Пример применения алгоритма полураспада (Q=16; P0=16)
Рисунок 2.9. Пример применения алгоритма полураспада (Q=16; P0=16)

ОС VM/370 [19] демонстрирует нам значительно более сложный (но и более гибкий) пример планирования - рассчитанный на одновременное выполнение задач разных типов. Этот алгоритм можно рассматривать как некоторую версию дисциплины MLFB. Единицей планирования ЦП в этой ОС является виртуальная машина (ВМ). Планировщик ВМ определяет последовательность использования ЦП виртуальными машинами и длительность этого использования. Последовательность определяется положением ВМ в очередях планировщика, длительность - величиной кванта и частотой его получения.
Планирование осуществляется, исходя из таких требований: равномерное (на некотором интервале времени) использование ЦП всеми ВМ; обеспечение гарантированного времени ответа при заданной загрузке системы; соблюдение нормативов потерь на страничный обмен (о страничном обмене - см. главу 3).
Для выполнения этих требований планировщик периодически вычисляет затраты на страничный обмен и среднее время использования ЦП одной ВМ, а также постоянно ведет для каждой ВМ учет использованного ею процессорного времени и времени пребывания в очередях.
С точки зрения планировщика ВМ может находиться в одном из состояний, показанных на рисунке 2.10.
Примеры драйверов устройств
6.4 Примеры драйверов устройств
Приводимые ниже примеры показывают, что на драйверы некоторых устройств часто возлагаются дополнительные функции помимо непосредственного управления вводом-выводом.
Примитивы синхронизации в языках программирования
8.10. Примитивы синхронизации в языках программирования
До сих пор мы рассматривали методы, которые обеспечивают и взаимное исключение, и синхронизацию. Целый ряд прикладных задач, однако, требует только синхронизации без взаимного исключения. Отказ от последнего, если это не мешает решению задачи, всегда оправдан, так как взаимное исключение усложняет решение может снижать уровень мультипрограммирования.
Один из возможных примитивов, обеспечивающих синхронизацию без взаимного исключения, называется счетчиком событий. Счетчик событий - тип данных, представляемый неуменьшающимся целым числом с начальным значением 0. Его значение в любой момент времени - число событий определенного типа, произошедших от некоторой точки начала отсчета. Над этим типом данных возможны следующие операции: advance(E) - увеличение значения счетчика событий E на 1, атомарная операция; eread(E) - возвращает текущее значение счетчика E, эта операция не взаимоисключающая с advance, так что к моменту, когда значение попадет в читающий его процесс, текущее значение счетчика может быть уже изменено; await(E,value) - ждать - ожидание (блокировка процесса), пока значение счетчика E не станет большим или равным value.
Существенно, что из перечисленных операций только advance является взаимоисключающей, остальные могут выполняться параллельно друг с другом и с advance.
Вот как решается с помощью счетчиков событий задача для одного производителя и одного потребителя: 1 typedef unsigned int eventcounter; /* тип данных - счетчик событий */ 2 static eventcounter inCnt = 0, outCnt = 0; /* счетчики для чтения и записи */ 3 static portion buffer [BUFSIZE]; /* буфер */ 4 /*== процесс-потребитель ==*/ 5 void consumer ( void ) { 6 int portNum; /* номер порции */ 7 portion work; /* рабочая область порции */ 8 /* цикл потребления */ 9 for ( portNum = 1; ; portNum++ ) { 10 /* ожидание доступности порции по номеру */ 11 await (inCnt, portNum); 12 /* выборка из буфера */ 13 memcpy (&work, buffer + portNum % BSIZE, sizeof(portion) ); 14 /* продвижение счетчика записи */ 15 advance (outCnt); 16 < обработка порции в work > 17 } 18 } 19 /*== процесс-производитель ==*/ 20 void producer ( void ) { 21 int portNum; /* номер порции */ 22 portion work; /* рабочая область для порции */ 23 /* цикл производства */ 24 for ( portNum = 1; ; portNum++ ) { 25 < производство порции в work > 26 /* ожидание доступности порции по номеру */ 27 await (outCnt, portNum - BSIZE); 28 /* запись в буфер */ 29 memcpy (buffer + portNum % BSIZE, &work, sizeof(portion) ); 30 /* продвижение счетчика чтения */ 31 advance (inCnt); 32 } 33 }
Как мы уже отмечали выше, производитель и потребитель работают с разными секциями буфера, и взаимное исключение для них не требуется. Процессы - производитель и потребитель - могут перекрываться в любых своих фазах, кроме операций advance (строки 15 и 31). Переменные inCnt и outCnt являются счетчиками событий - производства порции и потребления порции соответственно. Кроме того, каждый процесс хранит в собственной локальной переменной portNum - номер порции, с которой ему предстоит работать (счет начинается с 1). Потребитель ждет, пока счетчик производств не достигнет номера очередной его порции, затем выбирает порцию из буфера и увеличивает счетчик потреблений. Производитель работает симметрично. Обратите внимание на второй параметр операции await в производителе (строка 27). Он задается таким, чтобы обеспечить отсутствие ожидания при наличии хотя бы одной свободной секции в буфере.
Другой механизм синхронизации носит название секвенсоров (sequencer). Буквальный перевод этого слова - "упорядочиватель" - так называются средства, которые выстраивают неупорядоченные события в определенном порядке. Как и счетчик событий, секвенсор представляется целым числом, над которым выполняется единственная операция: ticket. Операция ticket(S) возвращает текущее значение секвенсора и увеличивает его на 1. Операция является атомарной. Начальное значение секвенсора - 0.
Имея в своем распоряжении секвенсоры мы можем так записать решение задачи производителей-потребителей для произвольного числа процессов: 1 /* типы данных - счетчик событий и секвенсор */ 2 typedef unsigned int eventcounter; 3 typedef unsigned int sequencer; 4 static eventcounter inCnt = 0, outCnt = 0; /* счетчики для чтения и записи */ 5 /* секвенсоры для чтения и записи */ 6 static sequencer inSeq = 0, outSeq = 0; 7 static portion buffer [BUFSIZE]; /* буфер */ 8 /*== процесс-производитель ==*/ 9 void producer ( void ) { 10 int portNum; /* номер порции */ 11 portion work; /* рабочая область для порции */ 12 /* цикл производства */ 13 while (1) { 14 < производство порции в work > 15 /* получение "билета" на запись порции */ 16 portNum = ticket (inSeq); 17 /* ожидание номера порции */ 18 await (inCnt, portNum); 19 /* ожидание свободного места в буфере */ 20 await (outCnt, portNum - BSIZE+1); 21 /* запись в буфер */ 22 memcpy (buffer + portNum % BSIZE, &work, sizeof(portion) ); 23 /* продвижение счетчика чтения */ 24 advance (inCnt); 25 } 26 } 27 /*= процесс-потребитель =*/ 28 void consumer ( void ) { 29 int portNum; /* номер порции */ 30 portion work; /* рабочая область для порции */ 31 /* цикл потребления */ 32 while (1) { 33 /* получение "билета" на выборку порции */ 34 portNum = ticket (outSeq); 35 /* ожидание номера порции */ 36 await (outCnt, portNum); 37 /* ожидание появления в буфере */ 38 await (inCnt, portNum+1); 39 /* выборка порции */ 40 memcpy (&work, buffer + portNum % BSIZE, sizeof(portion) ); 41 /* продвижение счетчика записи */ 42 advance (outCnt); 43 < обработка порции в work > 44 } 45 }
Каждый производитель получает "билет" со своим номером в очереди на запись в буфер (строка 16). Затем он ожидает, когда до него дойдет очередь (строка 18), ожидает освобождения места в буфере (строка 20), записывает информацию (строки 22, 23) и наращивает счетчик производств (строка 24). Увеличение счетчика событий inCnt является сигналом к разблокированию как для потребителя, получившего "билет" на выборку этой порции и ожидающего в строке 36, так и для производителя, получившего "билет" на запись следующей порции и ожидающего в строке 20. Полученный процессом "билет" определяет и адрес в буфере той секции, с которой будет работать процесс. Хотя каждый процесс работает со своей секцией в буфере, одновременный доступ к буферу однотипных процессов исключается ожиданием в строке 18 или 36. Если разрешить одновременный доступ к буферу двух, например, производителей, то процесс, получивший "билет" на запись порции в n-ю секцию буфера может закончить запись раньше, чем процесс, пишущий порцию в n-1-ю секцию, даже если последний начал запись раньше. Процесс, закончивший запись, увеличит счетчик inCnt и выйдет из ожидания потребитель, имеющий билет на n-1-ю секцию, запись в которую еще не закончена.
Прямое подключение устройства
Рисунок 6.1. Прямое подключение устройства

Сколько-нибудь сложные по управлению устройства подсоединяются к ЭВМ через контроллеры ввода-вывода (устройства управления), причем один контроллер может обслуживать несколько однотипных устройств, как показано на Рисунке 6.2. С точки зрения программного интерфейса это подключение ничем не отличается от предыдущего варианта, регистры контроллера выглядят для программы так же, как и регистры устройств.
Проблема идентификации адресата
11.3. Проблема идентификации адресата
При параллельном выполнении нескольких процессов возникает проблема взаимодействия пользователя с ними: при появлении на экране сообщения, как пользователь определит, какой из процессов это сообщение выдал? при вводе сообщения пользователем, как ОС определит, какому процессу сообщение адресовано?. Решение этой проблемы зависит прежде всего от степени интерактивности процессов (насколько часто они обмениваются сообщениями с пользователем). Если процессы не очень интерактивны, то им можно разрешить квазиодновременный вывод на терминал: их сообщения могут чередоваться, но каждое сообщение должно быть неделимым. В этом случае выводимое сообщение должно нести в себе и идентификацию процесса, его выдавшего. Дейкстра [7] подробно рассмотрел реализацию диалогового взаимодействия такого рода с помощью семафоров. Им показано, что для этого случая ответы пользователя должны либо также содержать идентификатор процесса-адресата, либо пара действий вопрос-ответ должна быть одной транзакцией. В последнем случае, однако, задержка ответа надолго блокирует общий канал обмена между процессами и пользователем, поэтому у пользователя также должна быть возможность откладывания ответа с последующим возвращением к диалогу с этим же процессом.
Подход, предполагающий явное адресование сообщений, становится излишне громоздким, если пользователь работает с существенно интерактивными процессами. Общая идея обеспечения взаимодействия для такого случая состоит в том, что в каждый момент времени только одному процессу (по выбору пользователя) разрешается быть интерактивным (foreground - на переднем плане), то есть, иметь доступ к терминалу. Остальные процессы (background - фоновые) выполняются без доступа к терминалу. В распряжении пользователя имеются средства изменения статуса процесса - перемещения его с заднего плана на передний (текущий процесс переднего плана при этом отодвигается на задний план).
Что делать с фоновым процессом, если у него возникла необходимость выдать сообщение на терминал? Одним из решений может быть блокировка такого процесса до его выдвижения. Более эффективным является "скрытый" вывод, при котором обеспечивается для выполнения процессов несколько параллельных сеансов. В каждом сеансе могут выполняться один или несколько процессов. С каждым сеансом связан собственный буфер логического терминала, включающий в себя логический видеобуфер, логический буфер клавиатуры и логический буфер мыши. Весь обмен процесс ведет с логическим видеобуфером терминала. В каждый момент логический буфер только одного (так называемого, активного) сеанса связан с физическими буферами терминальных устройств. Таким образом, фоновый сеанс может вести обмен с терминалом (в основном - вывод) без отображения на терминал. Когда сеанс становится активным, его логический буфер связывается с физическими устройствами, и на экране видеотерминала отображается содержимое его логического видеобуфера. В составе API есть также средства аварийной активизации сеанса: если процессу, работающему в фоновом сеансе, необходимо выдать срочное сообщение, то он может воспользоваться так называемым "иллюминатором". На время существования иллюминатора ОС выделяет временный активный видеобуфер и все средства обмена с консолью работают с этим буфером. Это очень сильное средство, используемое только в исключительных случаях, так как на время существования иллюминатора блокируются запросы активного сеанса, а переключать сеансы в это время не может даже оператор.
Процедуры аутентификации и авторизации
Рисунок 10.1. Процедуры аутентификации и авторизации

В соответствии с требованиями безопасности система должна различать пользователей. Пользователь - это некоторое имя, определенное в системе и связанное с некоторым субъектом, который может выполнять доступ к ее ресурсам. Система должна "знать" своих пользователей, следовательно, в системе должна быть некоторая база данных, хранящая дескрипторы пользователей (имена м пароли). Информацию, хранящуюся в дескрипторе пользователя, иногда называют профилем (profile) пользователя. Различение пользователей (и, соответственно, ведение базы профилей) может быть заложено в ядро ОС или выполняться утилитами. По тому признаку, различает ли ядро ОС пользователей, мы и делим ОС на одно- или многопользовательские. (Так, например, OS/2 на уровне ядра является однопользовательской системой, но дополнительное программное обеспечение позволяет вводить регистрацию пользователей.) Хотя утилиты могут превратить однопользовательскую ОС в многопользовательскую, возможности защиты ресурсов в той ОС, у которой эти свойства заложены в ядро, принципиально большие.
Помимо имен и паролей, в профиль также могут входить настройки интерфейса рабочего места, процедура, автоматически выполняемая при начале пользователем сеанса, установки библиотек и каталогов для поиска и т.д. и т.п. В профиль может также входить "бюджетная информация" (account) - сведения о правах доступа и полномочиях пользователя. Даже в системах защиты, ориентированных на списки контроля доступа, некоторые данные бюджета все равно содержатся в профиле пользователя: его имя и пароль, его полномочия, список групп, к которым он принадлежит. (Некоторые из составляющих бюджета объясняются ниже.) Профили пользователей должны быть одними из наиболее строго защищаемых объектов в системе.
При входе пользователя в систему или при запуске приложения от его имени выполняется аутентификации (authentification). Эта процедура состоит в представлении пользователя системе при установлении связи с ней и подтверждении его подлинности. Подтверждение подлинности выполняется паролем. При выполнении аутентификации процесс входа в систему находит имя пользователя в базе профилей и сверяет введенный пользователем пароль с паролем, хранящимся в профиле. Как правило, пароль хранится в профиле пользователя в закодированном виде, причем используется кодирование на основе хеширования, не допускающее восстановление пароля по его хеш-коду. (Если пользователь забыл свой пароль, то даже системный администратор не может сообщить ему его пароль, а может только предоставить ему возможность назначить новый пароль.) Поэтому введенный пользователем пароль кодируется по тому же алгоритму и сравниваются уже хеш-коды паролей. При подтверждении системой легальности пользователя выбирается идентификатор безопасности для этого пользователя (косвенный указатель на бюджет пользователя), и этот идентификатор включается в контексты всех процессов, создаваемых данным пользователем. Естественно, что пользователь (или приложение), не прошедший процедуру аутентификации, к работе не допускается.
В системах обычно предусматривается возможность входа в систему пользователя-гостя (guest). Такой пользователь имеет доступ только к полностью открытым ресурсам и не имеет никаких полномочий.
После входа в систему пользователь (или работающее от его имени приложение) может запрашивать доступ к ресурсам. Каждый случай получения пользователем тех ресурсов, которые включены в число защищаемых, сопровождается процедурой авторизации (authorization), которая заключается в проверке того, может ли данный пользователь выполнять запрошенное действие над данным объектом. В процессе выполнения авторизации привлекается информация безопасности, связанная с объектом и информация безопасности, связанная с пользователем, и выносится решение о предоставлении или отклонении доступа. В объектно-ориентированных системах процедура авторизации может быть решена единообразно. Любая операция получения ресурса (getResource) должна сопровождаться единообразной проверкой полномочий и привилегий субъекта по отношению к данному объекту.
Процессы в ОС Unix
Рисунок 4.2. Процессы в ОС Unix

Хотя на Рисунок 4.2. между процессами init и shell находятся еще два процесса, shell может считаться прямым потомком init, так как находящиеся между ними процессы завершаются при запуске потомка.
В других ОС может выстраиваться и более сложная иерархия системных процессов. Так, например, в OS/390 между ядром ОС и задачей (task - синоним процесса в терминах IBM) пользователя находятся еще задачи: управления разделом; системного дампа; управления командой START; инициатор (для пакетных задач) или LOGON (для интерактивных задач).
Эти задачи существуют параллельно и выполняют управление ресурсами на разных уровнях.
При завершении родительского процесса не обязательно завершаются все его потомки. Некоторые процессы могут продолжать выполнение даже после завершения их непосредственного предка. Предком таких осиротевших процессов обычно становится процесс, находящийся в корне всего дерева наследования. Такие процессы обычно применяются для выполнения каких-либо фоновых задач, например, для ожидания и обработки каких-то внешних событий, и за ними закрепилось название демоны (daemon).
Программные каналы
9.6. Программные каналы
Программный канал по-английски называется pipe (труба), и это весьма удачное название. Канал действительно можно представить как трубопровод пневматической почты, проложенный между двумя процессами, как показано на Рисунок 9.1. По этому трубопроводу данные передаются от одного процесса к другому. Как и трубопровод, программный канал однонаправленный (хотя, например, в Unix одним системным вызовом создаются сразу два разнонаправленных канала). Как и трубопровод, программный канал имеет собственную емкость: данные записанные в канал, не обязательно должны немедленно выбираться не противоположном его конце, но могут накапливаться в канале, пока это позволяет его емкость. Как и трубопровод, канал работает по дисциплине FIFO: первый вошел - первый вышел.
Рисунок 9.1. Программные каналы

