Теория операционных систем
Компьютер и внешние события
| Мы ждали его слишком долго. Что может бытьглупее, чем ждать? Б. Гребенщиков |
Практически все функции современных вычислительных систем так или иначе
сводятся к обработке внешних событий. Единственная категория приложений,
для которых внешние события совершенно неактуальны — это так называемые
пакетные приложения, чаще всего — вычислительные
задачи. Доля таких задач
в общем объеме компьютерных приложений в наше время невелика и постоянно
падает. В остальных же случаях, даже если не вспоминать о специализированных
управляющих компьютерах, серверы обрабатывают внешние по отношению к ним
запросы клиентов, а персональный компьютер — реагирует на действия пользователя.
Различие между управляющими системами (приложениями реального времени)
и системами общего назначения (термин — система разделенного
времени вышел
из употребления и не всегда точно отражает суть дела) состоит лишь в том,
что первые должны обеспечивать гарантированное время реакции на событие,
в то время как вторые "всего лишь" — предоставить хорошее среднее
время такой реакции и/или обработку большого количества событий в секунду.
Примечание
Время обработки одного события и количество событий, обрабатываемых в
единицу времени, далеко не всегда являются жестко взаимосвязанными — ведь
при многопоточной обработке система может обрабатывать несколько событий
параллельно.
Единственный способ, которым фон-неймановский компьютер может отреагировать
на что бы то ни было — это исполнить программу, последовательность команд.
В случае внешнего события, естественным решением кажется предоставить
команду условного перехода, условием которого является признак события.
В системах команд микроконтроллеров частореализуют именно такие переходы
(см. например табл. 2.2). В качестве признака события в этом случае используется
значение одного из битов специального регистра, биты которого соответствуют
входам микросхемы контроллера. Бит равен единице, если на соответствующий
вход подано высокое напряжение, и нулю — если низкое.
Наличие таких команд полезно, но решает проблему не полностью: да, сели
событие произошло, мы моыжем вызвать программу и осуществить реакцию но
что мы будем делать, если его еще не происходило?
Теория операционных систем
Прерывания Альтернатива опросу, применяемая практически во всех
современных процессорах, называется прерываниями
(interrupt), и состоит в значительном усложнении логики обработки
команд процессором. Прерывания в PDP-11 Прерывания лишены недостатков, которые мы указали и выше
для обработки событий при помощи опроса: ожидая события, процессор может
заниматься какой-либо другой полезной работой, а когда событие произойдет,
он приступит к обработке, не дожидаясь полного завершения этой работы. |
|||

Исключения
Многие процессоры используют механизм, родственный прерываниям, для
обработки не только внешних, но и внутренних событий: мы с вами уже сталкивались
с исключительными ситуациями (exception) отсутствия страницы и ошибки
доступа в процессорах с виртуальной памятью, а также некоторыми другими
— ошибкой шины при доступе к невыровненным словам, заполнению и очистке
регистрового окна у SPARC и т. д. Большинство современных процессоров
предоставляют исключения при неизвестном коде
операции, делении на ноль, арифметическом переполнении или, например,
выходе значения операнда за допустимый диапазон в таких операциях, как
вычисление логарифма, квадратного корня или арксинуса.
Исключительные ситуации обрабатываются аналогично внешним прерываниям:
исполнение программы останавливается, и управление передается на процедуру-обработчик,
адрес которой определяется природой исключения.
Отличие состоит в том, что прерывания обрабатываются после завершения
текущей команды, а возврат из обработчика приводит к исполнению команды,
следующей за прерванной. Исключение же приводит к прекращению исполнения
текущей команды (если в процессе исполнения команды мы уже успели создать
какие-то побочные эффекты, они отменяются), и сохраненный счетчик команд
указывает на прерванную инструкцию. Возврат из обработчика, таким образом,
приводит к попытке повторного исполнения операции, вызвавшей исключение.
Благодаря этому, например, обработчик страничного отказа может подкачать
с диска содержимое страницы, вызвавшей отказ, перенастроить таблицу дескрипторов
и повторно исполнить операцию, которая породила отказ. Обработчик исключения
по неопределенному коду операции может использоваться для эмуляции расширений
системы команд.
Например, при наличии арифметического сопроцессора операции с плавающей
точкой исполняются им, а при отсутствии — пакетом эмулирующих подпрограмм.
