файлам является частным случаем более общей модели управления доступом субъектов к объектам. Другой частный случай мы рассмотрели в главе 3 применительно к памяти. Модель рассматривает объекты - элементы системы, которым требуется защита, и субъекты - активные элементы, стремящиеся получить доступ к объектам. Типичный пример объекта - файл, типичный пример субъекта - процесс. Элемент, выступающий в одной ситуации, в роли субъекта, в другой ситуации может выступать в роли объекта. Так, например, необходимо обеспечивать защиту адресных пространств одних процессов (объектов) от других процессов (субъектов).
Механизмы защиты должны обеспечивать ограничение доступа субъектов к объектам: во-первых, доступ к объекту должен быть разрешен только для определенных субъектов, во-вторых, даже имеющему доступ субъекту должно быть разрешено выполнение только определенного набора операций.
Для обеспечения защиты могут применяться следующие механизмы: кодирование объектов; сокрытие местоположения объектов; инкапсуляция объектов.
Кодирование предполагает шифрование информации, составляющей объект. Любой субъект может получить доступ к информации, но воспользоваться ею может лишь привилегированный субъект, знающий ключ к коду. Другой вариант защиты через кодирование предполагает, что расшифровка информации производится системными средствами, но только для привилегированных субъектов. Кодирование не защищает объект от порчи, поэтому оно может использоваться только для защиты узкого класса специфических объектов или в качестве дополнительного средства в сочетании с другими механизмами защиты. Рассмотрение способов кодирования не входит в задачи нашего пособия, оно должно происходить при изучении курса "Защита информации".
Сокрытие местоположения объекта предполагает, что адрес объекта в памяти системы известен только тем субъектам, которые имеют право доступа к объекту. Такие привилегированные субъекты могут выполнять любые операции над объектом. Непривилегированные субъекты могут запрашивать доступ к объекту и получать некий внутренний идентификатор объекта. Используя этот идентификатор, они могут выполнять над объектом ограниченный набор операций, но не непосредственно, а обращаясь к привилегированным субъектам. Примером такого механизма является сокрытие дескрипторов ресурсов. Местоположение (адрес в памяти) дескрипторов известно ОС, прикладные же процессы получают манипулятор ресурса, который, как правило, адресует дескриптор только косвенно (через таблицы). Если сокрытие является единственным механизмом защиты, то защиту нельзя назвать непроницаемой. Субъект может получить адрес объекта случайно или намеренно (получив доступ к внутренней документации).
Инкапсуляция предполагает полное закрытие для субъектов возможности оперирования с внутренним содержимым объектов. Субъект даже не должен знать структуры этого содержимого. Для каждого объекта, однако, определено множество допустимых операций над ним, которые реализуются монитором объекта. Объект, таким образом, предстает в виде "черного ящика" с четко специфицированными входами и выходами и с абсолютно непроницаемыми стенками. Механизм инкапсуляции может обеспечивать наиболее полную защиту, но его реализация требует решения двух важных вопросов: во-первых, как обеспечить "непрозрачность стенок", во-вторых, как принимать решения о предоставлении доступа или об отказе в нем.
Непроницаемость ящика обеспечивается чаще всего средствами защиты памяти. Область памяти, в которой расположен объект, делается недоступной для любых субъектов, кроме монитора, реализующего операции над объектом. Как мы знаем (см. главу 3), защита памяти поддерживается аппаратными средствами вычислительных систем, и защита объектов, таким образом, представляется реализованной на аппаратном уровне. Надежность такой защиты, однако, в значительной степени иллюзорна. Во-первых, память также представляет собой объект, нуждающийся в защите. От того, насколько сама защита памяти защищена от перепрограммирования ее произвольным субъектом, зависит эффективность всей системы защиты в целом. Во-вторых, аппаратно поддерживается только конечное число уровней защиты памяти, на практике же используются только два уровня: доступ к ограниченному подмножеству адресов и полный доступ. Если в системе имеется большое количество объектов разного типа, то каждый тип обеспечивается своим монитором. Если все мониторы работают с полным доступом, то нет гарантии в том, что монитор в результате, например, ошибки в нем не воздействует на объект, не предусмотренный в данной операции.
Наиболее надежным образом защита памяти достигается при помощи изоляции адресных пространств процессов и мониторов. Если таблицы дескрипторов ресурсов и сами ресурсы располагаются в отдельных адресных пространствах, то процесс просто не может получить к ним доступа, а может воздействовать на них только косвенно, передавая в системном вызове индекс элемента в недоступной для него таблице. Адресные пространства различных мониторов тоже могут быть изолированы друг от друга, что (при надежной изоляции) исключит воздействие ошибки в мониторе на другие ресурсы.
Для каждого объекта определено множество допустимых для него операций. Применительно к файлам, например, возможны в общем случае следующие операции: Read - получение информации из объекта; Write - обновление информации в объекте; Append - добавление в объект новой информации (не изменяя старой); Execute - интерпретация объекта как исполняемого кода; Delete - уничтожение объекта; Getinfo - получение информации об объекте; Setinfo - установка информации об объекте; Privilege - установка прав доступа к объекту (частный случай Setinfo, по понятным причинам выделенный в отдельную операцию).
Неизбыточный набор операций повышает надежность объекта, лишая потенциального "взломщика" возможностей воздействовать на объект. Так, например, для объекта "программа" могут отсутствовать операции Read и Write. Действие всех компьютерных вирусов заключаются в том, что они читают программный файл, как файл данных, и дописывают в него (как в файл данных) коды, выполняющие несанкционированные действия. Если программу невозможно читать и писать, то у вируса просто нет возможности "заразить" ее своим кодом.
Перечень всех операций, допустимых для данной пары субъект-объект, составляет привилегию доступа (access privilege) или право доступа (access right) данного субъекта к данному объекту.
Каждая пара субъект-объект при каждом акте доступа взаимодействует в определенном режиме доступа (access mode). Условием разрешения доступа является совпадение запрошенного субъектом режима доступа с его привилегиями по отношению к запрошенному объекту.
Проведение политики контроля доступа включает в себя процедуры аутентификации и авторизации, показанные на Рисунок 10.1.
Общие области памяти
9.4. Общие области памяти
Два и более процессов могут использовать одну и ту же физическую область памяти. Наиболее просто это достигается в тех моделях памяти, которые обеспечивают динамическую трансляцию адресов. Напомним, что каждый процесс имеет собственную таблицу сегментов или страниц, в которой содержится, помимо прочего, базовый адрес сегмента/страницы в физической памяти. Для разделяемой области памяти создается по элементу в таблице для каждого процесса, ее использующего. В чисто страничной модели, однако, возникают трудности, связанные с тем, что разделяемая область памяти может иметь объем, некратный размеру страницы, обычно в таких случаях разделяемая область выравнивается до границы страницы. В сегментной или сегментно-страничной модели таких проблем нет. Поскольку для каждого процесса разделяемый сегмент описывается своим дескриптором, права доступа к сегменту могут быть установлены различными для разных процессов.
В случае именованных областей памяти один процесс создает общую область памяти: vAddr = createNamedMemorySegment(segmentName, segmentSize);
а второй ее "открывает": vAddr = openNamedMemorySegment(segmentName);
В этих вызовах segmentName - имя области, segmentSize - ее размер. Оба вызова возвращают виртуальный адрес общей области памяти в виртуальном адресном пространстве процесса - vAddr.
Для неименованной области памяти создание области осуществляется вызовом: vAddr = createMemorySegment(segmentSize);
а "открытие": vAddr = openMemorySegment(hostAddr, hostPid);
где hostAddr - виртуальный адрес области памяти у процесса-создателя области, hostPid - идентификатор процесса-создателя области. Этот вызов возвращает виртуальный адрес области в адресном пространстве процесса, открывшего область.
Разумеется, в составе API имеются системные вызовы "закрытия"/уничтожения общей области памяти.
Разделяемые области памяти, однако, порождают ряд проблем как для программистов, так и для ОС. Проблемы программистов - те, что рассматривались в предыдущем разделе: взаимное исключение процессов при доступе к общей памяти. Программисты могут дифференцировать права доступа для процессов или организовать взаимное исключение, используя семафоры (см. ниже). Проблемы ОС - организация свопинга. Очевидно, что вероятность вытеснения разделяемого сегмента или страницы должна быть тем меньше, чем больше процессов разделяют этот сегмент/страницу. Если каждый процесс имеет собственный дескриптор разделяемого сегмента или страницы, то учет использования сегмента или страницы (поля used и dirty) будут вестись по каждому процессу отдельно. ОС должна обрабатывать, например, такой случай: два процесса - A и B - разделяют сегмент; процесс A произвел запись в сегмент и в его дескрипторе сегмент помечен, как "грязный". В то время, когда активен процесс B, принимается решение о вытеснении этого сегмента из памяти. Но в дескрипторе процесса B этот сегмент имеет признак "чистый", поэтому сегмент может быть освобожден в физической памяти без сохранения на внешней памяти и изменения в сегменте, сделанные процессом A, будут утеряны. ОС приходится вести отдельную таблицу разделяемых сегментов, в которой отражать истинное их состояние.
С точки зрения идентификации разделяемые области памяти могут рассматриваться как виртуальные коммуникационные порты. Для общей области может быть по соглашению между разработчиками взаимодействующих процессов установлено внешнее имя, которое будет использовано для получения доступа. (В Windows 95, например, такие области называются "файлами отображаемой памяти" - memory mapped file - и для установления доступа к ним используются системные вызовы типа create и open). Для неименованных областей памяти возможна передача селектора (номера в таблице дескрипторов) от одного процесса к другому.
В системах, которые ориентированы на процессор Intel-Pentium, может использоваться то обстоятельство, что адресация возможна через две таблицы дескрипторов - LDT и GDT. За счет этого общее адресное пространство процесса может достигать 4 Гбайт. Из них младшие 2 Гбайт адресуются через LDT а старшие - через GDT. Глобальная таблица дескрипторов - общая для всех процессов, и именно она может использоваться для доступа к совместно используемой памяти. Размещение в общих виртуальных адресах удобно для системных программ и динамических библиотек, к которым происходят частые обращения из приложений: если эти компоненты ОС находятся в адресном пространстве процесса, то обращения к ним не требуют переключения контекста. Но с другой стороны, это снижает надежность: если системные компоненты доступны для приложения, то они могут быть им испорчены. Поэтому такая "роскошь" может быть допущена только в однопользовательских системах.
Общие требования безопасности
10.1. Общие требования безопасности
В системе ценностей современного мира информация занимает одно из ведущих мест, и рейтинг ее в этой системе возрастает с течением времени почти экспоненциально. Как всякая ценность, информация должна быть надежно защищена. Защита информации достигается комплексом мер безопасности (security), включающим в себя как обеспечение целостности (непротиворечивости) и сохранности информации, так и контроль доступа к ней.
Требования к безопасности - целостности, сохранности и конфиденциальности пользовательских и системных программ и данных, а также к потреблению ресурсов пользователями в пределах установленных им бюджетов всегда являлось одним из важнейших в вычислительных системах. В обеспечении этих требований был некоторый период "тяжелых времен" - в начале бума персональных компьютеров, что было связано с внедрением в сферу полупрофессионального использования вычислительной техники большого числа неподготовленных лиц с задачами, ценность которых не стоила расходов по обеспечению их безопасности. Но с неизбежным разделением сфер использования компьютеров на персональную и производственную вопросы безопасности в производственной сфере не только восстанавливают свои позиции, но и приобретают все больший вес в связи с развитием компьютерных коммуникаций. В настоящее время все сколько-нибудь серьезные пользователи в производственной сфере готовы платить за гарантии безопасность в своей работе - как материальными затратами, так и некоторым снижением эффективности выполнения своих приложений.
Целостность информации - обеспечение непротиворечивости данных. Правила целостности определяются законами прикладной области, к которой относится информация, так называемыми, бизнес-правилами. Поскольку ОС является универсальным программным обеспечением, предназначенным для поддержки выполнения процессов обработки данных практически любых прикладных областей, поддержание целостности прикладных данных не входит в ее функции. Целостность, определяемая пользователем, поддерживается средствами промежуточного программного обеспечения, наиболее развиты эти средства в системах управления базами данных. Целостность же, за которую отвечает ОС, - это целостность общей структуры хранения информации, прежде всего она касается файловой системы. Целостность файловой системы состоит в соответствии метаданных файловой (дисковых и файловых справочников) системы реальному ее состоянию. В задачи ОС входит также обеспечение сохранности данных при ошибках. Ошибок не должно быть при правильном функционировании всех звеньев вычислительной системы, но такое функционирование относится к области идеалов Источниками ошибок являются ошибки в системном программном обеспечении, сбои оборудования и неправильные (иногда - злонамеренные) действия пользователей. Первые - возможны, вторые - неизбежны, третьи - гарантированы. Применительно к данным на внешней памяти мы уже рассматривали методы защиты целостности и сохранности в разделах главы 7, такие методы (избыточность, резервное копирование, дополнительные указатели) применимы и к другим ресурсам вычислительной системы.
Контроль доступа - обеспечение доступа к информации только тому, кто имеет на это право. Этот аспект безопасности является основным предметом рассмотрения в данной главе. В современных системах обработки данных применяется обязательное или избирательное управление безопасностью.
Основными понятиями обязательного управление безопасность являются уровень секретности и уровень доступа. Каждый объект, включенный в систему защиты, имеет некоторый уровень секретности (например: совершенно секретно, секретно, для служебного пользования и т.д.). Каждый пользователь, получающий доступ к защищенным ресурсам имеет некоторый уровень допуска. Число уровней допуска равно числу уровней секретности. Если обозначить уровни секретности и уровни допуска числовыми кодами, таким образом, чтобы больший числовой код соответствовал большей секретности или более высокому допуску, то правила предоставления разрешений на доступ к ресурсам можно сформулировать следующим образом: пользователь получает разрешение на чтение объекта только в том случае, если его уровень допуска равен уровню секретности объекта или больше его; пользователь получает разрешение на запись в объект или модификацию объекта только в том случае, если его уровень допуска равен уровню секретности объекта.
Другими словами второе правило можно сформулировать так: любая информация, записанная пользователем с уровнем допуска L получает уровень секретности L. Таким образом, например, пользователь, имеющий допуск к совершенно секретной информации, не может записать информацию в открытый документ для служебного пользования (документ с более низким уровнем секретности), так как это может нарушить безопасность.
Избирательное управление безопасностью базируется на правах доступа. В случае избирательного управления каждый пользователь обладает определенным правами доступа к определенным ресурсам. Права доступа разных пользователей к одному и тому же ресурсу могут различаться. Избирательное управление часто базируется на принципе владения. В этом случае у каждого ресурса имеется владелец, который обладает всей полнотой прав доступа к ресурсу. Владелец определяет права доступа к своему ресурсу других пользователей.
Министерством обороны США разработана общая классификация уровней безопасности, которая применяется и во всем мире. Эта классификация определяет четыре класса безопасности (в порядке возрастания): D - минимальная защита: C - избирательная защите (с подклассами C1 и С2; C1 < C2); B - обязательная защита (с подклассами B1 < B2 < B3); A - проверенная защита (с математическим доказательством адекватности).
На сегодняшний день некоторые компьютерные системы в бизнесе удовлетворяют требованиям класса B1, однако, большинство коммерческих применений компьютерных систем ограничиваются требованиями класса C2.
Основные требования класса C2 сводятся к следующим: владелец ресурса должен управлять доступом к ресурсу; ОС должна защищать объекты от несанкционированного использования другими процессами (в том числе, и после их удаления); перед получением доступа к системе каждый пользователь должен идентифицировать себя, введя уникальное имя входа в систему и пароль; система должна быть способной использовать эту уникальную информацию для контроля действий пользователя; администратор системы должен иметь возможность контроля (audit) связанных с безопасностью событий, доступ к этим контрольным данным должен ограничиваться администратором; система должна защищать себя от внешнего вмешательства типа модификации выполняющейся системы или хранимых файлов.
Сертификация на соответствие уровню безопасности - длительный процесс, и ему подвергается не только программное обеспечение, а весь комплекс средств системы обработки данных, включая аппаратные, системные и прикладные программные средства, каналы связи, организация эксплуатации системы и т.д. Но операционная система может оцениваться на предмет того, может или не может она поддерживать функционирование системы обработки данных, соответствующей определенному уровню.
Очереди сообщений
9.7. Очереди сообщений
Очереди воплощают модель взаимодействия процессов "много отправителей - один получатель". Эту модель часто называют почтовым ящиком (mailbox) из-за сходства с почтовым ящиком, висящим на дверях каждой квартиры.
Процесс-получатель является владельцем очереди, он создает очередь, а остальные процессы получают к ней доступ, "открывая" ее. Очередь обычно имеет внешнее имя. Передача данных в очереди происходит всегда сообщениями, причем каждое сообщение имеет заголовок и тело. Заголовок всегда имеет фиксированный для данной системы формат. В него обязательно входит длина сообщения, а другая информация зависит от спецификаций конкретной системы: это может быть приоритет сообщения, тип сообщения, идентификатор процесса, пославшего сообщение и т.п. Тело сообщения интерпретируется по правилам, устанавливаемым самими процессами - отправителем и получателем. Заголовок и тело представляют собой существенно разные структуры данных и располагаются в разных местах в памяти. Собственно очередь (чаще всего - линейный список) ОС составляет из заголовков сообщений. В элементы очереди включаются указатели на тела сообщений, располагающиеся в памяти системы или процессов (об этом - ниже).
Как правило, возможности процесса-получателя сообщений не ограничиваются чтением по дисциплине FIFO, ему предоставляется более богатый выбор дисциплин: LIFO, по приоритету, по типам, по идентификаторам отправителя и т.п. В распоряжении владельца имеются также средства определения размера очереди, а возможно, и просмотра очереди - неразрушающего чтения из нее. В распоряжении процесса-отправителя имеется только вызов типа sendMessage - посылки сообщения в очередь. Если при попытке процесса послать сообщение обнаруживается, что очередь заполнена, процесс-отправитель блокируется. Это, впрочем, довольно редкий случай, так как системные ограничения на размер очередей никогда не бывают слишком жесткими. Процесс-получатель блокируется при попытке читать сообщение, когда очередь пуста.
Существенным вопросом при конструировании механизма очередей является вопрос о включении или невключении в ОС системной буферизации сообщений. При включении такого средства (Рисунок 9.2) тело посылаемого сообщения копируется в системную область памяти, а при чтении - копируется из нее в адресное пространство процесса-получателя. При отсутствии системной буферизации тела сообщений хранятся в общей для отправителя и получателя памяти, а передается только указатель на тело сообщения (Рисунок 9.3). В первом случае выполняются дополнительные пересылки, затрачивается дополнительная память и вводятся более жесткие ограничения на объем сообщений, но достигается надежность передачи и значительно более простой интерфейс процессов. Во втором случае значительно экономится память, но сами процессы должны заботиться об управлении совместно используемой памятью и о сохранности сообщений в ней. При отсутствии системной буферизации сообщений применяются обычно два метода передачи тела сообщения: либо процесс-отправитель помещает тело сообщения в отдельный разделяемый сегмент, получает у ОС манипулятор этого сегмента для процесса-получателя и передает этот манипулятор в составе сообщения; либо для всех сообщений выделяется одна общая область памяти с общим манипулятором, и для размещения сообщения в нем используются системные вызовы выделения памяти в куче.
Односегментная модель
3.3. Односегментная модель
Нам неизвестны ОС, поддерживающие односегментную модель "в чистом виде", но ее рассмотрение облегчит понимание более сложных моделей.
Внешне (с точки зрения программиста) эта модель очень похожа на модель с фиксированными разделами: программа-процесс готовится в плоском виртуальном адресном пространстве. Процесс занимает непрерывное пространство виртуальной памяти, и в реальную память он также загружается в один непрерывный раздел (сегмент). Сегмент может начинаться с любого адреса реальной памяти и иметь любой раздел, не превышающий, однако, размера реальной памяти. Существенное отличие сегментной модели состоит в том, что она использует аппаратную динамическую трансляцию адресов. Загруженный в реальную память и выполняющийся процесс продолжает обращаться к памяти, используя виртуальные адреса, и лишь при каждом конкретном обращении виртуальный адрес аппаратно переводится в реальный. В вычислительной системе, поддерживающей односегментную модель, должен существовать регистр дескриптора сегмента, содержимое которого состоит из двух полей: начального (базового) адреса сегмента в реальной памяти и длины сегмента. Когда процесс размещается в памяти, для выделенного ему сегмента формируется дескриптор, который записывается в вектор состояния в контексте процесса. При переключении контекста дескриптор сегмента загружается в аппаратный регистр дескриптора сегмента и служит той "таблицей трансляции", по которой аппаратура переводит виртуальные адреса в реальные. Сама трансляция адресов происходит по простейшему алгоритму. Поскольку виртуальное адресное пространство процесса представляет собой линейную последовательность адресов, начинающуюся с 0, виртуальный адрес является простым смещением относительно начала сегмента. Реальный адрес получается сложением виртуального адреса с базовым адресом, выбранным из дескриптора сегмента, как показано на Рисунке 3.4. Единственный путь для выхода процесса за пределы своего виртуального адресного пространства - задание виртуального адреса, большего, чем размер сегмента. Этот путь легко может быть перекрыт, если аппаратура при трансляции адресов будет сравнивать виртуальный адрес с длиной сегмента и выполнять прерывание-ловушку, если виртуальный адрес больше.
Рисунок 3.4. Односегментная модель