Из всех средств взаимодействия между процессами каналы (pipe) лучше всего вписываются в модель виртуальных коммуникационных портов. Канал для процесса практически аналогичен файлу. Специальные системные вызовы типа createPipe, openPipe используются для создания канала и получения доступа к каналу, а для работы с каналом используются те же вызовы read и write, что и для файлов, и даже закрытие канала выполняется файловым системным вызовом close. При создании канала для него создается дескриптор, как для открытого файла, что позволяет работать с ним далее, как с файлом. Канал, однако, представляет собой не внешние данные, а область памяти. Для канала выделяется память в системной области, что может ограничивать емкость канала.
Наиболее часто используются неименованные каналы, как средство связи между родителем и потомком. Операция создания неименованного канала возвращает два файловых манипулятора: для чтения и для записи. Процесс-предок передает эти манипуляторы процессу-потомку. Если связь между предком и потомком однонаправленная, то каждый из них закрывает канал по одному из манипуляторов. Например, если данные передаются только от предка к потомку, то предок после передачи манипуляторов закрывает канал на чтение, а потомок - на запись. Пример установления такой связи в ОС Unix приведен в главе 11, в фрагменте программы командного интерпретатора.
С точки зрения реализации канал представляет собой классический вариант задачи "производитель-потребитель": один процесс пишет в канал данные, другой - читает их из канала. Если при попытке записи данных в канал обнаруживается, что канал полон, пишущий процесс блокируется до освобождения места в канале, если при попытке чтения данных обнаруживается, что канал пуст - читающий процесс блокируется до появления в канале данных. Внутренним механизмом ОС, обеспечивающим синхронизацию в таких ситуациях, является, конечно же, семафор.
Именованные каналы представляют собой удобное средство клиент-серверных коммуникаций. Именованные каналы в некоторых ОС (например, OS/2) существенно отличаются от неименованных. Именованные каналы ориентированы в этих системах прежде всего на взаимодействие процессов в сетевой среде (или, точнее, для них прозрачно, находятся ли оба процесса на одном компьютере или в разных узлах сети). Такой канал двунаправленный, то есть, к нему возможны обращения и для чтения, и для записи. Данные в канале могут передаваться как потоком байт, так и сообщениями. В последнем случае каждое сообщение снабжается заголовком, в котором указывается его длина. К одному концу канала постоянно подключен процесс, его создавший - владелец или сервер, к другому концу могут подключаться различные процессы-клиенты, таким образом, обмен данными по именованному каналу между процессами, ни один из которых не является владельцем канала, невозможен. При создании канала (системный вызов createNamedPipe) указывается максимально возможное число клиентов, которые могут быть одновременно подключены к каналу (это число, впрочем, может и не ограничиваться). Когда владелец создает канал, канал находится в так называемом отключенном состоянии. Системным вызовом connectNamedPipe владелец переводит канал в ждущее состояние. Теперь процессы-клиенты могут подключаться к другому концу канала при помощи файловых системных вызовов openNamedPipe. Канал, открытый хотя бы одним клиентом, считается подключенным, сервер и подключенные клиенты могут работать с ним, используя вызовы файлового API. Клиенты отключаются от канала вызовом close, в распоряжении владельца есть вызов disconnectNamedPipe - разрыва канала. Помимо обычных вызовов файлового обмена, для работы с именованным каналом в составе API могут быть специальные системные вызовы, обеспечивающие выполнение сложных транзакций на именованном канале например: transactNamedPipe - взаимный обмен данными (вывод и ввод) за одну операцию, callNamedPipe - обеспечивает также открытие канала, взаимный обмен, закрытие канала. Кроме того, к именованному каналу или к нескольким именованным каналам может быть подключен семафор, который сбрасывается при изменении состояния канала (заполнен - не заполнен, пуст - не пуст).
"Производителипотребители"
8.6. "Производители-потребители"
Пусть мы имеем два циклических процесса, которые мы назовем "производитель" и "потребитель". Производитель в каждой итерации своего цикла вырабатывает (производит) порцию информации, которую он помещает в общий для обоих процессов буфер. Предположим для начала, что емкость буфера не ограничена. Потребитель в каждой итерации своего цикла выбирает из буфера порцию информации, выработанную производителем, и обрабатывает (потребляет) ее. Потребитель не должен начинать обработку порции, пока ее производство не будет закончено. Задача состоит в синхронизации действий производителя и потребителя таким образом, чтобы не допустить потерь и искажений информации, во-первых, и голодания процессов, во-вторых.
Решение достигается при помощи единственного общего семафора, играющего роль счетчика числа порций в буфере (здесь и далее мы предполагаем структуру семафора, определенную в предыдущем разделе): 1 static semaphore *portCnt = { 0, 0, NULL }; 2 static ... buffer ...; 3 /* процесс-производитель */ 4 void producer ( void ) { 5 while (1) { 6 < производство порции > 7 < добавление порции в буфер > 8 V(portCnt); 9 } 10 } 11 /* процесс-потребитель */ 12 void consumer ( void ) { 13 while (1) { 14 P(portCnt) 15 < выборка порции из буфера > 16 < обработка порции > 17 } 18 }
Исходное значение семафора portCnt - 0. Производитель каждую итерацию своего цикла заканчивает V-операцией, увеличивающей значение счетчика. Потребитель каждую свою итерацию начинает P-операцией. Если буфер пуст, то потребитель задержится в своей P-операции до появления в буфере очередной порции. Таким образом, если потребитель работает быстрее производителя, он будет время от времени простаивать, если производитель работает быстрее - в буфере будут накапливаться порции.
В реальных задачах такого рода буфер всегда имеет некоторую конечную емкость. Если производитель работает быстрее, то при заполнении буфера он должен приостанавливаться, ожидая освобождения места в буфере. Это легко обеспечить, введя новый семафор freeCnt, выполняющий роль счетчика свободных мест в буфере: 1 static semaphore *portCnt = { 0, 0, NULL }, 2 *freeCnt = { BSIZE, 0, NULL }, 3 static ... buffer [BSIZE]; 4 /* процесс-производитель */ 5 void producer ( void ) { 6 while (1) { 7 < производство порции > 8 P(freeCnt); 9 < добавление порции в буфер > 10 V(portCnt); 11 } 12 } 13 /* процесс-потребитель */ 14 void consumer ( void ) { 15 while (1) { 16 P(portCnt) 17 < выборка порции из буфера > 18 V(freeCnt); 19 < обработка порции > 20 } 21 }
Попытаемся теперь обобщить решение для произвольного числа производителей и потребителей. Но в таком обобщении мы сталкиваемся с еще одной существенной особенностью. В вышеприведенных решениях мы допускали одновременное выполнение операций <добавление порции в буфер> и <выборка порции из буфера> . Очевидно, что при любой организации буфера производитель и потребитель могут одновременно работать только с разными порциями информации. Иначе обстоит дело с многочисленными производителями и потребителями. Два производителя могут попытаться одновременно добавить порцию в буфер и выбрать для этого одно и то же место в буфере. Аналогично, два потребителя могут попытаться выбрать из буфера одну и ту же порцию. В следующем примере мы для наглядности представляем буфер в виде кольцевой очереди с элементами (порциями) одинакового размера: 1 typedef ... portion; /* порция информации */ 2 static portion buffer [BSIZE]; 3 static int wIndex = 0, rIndex = 0; 4 static semaphore *portCnt = { 0, 0, NULL }, 5 *freeCnt = { BSIZE, 0, NULL }, 6 *rAccess = { 1, 0, NULL }, 7 *wAccess = { 1, 0, NULL }; 8 /* имеется NP аналогичных процессов-производителей */ 9 void producer ( void ) { 10 portion work; 11 while (1) { 12 < производство порции в work > 13 P(wAccess); 14 P(freeCnt); 15 /* добавление порции в буфер */ 16 memcpy(buffer+wIndex,&work, sizeof(portion) ); 17 if ( ++wIndex == BSIZE ) w_index = 0; 18 V(portCnt); 19 V(wAccess); 20 } 21 } 22 /* имеется NC аналогичных процессов-потребителей */ 23 void consumer ( void ) { 24 portion work; 25 while (1) { 26 P(rAccess); 27 P(portCnt) 28 /* выборка порции из буфера */ 29 memcpy(&work, buffer+rIndex, sizeof(portion) ); 30 if ( ++rIndex == BSIZE ) rIndex = 0; 31 V(freeCnt); 32 V(rAaccess); 33 < обработка порции в work> 34 } 35 }
Мы оформляем обращения к буферу как критические секции, защищая их семафорами rAccess и wAccess. Поскольку конфликтовать (пытаться работать с одной и той же порцией в буфере) могут только однотипные процессы, мы рассматриваем буфер как два ресурса: ресурс для чтения и ресурс для записи и каждый такой ресурс защищается своим семафором. Таким образом запрещается одновременный доступ к буферу двух производителей или двух потребителей, но разрешается одновременный доступ одного производителя и одного потребителя.
Простая модель монитора
Рисунок 8.2. Простая модель монитора

Обратите внимание на то, что взаимное исключение обеспечивается для всех охраняемых процедур, а не только для одноименных. В сущности, такая процедура представляет собой ту же критическую секцию, и ее охрана реализуется любым из методов защиты критической секции, скорее всего, в роли "охранника" будет выступать скрытый семафор.
Другие наши нововведения связаны с блокировками внутри охраняемой процедуры. Мы ввели тип данных, названный нами event. Этот тип представляет некоторое событие. Примитив wait проверяет наступление этого события и переводит процесс в ожидание, если событие еще не произошло. Примитив signal сигнализирует о наступлении события. Событие является потребляемым ресурсом: если два процесса ожидают одного и того же события, то при наступлении события разблокирован будет только один из процессов, другой будет вынужден ждать повторного наступления такого же события.
Примитивы ожидания-сигнализации требуют принятия решений по ряду проблем их реализации. Если один процесс выдает сигнал о наступлении некоторого события, то в какой момент должен быть разблокирован процесс, ожидающий этого события? Если немедленно, то тогда в нашей "комнате" окажется два процесса одновременно: разблокированный процесс и процесс, выдавший сигнал, но еще не покинувший монитор. Если позже, то за это время в монитор может войти какой-то третий процесс. Если несколько процессов ожидают одного и того же события, то какой (или какие) из них должен быть разблокирован? Если в момент выдачи сигнала нет процессов, ожидающих этого события, то должен ли сигнал сохраняться или его можно "потерять"?
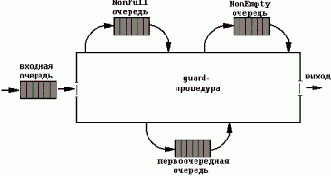
Общий подход к решению этой проблемы иллюстрируется расширением модели "одноместной комнаты", показанным на Рисунке 8.3. Для каждого события, которое может ожидаться в мониторе, мы водим свою очередь с соответствующими входными и выходными дверями для нее. На рисунке эти очереди показаны внизу монитора. Мы вводим также очередь, которую мы называем приоритетной. Процессы, находящиеся в очередях, не считаются находящимися в мониторе. "Правила для посетителей" комнаты-монитора следующие. Новый процесс поступает во входную очередь. Новый процесс может войти в монитор через дверь 1 только, если в мониторе нет других процессов. Если процесс выходит из монитора через дверь 2 (выход), то в монитор входит процесс из двери 4 - из приоритетной очереди. Если в приоритетной очереди нет ожидающих, входит процесс из двери 1 (если есть ожидающие за ней). Процесс, выполняющий операцию wait, выходит из монитора в дверь, ведущую в соответствующую очередь (5 или 7). Если процесс выполняет операцию signal, то проверяется очередь, связанная с событием. Если эта очередь непуста, то сигнализирующий процесс уходит в приоритетную очередь (дверь 3), а в монитор входит один процесс из очереди к событию (дверь 6 или 8). Если очередь пуста, сигнализирующий процесс остается в мониторе. Все очереди обслуживаются по дисциплине FCFS.
Рандеву
8.11. Рандеву
Модель взаимодействия процессов, названная рандеву, рассматривает синхронизацию и передачу данных как единую деятельность. Когда процесс A намерен передать данные процессу B, оба процесса должны объявить о своей готовности установить связь, выдав запросы на передачу и прием данных соответственно. Если процесс A выдает заявку на передачу прежде, чем процесс B выдал заявку на прием, то процесс A приостанавливается до выдачи заявки процессом B. И наоборот: если процесс B выдал заявку на прием раньше, чем процесс A на передачу, то приостанавливается процесс B. Таким образом, процессы взаимодействуют только при встрече (рандеву) их заявок на передачу и прием.
В абстрактной записи взаимодействие между процессами записывается так: 1 processA { 2 объявление локальной переменной x; 3 . . . 4 B!x; 5 . . . 6 } 7 processB { 8 объявление локальной переменной y; 9 . . . 10 A?y; 11 . . . 12 }
Нотация B!x в строке 4 означает, что процесс A передает процессу B значение своей переменной x. A?y в строке 10 означает, что процесс B принимает значение, переданное процессом A, и записывает его в свою переменную y.
Эта запись отражает, так называемую, синхронную модель рандеву. Запись асинхронной модели мы можем получить, заменив строку 10 на: 10 ?y;
В синхронной модели оба процесса должны указывать в операторах приема или передачи имя процесса-корреспондента. В асинхронной модели только процесс-передатчик указывает имя процесса-приемника. "Безадресный" оператор приема соответствует идеям структуризации данных и программирования "снизу вверх", развивавшимся автором моделей рандеву и мониторов - К.Хоаром [6]. Асинхронная модель делает возможным разработку библиотечных процессов, которые, во-первых, могут использоваться в разных разработках, а во-вторых, играть роль процессов-серверов, обрабатывающих запросы от разных параллельно выполняющихся процессов-клиентов.
Асинхронная модель рандеву лежит в основе взаимодействия процессов в языке ADA. Мы не имеем возможности дать здесь полное описание языка (его синтаксис во многом подобен синтаксису языка Pascal) и ограничимся только средствами, интересующими нас в первую очередь. Во всех последующих примерах ключевые слова языка ADA записаны строчными буквами.
Процесс в языке ADA называется задачей и описание задачи состоит из спецификаций задачи и ее тела. Спецификация имеет структуру: task ИМЯ_ЗАДАЧИ is < описания входных точек > end; Тело имеет структуру: task body ИМЯ_ЗАДАЧИ is < переменные и операторы > end ИМЯ_ЗАДАЧИ;
В спецификации указываются точки входа задачи для рандеву. Их описания идентичны описаниям процедур: имя и параметры с указанием направления передачи параметров: in, out или inout. В задаче, обращающейся ко входной точке, обращение выглядит точно так же, как обращение к процедуре. Однако, выполняется такое обращение иначе. В задаче-приемнике такое обращение обрабатывается оператором приема. В простейшем случае такой оператор имеет вид: accept ИМЯ_ВХОДА ( < параметры > ) do < операторы > end;
Оператор приема входит в структуру последовательно выполняемых операторов тела задачи. Если при обращении к данному входу выполнение задачи-приемника еще не дошло до оператора приема, то задача-передатчик блокируется. Если выполнение дошло до оператора приема, но обращения к данному входу не было, блокируется задача-приемник.
В ряде случаев неизвестно заранее, в какой последовательности будут поступать запросы. Для недетерминированного выбора из нескольких возможных запросов используется оператор отбора: select < оператор accept > < другие операторы > or < оператор accept > < другие операторы > or . . . else < другие операторы > end;
Когда выполнение приемника доходит до оператора отбора, приемник готов выполнить любой из операторов приема, перечисленных среди альтернатив отбора. Если к этому моменту уже поступили обращения к нескольким входам, включенным в отбор, принимается одно из обращений (какое именно - правила языка не определяют). Если обращений нет, то либо выполняется альтернатива else, либо (если эта альтернатива не задана) процесс-приемник ожидает.
Операторы accept, составляющие альтернативы отбора, могут быть "защищены" условиями. Заголовок оператора в этом случае выглядит так: when <логическое выражение > => accept ...
Защищенный оператор приема включается в число альтернатив отбора только в том случае, если логическое выражение имеет значение "истина".
Наше краткое описание средств языка само по себе, видимо, недостаточно для его понимания, поэтому проиллюстрируем его примером - все той же задачей производителей-потребителей: 1 PROD_CONS: declare; 2 /* пустая спецификация производителя */ 3 task PRODUCER is 4 end; 5 /* тело производителя */ 6 task body PRODUCER is 7 /* рабочая область для порции */ 8 WORK : PORTION; 9 begin 10 loop /* цикл производства */ 11 < производство порции в WORK > 12 PUTPORTION(WORK); /* запись порции */ 13 end loop; /* конец цикла производства */ 14 end PRODUCER;/* конец тела производителя */ 15 /* пустая спецификация потребителя */ 16 task CONSUMER is 17 end; 18 /* тело потребителя */ 19 task body CONSUMER is 20 /* рабочая область для порции */ 21 WORK : PORTION; 22 begin 23 loop /* цикл потребления */ 24 GETPORTION ( WORK ); /* выборка порции */ 25 < обработка порции в WORK > 26 end loop; /* конец цикла потребления */ 27 end CONSUMER; /* конец тела потребителя */ 28 /* спецификация задачи-сервера */ 29 task SERVER is 33 /* описание входных точек сервера */ 37 entry GETPORTION(PORT : out PORTION); 32 entry PUTPORTION(PORT : in PORTION); 33 end; 34 /* тело сервера */ 35 task body SERVER is 36 /* буфер */ 37 BUFFER : array [1..BSIZE] of PORTION; 38 /* индексы для чтения и записи */ 39 INCNT, OUTCNT : INTEGER range 1..BSIZE := 1; 40 /* счетчик порций в буфере */ 41 PORTCNT : INTEGER range 0..BSIZE := 0; 42 begin 43 loop /* цикл обслуживания */ 44 /* выбор из наступивших событий */ 45 select when PORTCNT < BSIZE => 46 /* если буфер не полон, обслуживается запись */ 47 accept PUTPORTION(PORT:in PORTION) do 48 BUFFER[INCNT] := PORT; /* запись */ 49 end; 50 /* модификация счетчиков */ 51 INCNT := INCNT mod BSIZE + 1; 52 PORTCNT := PORTCNT + 1; 53 or 54 /* или если буфер не пуст, обслуживается выборка */ 55 accept GETPORTION(PORT:out PORTION) do 56 PORT := BUFFER[OUTCNT]; /* выборка */ 57 end; 58 /* модификация счетчиков */ 59 OUTCNT := OUTCNT mod BSIZE + 1; 60 PORTCNT := PORTCNT - 1; 61 end select; /* конец выбора */ 62 end loop; /* конец цикла обслуживания */ 63 end SERVER; /* конец тела сервера */ 64 /* главная процедура */ 65 begin 66 /* запуск всех задач */ 67 initiate SERVER, PRODUCER, CONSUMER; 68 end.
В нашу программу входят: главная процедура (строки 64 - 68); задача-производитель (строки 2 - 14); задача-потребитель (строки 15 - 27); задача-сервер (строки 28 - 63), обеспечивающая обмен производителя и потребителя с буфером.
Главная процедура запускает три другие задачи оператором initiate (строка 67) и переходит в ожидание. Она завершится, когда завершатся все запущенные ею задачи. Задачи PRODUCER и CONSUMER не имеют операторов приема, поэтому их спецификации (строки 2 - 4 и 15 - 17) вырожденные - пустые. Тела этих задач содержат простые бесконечные циклы (loop), в которых выполняется подготовка или обработка порции и обращение к соответствующей входной точке сервера. Задача SERVER является аналогом монитора. В ее спецификации (строки 28 - 33) описаны две входные точки: GETPORTION и PUTPORTION. Сам буфер является локальным в теле сервера (строка 37), также локальны и индексы чтения и записи (строки 39, 40) и счетчик порций (строкa 41). Выполнение сервера представляет собой бесконечный цикл (строки 43 - 62), в каждой итерации которого обрабатывается одно обращение. Оператор select (строки 45 - 61) обеспечивает выбор из обращений: GETPORTION или PUTPORTION. В зависимости от значения счетчика PORTCNT из числа альтернатив может исключаться GETPORTION - если буфер пуст или PUTPORTION - если полон. Если к началу очередной итерации обращений нет или есть обращение, которое не позволяет принять защита when, сервер ожидает. Обратите внимание на операторные скобки do ... end, следующие за операторами accept (строки 47 - 49 и 55 - 57). Они ограничивают критическую секцию. Выполнение процесса-передатчика не возобновится до тех пор, пока процесс-приемник не выйдет из критической секции. Мы включили в критические секции приемов только операторы, непосредственно работающие с параметрами вызовов, так как основное предназначение этой секции - защита параметров от преждевременного их изменения. Остальные операторы, выполняемые в ходе обработки вызовов (модификация индексов и счетчика), выполняются уже вне критической секции.
В нашем примере мы запустили по одному производителю и потребителю. В языке, однако, имеется возможность запускать любое число однотипных задач - как полностью идентичных, так и различающихся значениями параметров.
Модель рандеву как достаточно универсальный метод взаимодействия позволяет легко реализовать и примитивы взаимного исключения и синхронизации. Двоичный семафор, например, выглядит так: 1 task SEMAPHORE is 2 entry P; 3 entry V; 4 end; 5 task body SEMAPHORE is 6 begin 7 loop 8 accept P; 9 accept V; 10 end loop; 11 end SEMAPHORE;
В этой задаче операторы приема не являются альтернативными, а выполняются строго последовательно. Если какая-либо внешняя задача выполнит P-обращение, то любая задача, выдавшая еще одно P-обращение, будет заблокирована до тех пор, пока не будет выполнено V-обращение, и семафор не войдет в следующую итерацию своего цикла.
Асимметричные рандеву являются дальнейшим развитием идеи мониторов. В большинстве ADA-приложений задачи четко разделяются на задачи-клиенты, выдающие вызовы, и задачи-серверы, их принимающие. Но концептуально рандеву являются более универсальным и гибким средством взаимодействия процессов. Обратите внимание на то, что взаимодействующие задачи не используют общих переменных. Это делает язык ADA независимым от конкретной реализации параллельной работы в системе: это может быть однопроцессорная система с разделением времени, мультипроцессорная система с общей памятью или многомашинная система (сеть).
Существенным недостатком модели рандеву является то, что большинство решений, ее использующих, требует введения дополнительных процессов (в наших примерах - задача-сервер или семафор, как отдельная задача). Это увеличивает число переключений процессов и накладные расходы системы.
Расширенная модель монитора
Рисунок 8.3. Расширенная модель монитора
Эти правила предполагают, что процесс будет разблокирован немедленно (речь идет не о немедленной активизации процесса, а о его разблокировании - перемещении в очередь готовых к выполнению). Разблокированный процесс имеет преимущество перед процессом, ожидающим во входной очереди.
В нашем примере производителей-потребителей мы употребляли операцию signal в конце процедуры. Такое употребление характерно для очень большого числа задач. Наши правила требуют перемещения сигнализирующего процесса в приоритетную очередь. Однако, если сигнализирующий процесс после выдачи сигнала больше не выполняет никаких действий с разделяемыми данными, необходимости в таком перемещении (и вообще в приоритетной очереди) нет. Жесткая привязка сигнала к окончанию охраняемой процедуры снижает гибкость монитора, но значительно упрощает диспетчеризацию процессов в мониторе.
Возможно решение, в котором операция signal разблокирует все процессы, находящиеся в соответствующей очереди. Поскольку все ожидавшие процессы не могут вместе войти в монитор, в нем остается только один из них, успевший "подхватить" событие, а остальные направляются в приоритетную очередь. Процесс, который разблокировался таким образом, уже не может, однако, быть уверенным в том, что его разблокирование гарантирует наступление события (событие могло быть перехвачено другим процессом). Поэтому в проверке условия ожидания оператор if для такой реализации должен быть заменен оператором while, например, строки 11, 12 последнего примера должны выглядеть так: 11 / если буфер полон - ожидать события НЕ_ПОЛОН */ 12 while ( cnt == BSIZE ) wait (nonFull);
Поскольку охраняемые процедуры есть критические секции, для поддержания высокого уровня мультипрограммирования нахождение в них процессов должно быть кратковременным. Проблема времени может возникнуть в том случае, когда в процедуре монитора имеется обращение к другому монитору. По нашим правилам такое обращение не выводит процесс из первого монитора. Однако во втором (вложенном) мониторе процесс может быть заблокирован, тогда его пребывание в первом мониторе недопустимо затянется. Возможно несколько вариантов решения этой проблемы: переложить ответственность за возникновение такой ситуации на программиста; запретить вложенные вызовы вообще; при вхождении во вложенный монитор автоматически снимать исключение с внешнего монитора, когда процесс возвращается из вложенного монитора, он попадает в приоритетную очередь внешнего монитора; предоставить программисту выбор из перечисленных выше возможностей.
Внутренней дырой называется память, которая
Рисунок 3.2. Разделы в реальной памяти OS/360