Благодаря этому может обеспечиваться полная бинарная совместимость между
старшими (имеющими сопроцессор) и младшими (не имеющими его) моделями
одного семейства компьютеров.
Исключения, возникающие при исполнении привилегированных команд в пользовательском
режиме, могут использоваться системой виртуальных машин. Работающее в
виртуальной машине ядро ОС считает, что исполняется в системном режиме.
На самом же деле оно работает в пользовательском режиме, а привилегированные
команды (переключения режима процессора, настройка диспетчера памяти,
команды ввода/вывода) приводят к вызову СВМ.
При грамотной реализации обработчиков таких исключений их обработка Произойдет
полностью прозрачно для породившей эти исключения программы. Конечно,
"подкачка" страницы с диска или программная эмуляция плавающего
умножения займет гораздо больше времени, чем простое обращение к памяти
или аппаратно реализованное умножение, но, наверное, Потребитель вычислительной
системы знал, что делал, когда устанавливал недостаточное количество памяти
или приобретал машину без сопроцессора.
Многие другие исключения, такие, как деление на ноль, обычно бессмЬ1с
ленно обрабатывать повторной попыткой деления на какое-то другое число
В этом случае целесообразно возвратить управление не на команду, вызвав
шую исключение, а в какую-то другую точку. Вопрос, впрочем, в том, куда
именно следует возвращаться. Понятно, что код, который может восстано
виться в случае деления на ноль, сильно зависит от контекста, в котором
произошла ошибка (пример 6.2).
Пример 6.2. Обработка исключения Floating underflow (антипереполние при операциях с плавающей точкой)
#tinclude <setjmp.h>
static jmp_buf fpe_retry;
void fpe_handler (int sig) {
4> __fpreset () ; longjmp (fpe__retry, -1) ;
int compare_pgms (Image * imgO, Image * img1) {
int xsize=256, ysize=256;
int i, j , pO, pi, pd;
double avg, avgsq, scale, smooth;
scale= (double) xsize* (double) ysize;
avg = 0.0; avgsq = 0.0;
/* Подавить возможные антипереполнения */
signal (SIGFPE, fpe_handler) ;
for(i=0; i<ysize; i smooth = (double) (imgO->picture [i*xsize] -imgl->picture
[i*xsize] ) ; for(j=0; j<xsize; j++) { pO=imgO->picture [ j+i*xsize]
; pl=imgl->picture [ j+i*xsize] ; pd=(pO-pl) ;
if (setjmp (fpe_retry) == 0) { smooth = smooth* (1 . 0-SMOOTH_FACTOR)
+ (double) pd*SMOOTH_FACTOR;
vq += smooth; avgsq += smooth*smooth;
eise
smooth=0 . 0 ;
if (Setjmp(fpe_retry) == 0)
Aspersion = avgsq/scale-avg*avg/ (scale*scale) ;
else dispersion = 0.0;
signal (SIGFPE, SIGJDFL) ;
}
При программировании на ассемблере это может быть реализовано простой подменой адреса возврата в стеке. Многие языки высокого уровня (ЯВУ) реализуют те или иные средства для обработки исключений. Уровень этих средств различен в разных языках, начиная от пары функций setjmp и longjmp в С [Керниган-Ритчи 2000] (пример 6.3) и заканчивая операторами try/catch и throw C++ [Страуструп 1999] и Java [Вебер 1999].
Пример 6.3. Исходный текст функций set jmp/ longjmp.