То обстоятельство, что процесс работает в виртуальных адресах, делает возможным перемещение сегментов в реальной памяти. Переместив процесс в другую область реальной памяти, ОС просто изменяет поле базового адреса в дескрипторе его сегмента. Поскольку, как и в модели с фиксированными разделами, реальная память распределяется непрерывными блоками переменной длины, здесь применяются те же стратегии размещения. Но возможное здесь перемещение сегментов является эффективным способом борьбы с внешними дырами. Сегменты переписываются в реальной памяти таким образом, чтобы свободных мест между ними не оставалось, все свободное пространство сливается в один большой свободный блок и, таким образом, оказывается доступным для последующего распределения.
Другой возможностью, которую открывает динамическая трансляция адресов, является вытеснение сегментов. Если даже после перемещения сегментов запрос на память не может быть удовлетворен, то ОС может переписать какой-либо сегмент на внешнюю память и освободить занимаемую им реальную память. Поскольку контекст процесса, который содержится в вытесненном сегменте, сохраняется, то впоследствии ОС может вновь загрузить этот сегмент в реальную память, откорректировать базовый адрес в его дескрипторе и возобновить выполнение процесса. Перемещение сегментов и (см. ниже) страниц между оперативной и внешней памятью и наоборот называется свопингом (swapping), а составные его части - вытеснением (swap out) и подкачкой (swap in). Поскольку в модели происходит вытеснение сегментов, должна быть реализована какая-то его стратегия. Естественно, что наилучшим кандидатом на вытеснение должен быть сегмент процесса, находящегося в заблокированном состоянии. Но следует при этом иметь в виду, что процесс может быть заблокирован потому, что он ожидает завершения операции ввода/вывода. При вводе/выводе, использующем канал или прямой доступ к памяти, аппаратура ввода/вывода не выполняет трансляцию адресов (см. главу 6), а производит обмен данными с областью памяти, реальный адрес которой был задан ей при инициировании операции. Сегмент, участвующий в такой операции ввода/вывода, должен быть заблокирован не только от вытеснения, но и от перемещения в реальной памяти. (Эти же соображения должны учитываться и в других моделях памяти). При отсутствии подходящих кандидатов на вытеснение в очереди заблокированных процессов жертва может быть выбрана из очереди готовых процессов. Естественно назначить жертвой процесс, имеющий самый низкий приоритет у планировщика процессов. Но если брать этот приоритет единственным критерием, то имеется потенциальная опасность возникновения избыточных перемещений. Процесс, имеющий низкий приоритет, может быть несколько раз вытеснен и вновь подкачан, но между всеми подкачками и вытеснениями может так и не получить ни одного кванта обслуживания на центральном процессоре. В системах с динамическими приоритетами процесс (например, Unix), подкачанный в оперативную память защищается от вытеснения некоторой временной выдержкой, в течение которой он имеет шанс повысить свой приоритет и получить квант обслуживания. Также и вытесненный процесс должен быть некоторое время выдержан на внешней памяти прежде чем он может быть подкачан. В системах со статическими приоритетами приоритет процесса у планировщика определяет и его приоритет в очереди к ресурсу реальной памяти.
Процесс, работающий в односегментной модели, памяти имеет возможность динамически изменять размер своего виртуального адресного пространства. При выполнении такого запроса от процесса ОС просто изменяет поле длины в дескрипторе его сегмента, если в реальной памяти вслед за сегментом процесса имеется свободный участок достаточного размера. Если же такого участка нет, ОС может переместить процесс или заблокировать его в ожидании освобождения ресурса.
Одноуровневая модель памяти
3.8. Одноуровневая модель памяти.
Дальнейшее расширение разрядной сетки процессоров может привести к появлению совершенно новых моделей памяти. Сейчас трудно с уверенностью прогнозировать, какая модель будет доминировать, на сегодняшний день большинство 64-разрядных ОС представляют собой клоны Unix, и расширенный виртуальный адрес используется в них для отображения в память файлов. Более активно использует 64-разрядный адрес AS/400. На примере последней мы и рассмотрим одноуровневую (single-level) модель памяти. Эта модель была реализована уже в System/38 и в ранних моделях AS/400 на базе 48-разрядного адреса, но мы сосредоточимся на ее 64-разрядной реализации в Advanced Series на процессоре Power PC
Отметим прежде всего, что эта "новая" модель памяти на самом деле является "хорошо забытой старой": в вычислительной системе Atlas (Англия, 1966г.) - первой системе с виртуальной памятью - была реализована именно эта модель. Впоследствии эта модель не нашла применения из-за ограниченных возможностей аппаратных средств, современное же состояние аппаратных средств позволяет вновь к ней вернуться на качественно ином уровне.
64-разрядное адресное слово позволяет процессу иметь плоскую виртуальную память размером до 64 Эбайт (эксабайт). В AS/400 эта возможность позволяет реализовать два принципиально важных свойства модели памяти: в виртуальное адресное пространство процесса включается не только оперативная память (memory), но вся память (storage) - и оперативная и внешняя - имеющаяся в системе; все процессы работают в одном и том же виртуальном адресном пространстве, разделяя его.
В традиционных системах любые объекты - обрабатываемые или выполняемые - должны быть прежде размещены в памяти. Это не обязательно означает их размещения в реальной оперативной памяти, такое размещение может быть отложено и выполняться по требованию механизмами подкачки сегментов или страниц, но виртуальная память процесса должна быть сформирована - в виде таблиц сегментов и/или страниц. В системе с одноуровневой памятью, строго говоря, концепция памяти отсутствует, она заменена концепцией пространства (space). Новосозданный процесс сразу получает свое распоряжение пространство (виртуальное адресное пространство), в котором уже размещены все имеющиеся в системе объекты, в том числе и программные коды процесса. Имеется также достаточно пространства для размещения любых новых объектов. Для работы с объектом процесс должен не разместить его в памяти, а только получить его адрес в пространстве. Для процесса прозрачно местонахождение объекта - в оперативной или на внешней памяти. Физически все объекты размещаются именно на внешней памяти, а оперативная память (ее размер исчисляется сотнями Мбайт) используется почти исключительно как пул страничных кадров.
Одноуровневая модель делает излишним API, связанный с управлением памятью, поскольку процессам нет необходимости запрашивать и освобождать память. Системные вызовы этой группы заменяются вызовами доступа к объектам. Защита памяти, таким образом, реализуется в рамках более общего механизма контроля доступа, который мы подробнее рассмотрим в главе 10. Задача же совместного использования памяти решается совершенно элементарно, так как все процессы работают в одном виртуальном адресном пространстве.
Плоская структура адресного пространства в одноуровневой модели снимает необходимость в сегментной фазе динамической трансляции адреса. В процессоре Power PC имеется возможность программного отключения трансляции сегмента в аппаратном процессе трансляции адреса. AS/400 может работать как в режиме с сегментацией, так и без нее. Режим с сегментацией включается только при повышенном уровне защиты.
Размер страницы в современных моделях AS/400 - 4Кбайт. Даже в процессоре Intel80386 таблица страниц для 32-разрядного адресного пространства не размещается в оперативной памяти и применяется двухэтапная трансляция номера страницы, как же решается эта проблема для 64-разрядного адресного пространства? Здесь применяется, так называемая, инверсная таблица страниц. В оперативной памяти хранятся дескрипторы не всех виртуальных страниц, а только тех, которые уже размещены в оперативной памяти. Поскольку виртуальное адресное пространство общее для всех процессов, таблица страниц также одна. При трансляции виртуального адреса требуемая страница прежде всего ищется в таблице страниц реальной памяти, а при неуспешном результате такого поиска - на внешней памяти. Для поиска в таблице страниц применяется метод хеширования. 64-разрядный виртуальный адрес путем несложных преобразований, состоящих их ряда побитовых логических операций, преобразуется в номер элемента таблицы страниц. Число элементов в таблице страниц зависит от размера оперативной памяти в системе и выбирается таким образом, что таблица страниц занимает фиксированный процент реальной оперативной памяти. Поскольку разрядность номера элемента значительно меньше разрядности виртуального адреса в процессе преобразования виртуальных адресов неизбежны коллизии - случаи преобразования разных виртуальных адресов в один и тот же номер элемента. Поэтому в элементе таблицы страниц зарезервировано место для нескольких (восьми) дескрипторов страниц, и после выбора элемента продолжается линейный поиск страницы в элементе таблицы. В таблице страниц также предусмотрена область переполнения - для случая, если число коллизий на один элемент таблицы превысит размер элемента, но на практике до ее использования дело не доходит.
Механизм поиска в таблице страниц может показаться достаточно сложным и времяемким, но, во-первых, архитектура микропроцессора Power PC включает в себя конвейер, а во-вторых, значительный объем ассоциативного буфера страниц (512 и более элементов) позволяет более чем в 90% случаев даже не производить поиск в таблице страниц.
В случае, если страница не найдена в таблице, генерируется прерывание-ловушка - страничный отказ. Модуль управления памятью в микроядре при обработке этой ловушки рассматривает виртуальный адрес как адрес на внешней памяти и передает его подсистеме ввода-вывода для подкачки страницы в оперативную память. Подкачка может потребовать освобождения страничного кадра - применяется дисциплина замещения LRU в пределах страничного пула, выделенного данному процессу. В системе предусмотрена возможность также и использования реальных адресов памяти - оперативной и внешней, но команды, работающие с ними, используются только ниже уровня интерфейса MI и недоступны даже для OS/400.
Операционная система процессы оборудование
Рисунок 1.4. Операционная система, процессы, оборудование