Внутренней дырой называется память, которая распределена процессу, но им не используется. Так, на Рис 3.2.а процессу 1 выделен раздел P1, но виртуальное адресное пространство процесса меньше размера раздела, оставшееся пространство раздела составляет внутреннюю дыру. Внешней дырой называется область реальной памяти, которая не распределена никакому процессу, но слишком мала, чтобы удовлетворить запрос на память. На Рис 3.2.б суммарный размер свободных областей, возможно, превышает запрос, но каждая из этих областей в отдельности меньше запроса, поэтому все эти свободные области являются внешними дырами.
Для управления памятью формируются те или иные управляющие структуры (заголовки), которые также занимают память. В некоторых системах общий объем заголовочной памяти может быть очень большим, и в таких случаях следует учитывать также и заголовочные дыры - области памяти, которые содержат не используемую в данный момент управляющую информацию. В системах с реальной памятью заголовочные дыры практически отсутствуют.
Хотя в любом случае невозможность использовать память является злом, внешние дыры, являются "меньшим злом", так как, во-первых, блок свободной памяти становится дырой из за малого своего размера, а "малый" - понятие относительное, во-вторых, в моделях памяти с динамической трансляцией адресов существуют методы борьбы с внешними дырами.
Модель с фиксированными разделами представляет весьма ограниченную версию управления памятью. Вытеснение здесь вообще не реализуется, процесс, которому недостает памяти, просто блокируется до освобождения требуемого ресурса (в OS/360 MFT можно было наблюдать даже такое явление: задача, требующая объема памяти, превышающего размер раздела, просто "запирала" этот раздел до перезагрузки системы). Стратегия подкачки здесь примитивная: весь процесс размещается в реальной памяти при его создании. В варианте MFT практически отсутствует и стратегия размещения: процесс размещается с начала раздела, а решение о размещении раздела и о распределении задач по разделам принимает оператор. А вот в варианте MVT, поскольку границы разделов не зафиксированы, ОС необходимо принимать решение о размещении. В этой ОС уровень мультипрограммирования был невысок (обычно 4 - 5 процессов), поэтому стратегия размещения принималась простейшая, а вот в системах с более высоким уровнем мультипрограммирования и, следовательно, со значительной фрагментацией памяти может оказаться целесообразным выбор более сложной и гибкой стратегии.
Первый вопрос, решаемый в стратегии размещения - способ представления свободной памяти. Существует два основных метода такого представления: списки свободных блоков и битовые карты. В первом методе ОС из свободных блоков памяти организует линейный список и хранит адрес начала этого списка. При обработке такого списка должна учитываться необходимость слияния двух смежных свободных блоков в один свободный блок суммарного размера. Эта задача может быть существенно упрощена, если список упорядочивается по возрастанию адресов блоков. Во втором методе память условно разбивается на некоторые единицы распределения (параграфы) и создается "карта памяти" (memory map) - битовый массив в котором каждый бит соответствует одному параграфу памяти и отображает его состояние: 1 - занят, 0 - свободен. Поиск свободного блока требуемого размера сводится к поиску цепочки нулевых бит требуемой длины. Выбор размера параграфа определяется компромиссом между потерями памяти на внутренних дырах (при большом размере параграфа) и потерями на размещение в памяти самой карты (при малом размере параграфа).
При не очень большой фрагментации памяти списки свободных блоков занимают меньше места, чем карта, но их обработка несколько сложнее.
Выбранная структура представления свободной памяти не ограничивает выбор стратегии размещения.
Простейшей стратегией размещения является стратегия "первый подходящий" (first hit): просматривается список свободных блоков (или карта памяти) и выбирается первый же найденный блок, у которого размер не меньше требуемого. Если размер найденного блока превышает запрошенный, то оставшаяся его часть оформляется как свободный блок. При всей своей простоте эта стратегия дает неплохие результаты и применяется в большинстве систем с фиксированными разделами и с сегментацией (см. ниже). При значительной фрагментации алгоритм может быть модифицирован кольцевым поиском. Если всякий раз поиск начинается с начала списка/карты, то маленькие свободные участки будут накапливаться в списка/карты и для нахождения свободного блока значительной длины надо будет сначала выбрать и отбросить много маленьких блоков. При кольцевом поиске поиск всякий раз начинается с того места, на котором он закончился в прошлый раз, а при достижении конца списка/карты - продолжается с начала. Таким приемом сокращается среднее время поиска.
Другой несложной стратегией является "самый подходящий" (best hit): просматривается весь список свободных блоков (или карта памяти) и выбирается блок, размер которого равен запросу или превышает его на минимальную величину. Хотя на первый взгляд этот метод может показаться более эффективным, он дает в среднем худшие результаты, чем "первый подходящий". Во-первых, это объясняется тем, что здесь следует обязательно просмотреть весь список или карту, во-вторых, тем, что здесь более интенсивно накапливаются внешние дыры, так как остатки от "самых подходящих" блоков оказываются маленького размера. Существенным же преимуществом этой стратегии является то, что она охраняет большие свободные блоки от "разбазаривания по мелочам".
Первый недостаток метода "самый подходящий" может быть преодолен при упорядочении списка свободных блоков по возрастанию размеров: полный просмотр списка тогда не потребуется, но будет усложнена задача слияния смежных блоков. Еще более ускоряет поиск разбиение списка свободных блоков на несколько подсписков, каждый из подсписков содержит блоки, размер которых ограничен сверху и снизу. Поиск ускоряется за счет просмотра только подсписка, соответствующего запросу, если в подсписке выбирать первый подходящий, то отчасти сглаживается и острота проблемы внешних дыр. При представлении свободной памяти в виде карты аналогичный эффект может быть получен при создании нескольких карт разного масштаба и поиске по той карте, масштаб которой соответствует запрошенному размеру блока.
Поскольку модель с фиксированными разделами ограничивает виртуальное адресное пространство размерами реальной памяти, возникает проблема больших программ, не вмещающихся в доступную память. Преодоление этого ограничения достигается созданием программ с оверлейной (overlay - перекрытие) структурой. Структура межмодульных вызовов оверлейной программы имеет вид дерева. В корне дерева (нулевой уровень) находится модуль-монитор, из которого происходят обращения к модулям, расположенным на ветвях дерева. Каждый модуль первого уровня в свою очередь может быть корнем поддерева и т.д. Принцип оверлейности или перекрытия заключается в том, что ветви дерева занимают одни и те же области в виртуальном адресном пространстве программы. Поскольку модули, расположенные в разных ветвях дерева, не могут выполняться одновременно, то только монитор является резидентным в оперативной памяти все время выполнения программы, ветви же сменяют друг друга в одной и той же области памяти. На самом деле построить программу, имеющую идеальную древовидную структуру, довольно трудно, поскольку при этом обязательно догматическое соблюдение дисциплины программирования "сверху вниз". Необходимо тщательно следить, чтобы ветви дерева не пересекались: никакой модуль не имеет права передавать управление в модуль, расположенный на другой ветви, или обращаться к данным, определенным в модуле другой ветви. Реальные программы обычно нарушают эти правила, так как при их разработке используется комбинация дисциплин "сверху вниз" и "снизу вверх", за счет чего появляются низкоуровневые процедуры, обращения к которым производится из любых ветвей дерева. Выход из противоречия состоит либо в помещении этих процедур в корневой модуль, либо в создании еще одной или нескольких резидентных областей для размещения модулей, содержащих эти процедуры. В системах, поддерживающих развитые средства создания оверлейных программ (та же OS/360), выполнение функции именования - отображения имен входных точек и общих переменных на виртуальное адресное пространство возлагается на редактор связей (link editor), который и формирует содержимое адресного пространства процесса в соответствии с оверлейной структурой, описываемой программистом с помощью специального языка. На Рисунке 3.3 представлен пример оверлейной структуры программы.
Другой аспект распределения дисковой памяти
Рисунок 7.4. Размещение файла в файловой системе s5

Другой аспект распределения дисковой памяти - учет свободного пространства на диске. Как и для учета размещения файлов, здесь применяются либо карта дискового пространства, либо списки свободных блоков. В случае, если размещение файлов отслеживается картой размещения, на этой же карте могут быть отображены и свободные блоки. Если же используются различные механизмы отслеживания размещения и учета свободного пространства, то карта свободной памяти может состоять из однобитовых элементов со значением 0 - свободен, 1 - занят. Поиск свободного участка заданного размера сводится к поиску в карте цепочки нулевых бит заданной длины. Если для системы имеет значение выделение дисковой памяти непрерывными участками, то состояние дискового пространства может отображаться в двух или более картах разного "масштаба". Наряду с обязательной картой свободных блоков, самой "мелкомасштабной", может существовать карта свободных дорожек и карта свободных цилиндров. Наличие "крупномасштабных" карт позволяет ускорить поиск больших непрерывных свободных участков.
Списки свободных блоков организуются точно так же, как и списки блоков, принадлежащих файлу. Дескриптор диска содержит указатель на начало списка свободных блоков. Последовательная природа списка не оказывает влияния на эффективность его обработки, так как список свободных блоков может обрабатываться по дисциплине LIFO - выборка блока происходит из начала списка, и новый свободный блок также добавляется в начало списка. Изящный пример работы со свободными блоками показывает та же ФС s5, пример относится к категории "ленивых политик", свойственных этой ОС Unix.
В дескрипторе диска s5 (суперблоке) содержится массив из 10 номеров свободных блоков. Поскольку суперблок в процессе работы хранится в оперативной памяти, первые 10 свободных блоков могут быть выбраны без обращений к внешней памяти. Если этот "запас" свободных блоков исчерпан, то используется последний элемент этого массива, который ссылается на свободный блок, содержащий еще 10 номеров свободных блоков. Эти новые номера заново заполняют массив в суперблоке и т.д. При необходимости включить в список новые свободные блоки их номера сохраняются в массиве суперблока, пока в нем есть свободные места. Если же свободные места исчерпаны, массив выводится в блок на внешней памяти, добавдяемый в список, а место в суперблоке освобождается.
Сегментностраничная модель
3.6. Сегментно-страничная модель
Из предыдущего изложения должно быть ясно, что сегментная модель памяти ориентирована в большей степени на программиста, а страничная - на ОС. Программисту удобно компоновать команды и данные своего процесса в блоки переменной длины (сегменты). ОС же удобнее управлять памятью, разбитой на блоки постоянной длины (страницы). Естественным путем развития моделей памяти явилось объединение достоинств этих двух моделей в одной - сегментно-страничной.
Виртуальный адрес теперь состоит из трех частей - номера сегмента, номера страницы в сегменте и смещения в странице. Аппарат трансляции адресов, представленный на Рисунке 3.8, по крайней мере, трехшаговый: регистр адреса дескриптора указывает на таблицу сегментов, из нее выбирается дескриптор сегмента, а из последнего - адрес таблицы страниц; из таблицы страниц выбирается дескриптор страницы, а из него - номер страничного кадра; реальный адрес получается сложением базового адреса страничного кадра со смещением в странице.
Семафоры
8.5. Семафоры
Все рассмотренные выше методы используют занятое ожидание: если процесс не может войти в критическую секцию, он зацикливается на опросе переменных состояния. Следующие методы используют блокировку ожидающего процесса - перевод его из списка процессов, планируемых на выполнение (готовых), в список ожидающих (заблокированных). Этим экономится процессорное время, в противном случае попусту растрачиваемое в занятом ожидании, а затраты сводятся к переключению процессов.
Такая возможность обеспечивается: введением специальных целочисленных общих переменных, которые называются семафорами; добавлением к набору элементарных действий, из которых строятся процессы, операций над семафорами: V-операции и P-операции.
V-операция есть операция с одним операндом, который должен быть семафором. Выполнение операции состоит в увеличении значения аргумента на 1, это действие должно быть атомарным.
P-операция есть операция с одним операндом, который должен быть семафором. Выполнение операции состоит в уменьшении значения аргумента на 1, если только это действие не приведет к отрицательному значению операнда. Выполнение P-операции, то есть, принятие решение о том, что момент является подходящим для уменьшения аргумента, и последующее его уменьшение должно быть атомарным.
Атомарность P-операции и является потенциальной задержкой: если процесс пытается выполнить P-операцию над семафором, значение которого в данный момент нулевое, данная P-операция не может завершиться пока другой процесс не выполнит V-операцию над этим семафором. Несколько процессов могут начать одновременно P-операцию над одним и тем же семафором. Тогда при установке семафора в 1 только одна из P-операций завершится, какая именно - мы обсудим позже.
Защита разделяемых ресурсов теперь выглядит следующим образом. Каждый ресурс защищается своим семафором, значение которого может быть 1 - свободен или 0 - занят. Процесс, выполняющий доступ к ресурсу, инициирует P-операцию (эквивалент csBegin). Если ресурс занят - процесс задерживается в своей P-операции до освобождения ресурса. Когда ресурс освобождается, P-операция процесса завершается, и процесс занимает ресурс. При освобождении ресурса процесс выполняет V-операцию (эквивалент csEnd).
Э.Дейкстра [7], вводя семафорные примитивы для синхронизации и взаимного исключения, исходил из гипотезы о том, что P- и V-операции реализованы в нашей вычислительной системе аппаратно. На самом же деле, в составе любого набора команд таких операций нет - и это оправданно. Программная реализация семафоров позволяет нам включить в них блокировку и диспетчеризацию процессов, чего нельзя было бы делать на аппаратном уровне.
В соответствии с общей методикой нашего подхода, сосредотачивающей внимание на механизмах реализации взаимного исключения, рассмотрим реализацию семафоров и операций над ними. Сам семафор может быть представлен следующим образом: 1 typedef struct { 2 int value; 3 char mutEx; 4 process *waitList; 5 } semaphore;
Здесь value - та самая целочисленная переменная, которая представляет значение семафора в приведенном выше определении. mutEx - переменная взаимного исключения, которая обеспечивает, как мы увидим ниже, атомарность операций над семафорами. waitList - указатель на список процессов, ожидающих установления этого семафора в 1. (Здесь мы предполагаем линейный однонаправленный список, но очередь ожидающих процессов может быть представлена и любым другим образом.)
Мы начинаем рассмотрение с, так называемых, двоичных семафоров, для которых допустимые значения - 0 и 1. Если семафор защищает критическую секцию, то начальное значение поля value = 1. Начальные значения других полей: mutEx = 0; waitList = NULL.
Операции над семафорами можно представить в виде следующих функций: 1 void P ( semaphore *s ) { 2 csBegin (&s->mutEx); 3 if (!s->value) block(s); 4 else { 5 s->value--; 6 csEnd (&s->mutEx); 7 } 8 } 9 void V ( semaphore *s ) { 10 csBegin (&s->mutEx); 11 if(s->waitList!= NULL) unBlock(s); 12 else s->value++; 13 csEnd (&s->mutEx); 14 }
В нашей реализации вы видите "скобки критической секции" как элементарные операции. Они обеспечивают атомарность выполнения семафоров и могут быть реализованы любым из описанных выше корректных способов. Здесь мы ориентируемся на команду testAndSet с использованием поля семафора mutEx в качестве замка, но это может быть и любая другая корректная реализация (в многопроцессорных версиях Unix, например, используется алгоритм Деккера). Вопрос: в чем же мы выигрываем, если в csBegin все равно используется занятое ожидание? Дело в том, что это занятое ожидание не может быть долгим. Этими "скобками критической секции" защищается не сам ресурс, а только связанный с ним семафор. Выполнение же семафорных операций происходит быстро, следовательно, и потери на занятое ожидание будут минимальными.
Если при выполнении P-операции оказывается, что значение семафора нулевое, выдается системный вызов block, который блокирует активный процесс - переводит его в список ожидающих, в тот самый список, который связан с данным семафором. Важно, что процесс прервется именно в контексте строки 3 своей P-операции и впоследствии он возобновится в том же контексте. Поскольку заблокированный таким образом процесс не успеет закончить критическую секцию, это должен сделать за него системный вызов block, чтобы другие процессы получили доступ к семафору.
Когда процесс выполняет V-операцию (освобождает ресурс), проверяется очередь ожидающих процессов и разблокируется один из них. В системном вызове unBlock можно реализовать любую дисциплину обслуживания очереди, в том числе, и такую, которая предупреждает возможность бесконечного откладывания процессов в очереди. Если разблокируется какой-либо процесс, то значение семафора так и остается нулевым, если же очередь ожидающих пуста, то значение семафора увеличивается на 1.
Укажем еще вот на какую особенность. После того, как процесс разблокирован, он включается в список готовых. Может случится так, что этот процесс будет выбран планировщиком и активизирован даже раньше, чем процесс, освободивший ресурс, закончит свою V-операцию. Поскольку разблокированный процесс восстанавливается в контексте своей P-операции, то получится, что два процесса одновременно выполняют семафорные операции. В данном случае ничего страшного в этом нет, потому что для разблокированного процесса уже снято взаимное исключение (это было сделано при его блокировании), и этот процесс после разблокирования уже не изменяет значения семафора. Запомним, однако, эту особенность, которая в других примитивах взаимного исключения может приобретать более серьезный характер.
Итак, общие свойства решения задачи взаимного исключения с помощью семафоров таковы: дисциплина либеральна по тем же соображениям, что и предыдущая; метод справедлив для любого числа процессов и процессоров; когда процесс блокируется, он не расходует процессорное время на занятое ожидание; возможность бесконечного откладывания зависит от принятой дисциплины обслуживания очереди ожидающих процессов, при дисциплине FCFS бесконечное откладывание исключается; сами семафоры (но не защищаемые ими ресурсы) представляют собой монопольно используемые ресурсы, следовательно, могут порождать тупики; для борьбы с тупиками возможно применение любого из известных нам методов, предпочтителен - иерархический; как и все методы, рассмотренные выше, семафоры требуют от программиста корректного применения "скобок", в роли которых выступают P- и V-операции.
Для решения задачи взаимного исключения достаточно двоичных семафоров. Мы, однако, описали тип поля value как целое число. В приведенном нами выше определении Дейкстры речь тоже идет о целочисленном, а не о двоичном значении. Семафор, который может принимать неотрицательные значения, большие 1, называется общим семафором. Такой семафор может быть очень удобен, например, при управлении не единичным ресурсом, а классом ресурсов. Начальное значение поля value для такого семафора устанавливается равным числу единиц ресурса в классе. Каждое выделение единицы ресурса процессу сопровождается P-операцией, уменьшающей значение семафора. Семафор, таким образом, играет роль счетчика свободных единиц ресурса. Когда этот счетчик достигнет нулевого значения, процесс, выдавший следующий запрос на ресурс, будет заблокирован в своей P-операции. Освобождение ресурса сопровождается V-операцией, которая разблокирует процесс, ожидающий ресурс, или наращивает счетчик ресурсов.
Общие семафоры могут быть использованы и для простого решения задачи синхронизации. В этом случае семафор связывается с каким-либо событием и имеет начальное значение 0. (Событие может рассматриваться как ресурс, и до наступления события этот ресурс недоступен). Процесс, ожидающий события, выполняет P-операцию и блокируется до установки семафора в 1. Процесс, сигнализирующий о событии, выполняет над семафором V-операцию. Для графа синхронизации, например, показанного на Рисунок 8.1, мы свяжем с каждым действием графа одноименный семафор. Тогда каждое действие (например, E) должно быть оформлено следующим образом: 1 procE () { 2 /*ожидание событий B и D*/ 3 P(B); P(D); 4 . . . 5 /* сигнализация о событии E для двух 6 ожидающих его действий (F и H) */ 7 V(E); V(E); 8 }
Ниже мы рассмотрим применение семафоров для более сложного варианта задачи синхронизации.
9.5. Семафоры
В предыдущей главе мы достаточно подробно рассмотрели сущность и свойства семафоров. ОС может предоставлять семафоры в распоряжение пользователя, как средство для самостоятельного решения задач, требующих взаимного исключения и/или синхронизации.
При работе с именованным семафором один из процессов должен создать системный семафор при помощи вызова createSemapore, другие процессы получают доступ к созданному системному семафору при помощи вызова openSemaphore. Среди входных параметров этих вызовов имеется внешнее имя семафора, вызовы возвращают манипулятор для семафора, используемый для его идентификации при последующей работе с ним. При окончании работы с системным семафором процесс должен выполнить вызов closeSemaphore. Семафор уничтожается, когда он закрыт во всех процессах, его использовавших.
Выполнение операций над семафором может обеспечиваться системным вызовом вида: flag = semaphoreOp(semaphorId, opCode, waitOption); где semaphorId - манипулятор семафора, opCode - код операции, waitOption - опция ожидания, flag - возвращаемое значение, признак успешного выполнения операции или код ошибки.
Помимо основных для семафоров P- и V-операций, конкретные семафорные API ОС могут включать в себя расширенные и сервисные функции, такие как безусловная установка семафора, установка семафора и ожидание его очистки, ожидание очистки семафора. При выполнении системных вызовов - аналогов P-операции, как правило, имеется возможность задать опцию ожидания - блокировать процесс, если выполнение P-операции невозможно, или завершить системный вызов с признаком ошибки.
Во многих современных ОС наряду с семафорами "в чистом виде" API представляет те же семафоры и в виде "прикладных" объектов - объектов взаимного исключения и событий. Хотя содержание этих объектов одно и то же - семафор, ОС в отношении этих объектов представляет для прикладных процессов специфическую семантику API, соответствующую задачам взаимного исключения и синхронизации.
Все современные ОС предоставляют прикладному процессу возможность работать с "массивами семафоров", то есть, задавать список семафоров и выполнять операцию над всем списком, например, ожидать очистки любого семафора в заданном списке. Наиболее развито это средство в ОС Unix, где имеется возможность выполнять за один системный вызов semop (аналог нашего semaphoreOp) сразу нескольких различных операций над несколькими семафорами, причем весь список операций выполняется, как одна транзакция.
Неименованные семафоры обычно используются как средство взаимного исключения и синхронизации работы нитей одного процесса.
Скобки критических секций
9.1. Скобки критических секций.
Выделение критических секций, как системное средство, целесообразно применять для относительно сильно связанных процессов - таких, которые разделяют большой объем данных. Кроме того, поскольку, как мы показали в предыдущей главе, при применении программистом скобок критических секций возможны ошибки, приводящие к подавлению одних процессов другими, важно, чтобы конфликты между процессами не приводили к конфликтам между пользователями. Эти свойства характерны для нитей - параллельно выполняющихся частей одного и того же процесса: они все принадлежат одному процессу - одному пользователю и разделяют почти все ресурсы этого процесса. Следовательно, критические секции целесообразно применять только для взаимного исключения нитей. ОС может предоставлять для этих целей элементарные системные вызовы, функционально аналогичные рассмотренным нами в предыдущей главе csBegin и csEnd. Когда нить входит в критическую секцию, все остальные нити этого процесса блокируются. Блокировка не затрагивает другие процессы и их нити. Естественно, что такая политика весьма консервативна и снижает уровень мультипрограммирования, но это может повлиять на эффективность только в рамках одного процесса. Программист может самостоятельно организовать и более либеральную политику доступа к разделяемым ресурсам, используя, например, семафоры, которые будут описаны ниже.
Кроме того, роль таких скобок могут играть системные вызовы типа suspend и release, первый из которых приостанавливает выполнение нити, а второй - отменяет приостановку.
Непланируемыми называются ВМ, ожидающие завершения
Рисунок 2.10. Состояния виртуальных машин в ОС VM/370