/ setjmp. s (emx+gcc) — Copyright (c) 1990-1996 by Eberhard
Mattes
# include <emx/asm386.h>
.globl _setjmp, _longjmp
.text ALIGN
# define J_EBX 0
# define J_ESI 4
# define J_EDI 8
#define J_ESP 12
#define J_EBP 16
# define J_EIP 20
# define J_XCP 24
/ Слова со смещениями 28.. 44 зарезервированы
/ int setjmp (jmp_buf here)
_setjmp:
PROFILE__NOFRAME
movl l*4(%esp), %edx /* here */
raovl %ebx, J_EBX(%edx)
movl %esi, J_ESI(%edx)
movl ledi, J_EDI(%edx)
movl %ebp, J_EBP(%edx)
movl %esp, J_ESP(%edx)
movl 0*4(%esp), %eax /* Адрес возврата */
movl %eax, J_EIP(%edx)
cmpb $0, __osmode /* OS/2? */
je If /* No -> skip */
fs
movl 0, leax /* handler Обработчик исключений */
movl %eax, J_XCP(%edx) 1: xorl %eax, leax
EPILOGUE(setjmp)
ALIGN
/ void longjmp (jmp_buf there, int n)
_longjmp:
PROFILE_NOFRAME
cmpb $0, __osmode /* OS/2? */
je 2f /* No -> skip */
movl 1*4(%esp), %eax /* there */
pushl J_XCP(%eax)
call ___unwind2 /* восстановить обработчики сигналов */
addl $4, %esp 2: movl l*4(%esp), ledx /* there */
movl 2*4(%esp), leax /* n */
testl %eax, leax
jne 3f
incl %eax
3: movl J_EBX(%edx), %ebx
movl J_ESI(ledx), lesi
raovl J_EDI(%edx), %edi
movl J EBP(%edx), %ebp
J_ESP(%edx) ,
J_EIP(%edx>, %edx
%edx, 0*4(%espj /* адрес возврата */
EPILOGUE(longjmp) /* well, ... */
Исключения в ЯВУ часто позволяют избежать использования нелюбимого структурными
программистами оператора goto. В объектно-ориентированных
(ОО) языках этот механизм играет еще более важную роль: в большининстве
таких языков — это единственный способ сообщить о неудаче при исполнении
конструктора объекта.
Важно подчеркнуть, впрочем, что исключения в смысле ЯВУ и аппаратные исключения
процессора — разные вещи. В многозадачной ОС пользовательская программа
не имеет непосредственного доступа к обработке прерываний и исключений.
ОС предоставляет сервис, позволяющий программисту регистрировать обработчики
для тех или иных событий, как соответствующих аппаратным исключениям,
так и порождаемых самой операционной системой, но вызов таких обработчиков
всегда осуществляется в два этапа: сначала исполняется обработчик, зарегистрированный
ядром (пример 6.4), а он, если сочтет нужным и возможным, переключается
в пользовательский контекст и вызывает обработчик, зарегистрированный
пользователем. Среда исполнения ЯВУ, в свою очередь, может реализовать
и свои обработчики между сервисом операционной системы и средствами, доступными
программисту.
Пример 6.4. Обработчик арифметических исключений в ядре Linux I
/*
* Iinux/arch/i386/traps.c *
* Copyright (С) 1991, 1992 Linus Torvalds *
* Поддержка Pentium III FXSR, SSE
* Gareth Hughes <gareth@valinux.com>, May 2000 */
void die(const char * str, struct pt_regs * regs, long err) I
console_verbose(); spin_lock_irq(&die_lock); Printk("%s: %041x\n",
str, err & Oxffff}; show_registers(regs);
sPin_unlock_irq(&die_lock);
do_exit (SIGSEGV) ;
static inline void die_if_kernel (const char * str, struct pt_regs * regs
long err)
{
if ( ! (regs->eflags & VM_MASK) && ! (3 & regs->xcs)
) die (str, regs, err);
static inline unsigned long get_cr2 (void) { unsigned long address;
/* получить адрес */
_ asm _ ("movl %%cr2, %0" : "=r" (address));
return address;
static void inline do_trap(int trapnr, int signr, char *str, int vm86,
struct pt_regs * regs, long error_code, siginfo_t *info) { if (vm86 &&
regs->eflags & VM_MASK)
goto vm86_trap; if ( ! (regs->xcs & 3) ) goto kernel_trap;
trap_signal: {
struct task_struct *tsk = current; tsk->thread. error_code = error_code;
tsk->thread. trap_no = trapnr; if (info)
force_sig_info (signr, info, tsk) ; else
force_sig (signr, tsk) ; return;
kernel_trap:
unsigned long fixup = search_exception_table(regs->eip); if (fixup)
regs->eip = fixup; else
die(str, regs, error_code); return;
vm86_trap: {
int ret = handle_vm86_trap((struct kernel_vm86_regs *) regs, er-ror_code,
trapnr);
if (ret) goto trap_signal; return;