Как видно из рисунка, ОС играет роль "прослойки" между процессами пользователей и оборудованием системы. (Под оборудованием понимаются, как правило, внешние устройства, но можно трактовать этот термин и шире - включая в него все первичные ресурсы). Процессы пользователей не имеют непосредственного доступа к оборудованию и, говоря шире, к системным ресурсам. Если процессу необходимо выполнить операцию с системным ресурсом, в том числе, и с оборудованием, процесс выдает системный вызов. ОС интерпретирует системный вызов, проверяет его корректность, возможно, помещает в очередь запросов и выполняет его. Если выполнение вызова связано с операциями на оборудовании, ОС формирует и выдает на оборудование требуемые управляющие воздействия. Оборудование, выполнив операцию, заданную управляющими воздействиями, сигнализирует об этом прерыванием. Прерывание поступает в ядро ОС, которое анализирует его и формирует отклик для процесса, выдавшего системный вызов. Если выполнение системного вызова не требует операций на оборудовании, отклик может быть сформирован немедленно.
Управляющие воздействия и прерывания составляют интерфейс оборудования, системные вызовы и отклики на них - интерфейс процессов. В качестве синонима интерфейса процессов мы в соответствии со сложившейся в последнее время традицией часто будем употреблять аббревиатуру API (Application Programm Interface - интерфейс прикладной программы).
Отделение процессов пользователя от оборудования преследует две цели.
Во-первых, - безопасность. Если пользователь не имеет прямого доступа к оборудованию и вообще к системным ресурсам, то он не может вывести их из строя или монопольно использовать в ущерб другим пользователям. Обеспечение этой цели нуждается в аппаратной поддержке, рассматриваемой в следующем разделе.
Во-вторых, - обеспечение абстрагирования пользователя от деталей управления оборудованием. Вывод на диск, например, требует сложного программирования контролера дискового устройства, однако, все пользователи используют для этих целей простое обращение к драйверу устройства. Более того, в большинстве систем имеются библиотеки системных вызовов, обеспечивающие API для языков высокого уровня (прежде всего - для языка C). Можно также говорить о том, что ОС интегрирует ресурсы: из ресурсов низкого (физического) уровня она конструирует более сложные ресурсы, которые с одной стороны сложнее (по функциональным возможностям), а с другой стороны - проще (по управлению) низкоуровневых.
Операционная система с точки зрения системного программиста
1.1. Операционная система с точки зрения системного программиста
| Операционная система (ОС) есть набор программ, которые распределяют ресурсы процессам. |
Приведенная выше формулировка является ключевой для понимания всего курса. Прежде, чем мы ее раскроем, дадим определение входящих в нее терминов. Ресурс - "средство системы обработки данных, которое может быть выделено процессу обработки данных на определенный интервал времени" [4]. Простыми словами: ресурс - это все те аппаратные и программные средства и данные, которые необходимы для выполнения программы. Ресурсы можно подразделить на первичные и вторичные. К первой группе относятся те ресурсы, которые обеспечиваются аппаратными средствами, например: процессор, память - оперативная и внешняя, устройства и каналы ввода-вывода и т.п. Ко второй группе - ресурсы, порождаемые ОС, например, системные коды и структуры данных, файлы, семафоры, очереди и т.п. В последнее время в связи с развитием распределенных вычислений и распределенного хранения данных все большее значение приобретают такие ресурсы как данные и сообщения.
В [8] приведено около десятка определений термина "процесс", из которых автор выбирает: "программа в стадии выполнения". Это определение близко к тому, что интуитивно понимают под "процессом" программисты, но оно не является строгим. Более строгое определение процесса, которое дает терминологический стандарт, представляется нам гораздо более удачным, поэтому ниже мы приводим его полностью.
"Процесс обработки данных - система действий, реализующая определенную функцию в системе обработки информации и оформленная так, что управляющая программа данной системы может перераспределять ресурсы этой системы в целях обеспечения мультипрограммирования.
Примечания: Процесс характеризуется состояниями, которые определяются наличием тех или иных ресурсов в распоряжении процесса и, следовательно, возможностью фактически выполнять действия, относящиеся к процессу. Перераспределение ресурсов, выполняемое управляющей программой, влияет на продолжительность процесса обработки данных, но не на его конечный результат. Процесс оформляют с помощью специальных структур управляющих данных, которыми манипулирует управляющий механизм. В конкретных системах обработки информации встречаются разновидности процессов, которые различаются способом оформления и составом ресурсов, назначаемых процессу и отнимаемых у него, и допускается вводить специальные названия для таких разновидностей, как, например, задача в операционной системе ОС ЕС ЭВМ" [4].
(В соответствии со сложившейся в литературе традицией, мы часто будем употреблять термин "задача" как синоним термина "процесс".)
На примечания к определению процесса мы обратим внимание позже, а пока сосредоточимся на основной его части. С точки зрения ОС процесс - это "юридическое лицо", которое получает в свое распоряжение ресурсы. Процесс может иметь сложную структуру, но его составные части либо оформляются как отдельные процессы и тогда предстают перед ОС как независимые от процесса-родителя "юридические лица", либо используют ресурсы от имени всего процесса и тогда они "невидимы" для ОС. (Промежуточный случай - нити - мы рассматриваем в главе 4)
Такой взгляд на разработку и анализ ОС сложился в конце 60-х - начале 70-х годов, в значительной степени под влиянием ОС Unix [5, 24], в которой принцип процессов и ресурсов реализован наиболее последовательно и изящно. Большое количество изданий, посвященных ОС и отражающих как эмпирический (например, [8, 14, 27]), так и аналитический (например, [1, 2, 12]) подходы, разделяет именно такой взгляд. Следование принципу процессов-ресурсов позволяет структурировать изучение ОС в виде таблицы, приведенной на рисунке 1.1. Столбцами этой таблицы являются классы ресурсов, которыми управляют ОС, а строками - конкретные ОС.
Операционные системы и ресурсы
Рисунок 1.1. Операционные системы и ресурсы

В идеале исчерпывающее изложение курсов "Системное программное обеспечение ЭВМ" и "Операционные системы" должно привести к заполнению всех клеток этой таблицы, но в первой части данного учебного курса мы сосредоточили внимание на изучении "структуры записи" (строки) этой таблицы. Владение этой структурой позволит специалисту самостоятельно заполнить пробелы в таблице и при необходимости дополнить таблицу новыми строками. В связи с конкурентной борьбой на рынке программных продуктов описания современных ОС, появляющиеся в печати, по большей части акцентируют внимание на тех свойствах, которые придают системе "товарный вид", хотя и необязательно определяют фундаментальные возможности и эффективность системы. Понимание таких возможностей вооружает специалиста инструментом для сравнительного анализа различных ОС по общим объективным критериям.
Попытку "эскизного" заполнения таблицы рис 1.1 мы делаем во второй части.
Планирование процессов по дисциплине FCFS
Рисунок 2.2. Планирование процессов по дисциплине FCFS

RR (round robin - карусель) - простейшая дисциплина с вытеснением. Процесс получает в свое распоряжение ЦП на некоторый квант времени Q (в простейшем случае размер кванта фиксирован). Если за время Q процесс не завершился, он вытесняется из ЦП и направляется в конец очереди готовых процессов, где ждет выделения ему следующего кванта, и т.д. Показатели эффективности RR существенно зависят от выбора величины кванта Q. RR обеспечивает наилучшие показатели, если длительность большинства процессов приближается к размеру кванта, но не превосходит его. Тогда большинство процессов укладываются в один квант и не становятся в очередь повторно. При величине кванта, стремящейся к бесконечности, RR вырождается в FCFS. При Q, стремящемся к 0, накладные расходы на переключение процессов возрастают настолько, что поглощают весь ресурс ЦП. RR обеспечивает наилучшие показатели справедливости: штрафное отношение P на большом участке длительностей процессов t остается практически постоянным. Только на участке t < Q штрафное отношение начинает изменяться и при уменьшении t от Q до 0 возрастает экспоненциально. Потерянное же время M существенно растет с увеличением длительности процесса.
На рисунке 2.3 показаны примеры планирования по дисциплине RR с разными величинами кванта Q=1 (Рисунок 2.3.а) и Q=4 (Рисунок 2.3.б). Рассмотрим подробнее работу на начальном временном участке Рисунок 2.3.а. Процесс A поступает в момент времени 0 и получает квант времени ЦП. К моменту окончания кванта в очереди уже есть процесс B. Процесс A отправляется в очередь, а следующий квант получает процесс B. В момент времени 2 процесс B направляется в очередь, а из очереди выбирается процесс A. В этот же момент поступает новый процесс - C. Этот процесс ставится в конец очереди, а первым в очереди стоит процесс A, поэтому следующий квант отдается процессу A и т.д. Предоставляем читателю самостоятельно закончить рассмотрение этого примера, а также примера, показанного на Рисунок 2.3.б.
Планирование процессов по дисциплине HPRN
Рисунок 2.6. Планирование процессов по дисциплине HPRN

