Теория операционных систем
Внешние устройства
| Митрофан. Эта? Прилагательна. Правдин. Почему ж? Митрофан. Потому что она приложена ксвоему месту. Вон у чулана шеста неделя дверь стоит еще не навешана:так та покамест существительна Д. Фонвизин |
Все без исключения прилохсения вычислительных систем, так или иначе,
связаны с использованием внешних, или
периферийных устройств. Даже чисто
вычислительные задачи нуждаются в устройствах для ввода исходных данных
и вывода результата. Без преувеличения можно сказать, что процессор, не
имеющий никаких внешних устройств, абсолютно бесполезен.
У вычислительных систем первых поколений набор периферийных устройств
часто исчерпывался упомянутыми устройствами для ввода исходных данных
и вывода результата вычислений, поэтому до сих пор модули ОС, работающие
с периферией, называют подсистемой ввода-вывода (input/output
subsystem). У большинства современных компьютеров набор внешних
устройств весьма обширен, и функции многих из них не могут или лишь с
определенной натяжкой могут быть описаны как ввод и вывод.
С функциональной точки зрения внешние устройства, подключаемые к современным
компьютерам, можно разделить на следующие категории (приведенную классификацию
вряд ли можно считать исчерпывающей, а порядок перечисления не является
критерием важности данного типа устройств).
Например, у бортового компьютера самолета сенсорными устройствами могут
являться гироскопы или другие датчики ориентации, трубка Пито (датчик,
определяющий скорость самолета относительно воздуха), радар и терминал
глобальной системы позиционирования, а исполнительными устройствами —
шаговые электромоторы, управляющие рулевыми плоскостями, топливные насосы
двигателей и т. д.
Все перечисленные устройства либо передают информацию центральному процессору
(и, таким образом, могут быть объявлены устройствами
ввода), либо получают информацию от него (устройства
вывода), либо могут как передавать, так и принимать информацию
(устройства ввода-вывода). Эта классификация может показаться неестественной,
потому что в соответствии с ней в одну категорию попадают столь функционально
неродственные устройства, как сетевой адаптер и жесткий диск (устройства
ввода-вывода), или печатающее устройство и рулевая машинка летательного
аппарата (устройства вывода), однако разработчику операционной системы
во многих случаях этой классификации оказывается достаточно.
Нередко, впрочем, в эту классификацию вводят еще один уровень: устройства
ввода делят на пассивные (выдающие данные только в ответ на явные запросы
центрального процессора) и активные, или генераторы
событий, которые могут порождать данные тогда, когда их об этом
явно не просили. Ко второй категории относятся интерактивные устройства
ввода (клавиатура, мышь), сетевые адаптеры, таймеры различного рода, а
также многие датчики управляющих систем.
Доступ к внешним устройствам
С точки зрения центрального процессора и исполняющейся на нем программы, внешние устройства представляют собой наборы специализированных ячеек памяти или, если угодно, регистров. У микроконтроллеров эти ячейки памяти представляют собой регистры центрального процессора, у процессоров общего назначения регистры устройств обычно подключаются к шинам адреса и данных ЦПУ. Устройство имеет адресный дешифратор. Если выставленный на шине адрес соответствует адресу одного из регистров устройства, дешифратор подключает соответствующий регистр к шине данных (рис. 9.1). Таким образом, регистры устройства получают адреса в физическом адресном пространстве процессора.

Рис. 9.1. Подключение внешнего устройства к шине
Два основных подхода к адресации этих регистров — это отдельное адресное
пространство ввода-вывода и отображенный в
память ввод-вывод (memory-mapped I/O), когда память и регистры
внешних устройств размещаются в одном адресном пространстве. В первом
случае для обращения к регистрам Устройств используются специальные команды
IN и OUT. Во втором
случае Могут использоваться любые команды, способные работать с операндами
в памяти. Как правило, даже в случае раздельных адресных пространств,
для обмена данными с памятью и внешними устройствами процессор использу-ет
одни и те же шины адреса и данных, но имеет дополнительный сигнал адресной
шины, указывающий, какое из адресных пространств используется в данном
конкретном цикле.
Любопытный гибридный подход, сочетающий преимущества обоих вышеназванных,
предоставляют микропроцессоры с системой команд SPARC v9 У этих процессоров
команды имеют поле, служащее селектором адресного пространства. Этот селектор,
в частности, может использоваться для выбора адресного пространства памяти
или ввода-вывода. Благодаря этому, с одной стороны, можно применять для
работы с регистрами портов любые команды работы с памятью, как при отображенном
в память вводе-выводе, и в то же время полностью задействовать адресное
пространство памяти.
Два основных подхода к выделению адресов внешним устройствам — это фиксированная
адресация, когда одно и то же устройство всегда имеет одни и те
же адреса регистров, и географическая адресация,
когда каждому разъему периферийной (или системной, если внешние устройства
подключаются непосредственно к ней) шины соответствует свой диапазон адресов
(рис. 9.2). Географически можно распределять не только адреса регистров,
но и другие ресурсы — линии запроса прерывания, каналы ПДП.

Рис. 9.2. Фиксированная и географическая адресация
Географическая адресация обладает свойством, которое на первый взгляд
кажется противоестественным: перемещение платы устройства в другой разъем
приводит к необходимости переконфигурации ОС (а в некоторых случаях, например,
если перемещенная плата была контроллером загрузочного диска, а вторичный
загрузчик или процедура инициализации ядра недостаточно сообразительны,
может даже привести к ошибкам при загрузке). Однако этот способ распределения
адресного пространства удобен тем. тго исключает возможность конфликта
адресов между устройствами разных производителей или между двумя однотипными
устройствами (с этой проблемой должен быть знаком каждый, кто пытался
одновременно установить в компьютер сетевую и звуковую карты конструктива
ISA). Большинство периферийных шин современных
мини- и микрокомпьютеров, такие, как PCI, S-Bus и др., реализуют географическую
адресацию.
Многие современные конструктивы требуют, чтобы кроме регистров управления
и данных устройства имели также конфигурационные регистры, через обращение
к которым ОС может получить информацию об устройстве: фирму-изготовителя,
модель, версию, количество регистров и т. д. Наличие таких регистров позволяет
ОС без вмешательства (или с минимальным вмешательством) со стороны администратора
определить установленное в системе оборудование и автоматически подгрузить
соответствующие управляющие модули.
Простые внешние устройства
| У кошки четыре ноги - Вход, выход, земля и питание |
По-видимому, самым простым из мыслимых (а также и из
используемых) внешних устройств является порт вывода.
Такие устройства являются стандартным компонентом большинства микропроцессорных
систем. У микропроцессоров первых поколений порты реализовались отдельными
микросхемами, у современных микроконтроллеров они обычно интегрированы
в один кристалл с процессором.
Порт вывода представляет собой регистр и несколько выходных контактов,
называемых на жаргоне микроэлектронщиков "ногами". В литературе
входные и выходные контакты микросхем обычно называют просто входами и
выходами. Количество выходов порта, как правило, соответствует, и никогда
не превосходит количества битов в регистре. Если в бит регистра записан
ноль, напряжение на выходе порта будет низким, а если единица, то, соответственно,
высоким. Большинство современных микропроцессорных комплектов используют
так называемые ТТЛ-совместимые напряжения,
когда нулю соответствует напряжение 0 В, а единице — 5 В или, при работе
от источника питания с более низким напряжением, напряжение этого самого
источника (рис. 9.3).
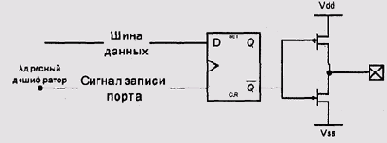
Рис. 9.3. Принципиальная схема ТТЛ-совместимых выходных каскадов порта вывода (здесь и далее Vss — высокое напряжение питания, Vdd — ноль)
Поскольку и внутри процессора для представления нулей
и единиц также используется высокое и низкое напряжение, порт полезен
прежде всего тем, что имеет регистр — чтобы удержать напряжение на выходе,
npouecconv достаточно один раз установить значение регистра.
Кроме того, польза от порта состоит в том, что поддержание напряжени на
выходе может потребовать пропускания через этот выход тока. Порты современных
микроконтроллеров имеют внутреннее сопротивление около 200 Ом и способны
без вреда для себя пропустить через вывод ток до 25 мА. Выводы шин адреса
и данных микропроцессоров, как правило, рассчитаны на гораздо меньшие
токи. Кроме того, порты часто имеют встроенные механизмы защиты от короткого
замыкания, статического электричества и т. д.
Применения порта вывода многообразны. Например, к нему можно присоединить
светодиод и получить лампочку, миганием которой можно программно управлять
(такие диоды часто используются при отладке программ для микроконтроллеров
— вместо диагностической печати).
Присоединив к выводу порта динамик, можно издавать различные звуки — впрочем, чтобы получился именно звук, а не одиночный щелчок, центральный процессор должен периодически записывать в соответствующий бит порта то ноль, то единицу. Применяя широтно-импульсную модуляцию (т. е. манипулируя относительными продолжительностями периодов высокого и низкого напряжений) таким способом можно генерировать не только прямоугольный меандр, но и сигналы более сложной формы и, соответственно, звуки различного тембра. Используя переменный период, можно генерировать сигналы с частотой, не кратной тактовой частоте центрального процессора или таймера, применяемого для синхронизации (пример 6.1). Изменяя период сигнала с помощью достаточно сложных алгоритмов, можно даже получать отношение тактовой частоты и частоты сигнала, равное иррациональному числу.