fldefine DO_ERROR(trapnr, signr, str, name) \
asmlinkage void do_tt#name(struct pt_regs * regs, long error_code) \ {
\ do_trap(trapnr, signr, str, 0, regs, error_code, NULL); \
Idefine DO_ERROR_INFO(trapnr, signr, str, name, sicode, siaddr) \ asmlinkage
void do_t#name(struct pt_regs * regs, long error_code) \ { \
siginfo_t info; \
info.si_signo = signr; \
info.si_errno =0; \
info.si_code = sicode; \
info.si_addr = (void *)siaddr; \
do^trap(trapnr, signr, str, 0, regs, error_code, Sinfo); \ }
ttdefine DO_VM86_ERROR(trapnr, signr, str, name) \
asmlinkage void do_##name(struct pt_regs * regs, long error_code) \ (
\
do_trap(trapnr, signr, str, 1, regs, error_code, NULL); \ }
ttdefine DO_VM86__ERROR_INFO(trapnr, signr, str, name, sicode, siaddr)
\
I
asmlinkage void do_##name(struct pt_regs * regs, long error_code) \ {
\
siginfo_t info; \
info.si_signo = signr; \
info.si_errno =0; \
info.si_code = sicode; \
info.si_addr = (void *)siaddr; \
do_trap(trapnr, signr, str, 1, regs, error_code, sinfo); \
' "
DO_VM86_ERROR_INFO( 0, SIGFPE, "divide error", divide_error,
FPE_INTDIV, regs->eip)
DO_VM86_ERROR( 3, SIGTRAP, "int3", int3)
DO_VM86_ERROR( 4, SIGSEGV, "overflow", overflow)
DO_VM86_ERROR( 5, SIGSEGV, "bounds", bounds)
DO_ERROR_INFO( 6, SIGILL, "invalid operand", invalid_op, ILL_ILLOPN,
regs->eip)
DO_VM86_ERROR( 7, SIGSEGV, "device not available", device_not_available)
DO_ERROR( 8, SIGSEGV, "double fault", double_fault)
DO_ERROR( 9, SIGFPE, "coprocessor segment overrun", coproces-sor_segment_overrun)
DO_ERROR(10, SIGSEGV, "invalid TSS", invalidJTSSl
DO_ERROR(11, SIGBUS, "segment not present", segment_not_present)
DO_ERROR(12, SIGBUS, "stack segment", stack_segment)
DO_ERROR_INFO(17, SIGBUS, "alignment check", alignment_check,
BUS_ADRALN,
get_cr2 () )
Многопроцессорные архитектуры
Как уже говорилось, относительно большие накладные расходы, связанные
с обработкой прерываний, нередко делают целесообразным включение в систему
дополнительных процессоров. Есть и другие доводы в пользу создания многопроцессорных
вычислительных систем.
Одним из доводов является повышение надежности вычислительной системы
посредством многократного резервирования. Если один из процессоров многопроцессорной
системы отказывает, система может перераспределить загрузку между оставшимися.
Для компьютеров первых поколений, у которых наработка аппаратуры процессора
на отказ была относительно невелика, повышение надежности таким способом
часто оказывалось целесообразным, особенно в приложениях, требовавших
круглосуточной доступности.
Примечание
Понятно, что для обеспечения непрерывной доступности недостаточно просто
поставить много процессоров, и даже недостаточно уметь своевременно обнаружить
отказ и исключить сломавшийся процессор из системы. Необходима также возможность
заменить отказавший узел без выключения и без перезагрузки системы, что
накладывает весьма жесткие требования и на конструкцию корпуса, и на электрические
параметры межмодульных соединений, и, наконец, на программное обеспечение,
которое должно обнаружить вновь добавленный процессорный модуль и включить
его в конфигурацию системы.
Другим доводом в пользу включения в систему дополнительных процессоров
является тот факт, что алгоритмы, используемые для решения многих прикладных
задач, нередко поддаются распараллеливанию:
разделению работы между несколькими более или менее независимо работающими
процессорами. В зависимости от алгоритма (и, косвенно, от природы решаемой
задачи) уровень достижимого параллелизма может сильно различаться. Отношение
производительности системы к количеству процессоров и производительности
однопроцессорной машины называют коэффициентом масштабирования.
Для различных задач, алгоритмов, ОС и аппаратных архитектур этот коэффициент
различен, но всегда меньше единицы и всегда убывает по мере увеличения
количества процессоров.