Непланируемыми называются ВМ, ожидающие завершения операции ввода-вывода на реальном внешнем устройстве или какого-либо другого внешнего события. Непланируемые ВМ исключаются из очередей планировщика. Планируемые - все остальные ВМ - могут быть активными или неактивными. Активной является ВМ, попавшая в очередь на обслуживание RUNLIST. Размер этой очереди ограничен соображениями эффективности страничного обмена. Все ВМ, не попавшие в эту очередь из -за ее ограниченности, являются неактивными. По мере разгрузки очереди RUNLIST, она пополняется из очередей неактивных ВМ. Активные ВМ, в свою очередь, подразделяются на диспетчируемые и недиспетчируемые. Диспетчируемые ВМ - это те, которые полностью готовы получить ЦП. Недиспетчируемой является ВМ, для которой: моделируется выполнение привилегированной команды; или моделируется выполнение операции ввода-вывода без связи с реальным устройством (см. главу 6); или обрабатывается страничный отказ.
Кроме этой, основной классификации, планируемые ВМ подразделяются на диалоговые, недиалоговые и чисто пакетные. Для некоторых статусов ВМ установлены следующие обозначения: Q1 - диалоговые активные; Q2 - недиалоговые активные; Q3 - пакетные активные; E1 - диалоговые неактивные; E2 - недиалоговые неактивные.
Все активные ВМ находятся в очереди RUNLIST, но статус ВМ влияет на ее положение в очереди. Для неактивных ВМ существуют две разные очереди - очередь E1 и очередь E2.
При пополнении очереди RUNLIST абсолютный приоритет имеет очередь E1, ВМ из очереди E2 переводятся в RUNLIST только, если очередь E1 пуста.
Новые ВМ (не показано на рисунке) вначале поступают в очередь RUNLIST, а при ее заполнении - в очередь E2. При попадании ВМ в очередь RUNLIST ей назначается размер кванта dt и квота обслуживания dT - интервал времени ЦП, который ВМ может использовать, планируясь из очереди RUNLIST. Начальное значение кванта устанавливается равным фиксированному значению dt0, в дальнейшем оно может быть изменено по таким правилам: квант сохраняется равным dt0, если на предыдущем кванте не было прерывания по вводу-выводу, квант назначается равным 4*dt0 в противном случае.
Квота обслуживания назначается: 8*dt для ВМ статуса Q1; 64*dt для ВМ статуса Q2; 512*dt для ВМ статуса Q3.
Таким образом, диалоговые ВМ имеют меньшие кванты, чем недиалоговые, но получают их чаще.
Очередность предоставления ЦП диспетчируемым ВМ определяется связанным с каждой ВМ приоритетным числом (чем оно меньше, тем выше приоритет ВМ). Начальное значение приоритетного числа определяется временем поступления ВМ в систему. Таким образом, та ВМ, сеанс на которой начался раньше, имеет более высокий приоритет. В дальнейшем планировщик формирует динамическую добавку к приоритетному числу, которая может его существенно изменять. Величина добавки зависит от поведения ВМ, которое мы рассмотрим, обращаясь к схеме на рисунке 2.11, где показана схема движения ВМ между ЦП и очередями планировщика.
Списки привилегий
Рисунок 10.3. Списки привилегий

Во втором случае имеется таблица объектов, с элементами которой связаны списки субъектов (Рисунок 10.4).
Списки управления доступом Дополнительные возможности
Рисунок 10.4. Списки управления доступом
Страничная модель
3.5. Страничная модель
Страничную организацию памяти легко представить как многосегментную модель с фиксированным размером сегмента. Такие сегменты называются страницами. Вся доступная реальная память разбивается на страничные кадры (page frame), причем границы кадров в реальной памяти фиксированы. Иными словами, реальная память представляется как массив страничных кадров. Виртуальный адрес состоит из номера страницы и смещения в странице, система поддерживает таблицу дескрипторов страниц для каждого процесса. Дескриптор страницы в основном подобен дескриптору сегмента, но в нем может быть сокращена разрядность поля base, так как в нем хранится не полный реальный адрес, а только номер страничного кадра, а необходимость в поле size вообще отпадает, так как размер страниц фиксирован. Проблема размещения значительно упрощается, так как любой страничный кадр подходит для размещения любой страницы, необходимо только вести учет свободных кадров. За счет этого страничная организация оказывается удобной даже при отсутствии свопинга, так как позволяет разместить непрерывное виртуальное адресное пространство в несмежных страничных кадрах. (Иногда для обозначения свопинга на уровне страниц применяют специальный термин "paging" - страничный обмен.) Внешние дыры в страничной модели отсутствуют, зато появляются внутренние дыры за счет недоиспользованных страниц. При наличии в системе свопинга нулевое значение бита present вызывает прерывание-ловушку "страничный отказ" (page falure) и подкачку страницы в реальную память. Для учета занятых/свободных страниц подходит техника битовой карты, но большинство ОС используют в качестве элементов карты (таблицы страничных кадров) не биты, а куда более сложные структуры, из которых могут составляться и многосвязные списки (в том числе и списки свободных кадров).
Какой размер страницы выгоднее - большой или малый? Соображения, которые могут повлиять на выбор размера следующие: при малых страницах получаются меньшие внутренние дыры; при малых страницах меньше вероятность страничного отказа (так как больше страниц помещаются в памяти); при больших страницах меньшие аппаратные затраты (так как разбиение памяти на большие блоки обойдется дешевле); при больших страницах меньшие заголовочные дыры и затраты на поиск и управление страницами (таблицы имеют меньший размер); при больших страницах выше эффективность обмена с внешней памятью.
Интересно, что публикации [8] и [27], приводя почти идентичные соображения по этому поводу, приходят к диаметрально противоположным выводам - о преимуществе малых [8] и больших [27] страниц. Вообще можно проследить, по большинству источников, что рекомендуемые размеры страниц растут с возрастанием года издания. По-видимому, решающим фактором здесь является вопрос стоимости памяти. Со временем стоимость этого ресурса уменьшается, а доступные объемы увеличиваются, поэтому более поздние авторы придают меньше значения потерям памяти.
Поскольку размер страницы обычно выбирается много меньшим, чем размера сегмента в предыдущей модели, страничная организация позволяет значительно увеличить уровень мультипрограммирования за счет того, что в реальную память могут в каждый момент отображаться только самые необходимые части виртуальных пространств процессов. Но при этом еще более возрастает интенсивность свопинга и, соответственно, роль стратегии вытеснения/подкачки страниц. При проектировании систем со страничным свопингом разработчики должны придерживаться двух основополагающих правил: процесс при большинстве своих обращений к памяти должен находить требуемую страницу уже в реальной памяти; если потери на свопинг превышают допустимую норму, то должен понижаться уровень мультипрограммирования.
Несоблюдение этих правил делает весьма вероятным возникновение такой ситуации, когда система будет занята только хаотичным перемещением страниц. (Например, выполнение команды процессора S/390: MVС память,память может потребовать трех страниц памяти: команды, первого и второго операндов. Если одной из страниц недостает, процесс блокируется в ожидании ее подкачки. Но при неудачной стратегии за время этого ожидания он может потерять другие необходимые страницы и повторная попытка выполнить команду вновь приведет к прерыванию-ловушке). В англоязычной литературе эту ситуацию называют trash - толкотня, в русскоязычной часто используется транскрипция - трэш.
При оценке эффективности стратегии свопинга показательной является зависимость частоты страничных отказов от числа доступных страничных кадров. Качественный вид этой зависимости, присущий всем стратегиям, показан на Рисунке 3.7. Как видно из рисунка, при уменьшении объема реальной памяти ниже некоторого ограниченного значения число страничных отказов начинает расти экспоненциально. Естественно, что показателем эффективности стратегии может служить степень близости колена этой кривой к оси ординат. Другой возможный критерий эффективности - площадь области, расположенной под этой кривой - чем она меньше, тем выше эффективность.
Стрелка от философа к палочке
Рисунок 5.1. (стрелка от философа к палочке означает, что философ хочет взять эту палочку, стрелка в обратном направлении - что эту палочку этот философ уже взял.) Каждый из философов взял палочку справа от себя, но не может взять палочку слева. Ни один из философов не может ни есть, ни думать. Эта ситуация и называется тупиком (deadlock).
Если же мы установим, что философ должен взять обе палочки сразу, то может возникнуть ситуация, показанная на
Структура драйвера
Рисунок 6.5. Структура драйвера

Как мы сказали, верхний уровень драйвера определяет очередность, в которой обслуживаются запросы от разных процессов. Для реализации политики обслуживания драйвер должен учитывать как приоритеты процессов, так и доступность устройств. Приоритетность запросов может оцениваться по разным стратегиям, из которых наиболее распространенной является та, согласно которой запрос процесса, имеющего наивысший процессорный приоритет, имеет наивысший приоритет в очереди драйвера и другие стратегии, ставящие целью повышение эффективности обмена с устройством, пример такой стратегии мы рассматриваем ниже применительно к драйверам дисковых накопителей.
Доступность устройства мы рассмотрим на примере канальной модели подключения. Путь от процессора к устройству включает в себя три "станции": канал, контроллер, устройство. Каждая из станций пути может быть свободна или занята независимо от других. На приведенной на Рисунок 6.4 древовидной структуре различные уровни этой структуры характеризуются различным временем своего участия в операции ввода-вывода. Канал участвует только в передаче данных. Например, при выводе канал может быть занятым только на время передачи из памяти в буфер контроллера, после чего канал освобождается и может обслуживать другой контроллер, а первый контроллер тем временем передает данные на устройство. После передачи данных на устройство освобождается контроллер, а устройству может потребоваться еще некоторое время, чтобы обработать полученные данные. Поэтому события освобождения канала, контроллера и устройства индицируются разными признаками в состоянии канала. В наборе команд ввода-вывода есть отдельные команды для проверки состояния устройства, контроллера и канала. Адрес устройства в схеме подключения, подобной той, что представлена на Рисунок 6.4, должен складываться из: идентификатора (номера) канала, идентификатора контроллера в канале, идентификатора устройства в контроллере. Процесс обращается к устройству по некоторому своему идентификатору - виртуальному адресу, который может быть подобен реальному, а может представлять собой и логическое имя устройства. В простейшем случае трансляция адреса устройства производится по таблице перекодировки. Возможна и более сложная структура, допускающая подключение устройства к нескольким контроллерам, а контроллера - к нескольким каналам. Реальный адрес устройства может формироваться, таким образом, динамически. В IBM System/390 эти функции переданы аппаратной подсистеме ввода-вывода.
Для принятия решений о доступности устройств ОС поддерживает таблицы дескрипторов, отражающие состояние станций пути (три таблицы - по числу типов станций). Для канала дескриптор включает в себя: идентификатор канала; состояние (занят/свободен); список контроллеров, подключенных к каналу; список запросов к каналу. Для контроллера: идентификатор контроллера; состояние; список каналов, к которым подключен контроллер; список устройств, подключенных к контроллеру; список запросов к контроллеру. Для устройства: идентификатор устройства; состояние; список контроллеров, к которым подключено устройство; список запросов к устройству.
Логически являясь частью ОС, драйверы, тем не менее оформляются как отдельные модули. Поскольку каждый драйвер однозначно связан с устройством определенного типа (а возможно, и данной модификации), то и состав набора драйверов зависит от конфигурации аппаратных средств. Кроме того, обязательно должна быть обеспечена возможность подключения к системе новых внешних устройств без внесения изменений в ОС. При модульности драйверов это достигается простым добавлением нового драйвера к системному программному обеспечению. Драйверы загружаются в память либо при загрузке системы, либо (реже) - динамически, при возникновении потребности в них. Выбор драйверов для загрузки выполняется либо по явным указаниям в процедуре инициализации ОС, либо неявно - по имеющимся таблицам конфигурации системы, либо полностью автоматически - путем опроса при загрузке всех установленных устройств, опознания их и подключения соответствующих драйверов.
Свойства ресурсов и их представление
5.1. Свойства ресурсов и их представление
Процессорное время и оперативная память являются ключевыми ресурсами любой ОС, без них не может выполняться ни один процесс. Ресурсы, которые мы рассматриваем в этой главе, являются монопольно используемыми: неперераспределяемыми и неразделяемыми. Свойство неперераспределяемости означает, что ресурс не может быть отобран у процесса во время его использования. Представьте себе, что процесс выводит платежную ведомость на принтер. Если мы в середине печати отберем у процесса ресурс-принтер и отдадим его другому процессу, то когда первый процесс вновь обретет этот ресурс, ему придется начать печать сначала. Как мы увидим дальше, неотбираемых ресурсов в системе быть не должно, поэтому уточним понятие неперераспределяемости: ресурс не может быть отобран без фатальных для процесса последствий. На том же примере печати поясним понятие неразделяемости: два процесса не могут выводить данные на один и тот же принтер одновременно. Ресурсы процессорного времени и памяти, как мы увидели выше, свойствами неперераспределяемости и неразделяемости не обладают.
К группе монопольных ресурсов относятся, прежде всего, многие устройства ввода-вывода: принтеры, магнитные ленты, каналы связи и т.п., файлы (они могут быть разделяемыми, но со значительными оговорками). Не забудем также вторичные ресурсы, порождаемые самой ОС, - системные структуры данных и коды. Так, например, при создании нового процесса необходимо занести новую запись в таблицу процессов. Эта запись также является ресурсом, причем неперераспределяемым и неразделяемым.
Ресурсы, которые мы рассматриваем, являются также повторно используемыми. Это означает, что ресурсы после их использования процессами не пропадают и не убывают, а могут быть использованы другим процессом. Альтернативу им составляют потребляемые ресурсы, которыми чаще всего могут быть входные данные и сообщения, поступающие в процесс извне.
Наши ресурсы обладают также свойствами дискретности и ограниченности. Первое означает, что ресурсы распределяются некоторыми неделимыми единицами (не может быть полтора принтера). Второе - то, что число единиц ресурса всегда небесконечно. (Процессорное время - бесконечно: его достаточно для выполнения любого процесса, и оно может дробиться планировщиком. Реальная память всегда конечна, виртуальная тоже ограничена разрядностью виртуального адреса, а непрерывность или дискретность ее зависит от принятой модели).
Мы будем называть классом ресурса пул идентичных неименованных единиц ресурса. Неименованными мы считаем их в том смысле, что процесс при запросе ресурса не указывает, какую именно единицу из пула он хочет получить, все единицы ресурса одинаковы. Все ресурсы одного класса управляются одним менеджером.
Из определений ОС (как с точки зрения разработчика, так и с точки зрения пользователя), которые мы дали в первой главе, однозначно следует, что процесс ни в коем случае не может самостоятельно завладеть ресурсом - а только через посредство ОС. Для предоставления процессам такой возможности в составе API ОС должны быть системные вызовы типа: resourceHandle = getResource(class, number [,action] ); releaseResource(resourceHandle);
Первый вызов выделяет процессу number ресурсов из класса class и возвращает манипулятор (handle) выделенного ресурса, который при всех дальнейших операциях процесса с ресурсом служит для идентификации ресурса. Манипулятор каким-то образом адресует дескриптор ресурса. В защищенных системах такой дескриптор располагается в недоступном для процесса адресном пространстве. Манипулятор обычно является номером в системной таблице или списке дескрипторов, и по нему ядро (но не процесс) выбирает требуемый дескриптор ресурса.
Второй вызов открепляет от процесса ранее выделенный ему ресурс. Возможно, форма выделения/освобождения ресурса напомнила вам знакомые операции открытия / закрытия файла - и недаром. Поскольку файлы также являются ресурсами, операции open/close являются частными случаями операций getResource/releaseResource. Как правило, в реальных API ОС нет общих операций выделения/освобождения ресурсов, но для каждого ресурса имеется своя пара операций, отличающаяся от других названием и, возможно, составом параметров.
Третий, необязательный параметр операции getResource задает действия ОС в ситуации, когда выделить ресурс невозможно (не все ОС предоставляют процессам возможности такого выбора). Во-первых (и это действие обычно выполняется по умолчанию), ОС может заблокировать процесс, выдавший запрос, до освобождения требуемого ресурса. Во-вторых, ОС может не блокировать процесс, а вернуть ему отказ - сразу или после некоторой временной выдержки (timeout), в этом случае "умный" процесс может пока заняться другой работой, которую он может выполнить и без этого ресурса, а позже повторить запрос. Как ОС должна реагировать на запрос, который вообще не может быть выполнен (требуемого объема ресурсов просто нет в системе)? По нашему убеждению, такой запрос должен приводить к аварийному завершению выдавшего его процесса. Но если ОС допускает динамическую реконфигурацию ресурсов, то запрос может быть поставлен в очередь в ожидании момента, когда ресурс будет введен в систему. Такие нереализуемые запросы могут составлять серьезную неприятность в работе ОС, так как ресурс может никогда и не быть введен. Для избежания таких запросов целесообразно иметь в составе API вызов, возвращающий общее число ресурсов данного класса. Наконец, при невозможности удовлетворить запрос ОС может потребовать от процесса освободить уже имеющиеся в его распоряжении ресурсы. Если такая возможность имеется, то она может быть очень полезна для развязки тупиков (см. ниже).
Для каждого класса ресурсов ОС должна поддерживать дескриптор класса, в который должны входить: идентификатор класса; общее число единиц в классе; число свободных единиц; таблица единиц ресурса; список процессов, ожидающих ресурс этого класса; точка входа в менеджер класса; и т.д.
Для каждой единицы ресурса имеется запись в таблице единиц, содержащая, как минимум, индикатор занятости ресурса и идентификатор процесса, которому ресурс распределен (если он не свободен).
Манипулятор ресурса каким-то образом адресует дескриптор ресурса. В защищенных системах сам дескриптор ресурса располагается в адресном пространстве, недоступном для процесса. Манипулятор представляет собой номер дескриптора в системной таблице или в системном списке дескрипторов ресурсов данного типа. При выполнении системного вызова, параметром которого является манипулятор ресурса, происходит переключение в контекст ядра, для модуля ОС, выполняющего системный вызов, таблица дескрипторов становится непосредственно доступной, и этот модуль выполняет действия над дескриптором, номер которого он получил в качестве параметра.
Информация о ресурсах, выделенных процессу, хранится также в блоке контекста процесса.
в настоящее время имеют технологии
Рисунок 7.5. Технология RAID 5