SRR (selfish RR - эгоистичный RR) - метод с вытеснением, дающий дополнительные преимущества выполняемым процессам, что позволяет повысить пропускную способность. Все процессы разделяются на две категории - новые и выбранные. Новыми считаются те процессы, которые не получили еще ни одного кванта времени ЦП, все остальные процессы - выбранные. При поступлении в систему каждому процессу дается некоторый приоритет P0, одинаковый для всех процессов, который в дальнейшем возрастает. В конце каждого кванта времени пересчитываются приоритеты всех процессов, причем приоритеты новых процессов возрастают на величину dA, а выбранных - на величину dB. ЦП отдается процессу с наивысшим приоритетом, а при равенстве приоритетов - тому, который раньше поставлен в очередь. Показатели дисциплины существенно зависят от выбранного соотношения между dA и dB. При dB/dA=1 дисциплина вырождается в обыкновенную RR, при dB >> dA - в FCFS. Собственно дисциплина SRR обеспечивается в диапазоне значений 0<dB/dA<1.
Рассмотрим работу дисциплины на примере, показанном на рисунке 2.7. Параметры дисциплины в этом примере: P0=0; dA=2; dB=1; Q=1.
Планирование процессов по дисциплине MLFB
Рисунок 2.8. Планирование процессов по дисциплине MLFB

В простейшем варианте MLFB очередь с большим номером не обслуживается до тех пор, пока есть процессы в очередях с меньшими номерами. Возможны, однако, многочисленные вариации метода MLFB, например, такие: наряду с предпочтительным обслуживанием высокоприоритетной очереди предоставлять (но с меньшей частотой) кванты времени и очередям с низкими приоритетами; выполнять обратное перемещение процесса в очередь с меньшим номером после того, как процесс прождал установленный интервал времени в низкоприоритетной очереди; установить размер кванта зависящим от номера очереди, например: Q[n]=q*n или Q[n]=q*2n; поскольку в очереди с большими номерами попадают более длинные процессы, их обслуживание с большим квантом позволит сэкономить расходы на переключение; обслуживать разные очереди по разным дисциплинам (например: RR - для первой очереди, FCFS - для второй).
Планирование процессов по дисциплине PSPN
Рисунок 2.5. Планирование процессов по дисциплине PSPN

HPRN (highest penalty ratio next - с наибольшим штрафным отношением - следующий) - дисциплина без вытеснения, обеспечивающая наилучшие показатели справедливости. Это достигается за счет динамического переопределения приоритетов. Всякий раз при освобождении ЦП для всех готовых процессов вычисляется текущее штрафное отношение: p[i]=(w[i]+t[i]) / t[i] где i - номер процесса; w[i] - время, затраченное процессом на ожидание; t[i] - длительность процесса - предзаданная или прогнозируемая. Для только что поступившего процесса p[i]=1. ЦП отдается процессу, имеющему наибольшее значение p[i]. Для коротких процессов HPRN обеспечивает примерно те же показатели справедливости, что и SJN, для длинных - более близкие к FCFS. На большом диапазоне средних длительностей процессов показатели, обеспечиваемые HPRN, представляют среднее между SJN и FCFS и слабо зависят от длительности. Еще одно достоинство HPRN - в том, что во времени ожидания может учитываться (с некоторыми весовыми коэффициентами) и ожидание в других очередях и, таким образом, выполняется более комплексный учет загрузки системы. Существенным недостатком метода является необходимость перевычисления штрафного отношения для всех процессов при каждом переключении, что плохо согласуется с общей политикой минимизации накладных расходов в дисциплинах без вытеснения.
В примере, показанном на рисунке 2.6, под временной шкалой даны текущие значения штрафного отношения для процессов-претендентов в те моменты времени, когда выполняется переключение. Так, в момент времени 6 два процесса - B и C - претендуют на использование ЦП. Текущее штрафное отношение для процесса B составляет: p[B]=(5+3)/3=2.33, а для процесса C: p[C]=(3+7)/7=1.43; следовательно, ЦП отдается процессу B. Аналогичные вычисления производятся в моменты времени 9 и 16.
Планирование процессов по дисциплине RR
Рисунок 2.3. Планирование процессов по дисциплине RR

SJN (shortest job next - самая короткая работа - следующая) - невытесняющая дисциплина, в которой наивысший приоритет имеет самый короткий процесс. Для того, чтобы применять эту дисциплину, должна быть известна длительность процесса - задаваться пользователем или вычисляться методом экстраполяции. Для коротких процессов SJN обеспечивает лучшие показатели, чем RR, как по потерянному времени, так и по штрафному отношению. SJN обеспечивает максимальную пропускную способность системы - выполнение максимального числа процессов в единицу времени, но показатели для длинных процессов значительно худшие, а при высокой степени загрузки системы активизация длинных процессов может откладываться до бесконечности. Штрафное отношение слабо изменяется на основном интервале значений t, но значительно возрастает для самых коротких процессов: такой процесс при поступлении в систему имеет самый высокий приоритет, но вынужден ждать, пока закончится текущий активный процесс.
Пример планирования по этой дисциплине показан на рисунке 2.4. Поступивший в момент времени 0 процесс A захватывает ЦП. Процесс B, поступивший в момент 1, вынужден ждать освобождения ЦП процессом A, хотя процесс B и более короткий. К моменту 6 - освобождения ЦП - из двух имеющихся в очереди процессов (B и C) выбирается более короткий процесс B. Процесс C получает ЦП только в момент времени 9, когда заканчивается процесс B. Когда в момент времени 16 процесс C освобождает ЦП, из двух имеющихся в очереди процессов выбирается более короткий процесс E, хотя он поступил позже, чем процесс D.
Планирование процессов по дисциплине SPN
Рисунок 2.4. Планирование процессов по дисциплине SPN

PSJN (preemptive SJN - SJN с вытеснением) - текущий активный процесс прерывается, если его оставшееся время выполнения больше, чем у новоприбывшего процесса. Дисциплина обеспечивает еще большее предпочтение коротким процессам перед длинными. В частности, в ней устраняется то возрастание штрафного отношения для самых коротких процессов, которое имеет место в SJN.
Рассмотрим пример, представленный на рисунке 2.5. Процесс A поступает в систему первым и успевает использовать единицу времени ЦП прежде, чем в систему приходит процесс B. Процесс B требует 3 единицы процессорного времени, а процессу A осталось использовать еще 5 единиц. Процесс A вытесняется, ЦП отдается процессу B. При освобождении ЦП в очереди уже есть и процесс C, но его длительность больше, чем остаток времени процесса A, поэтому процесс C получает ЦП только в момент времени 9, когда процесс A завершится. Процесс C успевает использовать только одну единицу времени ЦП, когда приходит короткий процесс E и вытесняет процесс C из ЦП. Выполнение C вновь откладывается до освобождения ЦП, которое происходит в момент 14. В момент 17 приходит процесс D. Его длительность (6) меньше, чем полная длительность процесса C (7), но к этому времени процесс C уже использовал 4 единицы времени ЦП, и для завершения ему необходимо еще только 4 единицы, поэтому процесс D не вытесняет процесс C.
Планирование процессов по дисциплине SRR
Рисунок 2.7. Планирование процессов по дисциплине SRR

Под временной шкалой здесь показаны текущие значения приоритетов процессов. Процесс A при поступлении получает приоритет 0. Поскольку на этот момент других процессов нет, процесс A начинает выполняться. Получив ЦП, процесс A попадает в категорию выбранных, поэтому при окончании кванта в момент 1 приоритет процесса A возрастает на 1. В момент 1 поступает процесс B, ему присваивается начальный приоритет 0, на текущий момент это ниже, чем приоритет A, поэтому ЦП остается у процесса A. По прошествии еще одного кванта, к моменту времени 2 приоритет процесса A увеличивается еще на 1 и становится равным 2, но приоритет процесса B, как нового, увеличивается на 2 и становится равным приоритету A. По принципу RR ЦП отдается процессу B, как дольше ожидающему. Процесс B теперь также становится выбранным и в дальнейшем его приоритет растет медленнее. Поступающий позже новый процесс C имеет нулевой начальный приоритет и вынужден ждать 3 кванта, пока его приоритет не сравняется с приоритетами выбранных процессов. Аналогичным образом происходит обслуживание и остальных поступающих процессов.
FB (foreground-background - передний-задний планы) - очередь готовых процессов расщепляется на две подочереди - очередь переднего плана и очередь заднего плана. Очереди обслуживаются по дисциплине RR, но очередь переднего плана имеет абсолютный приоритет: пока в ней есть процессы, очередь заднего плана не обслуживается. Новый процесс направляется в очередь переднего плана. Если процесс использовал установленное число N квантов в очереди переднего плана, но не завершился, он переводится в очередь заднего плана.
Обобщение дисциплины FB на n очередей с номерами 0, 1, ..., n-1 и с абсолютными приоритетами, убывающими при возрастании номера очереди, носит название MLFB (multiply level feed back - многоуровневые очереди с обратной связью). Расщепление очереди готовых процессов на две и более подочереди обеспечивает селекцию процессов по длительности - более длинные процессы попадают в очереди с большими номерами и, соответственно, с меньшими приоритетами. Дисциплина MLFB очень эффективна для систем, работающих в интерактивном режиме.
На рисунке 2.8 показаны примеры работы MLFB для N=1. Под временной шкалой показаны состояния процессов в каждый момент времени: "а" - для активного процесса и номер очереди - для неактивного. Процесс A поступает в очередь 0 и, поскольку ЦП свободен, сразу же выбирается из нее на выполнение. После использования одного кванта времени ЦП процесс A переводится в очередь 1. В этот момент (момент 1) в очередь 0 поступает процесс B. Поскольку очередь 0 имеет более высокий приоритет, чем очередь 1, на выполнение выбирается процесс B. Процесс B после использования кванта (момент 2) попадает также в очередь 1. Поскольку в момент времени 2 очередь 0 пуста, обслуживается очередь 1, из нее выбирается процесс A, который был поставлен в эту очередь раньше, чем процесс B. После этого кванта (момент 3) процесс A переходит в очередь 2, а в очереди 0 появляется новый процесс C, которому и будет отдан следующий квант. После этого кванта (момент 4) процесс C будет направлен в очередь 1. На этот момент времени мы имеем 3 процесса: процесс A в очереди 2, процесс B в очереди 1 и процесс C в очереди 1. Обслуживается очередь 1, процесс B попал в эту очередь раньше, он получает следующий квант и т. д.
Планирование процессов в реальных системах
2.3. Планирование процессов в реальных системах
Как мы отмечали выше, в реальных ОС при планировании процессорного времени применяются модификации и/или комбинации базовых алгоритмов, обеспечивающие большую эффективность и гибкость. Можно утверждать, что в реальных ОС применяются почти исключительно комбинированные методы, учитывающие как внешние приоритеты, так и поведение процесса, и степень загрузки ЦП, и, возможно, других ресурсов системы. Можно также утверждать, что дисциплины планирования без вытеснения в ОС общего назначения бесперспективны. Доживающая свой век Windows 3.x - последняя из современных ОС, применяющая кооперативную многозадачность.
По-видимому, в ближайшее время наиболее интенсивно будут применяться и развиваться интерактивные ОС и ОС, обеспечивающие режим клиент/сервер, поэтому современные ОС применяют дисциплины, отдающие предпочтение обменным процессам. Для таких ОС достаточно типичной можно считать следующую макросхему определения приоритетов процессов в очереди к ЦП. Наивысший абсолютный приоритет имеют системные процессы, которые не могут вытесняться. Далее - системные процессы, которые могут быть вытеснены. Наконец, низший приоритет имеют пользовательские процессы. Пользовательские процессы, в свою очередь, могут делиться на классы. Типовое деление включает в себя три класса: с высоким приоритетом - процессы реального времени; со средним приоритетом - интерактивные процессы; с низким приоритетом - счетные (пакетные) процессы.
Внутри каждого класса предусматривается еще несколько градаций приоритета, которые могут назначаться пользователем. Наконец, ОС может формировать еще динамическую добавку к приоритету, зависящую от истории выполнения процесса, текущего состояния ресурсов и т.д. Эта добавка может повышать или снижать приоритет процесса внутри класса, но, как правило, не выводит процесс за пределы назначенного ему класса. Динамическая составляющая совершенно необходима для процессов класса с нормальным приоритетом (интерактивных), так как их поведение во время выполнения наиболее трудно предсказать. Процессы других классов ОС может планировать и по статическим приоритетам.
Общие закономерности в динамическом вычислении приоритетов можно свести к следующим: приоритет процесса, долгое время находящегося в состоянии ожидания, повышается; приоритет процесса, часто выполняющего операции ввода-вывода, повышается; приоритет процесса, чаще получающего внешние сообщения и прерывания, повышается; если приоритет процесса не повышается, он убывает.
Ниже мы рассматриваем два примера динамического вычисления приоритетов. Еще раз подчеркнем, что рассматриваемые нами алгоритмы относятся только к пользовательским процессам - системные процессы имеют абсолютный и более высокий приоритет.
ОС Unix [24] - система многопользовательская и многозадачная, ориентированная прежде всего на интерактивную работу - дает пример изящного алгоритма динамического вычисления приоритетов, называемого иногда "алгоритмом полураспада" - модификацию дисциплины RR. С каждым i-ым процессом связано некоторое приоритетное число P[i]. Чем оно меньше, тем выше приоритет процесса. Каждый новый процесс получает некоторое исходное значение приоритетного числа - P0, одинаковое для всех процессов. Кроме того, с каждым процессом связан счетчик процессорного времени U[i] с исходным значением 0. Процесс с наименьшим значением P[i] получает квант времени ЦП (при равенстве приоритетных чисел ЦП отдается процессу, ожидающему дольше). За время кванта интервальный таймер выдает несколько сигналов-прерываний. По каждому такому прерыванию счетчик U[i] активного (только активного!) процесса увеличивается на 1. Использование ЦП процессом заканчивается при истечении кванта или при переходе процесса в ожидание. При этом модифицируются счетчики процессорного времени всех (в том числе и неактивных) процессов: U[i] = U[i] / 2 и для всех процессов перевычисляются приоритетные числа: P[i] = P0 + U[i] / 2.
На рисунке 2.9 показан пример работы алгоритма полураспада для случая трех одновременно поступивших процессов A, B, C. Для этого примера мы задались начальным значением приоритетного числа P0=16 и размером кванта, равным 16 "тикам" таймера.
Поскольку Unix не накладывает ограничений на количество процессов, порождаемых одним пользователем, для ОС может оказаться более важным справедливое распределение ЦП не между процессами, а между пользователями. Эта задача решается незначительной модификацией алгоритма. С каждым процессом связывается еще и групповой счетчик процессорного времени G[i]. Этот счетчик с каждым "тиком" таймера увеличивается на 1 как у активного процесса, так и у всех процессов, принадлежащих тому же пользователю. В конце кванта G[i] также "полураспадается", а приоритетное число вычисляется, как: P[i] = P0 + U[i] / 2 + G[i] / 2.
Рисунок 2.11. Планирование виртуальных машин в ОС VM/370