Некоторые задачи, например, построение фотореалистичных изображений методом
трассировки лучей, взлом шифров полным перебором пространства ключей [www.distributed.net]
или поиск внеземных цивилизаций [www.seti.org]
поддаются масштабированию очень хорошо: можно включить в работу десятки
и сотни тысяч процессоров, передавая при этом между ними относительно
малые объемы данных. В этих случаях часто оказывается Целесообразно даже
не устанавливать процессоры в одну машину, а использовать множество отдельных
компьютеров, соединенных относительно низкоскоростными каналами передачи
данных. Это позволяет задействовать процессоры, подключенные к сети (например,
к Интернет) и не занятые в данный момент другой полезной работой.
Другие задачи, например, работа с базами данных, поддаются распараллеливанию
в гораздо меньшей степени, однако и в этом случае обработка запросов может
быть распределена между несколькими параллельно работающими процессорами.
Количество процессоров в серверах СУБД обычно измеряется несколькими штуками,
они подключены к обшей шине, совместно используют одну и ту же оперативную
память и внешние устройства.
Многопроцессорность в таких системах обычно применяется только для ц0.
вышения производительности, но очевидно, что ее же можно использовать
и для повышения надежности: когда функционируют все процессоры, система
работает быстро, а с частью процессоров работает хоть что-то, пусть и
медленнее.
Некоторые многопроцессорные системы поддерживают исполнение на ных процессорах
различных ОС — так, на IBM z90 часть процессоров M исполнять Linux, а
остальные — z/OS. В такой конфигурации, работающий под управлением Linux
Web-сервер может взаимодействовать с работающим под z/OS сервером транзакций
через общую физическую память. Многопроцессорные серверы Sun Fire могут
исполнять несколько копий Solaris.
Промежуточное положение между этими крайностями занимают специализированные
массивно-параллельные компьютеры, используемые
для таких задач, как численное решение эллиптических дифференциальных
уравнений и численное же моделирование методом конечных элементов в геофизических,
метеорологических и некоторых других приложениях.
Современные суперкомпьютеры этого типа (IBM „SP6000, Cray Origin) состоят
из десятков, сотен, а иногда и тысяч отдельных процессорных модулей (каждый
модуль представляет собой относительно самостоятельную вычислительную
систему, обычно многопроцессорную, с собственной памятью и, нередко, с
собственной дисковой подсистемой), соединенных между собой высокоскоростными
каналами. Именно к этому типу относился шахматный суперкомпьютер Deep
Blue, выигравший в 1997 году матч у чемпиона мира по шахматам Гарри Каспарова
[www.research.ibm.com].
Многопроцессорные системы различного рода получают все более и более широкое
распространение. Если производительность отдельного процессора удваивается
в среднем каждые полтора года ("закон Мура" [www.intel.com
Moore]), то производительность многопроцессорных систем удваивается
каждые десять месяцев [www.sun.com 2001-05].
На практике, даже хорошо распараллеливаемые алгоритмы практически никогда
не обеспечивают линейного роста производительности с ростом числа процессоров.
Это обусловлено, прежде всего, расходами вычислительных ресурсов на обмен
информацией между параллельно исполняемыми потоками. На первый взгляд,
проще всего осуществляется такой обмен в системах с процессорами, имеющими
общую память, т. е. собственно многопроцессорных компьютерах.
В действительности, оперативная память имеет конечную, и небольшую по
сравнению с циклом центрального процессора, скорость доступа. Даже один
современный процессор легко может занять все циклы доступа ОЗУ, а несколько
процессоров будут непроизводительно тратить время, ожидая доступа к памяти.
Многопортовое ОЗУ могло бы решить эту проблему,
но такая память намного дороже обычной, однопортовой, и применяется лишь
в особых случаях и в небольших объемах.
Одно из основных решений, позволяющих согласовать скорости ЦПУ и ОЗУ,
— это снабжение процессоров высокоскоростными кэшами
команд и данных. Такие кэши нередко делают не только для центральных
процессоров, но и для адаптеров шин внешних устройств. Это значительно
уменьшает количество обращений к ОЗУ, однако мешает решению задачи, ради
которой мы и объединяли процессоры в единую систему: обмена данными между
потоками, исполняющимися на разных процессорах (рис. 6.2).

Рис. 6.2. Некогерентный кэш
Большинство контроллеров кэшей современных процессоров предоставляют
средства обеспечения когерентности кэша —
синхронизацию содержимого кэш-памятей нескольких процессоров без обязательной
записи данных в основное ОЗУ.