Впрочем, сигналы, порожденные с помощью вышеперечисленных
приемов, будут состоять не только из сигнала заданного тембра и частоты,
по и из гармоник тактовой частоты. Если последняя частота достаточно высока,
с этим можно смириться в надежде на то, что динамик не сможет се воспроизвести,
а слушатель — уловить.
Кроме того, к выводу порта можно присоединить внешнюю цифровую, аналоговую
или электромеханическую схему (например, шаговый электродвигатель), которая
будет выполнять какую-то полезную работу. Таким образом, порт вывода,
как правило, не является внешним устройством сам по себе, а служит интерфейсом
между микропроцессором и собственно внешним устройством.
Другое столь же простое устройство — это порт ввода.
Порт ввода также состоит из регистра и нескольких входных линий, соответствующих
битам реги~ стра (рис. 9.4). Бит регистра имеет значение 0, если на вход
подано низко6 напряжение (точнее говоря, если во время последнего цикла
тактового генератора порта на вход было подано низкое напряжение) и, наоборот,
единицу — если высокое. Понятно, что напряжение практически никогда не
соответствует в точности 0 или 5 В, поэтому в спецификациях портов ввода
всегда указывают диапазон напряжений, которые считаются нулем (например,
от 0 до 0.2 В) и единицей (например, от 4.5 до 5 В), для промежуточных
же напряжений значение соответствующего бита не определено (а на практике
определяется случайными факторами). Регистр порта ввода часто называют
регистром-защелкой (latch register), потому что основная его функция —
зафиксировать напряжения на входах в определенный момент времени и передать
их центральному процессору в виде однозначно (пусть и негарантированно
правильно) определенных значений.
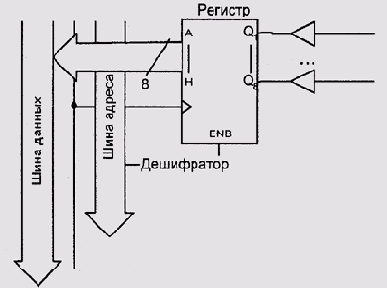
Рис. 9.4. Порт ввода
Разработчики микросхем часто совмещают входы портов
ввода и выходы портов вывода, создавая таким образом комбинированное устройство
— порт ввода-вывода. Такое устройство должно
быть существенно сложнее, чем простая комбинация порта ввода и порта вывода.
Если порт вывода пытается установить на определенном выходе высокое напряжение,
а другое Устройство пытается установить низкое, в соответствии с законом
Ома это приведет к возникновению электрического тока. Внутреннее сопротивление
типичного мпкроконтроллерного порта составляет около 200 Ом. При разности
напряжений в 5 В это соответствует упоминавшемуся выше предельно Допустимому
току в 25 мА: таким образом, устройство с нулевым внутренним сопротивлением
все-таки может выставить ноль, но попытка сделать это на нескольких линиях
одновременно приведет к перегрузке схем питания контроллера. В любом случае,
большие токи приводят к потерям энергии и разогреву схемы, поэтому без
крайней необходимости их лучше избегать. Если мы хотим использовать одни
и те же "ноги" микросхемы как для ввода, так и для вывода, мы
должны иметь возможность контролируемого включения выходных каскадов порта
вывода.
Отключаемые выходные каскады называются тристабильными, а третье, отключенное,
состояние выхода — высокоимпедансным. Тристабильные выходы используются
не только для реализации двунаправленных контактов микросхем, но и для
подключения устройств к шине: устройство, перешел шее в третье состояние,
освобождает шину и позволяет какому-то другому задатчику выставлять на
ней свои данные. Для управления переводом выходов в высокоимпедансное
состояние, порт ввода-вывода должен иметь еще один регистр, называемый
регистром или маской направления данных (data direction register) (рис.
9.5).
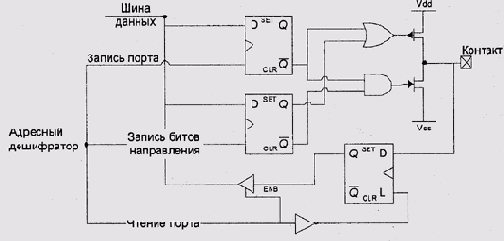
Рис. 9.5. Принципиальная схема порта ввода-вывода
Единица в разряде этого регистра обычно соответствует
переводу соответствующего вывода в третье состояние, дающее возможность
использовать этот контакт для ввода. Таким образом, даже такое простое
устройство, как порт ввода-вывода, имеет целых три регистра: два регистра
данных (многие реализации портов размещают эти два регистра по одному
адресу: при чтении обращение происходит к защелке порта ввода, а при записи
-- к регистру порта вывода) и один управляющий. Более сложные устройства
обычно также имеют один или несколько регистров данных и один или несколько
управляющих регистров. Устройства, передающие и принимающие большие объемы
данных (контроллеры жестких дисков, сетевые интерфейсы, видеоадаптеры)
часто вместо одного регистра данных снабжаются буфером памяти, отображенным
на адреса памяти процессора.
Вместо управляющих регистров у некоторых сложных устройств есть командный
регистр. Центральный процессор передает через этот регистр последовательность
команд, а устройство их исполняет и, возможно, передает последовательность
ответов.
Порты передачи данных
Порты ввода-вывода преимущественно используются для управления про-тыми
внешними устройствами: если бит установлен, мотор крутится (заслонка открыта,
нагреватель включен и т. д.), и наоборот. Если же уст-оойство более сложное,
и работа с ним предполагает обмен последовательностями команд и ответов,
или просто большими объемами данных, простой порт оказывается не очень
удобен.
Основная проблема при использовании простого порта в качестве средства
обмена данными состоит в том, что принимающему устройству необходимо знать,
выставило ли передающее устройство на своих выходах новую порцию данных,
или еще нет. Три основных подхода к решению этой проблемы называются синхронной,
асинхронной и изохронной передачами данных.
При синхронной передаче мы либо предоставляем
дополнительный сигнал, строб (рис. 9.6), либо
тем или иным способом передаем синхросигналы по тем же проводам, что и
данные. Например, можно установить, что каждая следующая порция данных
должна хотя бы одним битом отличаться от предыдущей. При этом необходимо
предусмотреть протокол, посредством которого передатчик будет кодировать,
а приемник декодировать повторяющиеся последовательности символов. Например,
второй символ из пары одинаковых последовательных символов можно заменять
на специальный символ повторения, впрочем, в этом случае нам необходимо
предусмотреть и способ кодирования символа, совпадающего по значению с
символом повторения. Реальные способы совмещения кодирующих и синхронизующих
сигналов в одном проводе относительно сложны и их детальное обсуждение
было бы более уместно в книге, посвященной сетевым технологиям. Некоторые
простые способы кодирования с таким совмещением мы рассмотрим в разд.
Шины
Описанные в предыдущем разделе порты передачи данных соединяют друг с другом два устройства. Однако часто оказывается целесообразно подключить к одному порту передачи данных несколько устройств, причем необязательно однотипных. Каждая передаваемая по такому порту порция данных обязана сопровождаться указанием, какому из подключенных устройств она предназначена — адресом или селектором устройства. Такие многоточечные порты называются шинами (bus) (рис. 9.14). Как и двухточечные порты передачи данных, шины бывают синхронные и асинхронные, а также последовательные и параллельные. При описании шин термины "синхронный" и "асинхронный" используют в ином значении, чем при описании портов. Асинхронными называют шины, в которых ведомое устройство не выставляет (или не обязано выставлять) сигнал завершения операции, а синхронными, соответственно, шины, где ведомый обязан это делать.
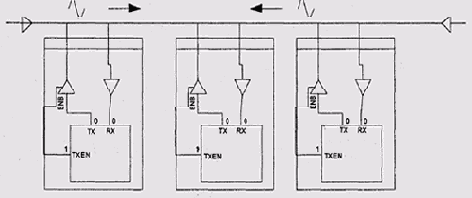
Рис. 9.14. Шина
Подключение N устройств двухточечными портами требует, чтобы центральный
процессор имел N приемопередатчиков, использование же многоточечного порта
позволяет обойтись одним. В частности, за счет этого Удается уменьшить
количество выводов микросхемы процессора или периферийного контроллера.
Кроме того, при удачном размещении устройств Можно получить значительный
выигрыш в общей длине проводов и, таким образом, например, уменьшить количество
проводников на печатной плате. Во многих случаях это приводит к столь
значительному снижению общей стоимости системы, что оказывается целесообразным
смириться с усложнением протокола передачи данных и другими недостатками,
присущими шинной архитектуре.
Основной недостаток шин состоит в том, что в каждый момент времени только
одно устройство на шине может передавать данные. Если у двухточечных портов
часто оказывается целесообразным реализовать полподуплексный обмен данными
при помощи двух комплектов линий (один прием, другой на передачу, как
в описанном выше RS232), то в случае шинной топологии это невозможно.
Поэтому шины бывают только полудуплексные или симплексные.
Невозможность параллельно осуществлять обмен с двумя устройствами может
привести к падению производительности по сравнению с собственным портом
обмена данными у каждого устройства. Если устройства не занимают пропускную
способность каналов передачи полностью, проигрыш оказывается не так уж
велик. Благодаря этому шины широко используются даже в ситуациях, когда
только одно устройство имеет возможность инициировать обмены данными.