Из диспетчируемых ВМ в очереди RUNLIST выбирается ВМ с высшим приоритетом, и ей выделяется квант времени ЦП - dt. ВМ может освободить ЦП по одной из следующих причин: ВМ запрашивает операцию ввода-вывода, выполняющуюся на реальном внешнем устройстве (1 на Рисунок 2.11), такая ВМ становится непланируемой и исключается из очередей планировщика; ВМ исчерпала квант времени ЦП (2 на Рисунок 2.11) - для этого случая проверяется, исчерпала ли ВМ квоту обслуживания dT (5 на Рисунок 2.11); если квота не исчерпана, ВМ возвращается в очередь RUNLIST, но ее приоритетное число несколько увеличивается; если же квота исчерпана, ВМ получает статус недиалоговой и направляется в очередь E2; ВМ запрашивает операцию, которую моделирует для нее ОС VM без использования реального внешнего устройства, или для ВМ обрабатывается страничный отказ (3 на Рисунок 2.11), такая ВМ переводится в состояние ожидания (устанавливается соответствующий бит в ее виртуальном PSW), она остается в очереди RUNLIST, но становится недиспетчируемой. ВМ, ставшие непланируемыми, ожидают в других очередях ОС, которые не имеют отношения к планировщику. Когда завершается операция ввода-вывода для такой ВМ (4 на Рисунок 2.11), эта ВМ получает статус диалоговой и направляется в очередь E1. При этом приоритетное число ВМ перевычисляется с учетом: старого приоритета; времени предыдущего ухода ВМ из очереди RUNLIST; времени, потерянного ВМ в очередях планировщика.
Новое значение приоритета определяет порядок выборки ВМ из очереди E1 в очередь RUNLIST и сохраняется за ВМ при переводе ее в очередь RUNLIST.
ВМ, получившие статус недиспетчируемых, ожидают, когда ОС переведет их виртуальное PSW из состояния ожидания в состояние счета (6 на Рисунок 2.11). После этого такая ВМ переводится в очередь E2. Таким образом, ВМ может попасть в очередь E2 либо по исчерпанию квоты обслуживания, либо по выполнению операций ОС. При постановке в очередь E2 приоритетное число перевычисляется с учетом: старого приоритета; эффективности использования ВМ памяти; времени пребывания ВМ в очередях; штрафа, накладываемого на ВМ, если она превысила среднее время использования процессора.
Те ВМ, которые 6 раз переходили из очереди E2 в очередь RUNLIST, минуя очередь E1, получают статус чисто пакетных и добавка к приоритетному числу для них в 8 раз больше, чем для диалоговых.
Всякий раз, когда какая-либо ВМ покидает очередь RUNLIST, ОС пытается пополнить последнюю из очередей неактивных ВМ. Возможность пополнения очереди RUNLIST определяется эффективностью управления памятью в соответствии с политикой "размера рабочего набора", рассматриваемой в следующей главе.
В VM/ESA сохранились основные черти приведенного алгоритма, но развитие аппаратных средств System/390 и передача им некоторых задач управления производительностью позволили значительно его упростить.
Плоская модель памяти
3.7. Плоская модель памяти.
Начиная с модели Intel-80386, в микропроцессорах Intel-Pentium адрес состоит из 16-разрядного номера сегмента и 32-разрядного смещения. 32-разрядное поле смещения позволяет адресовать до 4 Гбайт в пределах одного сегмента, что более чем достаточно для большинства мыслимых приложений и позволяет реализовать действительно "плоскую" (flat) модель виртуальной памяти процесса, представляющую собой линейное непрерывное пространство адресов..
Однако, при размере страницы 4 Кбайт таблица страниц должна содержать более 106 элементов и занимать 4 Мбайт памяти. Для экономии памяти аппаратура трансляции адреса микропроцессора поддерживает таблицы страниц двух уровней. Страничная таблица верхнего уровня называется каталогом страниц. Старшие 10 байт 32-разрядного смещения являются номером элемента в страничном каталоге. Элемент страничного каталога адресует таблицу страниц второго уровня. Следующие 10 байт смещения являются номером элемента в таблице страниц второго уровня. Элемент таблицы второго уровня адресует страничный кадр в реальной памяти, а младшие 12 байт смещения являются смещением в странице. Сегментная часть аппарата трансляции адреса оказывается излишней, в Intel-Pentium она не может быть отключена, но тот же эффект достигается, если каждому процессу назначается только один сегмент, и для процесса создается таблица сегментов, содержащая только один элемент. Поле base этого элемента адресует страничный каталог процесса, а каждый элемент страничного каталога - одну таблицу страниц. Структуры элементов каталога страниц и таблицы страниц второго уровня идентичны, каждая таблица страниц (каталог или таблица второго уровня) содержит 1024 элемента и сама занимает страничный кадр в памяти. Таблицы страниц участвуют в страничном обмене так же, как и страницы, содержащие любые другие данные и коды.
В 4-Гбайтном адресном пространстве появляется возможность разместить не только коды и данные процесса, но и объекты, используемые им совместно с другими процессами, в том числе и модули самой ОС. В этом случае обращение процесса к ОС происходит как обращение к процедуре, размещенной в адресном пространстве самого процесса. В современных ОС структура адресного пространства процесса обычно бывает следующей: самая младшая часть адресного пространства обычно для процесса недоступна, она используется ОС для поддержки реального режима; размер этой части адресного пространства обычно не менее 4 Мбайт, что соответствует одному элементу страничного каталога; далее размещается частное адресное пространство процесса, содержащее его коды, локальные данные, стек; выше размещаются "прикладные" общие области памяти, используемые несколькими процессами совместно; еще выше - системные модули, работающие в непривилегированном режиме, эти модули совместно используются всеми процессами; наконец, в самой верхней части размещаются системные модули, работающие в режиме ядра (уровень привилегий - 0), эти модули также совместно используются.
Совместное использование памяти обеспечивается либо тем, что элементы каталогов разных процессов адресуют одну и ту же таблицу страниц второго уровня, либо тем, что таблицы страниц второго уровня разных процессов адресуют один и тот же страничный кадр. В первом случае виртуальные адреса совместно используемых объектов являются одинаковыми для всех процессов, во втором - разными. Все системы используют первый способ для системных модулей, но разные способы для "прикладных" общих областей памяти.
Большинство разработчиков приложений горячо приветствовали введение плоской модели памяти в современных ОС (OS/2 Warp, Windows 95, Windows NT), так как представление виртуального адреса в виде одного 32-разрядного слова избавляет программиста от необходимости различать ближние и дальние указатели и упрощает программирование. Но справедливы и предупреждения [17] о том, что отказ от сегментного структурирования виртуального адресного пространства кое в чем ограничивает возможности программиста. Большая же эффективность плоской модели памяти является объективным фактором, так как, во-первых, оперирование с 32-разрядными адресными словами уменьшает число команд в программе, а во-вторых, поскольку в 4-Гбайтном виртуальном адресном пространстве процесса могут быть размещены и процедуры, реализующие системные вызовы, то обращения процесса к ОС происходят как к собственным локальным процедурам и не требуют переключений контекста.
Несколько усложняется защита памяти при фактическом отказе от сегментирования. В Intel-Pentium в аппаратном дескрипторе сегмента предусмотрено пять двоичных разрядов, которые могут быть использованы для целей защиты , а в дескрипторе страницы - только два таких разряда. Однако объединение средств защиты на уровне каталога страниц и таблиц второго уровня образует достаточно богатые возможности. Надежность защиты памяти в современных ОС определяется только тем, насколько активно и аккуратно эти возможности используются.
Подключение через канал вводавывода
Рисунок 6.4. Подключение через канал ввода-вывода

Идея канала ввода-вывода, впервые реализованная в System/360 фирмы IBM, была впоследствии воплощена в ряде других архитектур. Ввиду своей продуктивности эта идея без концептуальных изменений была перенесена и в System/370, и в System/390, и отказа от нее в перспективе также не предвидится. В последующем изложении мы опираемся именно на эти реализации каналов ввода-вывода.
Существует несколько типов каналов (селекторный, мультиплексный, байт-мультиплексный), предназначенных для подключения устройств с разными скоростями обмена, но для программиста все они выглядят одинаково. Средства программирования канала, во-первых, гораздо более мощные и гибкие, чем контроллера ПДП, во-вторых, позволяют унифицировать программирование ввода-вывода для различных устройств.
Выполнение операции ввода-вывода подразумевает совместное (параллельное или квазипараллельное) функционирование нескольких "субъектов": основной программы, выполняющейся на центральном процессоре (далее - программа ЦП), канала и устройства (далее - канал), аппаратного механизма прерываний и программы обработки прерываний. Программа ЦП формирует в оперативной памяти программу канала, сообщает системе ввода-вывода ее адрес, назначает Блок управления событием, в котором будет сделана отметка о завершении операции, и выдает команду "Начать ввод-вывод", адресующую канал и устройство. Канал проверяет готовность канала/устройства и начинает выполнение канальной программы. При этом команда "Начать ввод-вывод" завершается, и программа ЦП продолжает свое выполнение. Когда у программы ЦП возникает необходимость дождаться завершения операции, она опрашивает Блок управления событием. Если в нем есть отметка о выполнении, программа продолжает выполняться, в противном случае - переводится в состояние ожидания до появления отметки в Блоке управления событием. Канал при завершении операции сообщает системе ввода-вывода информацию о своем состоянии и инициирует прерывание по вводу-выводу. Аппаратный механизм прерывания сохраняет текущее состояние программы и обеспечивает передачу управления на программу обработки прерываний по вводу-выводу. Программа обработки прерываний распознает канал и устройство, пославшие прерывания, и передает управление на соответствующую ветвь обработки. Из информации о состоянии канала определяется причина прерывания. Выполняются действия по обработке соответствующей ситуации. Диагностическая информация может быть также записана в область памяти, доступную для программы ЦП. Если прерывание, сообщает об окончании операции, обработчик прерывания делает отметку в Блоке управления событием. Обработчик прерывания возвращает управление в прерванную программу. Программа ЦП, если это необходимо, анализирует диагностическую информацию о результатах выполнения операции.
Программа канала размещается в оперативной памяти и представляет собой массив канальных команд. Каждая команда канальной программы - структура данных фиксированной длины, содержащая код операции, адрес области памяти, с которой происходит обмен, код контроля доступа к памяти, признаки режима выполнения, объем передаваемых или принимаемых данных.
Различаются несколько типов операций: "чтение" (передача данных из устройства в память), "запись" (передача данных из памяти в устройство), "управление" (выполнение специфических операций на устройстве, например, перемотка магнитной ленты) - эти команды специфичны для устройств, устройство может иметь несколько модификаций одной команды. Общей для всех устройств является команда "уточнить состояние" - передача в память информации о состоянии устройства. Команда "переход в канале" на устройство не передается, она изменяет последовательность выполнения канальных команд. Код контроля доступа к памяти позволяет предотвратить вторжение процесса в операциях ввода-вывода в области памяти, принадлежащие другим процессам или ОС. Среди признаков режима выполнения наибольший интерес представляют три. Признак "цепочка команд" определяет продолжение программы канала в следующей команде. Признак "цепочка данных" задает выполнение следующей канальной команды как продолжения текущей: поле кода операции в ней игнорируется, но все остальные поля обновляются. Если отсутствуют признаки "цепочка команд" или "цепочка данных", канальная команда считается последней в программе. Признак "программно управляемое прерывание" задает генерацию прерывания при выборке каналом команды, содержащей этот признак, это дает возможность синхронизировать работу программы на центральном процессоре с выполнением канальной программы.
Взаимодействие между субъектами выполнения операции ввода-вывода происходит также через фиксированные адреса памяти, в которые записывается управляющая и диагностическая информация: Адресное слово канала, Слово состояния канала, Слово состояния программы.
Как и контроллер ПДП, канал не выполняет динамическую трансляцию адресов, кроме того, в системах, где процесс работает только в своей виртуальной памяти, не имея дела с реальным адресами, ОС транслирует программу канала, размещая результат трансляции в недоступной для процесса области. В этом случае процесс не может модифицировать программу канала в ходе ее выполнения.
Контроллер ПДП и канал ввода-вывода являются специализированными процессорами. Следующим шагом в интеллектуализации контроллеров ввода-вывода являются процессоры ввода-вывода - универсальные процессоры, выполняющие функции контроллера ввода-вывода. Впервые процессоры ввода-вывода были применены в вычислительной системе CDC-6600, считающейся первым суперкомпьютером. С тех пор процессоры ввода-вывода перестали быть прерогативой суперсистем и постепенно внедряются в системы ординарные (например, AS/400). Интерфейс процессора ввода-вывода не похож на интерфейс устройства в обычном понимании. Взаимодействие ОС с процессором ввода-вывода происходит через механизм обмена сообщениями, поддерживаемый микроядром. Данные могут передаваться как в составе сообщения, так и выбираться процессором ввода-вывода непосредственно из оперативной памяти. Взаимодействие через сообщения, естественно, занимает больше времени, чем управление вводом-выводом через контроллер или канал, но выигрыш в эффективности получается за счет переноса некоторых (иногда весьма значительных по объему) операций обработки данных в процессор ввода-вывода. Являясь универсальным процессором, процессор ввода-вывода работает под управлением своей собственной мини-ОС и программа управления устройством имеет статус приложения в этой ОС.
Подключение через контроллер
Рисунок 6.2. Подключение через контроллер