Суперскалярные процессоры, у которых порядок реального исполнения операций
может не совпадать с порядком, в котором соответствующие команды следуют
в программе, дополнительно усугубляют проблему.
Порядок доступа к памяти в SPARC
Современные процессоры предоставляют возможность управлять порядком доступа
команд к памяти. Например, у микропроцессоров SPARCvQ [www.sparc.com v9]
определены три режима работы с памятью (модели памяти), переключаемые
битами в статусном регистре процессора.
Свободный доступ к памяти (RMO, Relaxed Memory Order), когда процессор
использует все средства кэширования и динамического переупорядочения команд,
и не пытается обеспечить никаких требований к упорядоченности выбор-ки
и сохранению операндов в основной памяти.
Частично упорядоченный доступ (PSO, Partial Store Order), когда процессор
по-прежнему использует и кэширование, и переупорядочивание, но в потоке
команд могут встречаться команды MEMBAR. Встретив такую команду, сор обязан
гарантировать, что все операции чтения и записи из памяти, зако дированные
до этой команды, будут исполнены (в данном случае под исполнением подразумевается
перенос результатов всех операций из кэша в ОЗУ), д0 того, как процессор
попытается произвести любую из операций доступа к памяти, следующих за
MEMBAR.
Полностью упорядоченный доступ (TSO, Total Store Order), когда процессор
гарантирует, что операции доступа к памяти будут обращаться к основному
ОЗУ в точности в том порядке, в котором закодированы.
Каждый следующий режим повышает уверенность программиста в том, что его
программа прочитает из памяти именно то, что туда записал другой процессор,
но одновременно приводит и к падению производительности. Наибольший проигрыш
обеспечивает наивная реализация режима TSO, когда мы просто выключаем
и динамическое переупорядочение команд, и кэширование данных (кэширование
кода можно оставить, если только мы не пытаемся исполнить код, который
подвергается параллельной модификации другим задатчиком шины).
Другим узким местом многопроцессорных систем является системная шина. Современные компьютеры общего назначения, как правило, имеют шинную архитектуру, т. е. и процессоры, и ОЗУ, и адаптеры шин внешних устройств (PCI и т. д.) соединены общей магистралью данных, системной шиной или системной магистралью. В каждый момент магистраль может занимать только пара устройств, задатчик и ведомый (рис. 6.3). Обычно, задатчиком служит процессор — как центральный, так и канальный — или контроллер ПДП, а ведомым может быть память или периферийное устройство. При синхронизации содержимого кэшей процессорный модуль также может оказаться в роли ведомого.
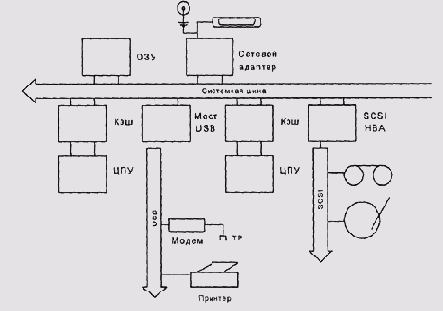
Рис. 6.3. Шинная архитектура
Доступ к шине регулируется арбитром шины.
Практически применяются две основные стратегии арбитража — приоритетная,
когда устройство, имеющее высокий приоритет, всегда получает доступ, в
том числе и при наличии запросов от низкоприоритетных устройств, и
справедливая (fair), когда арбитр гарантирует всем устройствам
доступ к шине в течение некоторого количества циклов.
Системы шинной архитектуры просты в проектировании и реализации, к ним
легко подключать новые устройства и типы устройств, поэтому такая архитектура
получила широкое распространение. Однако, особенно в многопроцессорных
системах, шина часто является одним из основных ограничителей производительности.
Повышение пропускной способности шины зачастую возможно, но приводит к
повышению обшей стоимости системы.
Впрочем, при большом количестве узлов проблемы возникают и у систем со
столь высокоскоростной шиной, как FirePane. Кроме того, по мере роста
физических размеров системы, становится необходимо принимать во внимание
физическую скорость передачи сигналов — как сигналов самой магистрали,
так и запросов к арбитру шины и его ответов. Поэтому шинная топология
соединений при многих десятках и сотнях узлов оказывается .неприемлема,
и применяются более сложные топологии.