Если передачу данных могут инициировать несколько устройств (как, например,
в случае системной шины с несколькими процессорами и/или контроллерами
ПДП), шинная топология оказывается наиболее естественным выбором. Такая
конфигурация требует решения еще одной проблемы: обеспечения арбитража
доступа к шине со стороны возможных инициаторов обмена — задатчиков шины
(рис. 9.15). Методы арбитража отличаются большим разнообразием.
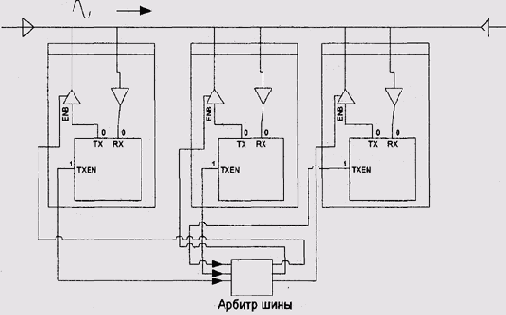
Рис. 9.15. Шина с несколькими задатчиками
Разрешение коллизий в I2С
Синхронная последовательная шина I2С (Inter-Integrated Circuit
— [протокол соединения] между интегральными схемами) широко применяется
для соединения цифровых микросхем во встраиваемых приложениях [Paret-Fenger
1997]. Шина состоит из двух линий, строба и данных (рис. 9.16). Предполагается,
что все подключенные к шине устройства имеют общие шины питания и нуля.
Хотя бы одно из устройств шины должно быть ведущим (master).
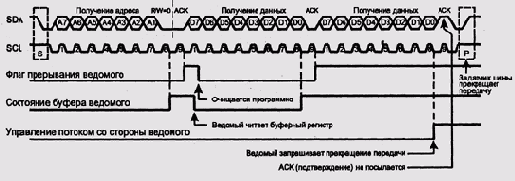
Рис. 9.16. Временная диаграмма шины I2С
Ведущее устройство генерирует стробовый сигнал и инициирует
все передачи данных по шине. Частота строба может составлять 100 или 400
кГц или 1 МГц. Все передачи начинаются с того, что ведущий передает адрес
целевого устройства. В зависимости от конфигурации адрес может состоять
из семи или десяти бит. Восьмой или, соответственно, одиннадцатый бит
адреса содержит указание на тип запроса: чтение или запись. Услышав свой
адрес, ведомое устройство генерирует на линии стробового сигнала импульс
подтверждения.
Импульса подтверждения может не последовать не только при отсутствии устройства
с таким адресом, но и, например, если соответствующее устройство не готово
принять или передать данные.
Если подтверждение все-таки последовало, начинается передача данных. Данные
состоят из восьми бит. Если запрос был на чтение, данные передает ведомое
устройство, если на запись — ведущее.
Спецификации I2С допускают конфигурацию с несколькими ведущими.
Чтобы избежать конфликтов, ведущее устройство генерирует стробовый сигнал
только во время инициируемых им передач данных, в остальное же время тихо
слушает линию и может, при запросе другого ведущего, стать ведомым.
Из-за того, что сигнал распространяется по шине с конечной скоростью,
да и внутренняя логика ведущих устройств срабатывает не мгновенно, возможна
ситуация, когда два ведущих с небольшим интервалом попытаются захватить
шину. Эта ситуация называется коллизией (collision — дословно, столкновение).
Протоколы арбитража большинства других шин считают коллизией любую попытку
двух устройств одновременно вести передачу. I2С предлагает
более слабое определение коллизии — в соответствии со спецификациями этой
шины, коллизия происходит, только когда ведущие пытаются выставить на
шине данных разные значения. Таким образом, если два (или даже больше!)
ведущих отправят один и тот же запрос одному и тому же ведомому, это не
будет считаться коллизией!
Механизм арбитража, используемый I2С, отличается крайней простотой.Ведущий,
пытающийся выставить на линии данных 1 в то время, как другой ведущий
пытается выставить там же 0, считается проигравшим арбитраж. Он должен
остановить передачу и дождаться, пока победитель завершит обмен и освободит
шину.
Важно подчеркнуть, что протокол арбитража не может просто объявить обоим
устройствам, что дескать, случилась коллизия — если оба устройства прeкратят
передачу и, не предприняв более ничего, сделают вторую попытку, мы получим
живую блокировку! Странное, на первый взгляд, определение коллизии принятое
в I2С, дает победителю арбитража возможность продолжить передачу
после обнаружения коллизии, исключая, таким образом, для него возможность
повторной коллизии после повторной попытки передачи, и, соответственно,
исключая опасность живой блокировки.
Видно, что спецификации I2С допускают ситуацию, когда два устройства
пытаются установить на шине разные напряжения. Чтобы избежать при этом
больших токов, стандарт устанавливает несколько необычный способ подключения
устройств к шине (рис, 9.17). Устройство, пытающееся выставить 1, должно
просто отключить свои выходные каскады — тогда через резистор Rp (для
питания 5 В его сопротивление должно быть не менее 1,7 кОм) конденсатор
Сb будет заряжен до напряжения питания. Только при попытке выставить ноль
устройство должно пропускать через себя ток.

Рис. 9.17. Схема приемопередатчиков I2С
Необходимость обнаружения коллизий и арбитража накладывает ограничения
на физический размер шины: сигналы распространяются по шине с конечной
скоростью, а любые два конфликтующих устройства должны узнать коллизии
за время, меньшее чем минимальный цикл передачи данных (цикл шины). Описанная
выше шина 12С предназначена для низкоскоростной связи в пределах одной
печатной платы, поэтому для нее эта проблема не актуальна, однако для
локальных сетей, протяженность которых составляет сотни метров или даже
километры, и для системных шин компьютеров с большим количеством процессоров
и банков памяти это превращается в серьезную проблему. Кроме того, большое
количество коллизий само по себе снижает производительность системы.
Один из основных путей решения этой проблемы упоминался в разд. Многопроцессорные
архитектуры: замена шины центральным коммутатором, либо более или
менее сложной сетью коммутаторов. Устройства соединяются с ближайшим коммутатором
полнодуплексными двухточечными каналами, такие же каналы используются
для соединения коммутаторов друг с другом, а все коллизии возникают и
разрешаются только внутри коммутаторов.
Внутренняя шина коммутатора, как правило, имеет большую пропускную способность,
чем внешние соединения — у многих практически используемых коммутаторов
несколько внутренних шин, поэтому разрешение коллизии внутри коммутатора
часто состоит в отправке данных другим путем (рис. 9.18).
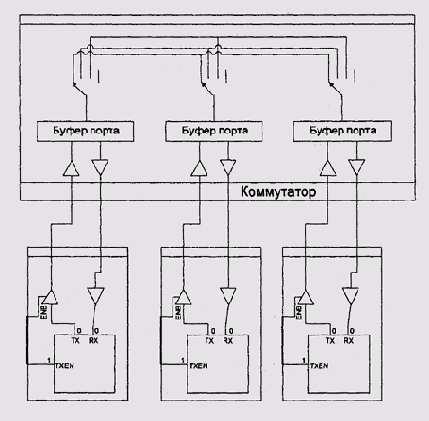
Рис. 9.18. Коммутатор с несколькими внутренними шинами
Таким образом, коммутируемая магистраль позволяет уменьшить производительности,
порождаемые коллизиями, и повысить реальную пропускную способность магистрали.
Однако коммутируемая магистраль значительно повышает общую стоимость системы
и далеко не всегда оправдана этой точки зрения.
Применяются также гибридные топологии, когда все или некоторые устройства
подключаются к коммутатору полудуплексным портом или коротки участком
шины — при этом возможны локальные коллизии, но их гораздо меньше, чем
при единой шине. Гибридная топология позволяет использовать устройства
с одними и теми же приемопередатчиками как в обычной шинной, так и в коммутируемой
топологии (рис. 9.19). В частности, именно такую гибридную топологию имеют
описанные в разд. Многопроцессорные
архитектуры многопроцессорные системы IBM NUMA-Q и SGI Origin — процессоры
и память подключаются к локальной шине процессорного модуля, а сами модули
соединяются коммутируемой сетью.
Гибридная топология также позволяет снизить стоимость системы по сравнению
с полностью коммутируемой сетью — коммутаторы можно устанавливать только
в тех участках шины, где расстояния или большое количество коллизий становятся
проблемой. В таких сетях часто используются двухпортовые коммутаторы,
называемые мостами (bridge). Так же называются и адаптеры, используемые
для соединения двух шин с разными протоколами.
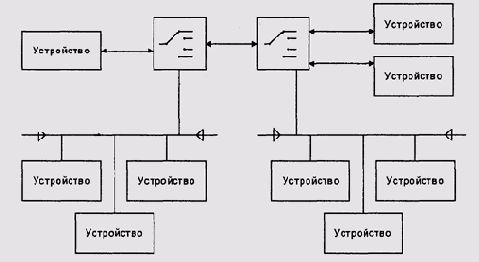
Рис. 9.19. Гибридная топология
Во всех перечисленных случаях сохраняется логическая шинная топология:
каждый потенциальный задатчик шины может обращаться по адресу к любому
другому устройству, поэтому разработчикам программного обеспечения не
всегда интересны детали реализации физического подключения устройств.