Быстродействие устройств много ниже быстродействия центрального процессора, поэтому обычно после выдачи команды на устройство программа должна дожидаться ее завершения. Программа может убедиться в завершении операции одним из двух способов: опросом или прерыванием. Опрос предполагает периодическое чтение регистра состояния устройства и проверку в нем признака завершения операции. Крайним случаем опроса является занятое ожидание - когда программа опрашивает устройство практически непрерывно, ничем другим не занимаясь. Помимо того, что при этом непроизводительно расходуется процессорное время, занятое ожидание еще и небезопасно: при отсутствии сигнала окончания от устройства (например, при сбое последнего) программа может "зависнуть" в состоянии занятого ожидания, а если она при этом была в непрерываемом состоянии - заблокировать работу всей системы.
Более действенным способом сигнализации об окончании операции является прерывание от устройства. При большом разнообразии механизмов прерываний в разных архитектурах вычислительных систем все они обеспечивают сохранение вектора состояния прерванного процесса и идентификацию устройства, приславшего прерывание. При использовании прерываний ОС после выдачи команды ввода-вывода на устройство переводит процесс в состояние ожидания. Прерывание, присланное устройством, обрабатывается ядром ОС, которое при этом разблокирует процесс, ожидающий завершения операции.
Для устройств, с которыми обмен ведется большими порциями информации, применяется прямой доступ к памяти (ПДП), показанный на Рисунке 6.3. Контроллер ПДП работает параллельно с центральным процессором и обменивается данными прямо с оперативной памятью, минуя центральный процессор. Сам контроллер ПДП выглядит для программы как устройство с доступом через регистры. Программа должна его запрограммировать, записав в его регистры адрес области оперативной памяти, с которой происходит обмен, и размер блока данных, а затем запустить операцию, которая инициирует прямой обмен. Регистр данных контроллера ПДП при этом используется только для передачи управляющей информации. Об окончании обмена программа может узнать либо по прерыванию, либо опрашивая регистр состояния контроллера. Контроллер ПДП обычно содержит собственную буферную память для сглаживания разницы в быстродействии устройства и оперативной памяти. Напомним, что аппаратура ПДП обычно не обеспечивает динамическую трансляцию адресов. Поэтому ОС, получив от процесса запрос на выполнение операции ввода-вывода через ПДП, фиксирует в реальной памяти ту часть виртуального адресного пространства программы, с которой происходит обмен - до окончания обмена. Отметим также, что непрерывное виртуальное адресное пространство процесса может отображаться в несмежные страничные кадры реальной памяти, поэтому ОС может водить-выводить непрерывный с точки зрения процесса блок данных за несколько операций обмена.
Подключение через ПДП
Рисунок 6.3. Подключение через ПДП

В сущности, и контроллер обычного устройства, и контроллер ПДП представляют собой специализированные процессорные устройства, но более полно это качество присуще каналу ввода-вывода. Каналы представляют собой специализированные процессоры, имеющие свою систему команд и работающие параллельно с центральным процессором, но использующие ту же оперативную память. В отличие от контроллеров, которые являются специализированными по типам устройств, каналы являются универсальными процессорами ввода-вывода, к одному каналу могут быть одновременно подсоединены контроллеры разных устройств. Работа канала во многом похожа на работу контроллера ПДП: канал программируется, а затем запускается операция, в ходе которой канал обеспечивает прямой обмен с оперативной памятью, минуя центральный процессор. Подключение через канал показано на Рисунке 6.4.
Последовательное выделение
Последовательное выделение.
Любыми ресурсами может одновременно пользоваться только один процесс. Если процесс A из предыдущего примера получил ресурс-принтер, то процессу B будет отказано даже в выделении ресурса-ленты. Очевидно, что такая стратегия делает тупики совершенно невозможными. Очевидно также, что некоторые процессы будут при этом простаивать совершенно неоправданно. Так, например, будет приостановлен некий процесс C, которому принтер и не нужен, а нужна только лента. Поскольку в число распределяемых ресурсов входят устройства ввода-вывода, а работают они медленно (пример - та же печать на принтере), простой может затянуться. Эта стратегия неоправданно снижает уровень мультипрограммирования и неэффективно использует ресурсы (они тоже простаивают), и может применяться только в таких ОС, в которых и расчетный уровень мультипрограммирования невысок.
Постановка проблемы
8.1. Постановка проблемы
Параллельными называются процессы, у которых "интервалы времени выполнения перекрываются за счет использования разных ресурсов одной и той же вычислительной системы или за счет перераспределения одного и того же набора ресурсов"[4]. При рассмотрении параллельности мы несколько расширим (только в пределах этой главы) понятие процесса: будем понимать под процессом любую последовательность действий. Процесс у нас имеет строго последовательную структуру, он выполняется операция за операцией, команда за командой. Но в один и тот же момент времени в системе могут выполняться несколько таких последовательностей. Такое расширение понимания процесса позволит нам включить в рассмотрение и такие последовательности действий, которые формально процессами не являются: отдельные нити одного процесса, модули ядра ОС, обработчики прерываний, процессы на внешних устройствах и т.д. С концептуальной точки зрения не имеет значения, является ли одновременность выполнения реальной (достигаемой за счет аппаратного распараллеливания) или виртуальной (достигаемой за счет разделения времени), хотя это различие, как мы увидим ниже, может сказываться на механизмах реализации.
Процессы, которые мы рассматриваем в этой главе, являются слабо связанными. Это означает, что за исключением достаточно редких моментов явной связи процессы выполняются независимо друг от друга. Взаимная независимость процессов запрещает нам при решении задач управления параллельным выполнением делать какие-либо предположения о соотношении скоростей выполнения процессов. За счет перераспределения ресурсов эти скорости вообще не могут считаться постоянными. Единственным оправданным предположением в этом отношении может быть предположение о наихудшем (наименее удобном для нас) соотношении скоростей.
Поскольку параллельные процессы разделяют ресурсы вычислительной системы, задачи управления параллельным выполнением есть задачи управления ресурсами. Как и в случае монопольно используемых ресурсов, методы решения этих задач составляют широкий спектр от самых консервативных (требующих значительного снижения уровня мультипрограммирования) до самых либеральных (допускающих параллельное выполнение большого числа процессов).
Основной задачей управления параллельным выполнением является задача взаимного исключения (mutual exclusion, сокращенно - mutex): два процесса не могут выполнять одновременный доступ к разделяемым ресурсам. Обратим внимание на то обстоятельство, что взаимное исключение обеспечивается уже на аппаратном уровне. Если процессор одновременно получает два запроса, то он выполняет их последовательно по тем или иным правилам арбитража. Каждая процессорная команда обладает свойством атомарности: она или выполняется полностью, или вообще не выполняется. Так же атомарно каждое обращение к памяти. Арбитражные свойства аппаратуры являются основой для построения более сложных механизмов взаимного исключения.
Последовательность операций в процессе, которая выполняет такую единицу работы (транзакцию) с разделяемым ресурсом, во время которой никакой другой процесс не должен иметь доступа к этому ресурсу, составляет критическую секцию. Чтобы процесс мог обеспечить безопасность выполнения своей критической секции, в его распоряжении должны быть средства - "скобки критической секции" - которыми он эту критическую секцию обозначит и защитит. Назовем эти скобки csBegin и csEnd и посвятим дальнейшее рассмотрение взаимного исключения механизмам реализации этих скобок. Для доказательства правильности каждой реализации для нее необходимо показать следующее: в любой момент времени не более, чем один процесс может находиться в своей критической секции; решение о том, какому процессу первому надлежит войти в критическую секцию, не может откладываться до бесконечности; остановка процесса вне своей критической секции не влияет на другие процессы.
В некоторых случаях возникает необходимость в приостановке выполнения процесса до наступления некоторого внешнего по отношению к нему события - такая задача называется задачей синхронизации. Если рассматривать события как ресурсы (потребляемые), то задача синхронизации является частным случаем задачи взаимного исключения. Как частный случай, она допускает частные решения.
Типичным примером задачи синхронизации является обеспечение выполнения "графа синхронизации", подобного тому, который представлен на Рисунке 8.1. Граф синхронизации задает порядок выполнения действий. В программной реализации мы можем представлять действия A, B, ..., I как отдельные процессы и выполнять явную синхронизацию или, использовать неявную синхронизацию, представляя в виде процессов тройки ABC, DEF, GIH или ADG, BEH, CFI, и вводить явные точки синхронизации внутри процессов.
Более сложные задачи синхронизации, такие как "читатели-писатели" и "производители-потребители" мы рассмотрим отдельно ниже.
Поток вводавывода
Рисунок 6.6. Поток ввода-вывода
Поток (stream) представляет собой цепочку очередей, через которые проходят данные, передаваемые от процесса драйверу устройства или в обратном направлении. Каждая очередь в этой цепочке обрабатывается одним программных модулем - модулем потока, как показано на Рисунке 6.6. Данные движутся по цепочке очередей от процесса к драйверу или обратно, по пути проходя обработку в модулях потока. Модуль потока выбирает данные из своей очереди, выполняет их обработку и передает данные в очередь к следующему модулю потока. Когда модуль завершает обработку очередной порцию информации, он запускает на выполнение следующий модуль, который обрабатывает эти данные или заносит их в свою очередь. Вставляя в поток новые модули (и, соответственно, новые очереди) можно обеспечивать сколь угодно сложную дополнительную обработку данных.
Потоки прозрачны для пользовательских процессов, но последним предоставляется возможность вставлять в потоки собственные модули.
Поток может быть однонаправленным или дуплексным, то есть, содержать две параллельные цепочки очередей - вводную и выводную, как и показано на рис 6.6.
Развитием идеи потоков являются многоуровневая структура драйверов, которая применяется в ряде современных ОС. Обработка данных проходит в этом случае через цепочку отдельных драйверов. Места драйверов в цепочке распределяются таким образом, чтобы каждый драйвер более низкого уровня осуществлял обработку, более привязанную к конкретному устройству. Драйверы высоких уровней могут обслуживать несколько устройств одного типа, но разных моделей. Непосредственно аппаратно-зависимым является только драйвер самого нижнего уровня (аппаратный драйвер). В некоторых ОС даже аппаратный драйвер не осуществляет прямого взаимодействия с устройством, а использует для этого сервис ОС. В многоуровневой структуре драйверов может быть оставлено место и для пользовательских драйверов, выполняющих специфическую обработку данных.
Потоки и многоуровневые драйверы
6.5 Потоки и многоуровневые драйверы.
В целом ряде случаев данные, передаваемые из процесса на устройство или в обратном направлении, должны быть дополнительно преобразованы. Такими преобразованиями могут быть: кеширование данных, сжатие данных, криптографическое кодирование данных, согласование с форматами сетевых протоколов и т.д.
Выполнение этих функций может быть заложено непосредственно в драйвер устройства. Однако, такой вариант снижает мобильность драйвера, так как не во всех применениях данной вычислительной системы и данной ОС эти функции могут быть необходимы, требования к этим функциям могут меняться, что повлечет за собой необходимость создания нового драйвера. Даже для разных процессов могут понадобиться разные способы модификации данных. Решение этой проблемы содержится в идее потоков.
Предлагаемое вниманию читателей учебное пособие
Предисловие
Предлагаемое вниманию читателей учебное пособие написано по материалам курсов "Системное программное обеспечение" и "Системное программирование и операционные системы", читаемых студентам направлений "Компьютерные науки" и "Компьютерная инженерия" Национального политехнического университета "ХПИ", а также слушателям Межотраслевого института повышения квалификации при НТУ "ХПИ". Изложение этих курсов сопровождается неизменным интересом слушателей и неизменной нехваткой учебной литературы. Дело в том, что курсы базируются на общих концепциях, сложившихся в начале 70-х годов. Произошедшая в середине 80-х "персональная революция" создала ошибочное впечатление об устарелости этих концепций и вызвала перерыв в издании учебной литературы, эти концепции рассматривающей. Однако последующее совершенствование средств вычислительной техники и ее программного обеспечения показало, что эти концепции отнюдь не устарели, но продолжают применяться и развиваться. Старые издания не могут удовлетворить растущего интереса студентов и специалистов, во-первых, потому, что они уже стали библиографической редкостью, а во-вторых, потому, что в них, естественно, не рассматриваются современные версии ОС и те (пусть и немногие) новые концепции, которые появились в последние годы. Мы надеемся, что предлагаемое издание в какой-то мере уменьшит этот информационный дефицит.
В первой части настоящего учебного пособия мы не привязываемся к какой-либо конкретной ОС, рассматривая лишь общие принципы построения и функционирования ОС. Вторая же часть посвящена тому, как рассмотренные принципы реализованы в конкретных современных системах.
Системные вызовы мы, по возможности, именовали в соответствии с традициями, сложившимися в ОС Unix и зафиксированными в стандарте POSIX, однако, с легкостью отступали от этих традиций там, где это нам представлялось необходимым. В описании алгоритмов и данных мы ориентировались на язык программирования C, однако, опять-таки отступали от синтаксических правил языка там, где строгое следование им вело, по нашему мнению, к излишней конкретизации.
Авторы посвящают эту работу памяти своего друга и коллеги Хартмуда Штира (IBM, Germany), оказавшего неоценимую помощь при сборе материалов.
| Оглавление | Вперед |
Представлена тупиковая ситуация
Рисунок 5.5 представлена тупиковая ситуация: следование по графу любыми возможными путями заставит нас проходить одни и те же вершины. Если же мы уберем дугу, ведущую от процесса P3 к ресурсу R2, то появится выход из петли в вершину P3. Обнаружение тупика сводится к попытке редукции (сокращения) графа. Из графа удаляются те вершины-процессы, которые не имеют запросов или запросы которых могут быть удовлетворены. При этом сокращаются также и все дуги, связанные с этими вершинами. За счет освободившихся ресурсов появляется возможность сократить новые вершины-процессы и т.д. Если в графе нет петель, то после многократных сокращений нам удастся сократить все вершины-процессы.
Как часто следует выполнять проверку тупика? Обратим внимание на то, что если конструктор ОС отказывается от предупреждения тупиков, то он делает это в значительной степени из нежелания загружать систему значительным объемом вычислений по анализу безопасности при каждом запросе. Обнаружение тупика выполняется сходным образом с анализом безопасной ситуации и требует такого же объема вычислений, следовательно, желательно выполнять его как можно реже. Единственным событием, которое может перевести систему из нетупикового состояния в тупиковое, является поступление запроса, который не может быть удовлетворен. Следовательно, попытку обнаружения тупика надо производить только по этому событию, никак не чаще. В некоторых реализациях ОС применяет еще более ленивую политику. Неудовлетворенный запрос может привести к тупику, но может и не привести. "Ленивая" ОС не спешит выполнять проверку даже при поступлении такого запроса, а выжидает некоторое время: может быть "все само собой уладится" - и в большинстве случаев именно так и случается. И только, если запрос остается неудовлетворенным в течение определенного времени, ОС принимается за поиск тупика. Размер временной выдержки может определяться скоростными характеристиками запрашиваемого ресурса.
Если тупик обнаружен, то как его ликвидировать? К сожалению, развязка тупика практически всегда связана с потерями. Единственным реальным способом развязки является принудительное прекращение одного или нескольких процессов и освобождение удерживаемых ими ресурсов. Как выбрать жертву для прекращения? Во-первых, ОС, конечно, должна быть уверена в том, что при прекращении выбранных процессов освободится объем ресурсов, достаточный для развязки тупика. Во-вторых, оценивается объем потерь, связанных с прекращением того или иного процесса. Прекращенный процесс, скорее всего, будет запущен повторно, таким образом, ресурсы, использованные им при его незаконченном выполнении, составляют прямые потери. Поэтому естественным решением представляется прекращение того процесса, который к этому моменту использовал меньше всего ресурсов (не только монопольных, но любых ресурсов вообще). Поскольку самым дорогостоящим ресурсом обычно является процессорное время, выбор жертвы по критерию минимального использованного времени производится наиболее часто.
Желательно, чтобы "пострадавший" процесс был снова запущен, причем, возможно даже, с повышенным приоритетом. Но всякий ли процесс можно прервать на середине, а потом запустить сначала? Представьте себе процесс-программу, которая должна начислить взносы на 10 банковских счетов. Эта программа принудительно завершается в тот момент, когда она успела обработать только 5 счетов. Если при перезапуске программа начнет выполняться с начала, она повторно начислит взносы на первые 5 счетов. ОС не может знать, приведет ли перезапуск процесса к нежелательным последствиям, поэтому решение о повторном запуске обычно перекладывается на пользователя.
Представление планирования процессов в виде системы массового обслуживания
Рисунок 2.1. Представление планирования процессов в виде системы массового обслуживания