Системы NUMA-Q
Многопроцессорные серверы IBM NUMA-Q состоят из отдельных процессорных
модулей. Каждый модуль имеет собственную оперативную память и четыре процессора
х86. Модули называются quad (четверки) (рис. 6.4).
Четверки соединены высокоскоростными каналами IQ-Link с центральным коммутатором.
Замена общей шины на звездообразную топологию с центральным коммутатором
позволяет решить проблемы арбитража доступа к шине, в частности, устранить
задержки при запросе к арбитру шины и ожидании его ответа запрашивающему
устройству. NUMA-системы фирмы IBM могут содержать до 16 четверок, т.
е. до 64 процессоров.
Архитектура позволяет также включать в эти системы процессоры с архитектурой,
отличной от х86, например RS/6000 и System/390, позволяя, таким образом,
создать в пределах одной машины гетерогенную сеть со сверхвысокоскоростными
каналами связи.
При большем числе модулей применяются еще более сложные топологии, например
гиперкубическая. В таких системах каждый узел
обычно также содержит несколько процессоров и собственную оперативную
память (рис. 6.5).
При гиперкубическом соединении, количество узлов N пропорционально степени
двойки, а каждый узел имеет log2N соединений с другими узлами.
Каждый узел способен не только обмениваться сообщениями с непосредственными
соседями по топологии, но и маршрутизировать сообщения между узлами, не
имеющими прямого соединения. Самый длинный путь между узлами, находящимися
в противоположных вершинах куба, имеет длину log2N и не является
единственным (рис. 6.6). Благодаря множественности путей, маршрутизаторы
могут выбирать для каждого сообщения наименее загруженный в данный момент
путь или обходить отказавшие узлы.

Рис. 6.4. NUMA-Q с тремя четырехпроцессорными модулями
Массивно параллельные системы Cray/SGI
Origin
Узлы суперкомпьютеров семейства Cray/SGI Origin соединены в гиперкуб каналами
с пропускной способностью 1 Гбайт/с. Адаптеры соединений обеспечивают
не просто обмен данными, а прозрачный (хотя и с падением производительности)
доступ процессоров каждого из узлов к оперативной памяти других узлов
и обеспечение когерентности процессорных кэшей.

Рис. 6.5. Гиперкубы с 4, 8 и 16-ю вершинами
Различие в скорости доступа к локальной памяти процессорного модуля и Других модулей является проблемой, и при неудачном распределении загрузки между модулями (таком, что межмодульные обращения будут часты) Приведет к значительному снижению производительности системы. Известны два основных пути смягчения этой проблемы.
СОМА (Cache Only Memory Architecture) — архитектура памяти, при которой работа с ней происходит как с кэшем. Система переносит страницы памяти, с которой данный процессорный модуль работает чаще других, в его локальную память. 
Рис. 6.6. Самый длинный путь в гиперкубе
CC-NUMA (Cache-Coherent Non-Uniform Memory Access, неоднородный доступ к памяти с обеспечением когерентности кэшей). В этой архитектуре адаптеры межмодульных соединений снабжаются собственной кэшпамятью, которая используется при обращениях к ОЗУ других модулей. Основная деятельность центрального коммутатора и каналов связи состоит в поддержании когерентности этих кэшей [www.ibm.com NUMA-Q]. Понятно, что обе эти архитектуры не решают в корне проблемы неоднородности
доступа: для обеих можно построить такую последовательность межпроцессорных
взаимодействий, которая промоет1 все кэши и перегрузит межмодульные связи,
а в случае СОМА приведет к постоянной перекачке страниц памяти между модулями.
То же самое, впрочем, справедливо и для симметричных многопроцессорных
систем с общей шиной.
В качестве резюме можно лишь подчеркнуть, что масштабируемость
(отношение производительности системы к количеству процессоров) многопроцессорных
систем определяется в первую очередь природой задачи и уровнем параллелизма,
заложенным в использованный для решения этой задачи алгоритм. Разные типы
многопроцессорных систем и разные топологии межпроцессорных соединений
пригодны и оптимальны для различных задач.
Промывание кэша— довольно распространенный термин. Это последовательность
обращении, которая намного больше объема кэша и в которой нет ни одного
повторного обращения к одной и той же странице, или очень мало таких обращении.