Шины (как физические, так и логические) находят широчайшее применение
в вычислительной технике. В частности, один из важнейших сетевых протоколов
канального уровня, Ethernet, начинал свою карьеру как последовательная
шина с совмещением синхросигнала и данных, да и современные реализации
этого протокола, хотя физически и представляют собой коммутируемую или,
все реже и реже гибридную сеть, с логической точки зрения по-прежнему
являются шиной.
Связь центральных процессоров с банками ОЗУ и внешними устройствами в
подавляющем большинстве современных компьютеров осуществляется параллельными
стробируемыми шинами.
В вычислительных системах общего назначения чаще всего используется топология
с двумя или более шинами. Процессоры и память связаны системной
шиной. К этой шине также присоединены один или несколько адаптеров
периферийных шин, к которым и подключаются
внешние устройства (рис. 9.20). Основное преимущество такого решения состоит
в том, что одни и те же периферийные устройства могут использоваться в
вычислительных системах с различными системными шинами. Высокоскоростные
устройства, например дисковые адаптеры FC-AL у серверов или графические
контроллеры у персональных компьютеров, иногда подсоединяются к системной
шине непосредственно.
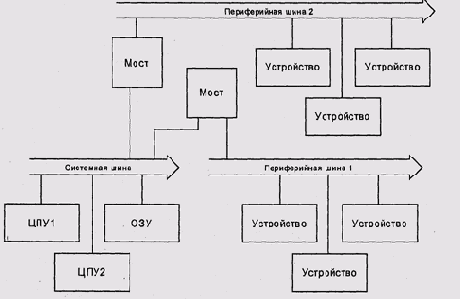
Рис. 9.20. Системная и периферийные шины
Шина PCI
Шина PC/ (Peripherial Component Interconnect), разработанная фирмой Intel
в настоящее время используется в вычислительных системах разного уровня,
начиная от персональных компьютеров с архитектурами х86 и PowerMac и заканчивая
старшими моделями серверов Sun Fire. В конструктиве PCI исполняется множество
различных периферийных устройств— сетевые карты, адаптеры SCS/, графические
и звуковые карты, платы видеоввода и видеовывода и лр [PC Guide PCI].
PCI не рассчитана на использование в качестве системной шины. Напротив
спецификации шины предполагают ее подключение к процессорам и памяти через
специальное устройство, мост системной шины (host-to-PCI bridge) (рис.
9.21). Это позволяет использовать PCI в системах, основанных на различных
процессорах, таких, как х86, Power, SPARC.
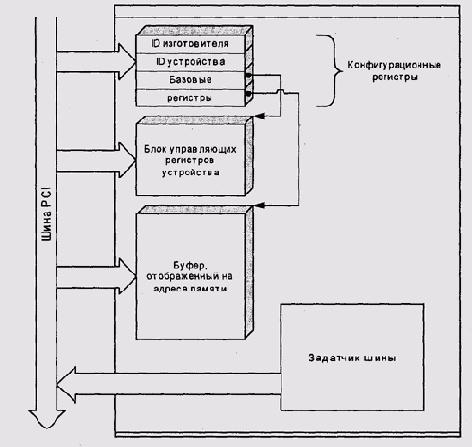
Рис. 9.21. Мост системной шины
PCI предусматривает как монтаж устройств на материнскую
плату системы, так и их исполнение в виде плат расширения. Шина допускает
подключение не более 4 устройств. По исходным спецификациям, не более
трех из них может подключаться через внешние разъемы, однако это не мешает
многим поставщикам оборудования изготавливать платы с четырьмя внешними
разъемами без мостов. Предусмотренный стандартом способ обхода указанного
ограничения состоит в установке в системе нескольких адаптеров PCI, через
собственные мосты системной шины или через PCI-to-PCI bridge. Допустимы
также мосты, подключающие другие периферийные шины, например ISA, USB
и т. д (рис. 9.22).
Каждое устройство на шине обязано иметь набор конфигурационных регистров,
адресуемых географически (по номерам шины и разъема). Эти регистры содержат
информацию об изготовителе и модели устройства. Кроме того, устройство
может иметь до шести базовых адресных регистров, указывающих на связанные
с устройством адресуемые объекты — блоки регистров ввода-вывода и отображенные
на адреса ОЗУ буферы (рис. 9.23). Адреса этих объектов определяются динамически
во время инициализации системы загрузочным монитором. Как правило, эти
адреса также распределяются по географическому принципу.
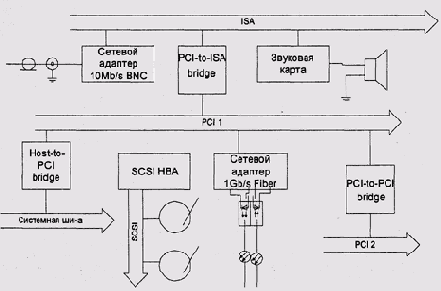
Рис. 9.22. Мосты PCI-to-PCI и PCI-to-ISA
Устройство может работать в пассивном режиме (передавая данные по запросам процессоров) или через ПДП в режиме задатчика шины. Во втором случае мост системной шины преобразует выставляемые устройством адреса PCI в адреса системной шины. Современные спецификации шины (т. н. PCI64) допускают 32-разрядную адресацию для регистров устройств и 32- или 64-битную адресацию для отображенных в память буферов и при работе по ПДП.
Шина SCSI
Среди других практически важных применений шин необходимо упомянуть стандарт
SCS/ (Small Computer System Interface — системный интерфейс малых компьютеров),
наиболее известный как интерфейс для подключения жестких дисков, но используемый
для подключения широкого спектра высокоскоростных устройств (табл. 9.3),
в том числе и не являющихся устройствами памяти, например, сканеров [Гук
2000].
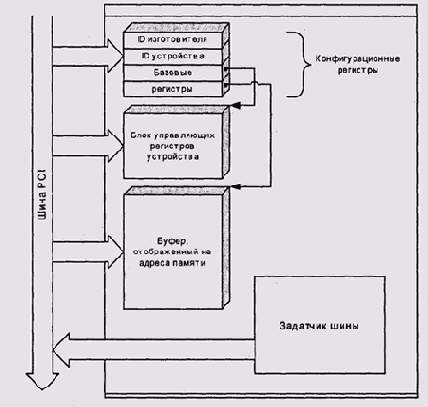
Рис. 9.23. Конфигурационные и рабочие регистры устройства PCI
Современные спецификации SCSI по структуре аналогичны спецификациям сетевых протоколов и состоят из трех уровней: команд, протокола и соединений. Уровень команд определяет формат и семантику команд и ответов на них, т. е. приблизительно соответствует тому, что в сетевых протоколах называется прикладным уровнем. Уровень протокола определяет способ передачи команд и ответов и соответствует канальному уровню сетевых протоколов. И, наконец, уровень соединений определяет физическую реализацию линий передачи данных (способ кодирования данных, допустимые токи и напряжения, конструкцию разъемов и т. д.), т. е. соответствует физическому уровню [www.t10.org architecture, Friedhelm/Shmidt 1997]. Сетевой (в данном случае описывающий способ адресации устройств) и транспортный уровни в спецификациях SCSI также присутствуют, хотя и в рудиментарном виде.
Таблица 9.3. Типы устройств SCSI, возвращаемые командой INQUIRY, цит. по [www.t10.org commands]
| Код | Описание |
| 00h | Устройство прямого доступа (например, магнитный диск) |
| 01h | Устройство последовательного доступа (например, магнитная лента) |
| 02h | Печатающее устройство |
| 03h | Процессорное устройство |
| 04h | Устройство однократной записи (например, некоторые оптические диски) |
| 05h | CD-ROM |
| 06h | Сканер |
| 07h | Оптическое запоминающее устройство (например, некоторые оптические диски) |
| 08h | Устройство с автоматической заменой носителя (например, jukebox) |
| 09h | Коммуникационное устройство |
| 0Ah-0Bh | Определено ASC IT8 |
| 0Ch | Контроллер массива запоминающих устройств (например, RAID) |
| 0Dh | Устройство enclosure services (мост к шине другого типа) |
| 0Eh-1Eh | Зарезервировано |
| 1Fh | Неизвестный или неопределенный тип устройства |
На физическом уровне SCSI представляет собой параллельную
шину с 8-ю или 16-ю (так называемая Wide SCSI) линиями передачи данных.
Современные реализации стандарта обеспечивают скорости передачи данных
до 160 Мбит/с. Стандартом SCSI III предусмотрены также реализации в виде
последовательной шины IEEE 1394 или волоконно-оптических колец FC-AL (Fiber
Channel Arbitrated Loop — волоконно-оптический канал [в виде] арбитрируемого
кольца). Fiber Channel допускает объединение нескольких колец коммутаторами,
подключение до 127 устройств, общую длину сети, измеряемую несколькими
сотнями метров и скорости передачи до 1Гбит/с.
Обмен данными по шине происходит не байтами и даже не словами, а кадрами,
которые могут содержать команды, информацию о состоянии устройства (sense
data) или собственно данные. Формат кадров и способ разрешения коллизий
зависит от используемого типа соединений — в этом смысле разделение уровня
соединений и уровня протокола не реализовано в полной мере. Каждый кадр
содержит адреса отправителя и получателя. Каждое устройство имеет собственный
адрес, называемый SCSI target ID. У старых версий протокола этот адрес
был 3-битным, допуская адресацию восьми устройств, у современной версии
(Ultra-SCSI или SCSI III) адрес 4- или 5-битный. Адаптер, через который
шина SCSI подключается к системной или периферийной шине компьютера —
НВА (Host Bus Adapter— адаптер системной шины) — также считается устройством
и обычно имеет ID, равный, в зависимости от разрядности адреса, 7, 15
или 127.