Промышленное применение в настоящее время имеют технологии RAID 0, 1 и 5. Резервное копирование и даже аппаратная избыточность позволяют уменьшить потери, но не избежать их полностью. В предыдущей главе мы упоминали о том, что все современные файловые системы используют кеширование дискового ввода-вывода, а, следовательно, в них возникает ситуация отложенной или ленивой записи (lazy write), когда данные, уже записанные процессом в файл, на самом деле находятся в буферной оперативной памяти. При сбое системы такие данные могут быть потеряны. Наиболее опасно то, что отложенной записи подвергаются не только данные, но и метаданные файловой системы - дескрипторы дисков и файлов, каталоги и т.п. При потере изменений в метаданных недоступными могут стать все данные на диске. Поэтому в тех ФС, к целостности которых предъявляются высокие требования, ведется протоколирование операций над метаданными - запись информации по повторению или откату операции над метаданными в файл протокола (log) или журнала (journal). При сбое системы восстановление или откат операций производится по журналу. Поскольку журнал также подвергается отложенной записи, периодически производится фиксация контрольной точки - принудительная запись журнала на диск. При сбое системы, таким образом, гарантируется восстановление до последней контрольной точки.
Причиной нарушения целостности может являться одновременный доступ к файлу двух и более процессов. Для предотвращения таких нарушений ОС накладывает "замки" (lock) на файлы: замок разделяемого доступа для файла, открытого для чтения, и замок монопольного доступа для файла, открытого для записи. Замок может входить в дескриптор открытого файла. Если новый замок конфликтует с замком, наложенным ранее начавшейся операцией, то новая операция должна быть заблокирована. Обычно ОС не поддерживает сложного управления синхронизацией операций, ограничиваясь замками файлов. Наиболее часто в ОС применяется, так называемая, двухфазная дисциплина, требующая, чтобы замок на файл накладывался при его открытии и снимался при его закрытии. Замыкаться могут не только файлы, но и целые диски или каталоги или наоборот - отдельные записи или байты файла. Задача обеспечения синхронизации является частным случаем задачи взаимного исключения, подробно рассматриваемой в главе 8.
Большинство ОС обеспечивает только разделение доступа к каждому отдельному файлу и восстановление целостности метаданных ФС, перепоручая управление сложными транзакциями и целостностью пользовательских данных промежуточному программному обеспечению - менеджерам транзакций (IBM CICS, MS Transaction Server и др.) и системам управления базами данных (Oracle, IBM DB2 и др.). В распоряжении процессов должны быть средства API для формирования структуры транзакций - системные вызовы или обращения к тому программному пакету, в среде которого функционирует процесс. Примером такого средства могут быть предложения языка SQL: COMMIT (фиксация) и ROLLBACK (откат).
Точка зрения пользователя
1.3. Точка зрения пользователя
| Операционные системы скрывают от пользователя детали управления оборудованием (hardware) и обеспечивают ему более удобную среду. |
Этот принцип иллюстрируется Рисунком 1.4.
Трансляция адресов Cегментностраничная модель
Рисунок 3.8. Трансляция адресов. Cегментно-страничная модель

Такой аппарат трансляции адресов поддерживается во многих современных процессорных архитектурах. Иногда алгоритм вычисления адреса состоит и из большего числа шагов. Серьезным недостатком этой модели является многоступенчатость трансляции адресов. Эта проблема решается на аппаратном уровне путем применения сверхбыстродействующей (обычно ассоциативной) памяти для хранения части таблиц.
Поскольку в модели, приведенной на Рисунок 3.8, каждый сегмент имеет собственную таблицу страниц, сами таблицы страниц могут занимать значительный объем в памяти. Простейшее решение этой проблемы представляет Windows 3.x: в системе существует единственная таблица страниц. Сегментная часть трансляции адреса имеет, таким образом, на выходе адрес в общем для всех процессов виртуальном страничном пространстве, объем которого превышает объем реальной памяти не более, чем в 4 раза. Подобное же, хотя и более гибкое и защищенное решение представляет VSE: система обеспечивает общий объем виртуальной памяти (до 2 Гбайт), который разбивается на разделы (до 12 статических и до 200 динамических), суммарный объем адресных пространств всех разделов не превышает общего объема виртуальной памяти. Простота решения, однако, может существенно сказываться на его эффективности: во-первых, из-за ограничений на размер виртуальной памяти, во-вторых, из-за необходимости выделять смежные дескрипторы в таблице страниц для страниц, смежных в виртуальной памяти. Поэтому действительно многозадачные системы применяют множественные таблицы страниц и включают память, занимаемую таблицами страниц, в страничный обмен. Вытеснение и загрузка частных таблиц страниц производится либо исключительно самой ОС (Unix), либо ОС использует для этого имеющиеся аппаратные средства (так, ОС, ориентированные на Intel-Pentium, используют каталоги страниц).
С точки зрения программиста, он имеет дело с сегментами, API управления памятью - такой же, как и в сегментной модели. Страничная часть адресации для процессов совершенно прозрачна, но зато эта часть используется ОС для эффективной организации свопинга.
Трансляция адресов Многосегментная модель Рисунок 3 6 Примерная структура дескриптора сегмента
Рисунок 3.5. Трансляция адресов. Многосегментная модель

Рисунок 3.6. Примерная структура дескриптора сегмента

Допустимое количество сегментов определяется разрядностью соответствующего поля виртуального адреса и может быть весьма большим. Либо аппаратура должна иметь специальный регистр размера таблицы дескрипторов (такой регистр есть в Intel-Pentium), либо ОС должна подготавливать для процесса таблицу максимально возможного размера, отмечая в ней дескрипторы несуществующих сегментов (например, нулевым значением поля size). Отметим, что для систем, упаковывающих номер сегмента и смещение в одно адресное число, разрядность смещения не является ограничением на длину виртуального сегмента. Виртуальный сегмент большего размера представляется в таблице двумя и более обязательно смежными дескрипторами. С точки зрения процесса он обращается к одному сегменту, задавая в нем большое смещение, на самом же деле переполнение поля смещения переносится в поле номера сегмента. Если же простая двоичная арифметика не обеспечивает модификацию номера сегмента, возможность работы с большими сегментами может поддерживаться ОС путем особой обработки прерывания-ловушки "защита памяти".
Каковы преимущества многосегментной модели памяти?
Самое первое преимущество заключается в том, что у процесса появляется возможность разместить данные, обрабатываемые различным образом, в разных сегментах своего виртуального пространства (так, в ОС Unix, например, каждый процесс имеет при начале выполнения три сегмента: кодов, данных и стека). Каждому сегменту могут быть определены свои права доступа. Поскольку обращения к памяти могут быть трех видов: чтение, запись и передача управления, то для описания прав доступа достаточно 3-битного поля Read-Write-eXecute, каждый разряд которого определяет разрешение одного из видов доступа. Аппаратные средства большинства архитектур обеспечивают контроль права доступа при трансляции адресов: поле прав доступа включается в дескриптор сегмента и, если поступивший вид обращения не разрешен, то выполняется прерывание-ловушка "нарушение доступа".
Другое важное преимущество многосегментной модели заключается в том, что процесс имеет возможность использовать виртуальное адресное пространство, размер которого больше, чем размер доступной реальной памяти. Это достигается за счет того, что не обязательно все сегменты процесса должны одновременно находиться в реальной памяти. Дескриптор каждого сегмента содержит бит present, который установлен в 1, если сегмент подкачан в оперативную память, или в 0 - если сегмент вытеснен из нее. Аппаратура трансляции адресов проверяет этот бит и при нулевом его значении выполняет прерывание-ловушку "отсутствие сегмента" (segment falure). В отличие от большинства других ловушек, которые в основном сигнализируют об ошибках, при которых дальнейшее выполнение процесса невозможно, эта не приводит к фатальным для процесса последствиям. ОС, обрабатывая это прерывание, находит образ вытесненного сегмента на внешней памяти, и подкачивает его в реальную память. Естественно, что процесс, обратившийся к вытесненному сегменту, переводится в ожидание, это ожидание может затянуться, если у ОС имеются проблемы с ресурсом реальной памяти. Когда сегмент будет подкачан, процесс перейдет в очередь готовых и будет активизирован вновь с той команды, которая вызвала прерывание-ловушку. В тех аппаратных системах, которые не обрабатывают бит присутствия в дескрипторе сегмента, можно вместо него использовать поле size: ОС должна сбрасывать это поле в 0 при вытеснении сегмента и восстанавливать при его подкачке.
Естественно, что для подкачки сегмента ОС должна знать его адрес на внешней памяти. Подавляющее большинство систем не поддерживают аппаратно поле внешнего адреса в дескрипторе сегмента. Для хранения его ОС может либо использовать поле base, либо хранить этот адрес в расширении таблицы дескрипторов, в котором для каждого сегмента хранится информация о нем, обрабатываемая только программно. В том же расширении может храниться истинное значение поля size при использовании его вместо поля present.
Очевидно, что в многосегментной модели свопинг приобретает более интенсивный характер. Следовательно, эффективность стратегий управления памятью имеет еще больший вес. Поскольку в реальной памяти размещаются сегменты разной длины, проблемы размещения остаются те же. Для многосегментной организации характерны внешние дыры, борьба с которыми ведется перемещением сегментов. Если перемещение сегментов не освобождает такого количества реальной памяти, которое требуется для удовлетворения запроса, ОС может принять решение о вытеснении какого-либо сегмента и освобождении занимаемой им реальной памяти. Некоторые системы (Unix) вытесняют из памяти какой-либо процесс целиком со всеми принадлежащими ему сегментами, но такое решение может быть эффективным только в том случае, если процессы имеют по незначительному числу сегментов каждый. Стратегии вытеснения мы подробно рассмотрим позже - в страничной модели памяти.
Отметим, что вытеснение сегмента - не обязательно долгий процесс. Если сегмент не имеет прав доступа для записи, то он содержит команды или статические инициализированные данные, копия этого сегмента уже есть на внешней памяти - в файле, содержащем загрузочный образ процесса. Поэтому вытеснение такого сегмента не сопровождается перезаписью его на внешнюю память. Даже если в сегмент и разрешена запись, то, возможно, запись еще не производилась, такой сегмент тоже незачем перезаписывать на внешнюю память. Поля used и dirty в дескрипторе сегмента используются при принятии стратегических решений о вытеснении.
Вытеснение одного или нескольких сегментов процесса еще не приводит к его блокированию. Процесс может продолжать выполняться до тех пор, пока не обратится к одному из вытесненных сегментов.
В многосегментной модели значительно увеличивается объем управляющей информации, сохраняемой в блоке контекста процесса, даже когда процесс не выполняется. Реальная память, занимаемая блоками контекста неактивных и даже полностью вытесненных процессов, не может быть отдана другим процессам. Такие участки памяти носят название заголовочных дыр. Если потери реальной памяти на заголовочные дыры оказываются недопустимо большими, то имеет смысл разбить блок контекста процесса на две части: меньшую, обязательно сохраняемую в реальной памяти, и большую, которая может быть вытеснена. В литературе [21, 30] описана ОС MULTICS, в которой для номера сегмента отводилось 18 двоичных разрядов. Таблица сегментов процесса могла быть настолько большой, что и одна она не помешалась в оперативной памяти. Для преодоления этого противоречия таблица сегментов разбивалась на страницы, которые подвергались свопингу. (ОС MULTICS была признана неудачным проектом и не получила широкого распространения, но значительно повлияла на последующие проекты ОС, прежде всего - на Unix.)
Чрезвычайно важным преимуществом многосегментной модели является возможность разделения (совместного использования) сегментов процессами. Процессы могут быть разработаны так, чтобы виртуальные пространства двух или более процессов перекрывались в каких-то областях. Процессы могут использовать общее виртуальное пространство для обмена данными. Реализация этой возможности в какой-то мере зависит от аппаратных средств. Во многих вычислительных системах процесс может работать с несколькими таблицами дескрипторов, поскольку в системе имеется несколько регистров адресов таблиц (так в процессоре Intel 80286 и последующих предусмотрены две таблицы, называемые локальной и глобальной). Решение, использующее это свойство, заключается в том, что дескриптор разделяемого сегмента помещается в общую для всех процессов (глобальную) таблицу, такой сегмент может быть доступным для всех процессов и имеет общий виртуальный номер для всех процессов. Другое решение, возможное и при наличии только одной таблицы для каждого процесса, заключается в том, что для общего сегмента создается по записи в таблице каждого процесса, с ним работающего, для каждого процесса этот сегмент имеет свой виртуальный номер. Второе решение представляется более удачным с точки зрения защиты, так как , во-первых, доступ к сегменту имеют только те процессы, в таблицах которых созданы соответствующие дескрипторы, во-вторых, есть возможность дать разным процессам разные права доступа к разделяемому сегменту. Но за такое решение приходится платить тем, что при свопинге разделяемого сегмента и при учете его использования необходимо корректировать его дескрипторы в таблицах всех процессов.
Что касается стратегии подкачки, то все ОС применяют в сегментной модели "ленивую" политику: вытесненный сегмент подкачивается в реальную память только при обращении к нему. Некоторые системы (например, OS/2) позволяют управлять начальной подкачкой сегментов при запуске процесса: сегмент может быть определен программистом как предварительно загружаемый (preload) или загружаемый по вызову (load on call). Разработать неубыточную стратегию упреждающей (до обращения) подкачки сегментов при свопинге пока не представляется возможным из-за отсутствия надежных методов предсказания того, к какому сегменту будет обращение в ближайшем будущем.
В многосегментной модели процесс имеет возможность динамически изменять структуру своего виртуального адресного пространства. Для этих целей ему должен быть доступен минимальный набор системных вызовов, приводимый ниже.
Получить сегмент: seg = getSeg (segsize, access);
ОС выделяет новый сегмент заданного размера и с заданными правами доступа и возвращает процессу виртуальный номер выделенного сегмента.
Освободить сегмент: freeSeg(seg); сегмент с заданным виртуальным номером становится недоступным для процесса.
Изменить размер сегмента: chSegSize(seg, newsize).
Изменить права доступа к сегменту: chSegAccess(seg, newaccess).
В конкретных системах этот минимальный набор может быть расширен дополнительным системным сервисом.
Системные вызовы, связанные с разделяемыми сегментами, мы рассмотрим в главе, посвященной взаимодействию между процессами.
Трехуровневая архитектура клиент/сервер
Рисунок 1.3. Трехуровневая архитектура клиент/сервер
Прогнозируется (см., например, [33]), что в ближайшие годы ПЭВМ должны будут существенно "потесниться" в роли клиента, уступив значительную часть этого ареала устройствам с ограниченными вычислительными возможностями (так называемым "тонким" клиентам), в том числе, и мобильным. Вычисления, таким образом, становятся все более сервер-центрическими, распределяясь между серверами приложений и серверами баз данных. При работе с мобильными клиентами и удаленными источниками данных получение обслуживания клиента у сервера приложений, а сервера приложений - у сервера данных может происходить и без установления непосредственной связи между клиентом и сервером, а состоять из посылки клиентом сообщения - запроса на обслуживание и получения им ответного сообщения с результатами выполнения запроса. В этом случае мы как бы возвращаемся к пакетному режиму, хотя и с иными характеристиками пакетов-заданий.
Хотя описанное нами развитие методов обработки данных происходит во времени, новый подход никогда полностью не отменяет предыдущие. В настоящее время в эксплуатации находятся вычислительные системы с самым разным объемом ресурсов и с применением самых разных методов обработки информации.
Целью настоящего издания не является исчерпывающий обзор ОС, однако в тексте мы часто будем приводить примеры организации тех или иных функций в конкретных системах. В сумме эти примеры, рассредоточенные по разным главам, могут составить не исчерпывающее, но довольно полное представление о нескольких ОС. Поэтому в приводимой ниже классификации мы дадим вводную характеристику тем ОС, которые составляют наш "банк примеров". Некоторые приводимые нами характеристики ОС, возможно, будут непонятны начинающему читателю, объяснения их вы найдете в следующих главах настоящего пособия.
Простейшим является класс однозадачных однопользовательских систем. Аппаратной платформой их является IBM PC (XT, AT), ОС - MS DOS. Поскольку ресурсы такой системы весьма ограничены, ее рассмотрение не представляет для целей данного пособия существенного интереса.
Класс многозадачных однопользовательских систем начинается с тандема MS DOS + Windows, но настоящими ОС этого класса являются OS/2 и Windows 9x. Эти ОС работают на аппаратной платформе не ниже процессора Intel 80386, ресурсы, поддерживаемые такими ОС, - более мощные, управление ими усложняется. Вместе с тем, в функции системы не входит защита ресурсов от других пользователей: в однопользовательской системе "украсть" ресурсы можно только у самого себя.
Windows 1.x - 3.x представляет собой надстройку над MS DOS, обеспечивающую управление виртуальной памятью (сегментную или сегментно-страничную - в зависимости от процессора - модель) и кооперативную многозадачность.
Операционные системы OS/2 и Windows 95/98/ME - системы многозадачные, однопользовательские.(Хотя OS/2 позиционируется на рынке как серверная система, ядро ее продолжает оставаться однопользовательским.) Они обеспечивают вытесняющую многозадачность и работу с нитями, а также богатый набор средств взаимодействия процессов. В них используется 32-разрядная (плоская) модель памяти
Многозадачные многопользовательские системы в настоящее время эксплуатируются на ЭВМ, работающих в многопользовательском интерактивном режиме или выполняющих функции серверов в сетях, их современные аппаратные платформы - на базе серверов Intel-Pentium и RISC-процессоров. Управление ресурсами здесь усложняется не только из-за простого возрастания их объема, но и из-за изменения задач. Система исходит из "презумпции нечестности" пользователей - предположения о том, что любой процесс будет стремиться захватить как можно больше ресурсов в ущерб процессам других пользователей. ОС должна обеспечить справедливое распределение ресурсов между пользователями и их учет (возможно, для оплаты). Важной составляющей таких ОС является также обеспечение безопасности: защита программ и данных пользователя от их чтения или изменения или уничтожения другими пользователями.
Первым примером ОС такого класса, естественно, должна быть названа ОС Unix, которая существует и развивается с 1968г. ОС Unix оказала огромное влияние на развитие концепций построения ОС, породила множество клонов (BSD Unix, Solaris, AIX, Linux и т.д.) и является основой стандартов для ОС.
Windows NT (начиная с версии 5 - Windows 2000) является полностью 32-разрядной ОС с объектно-ориентированной структурой и строится на базе микроядра.
Семейство вычислительных систем AS/400 является результатом длительного эволюционного развития, начавшегося с IBM System/38 (1978г.). По ряду идей и решений эволюционный ряд System/38 - AS/400 является лидером в развитии ОС. Среди особенностей, делающих эту систему интересным примером для нас, следует назвать: объектно-ориентированную ее структуру и архитектуру на базе микроядра, одноуровневую модель памяти, мощные средства защиты. Системное программное обеспечение AS/400 двухуровневое: нижний уровень выполняется Лицензионным Внутренним Кодом (LIC - Licensed Internal Code) и обеспечивает аппаратную независимость верхнего уровня, который составляет собственно ОС OS/400. AS/400 отличается значительной степенью системной интеграции и высоким уровнем системных интерфейсов.
Наконец, последний рассматриваемый нами класс - гигаресурсные (термин введен нами) системы. Являясь также многозадачными и многопользовательскими, они отличаются от предыдущего класса тем, что ресурсы, управляемые ими, на несколько порядков большие. Их аппаратной платформой являются мейнфреймы System/390 или ESA (Enterprise System Architecture) фирмы IBM, представляющие собой эволюционное развитие ряда System/360 - System/370. Современные мейнфреймы отличаются большим объемом возможностей, реализованных на аппаратном уровне, таких как мультипроцессорная обработка, средства создания системных комплексов, объединяющих несколько мейнфреймов, средства логического разделения ресурсов вычислительной системы, высокоэффективная архитектура каналов ввода-вывода, и т.д. Современные ОС ESA - VSE/ESA, VM/ESA, OS/390 представляют собой развитие работавших на System/360, System/370. VSE/ESA ориентирована на использование в конечных и промежуточных узлах сетей. Она функционирует на наименее мощных моделях мейнфреймов. VSE эффективно выполняет пакетную обработку и обработку транзакций в реальном времени. VM/ESA - гибкая интерактивная ОС, поддерживающая одновременное функционирование нескольких "гостевых" ОС на одной вычислительной системе. OS/390 (в последней версии - z/OS) - основная ОС для применения на наиболее мощных аппаратных средствах. Она обеспечивает наиболее эффективное управление ресурсами при пакетном и интерактивном режимах и обработке в реальном времени, возможно совмещение любых режимов. Обеспечивает также комплексирование вычислительных систем, динамическую реконфигурацию ввода-вывода, расширенные средства управления производительностью.
Управление устройствами
6.3. Управление устройствами
Внешние устройства ЭВМ отличаются большим разнообразием в форматах управляющей информации и в алгоритмах управления. Даже в канальной модели интерфейса разные устройства имеют разные модификации команд чтения/записи/управления, не говоря уже о том, что транзакция на устройстве обычно подразумевает выполнение нескольких команд, и последовательности их бывают совершенно различными для разных устройств.
Модули ОС, которые осуществляют трансляцию однотипных для всех устройств обращений к ним из процессов и из других модулей ОС в специфические для устройства управляющие воздействия и управляют выполнением этих воздействий, называются драйверами. (Мы не согласны с теми авторами, которые называют драйверами любые программы управления вводом-выводом, драйверы в нашем понимании обязательно включаются в состав ОС и обязательно соответствуют спецификациям данной ОС.) Каждому типу устройства соответствует свой драйвер. Драйвер устройства имеет два основных уровня, как показано на Рисунок 6.5. Первый (верхний) уровень принимает системные вызовы от процессов и формирует на основании каждого вызова запрос. Этот же уровень выстраивает запросы в очередь и поддерживает упорядоченность этой очереди в соответствии с принятой дисциплиной обслуживания. Второй (нижний) уровень драйвера выбирает из очереди первый запрос и обслуживает его: формирует управляющие воздействия и передает их на устройство, обрабатывает прерывания от устройства и сообщает ядру ОС о наступлении событий, связанных с вводом-выводом.
Уровни обработки и модели клиент/серверных вычислений
Рисунок 1.2. Уровни обработки и модели клиент/серверных вычислений
В персональных вычислительных системах, построенных по персональной идеологии, все три функции в полной мере сосредоточены на одном компьютере. При построении неперсональных систем выполняется перераспределение функций между компьютерами в сети. Распределение функций манипулирования данными между клиентом и сервером может быть различным. Различные варианты распределения функций между сервером и клиентами образуют различные варианты архитектуры клиент/сервер (см.Рисунок 1.2): если сервер выполняет только хранение данных и при необходимости вся единица хранения данных (файл) пересылается клиенту, и всю дальнейшую работу с данными выполняет клиент, то это вариант файлового сервера;. если на сервер возлагается выполнение одной из самых трудоемких функций логики приложения - выборки необходимых для обработки данных то это вариант вариант сервера данных; если вся логика приложений (или блдьшая ее часть) выполняется на сервере, а в клиентскую часть передаются лишь результаты обработки, то это вариант сервера приложений.
В любом из этих вариантов клиентские ОС работают в интерактивном режиме, обслуживая пользователей-операторов, а ОС сервера - тоже в интерактивном режиме, но пользователями для нее являются приложения-клиенты. Отличия режима клиент/сервер от обычного интерактивного скорее количественные, чем качественные: ОС сервера выполняет несколько более длинные последовательности процессорных команд без обращения к операциям ввода-вывода и несколько реже получает внешние прерывания. Поэтому дисциплины управления ресурсами в интерактивных и клиент/сервер ОС различаются не структурами алгоритмов, а их параметрами.
Сходные задачи стоят и перед системами реального времени, как правило, работающими в непосредственной связи (on-line) с объектом управления и выполняющими некоторые операции по управлению либо периодически, либо по требованию. Но в отличие от интерактивных или клиент/серверных ОС, для систем реального времени основной целью является обеспечение гарантированного времени ответа, ни в коем случае не превышающего некоторого критического значения.
Наконец, современная (и перспективная) модель вычислений предполагает выделение разнесение всех трех уровней клиент-серверной архитектуры - клиент, сервер приложений, сервер данных - по разным ЭВМ. Функции клиента сводятся к презентации информации для конечного пользователя. Сервер приложений обеспечивает разнообразные вычислительные возможности. Сервер данных - прежде всего хранение и выборку данных, хотя может выполнять и значительную часть их обработки. В условиях развития глобальных коммуникаций каждый клиент может получать обслуживание от многих серверов приложений, а каждый сервер приложений - получать данные из многих источников, как показано на Рисунок 1.3.
Установка межмодульных связей при динамической компоновке
Рисунок 4.1. Установка межмодульных связей при динамической компоновке