Первые два случая с точки зрения системы массового обслуживания одинаковы: в любом случае процесс выходит из данной системы. Если процесс не завершился, то после получения запрошенного ресурса процесс вновь поступит во входную очередь. В случае прерывания процесса по инициативе системы прерванный (вытесненный) процесс поступает во входную очередь сразу же. Порядок обслуживания входной очереди, очередность выбора из нее заявок на обслуживание и составляет дисциплину или стратегию планирования. Методы теории массового обслуживания применяются для аналитического моделирования процесса планирования, хотя формальному анализу поддаются только простейшие дисциплины (см., например, [12]).
Для оценки эффективности функционирования данной системы массового обслуживания могут быть применены количественные показатели. Обозначим через t - процессорное время, необходимое процессу для выполнения. Мы будем его называть длительностью процесса. Обозначим через T - общее время пребывания процесса в системе. Эту величину - интервал между моментом ввода процесса в систему и моментом получения результатов - также называют иногда временем реакции процесса. Наряду с временем реакции, могут быть полезны также и другие показатели.
Потерянное время: M = T - t; определяет время, в течение которого процесс находился в системе, но не выполнялся.
Отношение реактивности: R = t / T; показывает долю процессорного времени (времени выполнения) в общем времени реакции.
Штрафное отношение: P = T / t; показывает, во сколько раз общее время выполнения процесса превышает необходимое процессорное время.
Средние значения величин T, M, R, P и могут служить количественными показателями эффективности. Реальные системы, как правило, ориентированы на конкретные характеристики процессов, в частности, на определенные диапазоны значений t, поэтому указанные показатели удобно рассматривать как функции длительности процесcа: T(t), M(t), R(t), P(t).
К дисциплине планирования в общем случае может применяться широкий спектр требований, наиболее существенные из которых следующие: дисциплина должна быть справедливой - она не должна давать преимуществ одним процессам за счет других и ни в коем случае не должна допускать бесконечного откладывания процессов; дисциплина должна обеспечивать максимальную пропускную способность системы - выполнение максимального количества единиц работы (процессов) в единицу времени; дисциплина должна обеспечивать приемлемое время реакции для интерактивных пользователей; дисциплина должна обеспечивать гарантированное время реакции для процессов реального времени; дисциплина должна быть предсказуемой - дисперсия времен выполнения процессов, обладающих одинаковыми характеристиками, должна быть минимальной; дисциплина должна учитывать внешние приоритеты, присваиваемые процессам пользователями и/или администратором системы; накладные расходы по реализации дисциплины (затраты процессорного времени и других ресурсов) должны быть минимизированы; дисциплина должна учитывать комплексное использование ресурсов вычислительной системы, обеспечивая высокую загрузку системы в целом и рациональное использование ключевых ресурсов.
Очевидно, что выполнение всех перечисленных требований в одинаковой степени невозможно, так как некоторые из них противоречат друг другу. В конкретных системах те или иные требования выдвигаются на передний план - в зависимости от задач системы и характеристик выполняемых в ней процессов, возможно и выдвижение на первый план новых требований, не упомянутых в нашем списке.
В большинстве случаев рассмотрение оценок эффективности планирования процессорного времени производится при условии одного существенного допущения: не принимаются во внимание другие уровни планирования. Выполнение реального процесса состоит из выполнения программы в ЦП и операций ввода-вывода. Последние, во-первых, занимают значительно больше времени (но не времени процессорного), во-вторых, могут включать в себя ожидание ресурсов ввода-вывода. Реальные процессы могут быть классифицированы как вычислительные или обменные. Первые состоят в основном из вычислений в ЦП, вторые - содержат большое количество обращений к вводу-выводу. Оценки эффективности планирования процессорного времени выполняются в предположении, что все процессы относятся к вычислительному типу. Обменные процессы могут быть приведены к этой модели путем представления каждой последовательности процессорных команд между двумя операциями ввода-вывода как отдельного процесса вычислительного типа. Для систем, требующих комплексного сбалансированного управления ресурсами, стратегия затем расширяется учетом факторов, определяемых другими ресурсами.
С точки зрения реализации дисциплины планирования подразделяются прежде всего на дисциплины вытесняющие (preemptive) и невытесняющие (non-preemptive), иначе - кооперативные (cooperative). Для первых возможно прерывание активного процесса и лишение его ресурса ЦП по инициативе планировщика, для вторых - нет. Дисциплины с вытеснением выполняют более частые переключения процессов, следовательно, имеют большие накладные расходы. Но в большинстве случаев только дисциплины с вытеснением могут обеспечить требуемые показатели справедливости обслуживания.
Другие размерности классификации дисциплин связаны со способами определения и реализации приоритетов процессов. Различают приоритеты: внешние или внутренние - первые назначаются администратором системы или пользователем, вторые определяются самой системой по характеристикам процесса; статические или динамические - первые определяются при поступлении процесса в систему и не изменяются впоследствии, вторые перевычисляются планировщиком периодически или/и при событиях, влияющих на планирование процессов; абсолютные или относительные - в первых в выполнению допускается только процессы, имеющие наивысший приоритет, во вторых допускается планирование на выполнение и низкоприоритетных процессов.
Еще одной важной с точки зрения реализации характеристикой дисциплины планирования является объем априорной информации о процессе, необходимой планировщику. Если дисциплина не учитывает использование других ресурсов, кроме ЦП, то такой информацией может быть длительность процесса, так как показатели эффективности являются функциями именно этого аргумента. Если дисциплина использует комплексные приоритеты, то может появиться необходимость и в другой априорной информации. При наличии априорной информации появляется возможность более эффективной реализации, но обязанность подготовки такой информации возлагается на пользователя-владельца процесса, что снижает удобства применения системы. Для процессов, не являющихся чисто счетными, информация, логически эквивалентная априорной, может быть получена методами экстраполяции: на основании предшествовавшего поведения процесса делается предположение о его последующем поведении, например, так, как описано ниже.
Пусть процесс использовал S единиц времени ЦП до перехода в ожидание ввода-вывода. Тогда прогноз на следующий интервал времени ЦП, который понадобится процессу, может быть сделан так: E' = W1 * E + W2 * S где E - прогноз, сделанный на предыдущем интервале для текущего интервала, W1 и W2 - весовые коэффициенты, подбираемые так, что: W1 + W2 = 1 При изменении соотношения весовых коэффициентов в сторону увеличения W2 прогноз становится более реактивным (более чувствительным к изменению поведения процесса), в обратную сторону - более инерционным.
Представление прав доступа
10.3. Представление прав доступа
Полный набор прав доступа для всех субъектов и всех объектов может быть представлен в виде матрицы доступа, строки которой соответствуют субъектам, а столбцы - объектам (или наоборот). На пересечениях строк и столбцов указываются права доступа для данной пары. Права доступа могут задаваться, например, в виде битовых строк с позиционными кодами. На Рисунке 10.2 представлен пример такой матрицы.
Предварительные заявки и алгоритм банкира
Предварительные заявки и алгоритм банкира.
Эта стратегия названа так потому, что действия ОС напоминают действия банкира, выдающего ссуды клиентам, именно на таком примере эта стратегия была рассмотрена в первоисточнике [7]. Применение этой стратегии требует, чтобы процесс передал ОС "предварительную заявку" (advanced claim) и в ней указал максимальный объем ресурсов, который ему понадобится. В ходе выполнения процесс может в произвольном порядке запрашивать/освобождать ресурсы, не выходя, однако, за пределы заявленного объема. Ситуация в системе называется реализуемой, если ни одна заявка не превышает общего числа ресурсов в системе; ни один процесс не требует большего числа ресурсов, чем им заявлено; суммарное число уже распределенных всем процессов ресурсов не превосходит общего числа ресурсов в системе.
Ситуация называется безопасной, если процессы можно выстроить в такую последовательность, что: первый процесс может нормально завершиться даже, если он полностью выберет ресурсы по своей заявке; второй процесс может нормально завершиться даже, если он полностью выберет ресурсы по своей заявке, при условии, что завершится первый процесс и освободит удерживаемые им ресурсы; i-й процесс может нормально завершиться даже, если он полностью выберет ресурсы по своей заявке, при условии, что завершится i-1-й процесс и освободит удерживаемые им ресурсы.
В противном случае ситуация называется опасной.
Если ситуация безопасна, то при отсутствии новых процессов все уже имеющиеся процессы могут нормально завершится, выбрав ресурсы в соответствии со своими заявками, - тупик невозможен.
Пример представлен на Рисунке 5.3.: пусть у ОС имеется всего 12 ресурсов одного класса и на текущий момент выполняются три процесса - P1, P2 и P3, их заявки составляют 12, 4 и 8 ресурсов соответственно. На текущий момент времени процессу P1 выделено 4 ресурса, процессу P2 - 2, процессу P3 - 4 -
Мы описали работу каждого уровня
7.7. Пример
Мы описали работу каждого уровня ФС по отдельности. Их совместное функционирование будет удобнее всего разобрать на конкретном примере. Рассмотрим такую программу: 1 main() { 2 filehandler xfile; 3 xfile = open ("/ivanow/work/testfile.tst", WR_ONLY); 4 seek (xfile,1000); 5 write (xfile,"Example",7); 6 close (xfile); 7 }
Введенный нами тип данных главе filehandler предназначен для представления манипулятора файла.
Далее мы рассматриваем выполнение программы по шагам, причем, в идентификации шагов первая цифра - собственно номер шага, а вторая - номер строки исходного текста.
Шаг 1.3. Системный вызов open переключает контекст с процесса на ядро ОС. ОС передает этот вызов подсистеме логической организации, а та после соответствующих проверок - логической ФС.
Шаг 2.3. Логическая ФС начинает поиск файла по указанному пути, для чего выполняет синтаксический разбор строки имени файла. Поиск начинается с каталога "/" - корневого. Указатель на дескриптор корневого каталога у логической ФС уже имеется: дескриптор корневого каталога может находиться на фиксированном месте на диске ли же указатель на него может храниться в дескрипторе диска и считываться в память вместе с дескриптором диска. (Также логическая ФС постоянно имеет в своем распоряжении и указатель на дескриптор рабочего каталога, так как поиск может начинаться и с него. Первоначально этот указатель указывает на дескриптор корневого каталога, а затем изменяется системными вызовами setCurrentDirectory). Теперь логическая ФС обращается к базовой ФС с запросом на активизацию дескриптора корневого каталога.
Шаг 3.3. Базовая ФС передает на следующие уровни адрес дескриптора корневого каталога. На уровне СУВВ проверяется, не считан ли уже блок, содержащий этот дескриптор в буферную память. Для корневого каталога весьма велика вероятность того, что блок, содержащий его дескриптор уже есть в памяти. Если это так, то СУВВ выбирает из кеша буфер, содержащий требуемый дескриптор. Если же такого буфера в кеше нет, то СУВВ находит в кеше свободный буфер, если нет и свободного буфера, освобождает буфер, используя для выбора, например, дисциплину LRU. Затем СУВВ формирует запрос на ввод и ставит его в очередь. На время выполнения обмена процесс, выдавший вызов, блокируется. Когда прерывание от устройства сигнализирует об окончании ввода, процесс продолжает выполнение на нижнем уровне иерархии ФС. Происходит возврат из СУВВ в верхние уровни и базовая ФС получает дескриптор корневого каталога.
Заметим, что в некоторых случаях здесь может происходить две операции обмена и две блокировки процесса. Если СУВВ выбирает в кеше буфер для освобождения, а этот буфер "грязный", то сначала содержимое этого буфера выводится на диск, а уже затем в него вводится блок.
Шаг 4.3. Базовая ФС проверяет права доступа, находит свободное место в системной таблице открытых файлов и формирует в последней дескриптор открытого файла для корневого каталога. Режим открытия в этом дескрипторе устанавливается RD_ONLY, позиция файлового курсора - 0.
Шаг 5.3. Логическая ФС далее формирует запрос на чтение первого элемента каталога. Допустим, что элемент каталога состоит из 16-байтного имени и 4-байтного адреса. Базовая ФС получает, таким образом, запрос на 20 байт. Она передает на следующий нижний уровень дескриптор открытого файла и счетчик. Система физической организации по плану размещения файла и позиции файлового курсора определяет физической адрес блока, в котором находится требуемая информация, и передает запрос СУВВ. (Это определение может потребовать обращений к СУВВ для чтения информации о размещении файла).
Шаг 6.3. СУВВ находит требуемый блок в кеше или организует его ввод с диска (на время обмена процесс блокируется) и возвращает адрес буфера. Система физической организации выделяет из буфера нужные 20 байт и они возвращаются базовой ФС и далее - логической ФС. Базовая ФС увеличивает на 20 позицию файлового курсора.
В некоторых случаях для выполнения одного запроса система физической организации может формировать два и более запросов к СУВВ - если требуемая информация переходит из блока в блок.
Шаг 7.3. Логическая ФС сравнивает поле имени в полученном элементе каталога с первой составляющей строки поиска - ivanov. Скорее всего, результат сравнения в первый раз будет отрицательным. Если имя не совпадает, логическая ФС формирует запрос на чтение следующего элемента каталога и повторяются шаги 5, 6 и 7. Поскольку файловый курсор модифицирован, будут читаться следующие 20 байт и, скорее всего, СУВВ найдет их уже в кеше.
Шаг 8.3. Когда элемент с именем ivanov будет найден, логическая ФС дает команды базовой ФС освободить дескриптор открытого файла для корневого каталога и открыть подкаталог ivanov. Указатель на дескриптор подкаталога уже выбран логической ФС, далее открытие подкаталога происходит по тому же сценарию, что и корневого каталога.
Шаг 9.3. Когда наконец активизируется файловый дескриптор для последней составляющей пути - файла testfile.tst, режим открытия устанавливается WR_ONLY. К этому моменту все каталоги, открывавшиеся в процессе поиска, уже закрыты. Указатель на элемент системной таблицы открытых файлов помещается в контекст процесса - в таблицу файлов процесса. Индекс элемента в этой таблице возвращается процессу в качестве манипулятора открытого файла и сохраняется в переменной xFile.
Шаг 10.4. Следующий системный вызов из программы - seek. По манипулятору файла ядро выбирает дескриптор открытого файла. Выполнение системного вызова ограничивается уровнем базовой ФС. Последняя устанавливает файловый курсор в позицию 1000, определяемую параметром вызова. Если это определяется спецификациями ФС, то позиция курсора сравнивается с размером файла и ограничивается этим размером. На более низкие уровни этот вызов не передается.
Шаг 11.5. Следующий системный вызов - write. По манипулятору выбирается дескриптор открытого файла. Базовая ФС передает на следующий уровень запрос на запись. Подсистема физической структуры вычисляет номер блока, в который должна быть произведена запись. Последующие действия, выполняемые этой подсистемой, зависят от того, выделен уже файлу этот блок или нет. В первом случае формируется запрос для СУВВ на чтение этого блока, СУВВ читает блок или находит соответствующий буфер в кеше. Во втором случае подсистема физической структуры находит свободный блок на диске. (Поиск свободного блока может потребовать обращений к СУВВ для чтения информации о распределении свободного пространства.) СУВВ выделяет свободный буфер в кеше и связывает его с выделенным блоком. Подсистема физической структуры записывает на определенное место в буфер заданные 8 байт и формирует для СУВВ запрос на вывод блока. СУВВ пока только помечает буфер, как "грязный".
Шаг 12.6. При выполнении системного вызова close базовая ФС копирует часть дескриптора открытого файла на диск (обращаясь для этого к нижним уровням ФС) и освобождает его место в таблице открытых файлов. Дальнейшие действия ФС зависят от того, придерживается она "активной" или "ленивой" дисциплины. "Активная" ФС просматривает весь план размещения файла и формирует для СУВВ запросы на поиск в буферном кеше блоков, принадлежащих файлу. Если такие блоки найдены в кеше и они помечены, как "грязные", СУВВ выводит их на диск и снимает с них пометку. Таким образом, при закрытии файла все обновления его данных записываются на диск. "Ленивая" ФС оставляет "грязные" блоки файла в кеше. Эти блоки попадут на диск, когда потребуется освободить занятые ими буферы кеша.
Пример графа синхронизации Взаимное исключение запретом прерываний
Рисунок 8.1. Пример графа синхронизации
Пример иерархической структуры каталогов
Рисунок 7.2. Пример иерархической структуры каталогов