Устройство, имеющее один target ID, может содержать
несколько логически устройств, идентифицируемых номерами логических устройств
(LUN — Logjc Unit Number). Спецификации протокола
предусматривают два байта для код рования LUN,
но реальное число логических устройств, поддерживаемых практике, обычно
невелико.
Устройства SCSI делятся на два типа: инициаторы (initiator) и целевые
ройства (target). Инициатор посылает команды, а целевое устройство их
полняет. Спецификация допускает, что в разных актах обмена данными инициатор
может становиться целевым устройством и наоборот, но в пределах одной
операции эти роли заданы однозначно. Как правило, НВА может выступать
только в роли инициатора, а периферийные устройства — только в роли целевых.
Блоки команд — CDB (Command Descriptor Block — блок описания команды)
— невелики по размеру и могут содержать 6, 8, 10, 12 или 16 байт. Различие
в длине обусловлено размером используемых в команде адресов: 6-байтовая
команда использует 21-битный адрес блока на устройстве и 8-битное поле
для длины требуемого блока данных, 8-байтовая — 32-разрядный адрес и 16-битное
поле длины, а более длинные команды— 32-разрядные адрес и длину. 16-байтовая
форма команды содержит, кроме 32-разрядных адреса и длины, также и 32-битное
поле параметра. Кроме того, команда обязательно содержит код операции
и поле управления. Под код операции отводится байт. Старшие три бита этого
байта кодируют формат SCB. Некоторые команды используют только один формат
SCB, другие допускают применение различных форматов (обычно с адресами
и полем длины различной разрядности). Кроме перечисленных в табл. 9.4,
различные типы устройств имеют собственные команды.
Блоки данных, в отличие от команд, имеют практически неограниченную длину.
Многие команды интерпретируют поле длины CDB как указанное в блоках. При
размере блока 512 байт это позволяет передать за одну операцию до 2 Тбайт
(1 Тбайт=1024 Гбайт) данных. На практике, пакет данных, передаваемых за
одну операцию шины, ограничен размерами буферов устройств, поэтому запросы
на передачу больших объемов данных обрабатываются в несколькр приемов.
Команда может либо принимать, либо передавать данные. В качестве данных
могут передаваться либо блоки параметров и ответов, либо собственно данные.
Существование команд, способных и передавать, и принимать данные, явно
запрещено спецификациями, поэтому в CDB предусмотрена только одна группа
полей описания буфера. Впрочем, операция может исполняться в виде последовательности
команд и поэтому может предусматривать двусторонний обмен данными.
Большинство команд требует от устройства более или менее длительных подготовительных
операций (перемещения головки, перемотки ленты), поэтому передача данных
не может следовать немедленно за командой. По этой причине большинство
современных устройств поддерживает очереди команд. Чтобы связать команду
с пришедшим на нее ответом, команды могут снабжаться тегом задачи. Устройство
способно параллельно исполнять несколько задач, а в рамках одной задачи
может быть исполнена последовательность команд.
Таблица 9.4. Список команд SCSI, поддерживаемых всеми устройствами, цит. по www.t10.org commands]
| Имя команды | Код | Тип | Описание |
| CHANGE DEFIKTTION | 40h | O | Изменить версию протокола, используемого устройством |
| COMPARE | 39h | O | Сравнить данные |
| COPY | 18h | O | Копировать данные внутри устройства или между устройствами |
| COPY AND VERIFY | 3Ah | O | Копировать данные с проверкой |
| INQUIRY | 12h | M | Проверить наличие устройства, его тип и поддерживаемые им операции |
| LOG SELECT | 4Ch | Включить сбор статистики | |
| LOG SENSE | 4Dh | O | Считать собранную статистику |
| MODE SELECT(6) | 15h | Z | Выбор режима работы устройства |
| MODE SELECT(10) | 55h | Z | |
| MODE SENSE(6) | 1Ah | Z | Считывание режима работы |
| MODE SENSE(10) | 5Ah | Z | |
| MOVE MEDIUM ATTACHED | A7h | Z | Для устройств с автоматической сменой носителя |
| PERSISTENT RESERVE IN | 5Eh | Z | Управление режимом блокировки устройства |
| PERSISTENT RESERVE OUT |
5Fh | Z | |
| PREVENT ALLOW MEDIUM REMOVAL | 1Eh | 0 | Заблокировать сменный носитель в устройстве |
| READ BUFFER | 3Ch | 0 | Чтение данных |
| READ ELEMENTSTATUS ATTACHED | B4h | Z | Для устройств с автоматической сменой носителя |
| RECEIVE DIAGNOSTIC RESULTS | 1Ch | O | Получить результаты самотестирования устройства |
| RELEASE (6) | 17h | Z | Разблокировка (освобождение) устройства |
| RELEASE (10) | 57h | z | |
| REPORT LUNS | A0h | O | Считывание списка логических устройств |
| REQUEST SENSE | 03h | М | Считывание статуса устройства |
| RESERVE(6) | 16h | Z | Блокировка (захват) устройства |
| RESERVE(10) | 56h | Z | |
| SEND DIAGNOSTIC | 1Dh | M | Запрос самотестирования устройства |
| TEST UNIT READY | 00h | M | Проверка готовности устройства |
| WRITE BUFFER | 3Bh | O | Запись данных |
Здесь:
M — реализация команды обязательна; O— реализация команды возможна (может быть реализована, а может и не быть); Z— реализация и семантика команды зависит от типа устройства.Устройства графического вывода
Если устройства графического ввода (сканеры, видеограбберы, цифровые
фотоаппараты) пока еще относительно редки (хотя, по мере развития цифровой
фотографии, положение быстро меняется), то устройствами графического вывода
снабжается каждый современный настольный и переносной компьютер. Многие
встраиваемые приложения также имеют хотя бы небольшие, но дисплеи, чаще
всего жидкокристаллические.
Два основных практически применяемых типа дисплейных устройств — это электронно-лучевые
трубки, используемые в кинескопах телевизоров и мониторах настольных
компьютеров, и уже упоминавшиеся жидкокристаллические
дисплеи. Устройства других типов — матрицы светодиодов и газоразрядные
("плазменные") панели пока что дороги в производстве, либо не
всегда приемлемы по качеству, поэтому — во всяком случае, на момент написания
этой книги — еще не находят массового применения.
Принцип действия ЭЛТ широко известен. Изображение в этих устройствах формируется
катодным лучом — пучком электронов, испускаемых отрицательно заряженным
электродом. Вспомогательные электроды и электромагниты фокусируют луч,
а два набора управляемых электромагнитов — катушки горизонтальной и вертикальной
развертки — отклоняют этот луч по вертикали и горизонтали (рис. 9.24).
Попадая на лицевую поверхность трубки — экран — электроны заставляют светиться
нанесенный на нее краситель-люминофор, формируя, таким образом, изображение.
Изменяя напряжение на катоде, можно управлять яркостью луча и, соответственно,
яркостью участка изображения. Люминофор светится еще какое-то время после
ухода луча с него. За счет этого, а также за счет инерционности человеческого
восприятия, изображение воспринимается как более или менее подвижная двумерная
картинка, а вовсе не как быстро движущийся световой "зайчик".
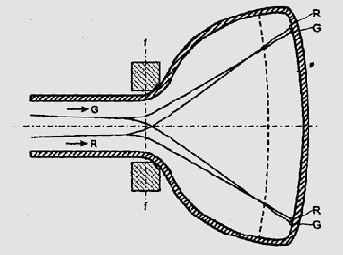
Рис. 9.24. Электронно-лучевая трубка
Для формирования цветного изображения используются три фокусируемых
со смещением катодных луча и маски, обеспечивающие попадание каждого из
лучей на участки предназначенного для него цветного люминофора.
Чтобы изображение занимало весь экран, луч (или тройка лучей) проводится
по сложной траектории, которая приведена на рис. 9.25. Генерация этой
траектории достигается простой подачей пилообразного напряжения на катушки
развертки. При этом частота "пилы" горизонтальной развертки
называется частотой строчной развертки, а вертикальной, соответственно,
частотой кадровой развертки. Соотношение кадровой и строчной частот равно
количеству строк в кадре (несколько строк приходится на кадровый гасящий
импульс, поэтому видимых строк на экране чуть меньше, чем следует из соотношения
частот).

Рис. 9.25. Развертка ЭЛТ
Катушки развертки не могут мгновенно изменить направление магнитного поля, поэтому и обратный ход луча как по вертикали, так и по горизонтали происходит не мгновенно. Чтобы луч на обратном ходе не был виден устройство управления ЭЛТ должно генерировать кадровый (для вертикально обратного хода) и строчный гасящие импульсы (рис. 9.26).