При совместном использовании процедур, входящих в состав модулей DLL, несколькими процессами все процессы используют один и тот же экземпляр кода DLL, но для каждого использования создается отдельный стек, таким образом, для каждого использования имеется свой набор экземпляров локальных переменных процедуры.
Динамическая компоновка при загрузке совершенно прозрачна для программы. При подготовке программных и DLL-файлов требуются специальные директивы для компоновщика, но в самом тексте программы обращения к динамически подключаемым процедурам ничем не отличаются от обращений к процедурам, подключенным статически. В современных ОС динамически подключаемые библиотеки широко используются для системного программного обеспечения. API ОС, средства работы с терминалом, графические средства и т.п. представляют собой библиотеки динамической компоновки, совместно используемые всеми программами. При загрузке любой программы эти модули, как правило, уже находятся в памяти.
Динамическая компоновка несколько ухудшает быстродействие программы: во-первых, расходуется время на установление связей при загрузке или при выполнении, во-вторых, при уже установленных связях обращение производится через посредство таблицы внешних ссылок. Преимущества же динамической компоновки бесспорны: во-первых, достигается экономия оперативной памяти за счет совместного использования модулей, во-вторых, достигается экономия внешней памяти за счет уменьшения объема загрузочных модулей, в-третьих, создается возможность модификации и полной замены модулей динамической компоновки без изменения двоичного кода главной программы.
Динамическая компоновка на этапе выполнения дает возможность программе самой управлять порядком загрузки модулей и установки связей. Программа может, например, менять загруженный в память набор модулей в разных фазах своего выполнения или использовать разные модули в зависимости от конфигурации вычислительной системы или условий выполнения и т.п. Для обеспечения таких возможностей ОС должна предоставлять в распоряжение программиста соответствующий набор системных вызовов. Этот набор может быть следующим.
Системный вызов: mod_handle = loadModule (mod_name); загружает модуль из файла с указанным именем. Если указанного модуля нет в памяти, ОС производит загрузку его из файла, если же модуль в памяти уже есть, ОС просто увеличивает на 1 счетчик использований этого модуля. Вызов должен возвращать манипулятор модуля, используемый для его идентификации во всех последующих операциях с ним.
Возможна модификация этого вызова: mod_handle = getModuleHandle (mod_name); получить манипулятор модуля: если модуль уже есть в памяти, вызов возвращает его манипулятор (и увеличивает счетчик использований), если нет - возвращает признак ошибки. В последнем случае программа может либо загрузить модуль вызовом loadModule, либо перейти на такую свою ветвь, которая не предусматривает обращений к данному модулю.
Системный вызов: freeModule (mod_handle); выгружает модуль. ОС уменьшает на 1 счетчик использования модуля, если этот счетчик обратился в 0, освобождает память.
Системный вызов: vaddr = getProcAddress (mod_handle, proc_name); возвращает виртуальный адрес процедуры с заданным именем в уже загруженном модуле. Все дальнейшие обращения к данной процедуре программа производит по этому адресу.
Вариант 1 общая переменная исключения
Вариант 1: общая переменная исключения.
Введем булевскую переменную mutEx, которая должна получать значение true (1), если вхождение в критическую секцию запрещено, или false (0), если вхождение разрешено. Попытка организовать "скобки критической секции" представлена следующим программным кодом: 1 static char mutEx = 0; 2 void csBegin ( void ) { 3 while ( mutEx ); 4 mutEx = 1; 5 } 6 void csEnd ( void ) { 7 mutEx = 0; 8 }
При вхождении в функцию csBegin процесс попадает в цикл ожидания (строка 3), в котором находится до тех пор, пока состояние переменной исключения не разрешит ему войти в критическую секцию. Выйдя из этого цикла, процесс устанавливает эту переменную в 1, запрещая тем самым другим процессам входить в их критические секции. Процесс, который выполнялся в критической секции, при выходе из последней сбрасывает переменную исключения в 0, разрешая этим другим процессам входить в их критические секции.
Это решение базируется на непрерываемости доступа к памяти - к переменной mutEx, но оно является НЕПРАВИЛЬНЫМ. Рассмотрим такой случай. Пусть процесс A вошел в свою критическую секцию и установил mutEx=1. Пока процесс A выполняется внутри своей критической секции, два других процесса - B и C также подошли к своим критическим секциям и обратились к функции csBegin. Поскольку переменная mutEx установлена в 1, процессы B и C зацикливаются в строке 3 кода функции csBegin. Когда процесс A выйдет из своей критической секции и установит mutEx=0, другой процесс, например B, выйдет из цикла строки 3, но имеется вероятность того, что прежде, чем процесс B успеет выполнить строку 4 кода и этим запретить вход в критическую секцию другим процессам, выйдет из цикла строки 3 и процесс C. Таким образом, два процесса - B и C входят в критическую секцию, задача взаимного исключения не выполняется.
Хотя это решение и не выполняет взаимного исключения, оно может быть приемлемо для решения некоторых частных задач. Например, граф синхронизации, представленный на
Вариант 2 переменнаяпереключатель
Вариант 2: переменная-переключатель
Введем общую переменную right, значением ее будет номер процесса, который имеет право входить в критическую секцию. Реализация "скобок критической секции" для двух процессов с номерами 0 и будет следующей: 1 static int right = 0; 2 void csBegin ( int proc ) { 3 while ( right != proc ); 4 } 5 void csEnd( int proc ) { 6 if ( proc == 0) right = 1; 7 else right = 0; 8 }
Процесс, вызвавший функцию csBegin, зацикливается до тех пор, пока не получит права на вход. Разрешение входа производится другим процессом при выходе его из своей критической секции.
Данный алгоритм обеспечивает разделение процессов 0 и 1. Два процесса могут одновременно войти в функцию csBegin, но при этом они только читают переменную right. Одновременное вхождение двух процессов в функцию csEnd невозможно. При обобщении алгоритма на большее число процессов первый процесс переключает право на второй, второй - на третий и т.д., последний - на первый. Если процессы используют разные группы разделяемых данных, то каждая группа может быть защищена своим переключателем, таким образом, не запрещается одновременный доступ к разным разделяемым данным. Это делает политику более либеральной, но при наличии двух и более групп разделяемых данных возможно возникновение тупика, так как группа разделяемых данных - тот же монопольный ресурс. Для предотвращения тупика возможно введение иерархии ресурсов, как было описано в главе 5.
Существенный недостаток этого алгоритма - в том, что он жестко определяет порядок, в котором процессы входят в критическую секцию. В нашем примере для двух процессов процессы 0 и 1 могут входить в нее только поочередно. Если предположить, что скорости процессов существенно разные, например, процессу 0 требуется вдвое чаще входить в критическую секцию, чем процессу 1, то частота вхождения процесса 0 снизится до частоты процесса 1, причем, снижение скорости процесса 0 будет обеспечиваться за счет занятого ожидания в строке 3. Таким образом, не выполняется пункт 3 условия правильности решения: если один из процессов остановится вне своей критической секции, то он заблокирует все остальные процессы.
Вариант 3 неальтернативные переключатели
Вариант 3: неальтернативные переключатели.
Введем для каждого процесса свою переменную, отражающую его нахождение в критической секции. Эти переменные сведены у нас в массив inside. Элемент массива inside[i] имеет значение 1, если i-й процесс находится в критической секции, и 0 - в противном случае.
Для примеров этого варианта введем функцию, определяющую номер процесса-конкурента: int other (int proc ) { if ( proc == 0 ) return 1; else return 0; }
Первое решение в этом варианте: 1 static char inside[2] = { 0,0 }; 2 void csBegin ( int proc ) { 3 int competitor; /* конкурент */ 4 competitor = other ( proc ); 5 while ( inside[competitor] ); 6 inside[proc] = 1; 7 } 8 void csEnd (int proc ) { 9 inside[proc] = 0; 10 }
Здесь и во всех последующих решениях параметр proc функций csBegin и csEnd - номер процесса, желающего войти в свою критическую секцию или выйти из нее.
Процесс находится в занятом ожидании (строка 5) до тех пор, пока его конкурент находится в своей критической секции. Когда конкурент снимает свой признак пребывания в критической секции, наш процесс устанавливает свой признак (строка 6) и, таким образом, запрещает вход в секцию конкуренту.
Решение, однако, не гарантирует взаимного исключения. Возможен случай, когда два процесса одновременно выполнят каждый строку 5 своего кода и, следовательно, войдут в свои критические секции одновременно.
В следующем решении мы меняем местами установку своего признака входа и проверку признака конкурента: 1 static char inside[2] = { 0,0 }; 2 void csBegin ( int proc ) { 3 int competitor; 4 competitor = other ( proc ); 5 inside[proc] = 1; 6 while ( inside[competitor] ); 7 } 8 void csEnd (int proc ) { 9 inside[proc] = 0; 10 }
Теперь процессы не могут одновременно войти в критические секции. Но возникает другая опасность: если процессы одновременно выполнят строку 5, то они заблокируют друг друга - оба процесса уже установят свои признаки, но будут зациклены в занятом ожидании, выйти из которого им не разрешит установленный признак конкурента.
Новое решение: 1 static char inside[2] = { 0,0 }; 2 void csBegin ( int proc ) { 3 int competitor; 4 competitor = other ( proc ); 5 do { 6 inside[proc] = 1; 7 if ( inside[competitor] ) inside[proc] = 0; 8 } while ( ! inside[proc] ); 9 } 10 void csEnd (int proc ) { 11 inside[proc] = 0; 12 }
Процесс устанавливает свой признак вхождения (строка 6). Но если он обнаруживает, что признак вхождения конкурента тоже установлен (строка 7), то он свой признак сбрасывает. Эти действия будут повторяться до тех пор, пока наш процесс не сохранит свой признак взведенным (строка 8), а это возможно только в том случае, если признак конкурента сброшен.
Это решение не может быть принято вот по какой причине. Возможно такое соотношение скоростей процессов, при котором они будут одновременно выполнять строку 7 - и одновременно сбрасывать свои признаки. Такая "чрезмерная уступчивость" процессов приведет к бесконечному откладыванию решения о входе в критическую секцию.
Виртуализация устройств и структура драйвера
6.1. Виртуализация устройств и структура драйвера
Управление вводом-выводом в полной мере воплощает в себе определение "ОС снаружи": ОС конструирует ресурсы высокого уровня - виртуальные устройства - и предоставляет пользователю интерфейс для работы с ними. Программисты, начинавшие работу в среде MS DOS, привыкли к доступности средств прямого управления вводом-выводом для любой программы, но в многозадачных ОС о такой доступности для прикладной программы может идти речь только в исключительных случаях, а в многопользовательских ОС она исключается вообще.
Можно в общем случае определить четыре метода, которые могут использоваться ОС для конструирования виртуальных устройств (виртуализации): метод закрепления или выделения (allocation); метод разделения (sharing); метод накопления или спулинга (spooling); метод моделирования (simulation).
Одна и та же ОС может использовать разные методы виртуализации для разных устройств.
Метод закрепления однозначно отображает виртуальное устройство на реальное устройство. Метод закрепления наименее эффективен, так как закрепляемое устройство является монопольно используемым ресурсом и применение этого метода порождает все проблемы, связанные с использованием таких ресурсов.
Метод разделения применим к устройством, ресурс которых является делимым. В этом случае ресурс устройства разбивается на части, каждая из которых закрепляется за одним процессом. Примером применения метода могут служить минидиски в ОС VM/370 [19]: все пространство диска разбивается на участки, каждый из которых выглядит для процесса как отдельный том. Можно, например, разделять между процессами и экран видеотерминала. Зафиксированная часть устройства является также монопольным ресурсом, и разделение лишь частично снимает остроту проблем управления таким ресурсом. Возможность дробления устройства предполагает внутреннюю адресацию в устройстве (адрес на диске, адрес в видеопамяти). По аналогии с адресацией в памяти, процесс и здесь работает с виртуальными адресами в виртуальном устройстве, а ОС транслирует их в реальные адреса в реальном устройстве.
Метод спулинга заставляет процесс обмениваться данными не с реальным устройством, а с некоторой буферной областью в памяти (оперативной или внешней). Обмен же данными между буфером и реальным устройством организует сама ОС, причем, как правило, с упреждением (при вводе) или с запаздыванием (при выводе). Буферизация прозрачна для процессов и может создавать у них иллюзию одновременного использования устройства - если каждому процессу выделен свой буфер. Примером могут служить спулинг печати, применяемый во всех современных ОС.
Метод моделирования не связан с реальными устройствами вообще. Устройство моделируется ОС чисто программными методами. Естественным применением этого метода является отработка приемов работы с устройствами, отсутствующими в конфигурации данной вычислительной системы. Часто ОС удобно представлять некоторые свои ресурсы как метафоры (подобия) устройств - это также моделируемые устройства. Так, в VM/ESA обмен данными между виртуальными машинами ведется через виртуальный адаптер, метафорой устройства можно также считать межпрограммный канал (pipe), реализованный во многих современных ОС.
При любом методе виртуализации ОС является "прослойкой" между процессами и реальными устройствами. Эту функцию выполняют входящие в состав ОС драйверы устройств. К драйверам обращаются и другие модули ОС, и процессы пользователя, причем последние, как правило, не непосредственно, а через библиотеки вызовов, предоставляющие более удобный API. В некоторых случаях ОС может предоставить пользователю интерфейс, обладающий высокой степенью подобия с интерфейсом реального устройства, но и в этом случае ОС, даже применяя метод выделения, производит обработку управляющих воздействий, сформированных процессом: проверку правильности команд, трансляцию адресов памяти, адресов устройств и адресов в устройствах и т.п.
Виртуальная и реальная память
3.1. Виртуальная и реальная память
Мультипрограммирование будет эффективным только в том случае, когда несколько процессов одновременно находятся в оперативной памяти, тогда переключение процессов не требует значительного перемещения данных между оперативной и внешней памятью. Но тогда на ОС возлагается задача распределения оперативной памяти между процессами и защиты памяти, которая выделена процессу, от вмешательства другого процесса. Таким образом, память является одним из важнейших ресурсов системы, и от эффективности функционирования менеджера этого ресурса в значительной степени зависят показатели эффективности всей системы в целом.
Процессор обрабатывает данные, которые находятся в оперативной памяти, и процессы размещают свои коды и данные в адресном пространстве, которое они рассматривают, как пространство оперативной памяти. В очень редких случаях программист задает при разработке программы реальные адреса в оперативной памяти, в большинстве же случаев между программистом и средой выполнения его программы стоит тот или иной аппарат преобразования адресов. В общем случае то адресное пространство, в котором пишется программа, называется виртуальною памятью, в отличие от реальной или физической памяти - в которой происходит выполнение программы (процесса). Работу с памятью можно представить в виде трех функций преобразования, которые показаны на Рисунке 3.1.
Виртуальные прерывания или сигналы
9.2. Виртуальные прерывания или сигналы
Мы уже говорили о виртуальных прерываниях, как о средстве, при помощи которого ОС сигнализирует процессу об окончании асинхронно выполняемой операции ввода-вывода. Расширяя эту концепцию, можно применять виртуальные прерывания для сообщения процессу о любом внешнем по отношению к нему событии. В частности, виртуальное прерывание может использоваться для того, чтобы выдавать синхронизирующий сигнал из одного процесса в другой. ОС может предоставлять в распоряжение процессов системный вызов: raiseInterrupt (pid, intType );
где pid - идентификатор процесса, которому посылается прерывание, intType - тип (возможно, номер) прерывания. Идентификатор процесса - это не внешнее его имя, а манипулятор, устанавливаемый для каждого запуска процесса ОС. Для того, чтобы процесс мог послать сигнал другому процессу, процесс-отправитель должен знать идентификатор процесса-получателя, то есть, находиться с ним в достаточно "конфиденциальных" отношениях. Чтобы предотвратить возможность посылки непредусмотренных прерываний, могут быть введены дополнительные ограничения: разрешить посылку прерываний только от процессов-предков к потомкам или ограничить обмен прерываниями только процессами одного и того же пользователя.
Когда процессу посылается прерывание, управление передается на обработчик этого прерывания в составе процесса. Процесс должен установить адрес обработчика при помощи системного вызова типа: setInterruptHandler (intType, action, procedure ); где action - вид реакции на прерывание. Вид реакции может задаваться из перечня стандартных, в число которых могут входить: реакция по умолчанию, игнорировать прерывание, восстановить прежнюю установку или установить в качестве обработчика прерывания процедуру procedure, адрес которой является параметром системного вызова.
Разумеется, в системе должны быть определены допустимые типы виртуальных прерываний. Виртуальные прерывания могут генерироваться в следующих случаях: завершение или другое изменение статуса процесса-потомка; программные ошибки (прерывания-ловушки); ошибки в выполнении системных вызовов или неправильные обращения к системным вызовам; терминальные воздействия (например, нажатие клавиши "Внимание" или Ctrl+Break); при необходимости завершения процесса (системный вызов kill); сигнал от таймера; сигналы, которыми процессы обмениваются друг с другом; и т.д.
Если процесс получает прерывание, для которого он не установил обработчик, то процесс должен аварийно завершиться (это - устанавливаемый по умолчанию вид реакции на прерывание). Такая установка может показаться чрезмерно жесткой, но вспомните, например, какова будет реакция системы на реальное прерывание, для которого не определен его обработчик (вектор прерывания в Intel-Pentium).
Еще одно решение, которое должен принять конструктор ОС, - является ли установка обработчика постоянной (до ее явной отмены) или одноразовой (для обработки только одного прерывания). Второй вариант является более гибким, так как каждая процедура обработки прерывания может при необходимости заканчиваться новым системным вызовом setInterruptHandler, которым будет задана установка на обработку следующего прерывания этого типа. Это решение можно также переложить на программиста, включив соответствующий параметр в спецификации системного вызова.
Как должна реагировать ОС на посылку прерывания несуществующему процессу? По-видимому, аварийное завершение процесса, выдавшего такое прерывание, может быть нормальной реакцией системы. Возможно, впрочем, и более либеральное решение - завершить вызов raiseInterrupt с признаком ошибки. Аналогичный эффект может вызвать выполнение прерывания, для которого в процессе-приемнике установлен специальный режим обработки - недопустимое прерывание.
Как и для реальных прерываний, процесс должен иметь средства запрещения виртуальных прерываний (например, при вхождении в критическую секцию) - всех или выборочно по типам. Для этих целей должны использоваться специальные системные вызовы. Если прерывание запрещено, то его обработка откладывается до разрешения прерываний. Когда обработка разрешается, обработка выполняется по тому виду реакции, который установлен на момент выполнения (он может отличаться от установленного на момент выдачи прерывания). Среди зарезервированных за ОС типов прерываний обязательно должны быть такие, запретить которые или переопределить обработку которых процесс не имеет возможности - обязательно в этом списке должно быть прерывание kill.
В большинстве современных ОС (Unix, OS/2 и др.) виртуальные прерывания носят название сигналов и используются прежде всего для сигнализации о чрезвычайных событиях. Сигнальные системы конкретных ОС, как правило, не предоставляют в составе API универсального вызова типа raiseInterrupt, который позволял бы пользователю выдавать сигналы любого типа. Набор зарезервированных типов сигналов ограничен (в Unix, например, их 19, а в OS/2 - всего 7), не все из них доступны процессам, и для каждого из доступных имеется собственный системный вызов. Недопустимы также незарезервированные типы сигналов. В набор включается несколько (по 3 - в упомянутых ОС) типов сигналов, зарезервированных за процессами, эти типы и используют взаимодействующие процессы для посылки друг другу сигналов, которые они интерпретируют по предварительной договоренности.