Иерархические каталоги хорошо известны пользователям MS DOS, поэтому мы будем останавливаться прежде всего на тех их свойствах, которые в этой системе неизвестны или непопулярны.
Обычно в каждый узел древовидной структуры включается запись о каталоге, являющемся по отношению к данному родительским. В такой записи имя каталога-родителя обозначается каким-либо специальным символом или комбинацией символов, например: "..". Это позволяет обращаться к файлам в другом каталоге, задавая путь с отправной точкой либо из корневого каталога, либо из текущего (рабочего). Так, если рабочим является каталог /users/ivanov (Рисунок 7.2), то возможно обращение: ../../petrov/pgm3.c
В каталог также включается запись о нем самом, обычно обозначаемая, как ".". Если рабочим является каталог /system/utility (Рисунок 7.2), то возможно обращение: ./disks/anti/test.1
Древовидный каталог является элегантной и в большинстве случаев удобной структурой, но в некоторых случаях может быть полезно внести в идеальную древовидную структуру некоторые нарушения. Но прежде, чем обсуждать такие нарушения, рассмотрим вопрос о составе элемента каталога.
Каждый элемент каталога описывает файл или подкаталог (subdirectory). С точки зрения ниже лежащих уровней ФС подкаталог является таким же файлом, как и файлы пользователей. Выше мы уже говорили о том, что элемент каталога содержит символьное имя файла или подкаталога и указатель на файловый дескриптор. Вся остальная информация о файле содержится в дескрипторе файла. В некоторых системах сам файловый дескриптор также входит в состав элемента каталога. Но хранение дескриптора файла отдельно от каталога логически вытекает из иерархической структуры ФС, поскольку поиск файла (работа с каталогами) и обработка файла (работа с дескриптором) выполняются разными уровнями ФС. Дескрипторы файлов могут храниться вместе с данными файлов или в специально отведенной области. Раздельное хранение каталогов и дескрипторов обеспечивает ряд дополнительных возможностей в логической ФС, первая из которых - алиасы.
Алиасами (alias) или жесткими связями (hard link), или просто связями (link) называются элементы каталогов, указывающие на один и тот же файловый дескриптор. Алиасы могут находиться в одном том же подкаталоге, в этом случае альтернативные имена обязательно должны быть разными, или в разных подкаталогах, тогда имена могут быть одинаковыми. Два разных элемента каталога, таким образом, указывают на один и тот же физический файл. Если при обращении к файлу по одному из альтернативных имен в данных файла были сделаны изменения, то при чтении файла по другому имени эти изменения будут найдены в файле. Как правило, алиасы создаются для того, чтобы включить в рабочий каталог пользователя файлы, находящиеся в других каталогах, но часто используемые данным пользователем. Например, если обычным рабочим каталогом для нас является /user/petrov, но нам часто приходится обращаться к файлу /system/tools/c, то удобно создать для этого файла альтернативный элемент каталога /user/petrov/c, это позволит нам в дальнейшем обращаться к этому файлу из нашего рабочего каталога по локальному имени. Алиас для рассмотренного примера показан на Рисунке 7.3.а. Отметим, что если для файла создан алиас, то оба альтернативных имен файла - старое и новое - являются равноправными. Нельзя говорить, что файл принадлежит к тому каталогу, в котором он был создан, и только присоединен к другому каталогу - файл в равной степени принадлежит обоим каталогам. При удалении файла по одному из альтернативных имен удаляется только соответствующий элемент в каталоге, физический же файл (и его дескриптор) продолжает существовать, он будет уничтожен, когда будет удалена последняя ссылка на него.
Пример оверлейной структуры программы
Рисунок 3.3. Пример оверлейной структуры программы

В модели с фиксированными разделами после загрузки процесса все обращения к памяти в нем производятся по реальным адресам. Следовательно, ничто не может помешать процессу обратиться к памяти, принадлежащей другому процессу или даже самой ОС, и последствия такого обращения могут быть фатальными. Защита от такого доступа должна поддерживаться аппаратно. Приведем два примера такой защиты. В вычислительной системе имеются специальные регистры, в которых содержатся значения верхней и нижней границы адресов, к которым доступ разрешается. При любом обращении к памяти аппаратура сравнивает заданный адрес с этими граничными значениями и, если адрес не лежит в границах, выполняет прерывание-ловушку. При размещении процесса в памяти ОС определяет для него эти границы и записывает их значения в контекст процесса (вектор состояния процессора). При переключении контекста на данный процесс эти значения загружаются в регистры границ и, таким образом, ограничивается область памяти, к которой имеет доступ процесс. В контексте самой ОС граничные адреса, естественно, соответствуют всему имеющемуся объему памяти. Реальная память разбивается на "блоки защиты" одинакового размера. С каждым таким блоком связан некоторый код - ключ. При размещении процесса ОС дает ему какой-то ключ доступа, сохраняет ключ в векторе состояния и присваивает тот же ключ всем блокам памяти, выделенным этому процессу. При любом обращении к памяти аппаратура сравнивает ключ текущего процесса с ключом блока, к которому производится обращение, и выполняет прерывание-ловушку, если эти ключи не совпадают. Сама ОС, конечно же, имеет "универсальный ключ", дающий ей доступ к любому блоку.