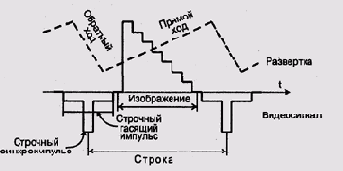
Рис. 9.26. Строка развертки ЭЛТ
Вертикальное разрешение изображения соответствует количеству видимых
строк на экране. Горизонтальное разрешение определяется двумя факторами:
частотой, с которой схемы управления ЭЛТ способны модулировать луч и,
у цветных мониторов, разрешением маски кинескопа. Второй параметр указывают
в паспортных данных кинескопов под названием размер
точки (dot pilch). У большинства мониторов первый параметр обычно
более или менее соответствует второму. Электронно-лучевые трубки громоздки,
создают сильные электромагнитные помехи и сами чувствительны к ним и,
наконец, имеют высокое энергопотребление, но они во много раз дешевле
всех альтернативных способов генерации изображений высокого качества и
высокого разрешения.
Жидкокристаллические экраны основаны на способности некоторых органических
соединений — жидких кристаллов — менять свою прозрачность и другие оптические
свойства под воздействием электрического поля. Жидкокристаллический экран
представляет собой две стеклянные или прозрачные пластиковые пластины
(обкладки), на которые нанесены полупрозрачные металлические электроды.
Пространство между пластинами заполнено жидким кристаллом. За пластинами
находится подложка — у черно-белых дисплеев зеркальная или черная, у цветных
дисплеев — цветная. Для повышения контрастности изображения подложка нередко
подсвечивается.
Подавая напряжение на электроды, контроллер ЖКД
может избирательно делать прозрачными те или иные участки экрана и, таким
образом, формировать различные изображения. Изменяя напряжение, можно
в определенных пределах управлять яркостью, или, скорее, контрастностью
изображения. В современных дисплеях высокого разрешения используется более
сложный способ формирования цветного изображения, чем просто разноцветная
подложка: в таких дисплеях используется жидкий кристалл, поворачивающий
плоскость поляризации проходящего через него света. Этот угол зависит
от напряжения на электродах и от частоты световой волны. Снабдив обкладки
экрана поляризационными фильтрами, можно управлять цветом участка экрана.
Формы электродов ЖКД отличаются большим разнообразием. Нередко применяются
прямоугольные матрицы точек, позволяющие создавать произвольные растровые
изображения. Однако многие приложения — часы, калькуляторы, простые дисплеи
— не требуют произвольных изображений, поэтому часто изготавливают пластины
с электродами сложной формы, соответствующей элементам цифр и букв и/или
различным пиктограммам.
ЖКД низкого разрешения дешевы, компактны, имеют низкое энергопотребление
и находят широкое применение в самых разнообразных устройствах — сотовых
и стационарных телефонах, калькуляторах, часах, измерительных и бытовых
приборах. Однако высококачественные цветные ЖКД большой площади представляют
собой весьма дорогостоящие устройства, цена которых составляет более половины
цены современных портативных компьютеров.
Подача напряжения на каждую пару электродов ЖКД отдельным контроллером
недопустимо дорога. К счастью, пара электродов представляет собой конденсатор,
который способен некоторое время без вмешательства извне сохранять электрический
заряд и, следовательно, изображение. Наличие у пиксела электрической емкости
позволяет свести поддержание изображения на жидкокристаллической матрице
к аналогу развертки ЭЛТ — периодическому сканированию электродов с подачей
на них напряжения, соответствующего яркости элемента изображения (рис.
9.27).
При изменении изображения емкость элементов матрицы скорее вредна — быстрая
перезарядка элемента требует больших токов, поэтому многие ЖКД, в том
числе и дисплеи старых переносных компьютеров, обладают высокой инерционностью
изображения. В современных высококачественных дисплеях каждый пиксел экрана
снабжается собственной усилительной схемой, способной быстро перезарядить
электроды. Такие экраны называются активной матрицей. Широкое распространение
получили активные матрицы с усилителями, реализованными на основе TFT
(Thin Film Transistor— тонкопленочный транзистор), нанесенных на обкладки
экрана.
Несмотря на коренное различие физических способов формирования изображения
в электронно-лучевых трубках и жидкокристаллических панелях, функции контроллера
этих устройств весьма похожи и сводятся к передаче значений яркости элементов
изображения с частотой, соответствующей частоте развертки дисплея. Контроллер,
предназначенный для работы с ЭЛТ, должен уметь также делать в потоке данных
паузы, соответствующие строчным и кадровым гасящим импульсам и должен
быть несколько сложнее. Однако общая структура графически контроллеров
для дисплеев различных типов удивительно похожа.
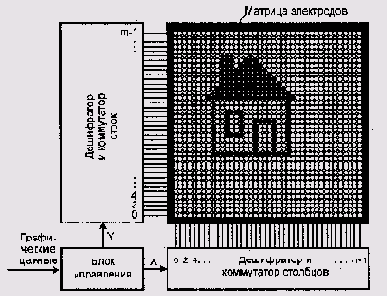
Рис. 9.27. Схема формирования изображения на жидкокристаллическом дисплее
Типичный графический контроллер (рис. 9.28) состоит из:
видеобуфера (frame buffer — буфер кадра) — блока памяти, элементы которого соответствуют пикселам дисплея; генератора тактовой частоты; собственно контроллера — устройства, которое передает содержимое видеобуфера, а также, если это необходимо, гасящие импульсы и синхросигналы аналоговым схемам управления дисплеем. ЦАП (цифро-аналогового преобразователя), который преобразует значения пикселов в аналоговый сигнал, и, если это необходимо, усилителей видеосигнала.Структура видеобуфера определяется цветовой глубиной дисплея. У черно-белых дисплеев обычно один бит соответствует одному пикселу, а один бант видеобуфера — восьми последовательным пикселам изображения. У черно-белых с градацией яркости ("черно-бело-серых") и цветных дисплеев видеобуфер должен иметь по несколько битов на пиксел.
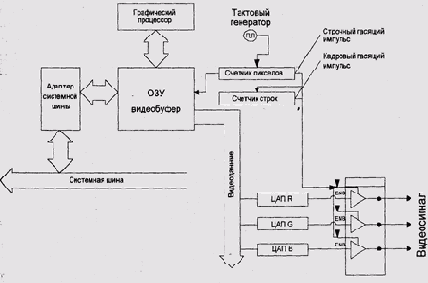
Рис. 9.28. Схема графического контроллера
Это достигается двумя способами. Первый состоит в организации
битовых плоскостей, когда в видеобуфере последовательно хранятся
сначала младшие биты значений пикселов, затем — вторые и т. д. (рис. 9.29).
При этом восемь последовательных пикселов описываются несколькими байтами,
размещенными в разных частях видеобуфера. Эта, немного странная на первый
взгляд, логика кодирования изображения удобна тем, что облегчает перенос
программного обеспечения, предназначенного для работы с черно-белыми дисплеями,
на цветные дисплеи.
Второй подход, чаще применяемый при больших цветовых глубинах, состоит
в кодировании одного пиксела одним или несколькими последовательными байтами
видеобуфера. Графические контроллеры современных персональных компьютеров
имеют цветовую глубину 24 или 32 бита, что соответствует трем или четырем
байтам на пиксел. Этого хватает, чтобы (с учетом Диапазона яркости современных
дисплеев) представить любой цвет, который человеческий глаз способен отличить
на дисплее от другого.
Контроллеры с такой цветовой глубиной обычно предоставляют по одному байту
для кодирования каждой из трех цветовых составляющих цветного изображения.
Устройства с меньшими цветовыми глубинами часто реализуют более сложную
схему кодирования цвета, называемую отображением
цветов (color mapping). Значение пиксела при этом представляет
собой индекс в специальной таблице, палитре. Элементы палитры — это значения
компонентов пиксела.
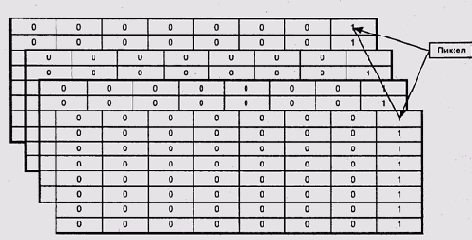
Рис. 9.29. Битовые плоскости
Большинство контроллеров включают в себя также более или менее сложную
логику управления содержимым видеобуфера со стороны центрального процессора.
Простейшим случаем такого управления является отображение видеобуфера
на адресное пространство системной шины. Это, привлекательное во многих
отношениях, решение не всегда применимо, например, если адресное пространство
процессора слишком мало или плотно занято, либо устройство не подключается
непосредственно ни к системной, ни к периферийной шине (например, контроллеры
жидкокристаллических дисплеев, предназначенных для использования во встраиваемых
приложениях, используют для общения с микропроцессором шину PC или нестандартные
протоколы последовательных портов).
При простой нехватке адресного пространства нередко видеобуфер отображают
на адресное пространство не целиком, а частями, банками. При этом контроллер
должен иметь специальный регистр — селектор банка.
Более радикальное решение, применимое даже при подключении через последовательный
порт, состоит в том, чтобы предоставить процессору два регистра — адрес
в видеопамяти и регистр данных, соответствующий ячейке видеопамяти по
этому адресу. Это решение можно считать вырожденным случаем банков видеопамяти,
когда банк имеет размер один байт. При этом требуется всего два регистра
в адресном пространстве ввода-вывода (этот метод редко применяется с видеобуферами
объемом более 64 Кбайт), и доступ к видеобуферу замедляется минимум вдвое.
При использовании последовательных шин и портов адрес и данные передаются
последовательно. Многие графические контроллеры с такой организацией предоставляют
различные способы доступа с автоинкрементом, позволяющие передать в буфер
последовательность байтов без явного доступа к регистру адреса.