В момент, когда для процесса генерируется виртуальное прерывание, процесс, возможно (в однопроцессорной системе - наверняка), пребывает в неактивном состоянии. Поэтому обработка прерывания откладывается до момента активизации процесса (в порядке очереди к планировщику), а прерывание запоминается в блоке контекста процесса. Как должно обрабатываться виртуальное прерывание, если во время его поступления процесс выполняет системный вызов? Выполнение системного вызова включает в себя как фрагменты кода, выполняемые в привилегированном режиме, так и фрагменты, выполняемые в режиме задачи. Очевидно, что привилегированные фрагменты прерываться не могут - их выполнение может быть связано с изменениями системных структур данных, которые должны выполняться транзакционно (то есть, не должны прерываться). В этом случае пришедшее виртуальное прерывание запоминается в блоке контекста процесса и обрабатываться при переходе процесса из состояния ядра в состояние задачи. Но системный вызов может содержать и непривилегированную часть, к тому же выполняющуюся весьма длительно (например, ввод с клавиатуры с ожиданием). Разумным решением будет разрешение прерывать такой системный вызов, но в этом случае выполнение прерванного системного вызова может заканчиваться с ошибкой, - и процесс должен быть готов к этому.
Взаимное исключение через общие переменные
8.3. Взаимное исключение через общие переменные
Следующая группа решений базируется на непрерываемости памяти. Представляя эти алгоритмы, мы в основном следуем первоисточнику [7] и приводим в качестве примеров как правильные, так и неправильные или неудачные варианты решений.
Почти все примеры мы даем для двух процессов с номерами 0 и 1, их нетрудно обобщить на произвольное число процессов.
Взаимное исключение запретом прерываний
Большинство компьютерных архитектур предусматривает в составе своей системы команд команды запрета прерываний (иногда - селективного запрета). В микропроцессорах Intel-Pentium, например, такими командами являются CLI (запретить прерывания) и STI (разрешить прерывания). Такие команды и могут составить "скобки критической секции": запрет прерываний при входе в критическую секцию и разрешение - при выходе из нее. Поскольку вытеснение процесса возможно только по прерыванию, процесс, находящийся в критической секции, не может быть прерван. Этот метод, однако, обладает большим числом недостатков: пока процесс находится в критической секции, не могут быть обработаны никакие внешние события, в том числе, и события, требующие обработки в реальном времени; исключаются не только конфликтующие критические секции, которые могут обращаться к разделяемым данным, но и все другие процессы вообще, дисциплина, таким образом, является весьма консервативной; процесс, находящийся внутри критической секции, не может перейти в ожидание (кроме занятого ожидания), так как механизм ожидания обеспечивается прерываниями; программист должен быть весьма внимателен к тому, чтобы все возможные варианты выхода из критической секции обеспечивались разрешением прерываний; вложение критических секций невозможно; обеспечение критической секции запретом прерываний базируется на аппаратной атомарности команд, оно неприменимо в мультипроцессорных системах с реальной параллельностью, так как программа, выполняющаяся на одном процессоре не может запретить прерывания другого процессора.
WIMPинтерфейс
11.4. WIMP-интерфейс
Интерфейс командной строки (но не командные файлы!) на сегодняшний день уже можно считать отходящим в прошлое, хотя прогнозировать его окончательный уход мы не беремся. Программируемые видеотерминалы дают возможность выводить информацию в любую позицию экрана и, следовательно, использовать все пространство экрана для организации взаимодействия между ОС и пользователем. Современные интерфейсы как приложений, так и ОС можно охарактеризовать как полноэкранные, графические, объекно-ориентированные.
Полноэкранный интерфейс строится на основе принципа согласованности, который состоит в том, что у пользователя формируется система ожидания одинаковых реакций на одинаковые действия. Основными компонентами интерфейса являются панели, диалоги и окна.
Панель - это информация, определенным образом сгруппированная и расположенная на экране. Основные типы панелей: меню - содержит один или более списков объектов, представляющих группы действий, доступных пользователю; панель ввода - отображает поля, в которые пользователь вводит информацию; информационная панель - отображает защищенную информацию (данные, сообщения, справки); списковая панель - содержит один или более списков объектов, из которых пользователь выбирает один или несколько и запрашивает одно или несколько действий над ними; панель-канва - свободное пространство, на котором можно размещать другие объекты интерфейса, такие как: кнопки различных видов и различной функциональности; элементы выбора; статические текстовые поля; протяжки; другие панели и т.д.
Диалог - это последовательность запросов между пользователем и компьютером: запрос пользователем действия, реакция и запрос компьютера, ответное действие пользователя и т.д. Диалог включает в себя запросы и навигацию - переходы из одной панели в другую. Информация, вводимая пользователем в ходе диалога, может удерживаться только на уровне данной панели или сохраняться.
Панели могут располагаться в отдельных ограниченных частях экрана, называемых окнами. Окна могут быть трех типов: первичное - окно, в котором начинается диалог; вторичные - вызываемые из первичного окна, в которых диалог ведется параллельно диалогу в первичном окне; всплывающие (pop-up) - расширяющие диалог в первичном или вторичном окне; перед тем, как продолжить диалог с окном, пользователь должен завершить работу со связанным с ним всплывающим окном.
Общие принципы панельного интерфейса в основном не зависят от типа применяемых терминалов. Однако, сочетание графических видеоадаптеров с высокой разрешающей способностью с общим увеличением вычислительной мощности (быстродействие и объем памяти) персональных вычислительных систем позволяет существенно изменить общий облик экрана. Можно определить следующие основные направления этих изменений: многооконность, целеуказание, иконика. Такие интерфейсы получили название WIMP (Windows, Icons, Menus, Pointer). Первое воплощение идеи WIMP нашли в разработках фирмы Xerox, а первая их коммерчески успешная реализация состоялась в компьютерах Apple Macintosh в 1985 году. Позднее идеи WIMP были приняты в Microsoft Windows, а сейчас они воплощены практически в всех операционных системах.
Интерфейс WIMP обладает концептуальной целостностью, достигаемой принятием знакомой идеальной модели - метафоры рабочего стола - ровной поверхности, на которой расположены объекты и папки, и ее тщательного, последовательного развития для использования воплощения в компьютерной графике. Главное изменение в облике интерфейса - иконика - представление объектов в виде миниатюрных графических изображений - пиктограмм. Помимо чисто внешних изменений иконика породила возможность манипулировать объектами через манипулирование их изображениями. Документы, папки и мусорная корзина являются точными аналогами предметов на столе. Вырезание, копирование и вставка точно имитируют операции, которые обычно осуществляются с документами на столе. Транспортировка непосредственно вытекает из метафоры рабочего стола; выбор значков или окон с помощью курсора является прямой аналогией захвата предметов рукой. Из метафоры рабочего стола непосредственно следует решение о перекрытии окон вместо расположения их одно рядом с другим. Представление активного окна как документа, "лежащего сверху", интуитивно понятным образом решает проблему идентификации адресата. Возможность менять размер и форму окон не имеет прямой аналогии с бумажными документами, но является последовательным расширением, дающим пользователю новые возможности, обеспечиваемые компьютерной графикой
В некоторых случаях интерфейс WIMP отходит от метафоры рабочего стола. Основные отличия: меню и работа одной рукой. Меню представляет собой не совершение действия, а выдачу кому-то (системе) команды на осуществление действия, причем, команда эта не формулируется языковыми средствами, а выбирается из списка.
Даже на чисто текстовых видеотерминалах имелась возможность вывода на экран нескольких окон одновременно, но для графического режима эта возможность значительно расширилась. Поскольку появление графического интерфейса в Apple и Windows совпало с введением многозадачности (сначала - без вытеснения), естественным образом возникло решение о выделении каждому из работающих приложений собственного окна (первичной панели). При одновременной работе нескольких приложений их окна могут перекрывать друг друга - частично или полностью, но на переднем плане всегда находится окно активного в данный момент приложения. Поскольку обилие окон может затруднить ориентацию пользователя, вводится возможность минимизации или сокрытия окон - окна неактивных приложений могут уменьшаться в размерах или вообще не выводиться на экран. Для предотвращения "потерь" скрытых окон у пользователя должна быть возможность в любой момент просмотреть список работающих приложений и восстановить нормальную визуализацию выбранных окон.
Высокая разрешающая способность графических дисплеев позволяет также имитировать объемные панели, создавая на плоском экране иллюзию светотеней. На "объемной" панели применяются графические элементы - органы управления, такие как: кнопки, линейка протяжки и т.д. Общепринятым является представление полей ввода в "утопленном" виде, а органов управления - в "приподнятом". К настоящему времени облик объемного интерфейса в современных ОС сформировался почти окончательно и включает в себя единый "источник света" и однотипное расположение органов управления на всех панелях.
Объектно-ориентированные свойства интерфейса совершенно необязательно связаны с объектно-ориентированной структурой ОС. Так, например, OS/400 является объектно-ориентированной системой с объектно-ориентированным интерфейсом, Windows NT v.3.51 была объектно-ориентированной ОС без объектно-ориентированного интерфейса, OS/2 и Windows 9x - не объектно-ориентированные ОС с объектно-ориентированным интерфейсом. Объектно-ориентированный интерфейс обычно связывают с графическим интерфейсом, но это необязательно. Так, в той же OS/400 предусмотрены две модели интерфейса: текстовая и графическая, обе в полной мере объектно-ориентированные.
В противовес обычному интерфейсу, который представляет пользователю практически единственный тип объекта - файл, единицу хранения информации в ОС, объектно-ориентированный интерфейс представляет объекты различных типов. Файлы могут быть разными типами объектов - в зависимости от типа информации в них хранящейся и способов ее обработки. Кроме того, объектами могут быть устройства, сетевые ресурсы и т.д. В объектно-ориентированном программировании под объектом понимается абстрактный тип данных, включающий в себя как сами данные, так и процедуры их обработки. Аналогично объекты понимаются и в объектно-ориентированном интерфейсе. Объект обязательно обладает некоторым набором свойств, и значения этих свойств доступно пользователю. Среди свойств, присущих объекту, имеется и указание на способ его обработки - в том числе и на приложение, обрабатывающее данные этого типа. Выполнение некоторых действий над объектом включает в себя автоматический запуск приложений, которые эти действия выполняют.
Концептуально важным объектом интерфейса является папка (folder). Папка - это контейнерный объект, содержащий в себе другие объекты и папки. Уместность папки в метафоре рабочего стола очевидна. Существенно то, что папка дает возможность пользователю создавать собственную структуру хранения объектов, альтернативную структуре хранения объектов в ОС (в файловой системе). Важным свойством, обеспечивающим эту возможность, является создание указателей на объекты. Если папка является физическим аналогом каталога файловой системы, то в нее может быть помещен указатель на объект, физически расположенный в другой папке-каталоге файловой системы (аналог косвенных файлов). Ссылка на объект с точки зрения пользователя выглядит так же, как оригинал объекта (хотя может иметь какие-то отличительные признаки ссылки), выполнение операции открытия над ссылкой приводит к открытию объекта-оригинала, но операции перемещения, удаления, переименования и т.п. выполняются не над объектом, а только над ссылкой. Возникает, однако, проблема согласования интерфейсной структуры хранения объектов с логической структурой файловой системы. Например, требуется, чтобы при перемещении объекта-оригинала в файловой системе все ссылки на него перенаправлялись на новое его место. Не все интерфейсы ОС успешно справляются с этой задачей.
Важным аспектом объектной ориентации является настройка интерфейса для конкретного пользователя. Обычно, если интерфейс рассматривается с точки зрения приложений, отмечается полезность создания нескольких форм интерфейса, ориентированных на пользователя разной квалификации - новичка, опытного, профессионала. Хотя та же задача может ставиться и перед интерфейсом ОС, более важной, на наш взгляд является интеграция интерфейса с системой безопасности ОС. Интерфейс должен показывать пользователю только те объекты и предоставлять ему только те команды, к которым данный пользователь имеет доступ. Такое возможно в тех ОС, где система безопасности тесно связана с объектно-ориентированными свойствами ОС. Настройки интерфейса могут являться частью профиля пользователя.
Каково место интерфейса WIMP в ОС? Можно назвать три подхода к выбору такого места.
Графический интерфейс может встраиваться в саму ОС и быть ее неотъемлемой частью. Такой подход применяется во всех продуктах семейства Windows и в ОС компьютеров Apple (в последних WIMP даже встроен в ПЗУ компьютера). Такой подход дает возможность тесно интегрировать интерфейс с ОС и повысить производительность интерфейсных модулей, выполняя часть из них в режиме ядра. Однако такой подход в то же время является неэкономным, так как интерфейс WIMP расходует много ресурсов и до некоторой степени опасным, так как модули WIMP могут явиться дополнительным источником ошибок в системе.
Графический интерфейс может представлять собой отдельное приложение, поставляемое в составе операционной системы и, возможно, достаточно тесно интегрированное с ней. Пример такого приложения - Workplace Shell OS/2. Такое приложение не допускается в режим ядра, но может использовать API более низкого уровня, чем обычно используемый в приложениях. Такое приложение WIMP не является обязательным компонентом ОС, система может работать и без него, в режиме командной строки или загрузить другое приложение WIMP.
Наконец, графический интерфейс может представлять собой приложение, никак не связанное с ОС, выполняющееся в тех же условиях, что и другие приложения, и выполняющее действия, задаваемые пользователем, используя обычный API ОС. В этом случае ОС не связана жестко с одним модулем WIMP, и графический интерфейс может выбираться по желанию пользователя. Примером такой ОС с большим выбором интерфейсов является Linux.
Нам представляется, что второй и третий подходы, дающие пользователю возможность выбора, являются предпочтительными.
Принцип согласованности интерфейса диктует необходимость для всех разработчиков приложений обеспечивать однотипный интерфейс в разных приложениях. Естественным решением является возможность для разработчиков приложений использовать те же модули и объекты, которые используются для построения WIMP-интерфейса ОС. В случае встроенного в ОС графического интерфейса системные объекты, обеспечивающие интерфейсные функции, делаются доступными для пользователей через соответствующий API (Windows). В случае интерфейса, представляющего собой интегрированное с ОС приложение, библиотека интерфейсных функций и объектов поставляется в составе ОС (Object Class Library в OS/2). Основой независимых графических интерфейсов являются независимые инструментальные средства, на основе которых может быть построен тот или иной WIMP-интерфейс.
Одной из наиболее успешных систем для построения таких интерфейсов является X Window, созданная в Массачусетском Технологическом Институте. Архитектура X Window построена по принципу клиент/сервер. Взаимодействие X-клиента и X-сервера происходит в рамках прикладного уровня - X-протокола. Для X Window безразличен транспортный уровень передачи, таким образом, X-клиент и X-сервер могут располагаться на разных компьютерах, в разных аппаратных и операционных средах, то есть, программа может осуществлять ввод-вывод графической информации на экран другого компьютера. Все различия в аппаратных и программных архитектурах X-клиента и X-сервера сглаживаются стандартом X-протокола. На базе инструментальных средств X Window было создано несколько сред WIMP-интерфейсов, наиболее популярный из которых, по-видимому, - Motif, являющийся стандартом Open Software Foundation.
По-видимому, WIMP-интерфейс не является окончательным решением, по мере развития аппаратных и программных средств обработки данных он, вполне вероятно, будет вытеснен новыми подходами и новыми средствами. По-видимому, на смену метафоре рабочего стола придет какая-то новая модель, обладающая собственной концептуальной целостностью. Сегодня представляется вероятным, что новая модель будет найдена где-то в области средств мультимедиа, которые сейчас развиваются весьма стремительно. Возможно, это будет голосовой ввод, возможно, что-нибудь другое. Однако, это будет достоянием уже следующего поколения. Пока, во всяком случае, мы не можем назвать какой-либо новой модели, обладающей такой же понятийной целостностью, как концепция рабочего стола.
Загружаемая файловая система
7.9. Загружаемая файловая система
Задачи переносимости программного обеспечения, в том числе, и системного, и функционирования программных изделий в среде распределенной обработки данных включают в себя требования к обеспечению единого пользовательского интерфейса различных ФС. Вытекающим отсюда следствием может быть совместное использование в одной операционной среде томов данных, обслуживаемых различными файловыми системами.
Иерархическая структура ФС дает возможность провести в иерархии уровней некоторую разграничительную линию, выше которой будут располагаться абстрактная ФС - структуры данных и алгоритмы, общие для любых ФС, а ниже - конкретная ФС со специфическими структурами и алгоритмами. Наиболее вероятно эта граница может проходить в базовой ФС, связывающей логическое представление файла с его физическим представлением. Такой подход был впервые применен в ОС Unix в связи с концепцией сетевых файловых систем. Проведение разграничительной линии на уровне базовой ФС вызывает расщепление дескриптора открытого файла на две части. Первая часть имеет общий для всех файлов формат и содержит общие для всех файлов поля, обработка которых не зависит от конкретной ФС. Это могут быть поля типа файла, размера, временные отметки и другие данные. Вторая часть - частный дескриптор - для конкретной ФС. В ней содержится план размещения файла, сведения об организации и т.д. Общая таблица томов в ядре указывает для каждого тома тип конкретной ФС, управляющей этим томом. Для каждого типа конкретной ФС ядро хранит таблицу операций - таблицу входных точек процедур, выполняющих для данной ФС стандартные функции (open, close, read и т.д.). При обращении к ФС абстрактная ФС, выполнив общие операции, определяет том и тип конкретной ФС на этом томе, выбирает соответствующую конкретной ФС таблицу входных точек и вызывает требуемую процедуру для конкретной ФС.
В системах с многоуровневыми драйверами драйвер ФС является одним из уровней, которые проходят данные на пути от процесса к устройству. При этом драйвер ФС не зависит не только от верхнего уровня - абстрактной ФС, но и от нижнего уровня - аппаратных драйверов.
Если конкретная ФС удовлетворяет спецификациям, диктуемым общей ФС, то конкретная ФС может быть загружаемой - включаемой в ядро при установке тома, управляемого конкретной ФС. Драйверы конкретной ФС могут даже и загружаться с этого же тома.
Залповое выделение
Залповое выделение.
Процесс должен запрашивать/освобождать все используемые им ресурсы сразу. Эта стратегия позволяет параллельно выполняться процессам, использующим непересекающиеся подмножества ресурсов. (Процесс C работает с лентой, процесс D - с принтером.) Тупики по-прежнему невозможны, однако неоправданное удерживание ресурсов продолжается. Так, если процессу в ходе выполнения нужны ресурсы R1 и R2, причем ресурс R1 он использует все время своего выполнения t1, а ресурс R2 требуется ему только на время t2<<t1, то процесс вынужден удерживать за собой и ресурс R2 в течение всего времени t1.
В рамках залповой стратегии возможны два варианта: выделять все ресурсы при создании процесса и освобождать при его завершении или же позволить процессу запрашивать/освобождать ресурсы несколько раз в ходе своего выполнения (но обязательно все "залпом"). Очевидно, что второй вариант более либеральный, так как он позволяет уменьшить интервал времени удерживания ресурсов и разнести использование разных ресурсов по разным "залпам". Интересны различия в API для этих двух вариантов. В первом случае требования на ресурсы могут быть вообще вынесены за пределы программного кода процесса и задаваться во внешних описателях процесса (например, в языке управления заданиями). Во втором случае системный вызов getResource является обязательным, причем обязательно должна быть обеспечена возможность запроса в одном вызове ресурсов разных классов и выделение всех запрошенных ресурсов одной непрерываемой операцией.
Запуск вторичного командного интерпретатора Командные файлы и язык процедур
Рисунок 11.1. Запуск вторичного командного интерпретатора
Зависимость частоты отказов от объема реальной памяти
Рисунок 3.7. Зависимость частоты отказов от объема реальной памяти

С точки зрения стратегии размещения не имеет значения, какой страничный кадр занимать при подкачке. Но как выбрать один кадр из всего пула кадров? Конечно, наилучшим кандидатом является полностью свободный кадр - такой, который еще не занимался или был когда-то распределен процессу, ныне уже закончившемуся. Но если суммарный объем виртуальных адресных пространств всех процессов существенно превышает объем реальной памяти, то такие страницы являются более чем дефицитным ресурсом. Выход состоит в том, что для каждого распределенного кадра в таблице страничных кадров (и/или в таблице дескрипторов) ведется учет факторов, определяющих выбор его в качестве жертвы для вытеснения, и из всех кадров выбирается тот, который является лучшим (с точки зрения принятой стратегии) кандидатом в жертвы (OS/2, Windows 95). Несколько более сложное решение - ОС ведет список свободных (условно свободных) кадров и очередная жертва выбирается из этого списка. Страничный кадр попадает в список жертв, если его "показатель жертвенности" превышает некоторое граничное значение, но может быть еще "спасен" из списка жертв, если во время пребывания в этом списке он будет востребован. Помещение кадра в список жертв может выполняться либо сразу по достижении "показателя жертвенности" граничного значения (VM), либо (ленивая политика - Unix) размер списка поддерживается в определенных границах за счет периодического его пополнения путем просмотра всей таблицы страничных кадров.
В качестве образцов для сравнения в литературе рассматриваются стратегии вытеснения RANDOM и OPT. Стратегия RANDOM заключается в том, что страница для вытеснения выбирается случайным образом. Понятно, что достичь высокой эффективности при такой стратегии невозможно, и любая другая введенная нами стратегия может считаться сколько-нибудь разумной только в том случае, если она, по крайней мере, не хуже стратегии RANDOM. Стратегия OPT требует, чтобы в первую очередь вытеснялась страница, к которой дольше всего не будет обращений в будущем. Интуитивно понятно и строго доказано, что эта стратегия является наилучшей из всех возможных. Но, к сожалению, эта стратегия в идеальном варианте нереализуема из-за невозможности точно прогнозировать требования. Реально применяемые стратегии могут оцениваться по степени приближения их результатов к результатам OPT.
Стратегия FIFO - первый на входе - первый на выходе - является простейшей. Согласно этой стратегии из реальной памяти вытесняется та страница, которая была раньше других в нее подкачана. Для реализации этой стратегии ОС достаточно организовать список-очередь страниц в реальной памяти с занесением подкачиваемой страницы в "голову" списка и выборкой страницы для вытеснения из "хвоста" списка. Хотя стратегия FIFO и лучше, чем RANDOM, она не учитывает частоты обращений: может быть вытеснена страница, к которой происходят постоянные обращения. Более того, при некоторых комбинациях страничных требований FIFO может давать аномальные результаты: увеличение числа страничных отказов при увеличении числа доступных страничных кадров (см. задания в конце главы).
Многие используемые в современных ОС стратегии вытеснения могут рассматриваться как разновидности стратегии LRU (least recently used) - наименее используемая в настоящее время: вытесняется та страница, к которой дольше всего не было обращений. Это можно рассматривать как попытку приближения к стратегии OPT путем экстраполяции потока страничных требований из прошлого на будущее. Разновидности LRU различаются тем, как они учитывают время использования страницы. Очевидно, что запоминание точного времени обращения к каждой странице обошлось бы слишком дорого. Стратегии LRU используют биты used и dirty дескриптора страницы для оценки этого времени. Бит used устанавливается в 1 аппаратно при любом обращении к странице, бит dirty устанавливается аппаратно при обращении к странице для записи; оба бита сбрасывается ОС по своему усмотрению. Все множество присутствующих в реальной памяти страниц разбивается на четыре подмножества, в зависимости от значений этих полей: неиспользованные чистые (used=0, dirty=0), неиспользованные грязные (used=0, dirty=1), использованные чистые (used=1, dirty=0), использованные грязные (used=1, dirty=1).
Чем меньше номер подмножества, в которое входит страница, тем желательнее она в роли жертвы. Внутри одного подмножества жертва может выбираться методом циклического поиска или случайным образом. ОС должна выбрать момент, когда она будет сбрасывать биты used в 0. Ленивая политика состоит в том, чтобы делать это только, когда уже не остается неиспользованных страниц. Противоположные вариант - при каждом поиске жертвы сбрасывать биты used для всех страниц или только для проверенных в ходе поиска. Наконец, общий сброс битов used может производиться по таймеру.
Интересным образом используется бит dirty в стратегии SCC (second cycle chance) - цикл второго шанса. Алгоритм этого варианта стратегии LRU осуществляет циклический просмотр таблицы страничных кадров. Разумеется, лучшим кандидатом является неиспользованная страница (подмножества 1 и 2). Но если таковых нет, то выбирается страница с нулевым полем dirty (подмножество 3). Просмотренные страницы, оказавшиеся грязными, ОС не трогает (пока), но сбрасывает в них поле dirty. Таким образом, даже если при полном обороте поиска не будет найдена жертва, она обязательно найдется при втором обороте. "Второй шанс" здесь состоит в том, что страница, принудительно отмеченная как чистая, может еще в промежутке между двумя поисками восстановить поле dirty. При такой стратегии поле dirty уже не отражает истинного состояния страницы, ОС должна сохранять действительное состояние в расширении дескриптора страницы.
Более сложные варианты стратегии LRU предусматривают более, чем одноразрядный, учет времени. Метод временного штампа (timestamp) предусматривает хранение для каждой страницы многоразрядного кода. Периодически этот код сдвигается на разряд влево, а в освободившийся старший разряд заносится текущее значение поля used, после чего поле used сбрасывается в 0. Код временного штампа хранит, таким образом, предысторию использования страниц. Наилучшей жертвой оказывается та страница, у которой значение штампа (если интерпретировать его как целое число без знака) минимальное.
Метод возраста страницы (Unix) подобен предыдущему, но здесь с каждой страницей связывается число - ее "возраст". При периодическом просмотре таблицы страничных кадров для страницы, у которой бит used равен 0, возраст увеличивается на 1, если же бит used установлен в 1, то он сбрасывается в 0, а возраст не меняется. Когда системный процесс "сборщик страниц" пополняет список свободных страниц, он заносит в него те страницы, для которых превышен установленный граничный возраст.
Выше мы использовали биты used и dirty, предполагая, что они поддерживаются аппаратно. Однако, возможна реализация указанных стратегий и при отсутствии такой аппаратной поддержки. В этом случае недостающие поля содержатся в расширении дескриптора страницы, а вместо них ОС сбрасывает в 0 бит present. Бит present в дескрипторе уже не отражает истинного состояния и дублируется в расширении. Обращение к такой странице вызывает ловушку "страничный отказ", однако ОС убеждается по расширению дескриптора, что страница на самом деле уже есть в реальной памяти, и вместо ее подкачки корректирует бит present в основном дескрипторе, одновременно устанавливая used в расширении.
Указанные стратегии применимы как к локальному, так и к глобальному управлению памятью. В первом случае каждому процессу выделяется статический пул страничных кадров и свопинг ведется в пределах этого пула (например, AS/400). Это дает возможность применять для разнотипных процессов разные стратегии, но требует принятия решения о размере каждого пула. В случае же глобального управления выбранная стратегия применяется по всему доступному множеству страничных кадров и производится постоянное перераспределение ресурсов между процессами (например, VM, MVS). Динамическое перераспределение - качество полезное, но, если оно не учитывает уровень мультипрограммирования, то может привести к толкотне.
Ряд глобальных стратегий, управляющих уровнем мультипрограммирования, основывается на идее рабочего набора - WS (working set). Идея эта базируется на явлении локализации обращений к памяти. Любая программа не обращается ко всему своему адресному пространство одновременно. На каждом временном отрезке программа работает только с некоторым подмножеством адресов и, соответственно, с некоторым подмножеством страниц. Временной отрезок, на котором это подмножество квазипостоянно, называется фазой программы. Почти полное обновление этого подмножества называется сменой фазы. Рабочим набором процесса S(w) называется перечень страниц, к которым процесс обращался в течении последнего интервала виртуального времени w. Методы, основанные на идее рабочего набора, стремятся к тому, чтобы выполняющийся процесс постоянно имел свой рабочий набор в реальной памяти и страницы, входящие в рабочие наборы выполняющихся процессов не вытеснялись. Если у ОС нет возможности разместить в реальной памяти весь рабочий набор процесса, она снижает уровень мультипрограммирования, переводя процесс в состояние ожидания. При разблокировании процесса ОС имеет возможность перед его активизацией выполнить упреждающую подкачку (preload) всего его рабочего набора и тем самым значительно снизить частоту страничных отказов.
На практике, однако, идеальная реализация стратегии WS не представляется возможной по тем же соображениям, что и для идеальной LRU: нет возможности запоминать время каждого обращения. Адаптированный метод WS состоит в его определении через фиксированные интервалы времени. В начале каждого интервала все страницы, для которых распределены страничные кадры, считаются входящими в рабочий набор. В течение интервала все запросы процесса на новые страницы удовлетворяются. По окончании интервала те страницы, которые не были использованы (бит used), удаляются из рабочего набора. Зафиксированный в конце интервала рабочий набор служит исходным для следующего интервала.
Некоторые методы стратегии WS не сохраняют полный перечень страниц, входящих в рабочий набор, а только определяют его обобщенные показатели. Алгоритм метода рабочего размера замеряет только размер рабочего набора и выделяет процессу соответствующее число страничных кадров (VM). Метод частоты страничных отказов основан на измерении интервала виртуального времени между двумя страничными отказами, если этот интервал меньше нижней границы, процессу выделяется дополнительный страничный кадр, если интервал больше верхней границы, у процесса отбирается один страничный кадр. Естественно, что методы, не сохраняющие всего списка рабочего набора, не имеют возможности выполнять упреждающую его подкачку.
При страничном свопинге, как и при сегментном, применяется, как правило, стратегия подкачки по запросу (demand paging), так как реализовать полностью безубыточную стратегию упреждающей подкачки невозможно. Тем не менее, в стратегии WS появляется возможность упреждающей подкачки с минимальными убытками. В системах, имеющих большой объем памяти и не особенно заботящихся о минимизации ее потерь иногда применяется также кластеризация подкачки. Этот метод также базируется на локализации и исходит из того, что если произошло обращение к некоторой странице, то с большой вероятностью можно ожидать в ближайшем будущем обращений к соседним с ней страницам, которые и подкачиваются, не дожидаясь этих обращений.
Системные вызовы страничной модели "не видят" страничной структуры и обращаются к памяти как к линейному пространству виртуальных адресов.
Выделение памяти происходит при помощи системного вызова: vaddr = getMem(size) который возвращает виртуальный адрес выделенной области заданного размера. На самом деле размер выделенной области кратен размеру страницы, а ее адрес выровнен по границе страницы.
Освобождение памяти: freeMem(vaddr)
Поскольку память выделяется страницами, при выделении памяти для маленьких (существенно меньших размера страницы) объектов образуются значительные внутренние дыры. Для того, чтобы избежать этих потерь, некоторые системы обеспечивают работу с кучей (heap) - заранее выделенной областью памяти размером в одну или несколько страниц с последующим выделением памяти для маленьких объектов в куче. Соответствующие системные вызовы: heapId = createHeap(size); vaddr = getHeapMem(heapID,size) freeHeapMem(vaddr)