Контроллеры с битовыми плоскостями часто предоставляют групповые операции
над байтами, кодирующими биты смежных пикселов.
Контроллеры, применяемые в современных персональных компьютерах и рабочих
станциях, содержат более или менее сложные видеопроцессоры, способные
без участия ЦПУ рисовать в видеобуфере различные графические примитивы,
начиная от прямых линий и окружностей, и заканчивая проекциями и/или фотореалистичными
изображениями трехмерных объектов, описываемых языком OpenGL.
Видеоконтроллеры представляют собой довольно сложные устройства. Подробные
описания современных видеоконтроллеров можно найти во многих доступных
книгах, например в [Гук 2000]. В документе [www.microchip.com
PICMicrol описывается встроенный контроллер жидкокристаллического дисплея
микроконтроллера PIC.
Запоминающие устройства прямого доступа
| Приобрел себе винчестер у дороги во кустах
Обнаружились бэд-блохи в восемнадцати местах Ахх Ю. Нестеренко |
Как уже говорилось, основную массу устройств этого типа составляют диски
— жесткие и гибкие, магнитные, магнитооптические и оптические. Ассоциация
между понятиями "постоянное запоминающее устройство прямого доступа"
и "диск" столь плотно укоренилась в общественном сознании, что
запоминающие устройства, основанные на иных принципах, например, банки
флэш-памяти, иногда называют "твердотельными дисками". В этой
главе мы будем рассматривать преимущественно устройство магнитных дисковых
накопителей. Принцип устройства дискового накопителя широко известен [Гук
2000].
Для хранения данных служит диск, покрытый ферромагнитным слоем. В современных
накопителях запись осуществляется на обе стороны диска. Многие приводы
с неудаляемыми дисками имеют несколько дисков. Диск может быть как гибким,
так и жестким. Диск насажен на ось, называемую шпиндель.
В зависимости от способа крепления, диски делятся на съемные (удаляемые)
и несъемные (фиксированные). В действительности, съемность накладывает
серьезные ограничения не только на крепление диска к оси, но и на конструкцию
блока головок и привода в целом, а также предъявляет определенные требования
к контроллеру — тот должен отслеживать наличие диска в приводе и факт
его замены. Несъемные диски, как правило, помещаются в герметичный корпус,
защищающий головки и поверхность диска от пыли и других вредных атмосферных
воздействий.
Включение двигателя и раскрутка шпинделя до рабочей скорости обязательно
производятся до начала форматирования диска или обмена данными с ним.
Контроллеры съемных дисков обычно останавливают мотор в то время, когда
накопитель не используется, контроллеры же дисков несъемных обычно останавливают
шпиндель только при выключении питания.
Запись на магнитный диск и считывание данных с него осуществляется головкой
чтения-записи, по принципу действия похожей на головку обычного бытового
магнитофона. Головка состоит из ферромагнитного сердечника, на который
намотан провод. Сердечник имеет разрез, как раз в той части, которая ближе
всего к поверхности диска. Подавая ток по проводу, можно создавать в сердечнике
и, соответственно, в разрезе сердечника магнитное поле, которое будет
намагничивать диск. Таким образом, осуществляется запись данных. С другой
стороны, когда направление намагниченности проходящего под головкой участка
диска меняется, в проводах возникает индуктивный ток — детектируя его,
можно осуществлять считывание. В отличие от простой передачи по проводу,
головка считывает не сам записанный сигнат, а его производную по времени
(в аналоговых магнитофонах это компенсируется аналоговым интегрированием
сигнала).
Способ кодирования нулей и единиц при такой записи представляет собой
несколько более сложную задачу, чем при немодулированной передаче данных
по проводу. Видно, что записать на диск постоянное высокое или низкое
напряжение (соответствующее последовательности нулей или единиц в принципе,
можно — в виде участка дорожки с постоянной намагниченностью, но такая
последовательность не может быть считана головкой. Считывать можно только
изменения намагниченности. Таким образом, использовать простые изменения
напряжения для кодирования единиц и нулей невозможно, и мы должны изобрести
более сложную схему кодирования.
Выбирая схему кодирования, мы должны обязательно решить также вопрос о
способе синхронизации считывания: добиться высокой стабильности от мотора,
вращающего шпиндель, невозможно. Кроме того, в приводах низкоскоростных,
особенно гибких, дисков приходится считаться с опасностью механического
заедания подшипников и самого диска, а в приводах жестких дисков с высокой
скоростью вращения — с механическими вибрациями всей конструкции, которые
могут повлиять на скорость прохождения диска под головкой даже при стабильной
средней угловой скорости шпинделя.
На лентопротяжных устройствах с несколькими головками нередко используется
отдельная синхродорожка, но на дисковых устройствах ее введение потребовало
бы существенного усложнения и недопустимого утяжеления блока головок,
поэтому обычно применяются схемы кодирования с совмещенным синхросигналом.
Простейшая форма такого кодирования, называется DFM
(Double Frequency Modulation— модуляция с двойной частотой). Видно,
что при записи нуля мы осуществляем одно изменение направления тока за
интервал кодирования одного бита, а при кодировании единицы — два, причем
первое из этих изменений смещено относительно начала интервала. Такое
кодирование использовалось на 8-дюймовых гибких дисках.
Несколько более сложная схема кодирования, использовалась на 5- и 3-дюймовых
гибких дисках низкой плотности. Эта схема называется модифицированной
фазовой модуляцией. На жестких дисках в 80-е годы использовались частотная
и модифицированная частотная Модуляция. Современные жесткие диски используют
сложные схемы группового кодирования, когда одно изменение фазы или частоты
намагничива-кодирует несколько битов.
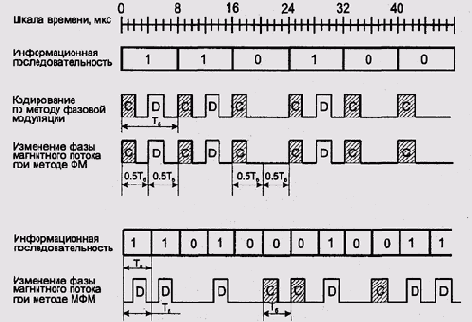
Рис. 9.32. Простая и модифицированная фазовая модуляция
Головка чтения/записи может перемещаться вдоль радиуса диска шаговым
электродвигателем. У жестких дисков головка обычно размещена на рычаге,
напоминающем звукосниматель граммофона. У гибких дисков головка движется
по направляющим под действием червячной передачи, а у CD-ROM — зубчатой
рейки. Накопители, имеющие более одной рабочей поверхности, имеют столько
же головок, сколько и поверхностей, но подача этого блока головок все
равно осуществляется одним двигателем.
Когда блок головок неподвижен, каждая головка может считывать данные,
записанные на диске в виде кольцевой дорожки (track).
Совокупность дорожек всех поверхностей, соответствующих одному положению
блока головок, образует цилиндр (cylinder).
Количество цилиндров у накопителя определяется шириной магнитной головки
(и обусловленной ею шириной намагниченной полосы) и точностью, которую
может обеспечить механика подачи головки. Стандартные приводы 3-дюймовых
дискет имеют 80 дорожек. Количество цилиндров у современных жестких дисков
достигает нескольких тысяч. При всех перечисленных выше, а также при более
сложных современных способах модуляции запись данных на дорожку осуществляется
блоками или секторами.
Секторы аналогичны кадрам, которыми осуществляется передача данных через
последовательные порты и шины. Сектор состоит из заголовка и блока данных.
Заголовок обычно содержит номер дорожки (чтобы
контроллер мог убедиться, что правильно позиционировал головку) и сектора
на дорожке, а иногда также и поверхности. Кроме того, заголовок практически
всегда содержит контрольную сумму или иногда две отдельных контрольных
суммы — для заголовка и для данных. Пространство между секторами заполнено
специальными зонами, служащими для выравнивания и синхронизации (рис.
9.35 и табл. 9.5). Нередко используются также специальные маркеры — последовательности
изменений сигнала, которые не могут появиться при принятой схеме модуляции.
Маркеры используются для отметки начала дорожки или, реже, начала сектора.
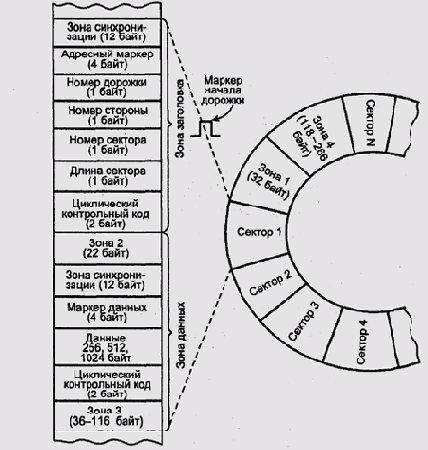
Рис. 9.35. Структура дорожки дискеты с двойной плотностью
Перед тем, как диск может быть использован для записи данных, он должен быть отформатирован или, как говорили раньше, размечен — на его дорожки должны быть записаны заголовки секторов с правильными номерами дорожки и сектора, а также, если это необходимо, маркеры. Как правило, при этом же происходит тестирование поверхности диска для поиска дефектов магнитного слоя. Не следует путать эту операцию — физическое форматирование диска — с логическим форматированием, созданием файловых систем. Современные жесткие диски конструктивов АТА и SCSI обычно требуют физического форматирования в заводских условиях.
Таблица 9.5. Структура сектора дискеты с двойной плотностью, цит. по [МикроЭВМ 1988]
| Длина в байтах | Описание |
| 12 | Зона синхронизации |
| 4 | Адресный маркер |
| 1 | Номер дорожки |
| 1 | Номер стороны |
| 1 т | Номер сектора |
| 1 | Длина сектора |
| 2 | Циклическая контрольная сумма |
| 22 | Зона типа 2 (см. рис. 9.35) |
| 12 | Зона синхронизации |
| 4 | Маркер данных |
| 256/512/1024 | Данные |
| 2 | Циклическая контрольная сумма |
| 36-116 т | Зона типа 3 (см. рис. 9.35) |
Зона типа 1 длиной 32 байта отмечает начало дорожки, а зона типа 4 длиной от 118 до 266 байт служит для заполнения дорожки до полной длины.
Количество секторов в одной дорожке определяется, с одной стороны, длиной сектора, а с другой — частотой модуляции. Частота модуляции, в свою очередь, ограничена частотной характеристикой схемы управления магнитной головкой, индуктивностью самой головки и параметрами ферромагнитной поверхности диска (размером минимального домена намагничивания). Последний фактор, фактически, ограничивает линейную плотность записи (количество битов на миллиметр или дюйм длины дорожки), поэтому в более длинных внешних дорожках целесообразно делать больше секторов, чем во внутренних (рис. 9.36). Это решение усложняет адресацию секторов и логику контроллера, поэтому начало широко применяться лишь относительно недавно.
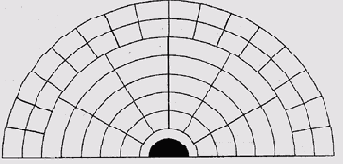
Рис. 9.36. Диск с переменным количеством секторов на дорожках
Привод магнитного диска, таким образом, состоит из трех разнородных электромеханических и аналоговых устройств. Управление которыми должно осуществляться в строгом согласовании:
электродвигателя шпинделя; шагового двигателя подачи головки; аналоговых каскадов управления магнитной головкой.Устройство, управляющее всем этим, называется дисковым контроллером и состоит из кодеров и декодеров используемой схемы модуляции, логики формирующей заголовок сектора при записи или проверяющей его целостность при считывании, буфера данных сектора и сдвигового регистра, подключенного к кодеру и декодеру управления головкой (рис. 9.37). Современные контроллеры обычно содержат более сложную логику, обеспечивающую передачу данных в основное ОЗУ компьютера в режиме ПДП (в том числе и распределение/сборку (scatter/gather) — передачу одного сектора или группы секторов в несмежные участки памяти), очередь обслуживаемых запросов, опережающее считывание, отложенную запись и кэширование данных, переадресацию дефектных секторов и др.
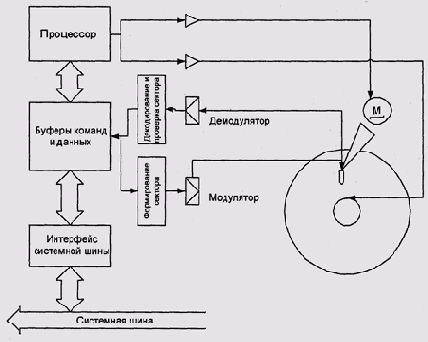
Рис. 9.37. Схема контроллера диска
Контроллер гибких дисков ДВК
В качестве простейшего дискового контроллера рассмотрим микросхему К1801ВП1-097
[МикроЭВМ 1988] (Эта микросхема является советским функциональным аналогом
микросхемы контроллера гибких магнитных дисков, разработанной фирмой DEC
для использования в мини- и микрокомпьютерах семейства PDP-11. К сожалению,
автору не удалось найти маркировку оригинальной микросхемы и ссылку на
документацию о ней).
Микросхема допускает подключение четырех приводов 5-дюймовых гибких дисков
и содержит в себе порты управления основным и шаговым электродвигателями
привода, сдвиговый регистр, модулятор и демодулятор МФМ, логику обнаружения
маркеров, генератор циклической контрольной суммы и интерфейс системной
шины Q-Bus. У микросхемы есть два 16-разрядных регистра, регистр управления
и регистр данных. Описание битов регистра управления приведено в табл.
9.6.
Таблица 9.6. Управляющий регистр К1801ВП1-097
| Бит | Описание | Комментарий |
| 00 (W) | Выбор накопителя 0 | — |
| 00 (R) | Дорожка 0 | Головка чтения/записи установлена на дорожку 0 |
| 01 (W) | Выбор накопителя 1 | — |
| 01 (R) | Накопитель готов | — |
| 02 (W) | Выбор накопителя 2 | — |
| 02 (R) | Запись запрещена | На дискете установлена защита записи |
| 03 (W) | Выбор накопителя 3 | — |
| 04 | Включение двигателя | — |
| 05 | Поверхность | Если 1, запись (чтение) происходите верхней поверхности диска |
| 06 | Направление шага | При записи 1 , направление к оси диска |
| 07 (W) | Шаг | При записи 1 в этот бит, головка перемещается на один шаг и бит очищается |
| 07 (R) | Данные готовы | Контроллер выставляет этот бит, когда считано или записано очередное слово данных. ЦПУ должно прочитать или записать следующее слово сектора |
| 08 | Частичный сброс | |
| 09 | Запись маркера | |
| 10 | Включение внешней схемы прекоррекции фазовых искажений | |
| 14 | Успех операции | 0, если операция завершилась ошибкой |
| 15 | Начало дорожки |
Видно, что микросхема предусматривает работу с ней центрального процессора в режиме опроса. Более сложный контроллер КМД (Контроллер МиниДисков), основанный на этой микросхеме, содержит микропроцессор, ПЗУ с программой для него и 2Кб ОЗУ (которое может использоваться и для промеж, точных данных программы микропроцессора, и для хранения самих данных передаваемого блока) [МикроЭВМ 1988]. Работа с этим контроллером осуществляется посредством двух регистров, команды/состояния и данных. Центральный процессор записывает в эти регистры команду (табл. 9.7) и адрес блока параметров в основном ОЗУ. Контроллер в режиме ПДП считывает блок параметров и пытается выполнить операцию, передавая данные, если это необходимо, также в режиме ПДП. Указатель на блок данных содержится в блоке параметров. Одной операцией можно прочитать или записать несколько последовательных секторов. После завершения передачи контроллер генерирует прерывание.
Таблица 9.7. Список команд контроллера КМД, цит. по [МикроЭВМ 1988]
| Код | Мнемоника | Описание |
| 0h | RD | Чтение |
| 1h | WR | Запись |
| 2h | RDM | Чтение с маркером |
| 3h | WRM | Запись с маркером |
| 4h | RDTR | Чтение дорожки |
| 5h | RDID | Чтение заголовка |
| 6h | FORMAT | Форматирование дорожки |
| 7h | SEEK | Подача головки |
| 8h | SET | Установка параметров |
| 9h | RDERR | Чтение состояния и ошибок |
| Fh | LOAD | Загрузка |
Контроллер жестких дисков ST506
Более сложный контроллер ST506 был разработан фирмой Western Digital в
конце 70-х годов прошлого века для управления жесткими дисками, подключаемыми
к микропроцессорным системам. Этот контроллер и его усовершенствованная
версия, ST412, широко применялись для подключения жестких дисков к IBM
PC и совместимых с ними компьютерах [citforum.ukrpak.net IDE, Гук 2000,
PC Guide IDE].
Контроллер ST506 допускал подключение двух жестких дисков емкостью до
40МЬ, использующих модифицированную частотную модуляцию, а более поздние
версии контроллера — групповую модуляцию RLL. Как и описанный выше КМД,
контроллер содержал логику управления мотором шпинделя и подачей головок,
буфер для одного сектора и схемы модуляции и демодуляции МЧМ. Диски присоединялись
к контроллеру двумя плоскими кабелями: один, с 34-мя проводами, использовался
для передачи сигналов управления двигателями, а второй, 20-проводной —
для передачи модулированных сигналов МЧМ.
Центральному процессору контроллер ST506 доступен в виде двух блоков регистров,
управляющего и командного. Блок управляющих регистров размещается по адресам
Ox3F4-Ox3F7, а блок командных— по адресам 1FO-1F7 (табл. 9.8).
Управляющие регистры используются для доступа к регистрам данных и статуса
без подачи контроллеру сигнала о том, что регистр прочитан (смысл этого
станет ясен далее). Пожалуй, единственный самостоятельно полезный бит
в этих регистрах управляет разрешением прерываний от контроллера. Основная
работа с контроллером происходит через блок из восьми командных регистров,
один из которых является регистром данных.
При исполнении команды записи контроллер подает головку к дорожке, указанной
регистрами CY и DK, генерирует прерывание и выставляет сигнал DRQ (табл.
9.9), сигнализируя процессору, что готов принять данные. Затем процессор
производит 512 операций записи в порт данных, заполняя буфер. Контроллер
выполняет запись, генерирует прерывание и, если счетчик секторов еще не
сравнялся с нулем, увеличивает номер сектора и снова выставляет сигнал
DRQ.
Операция чтения выполняется аналогично, с той лишь разницей, что контроллер
сначала считывает сектор, и лишь потом выставляет DRQ. Циклы чтения и
записи регистра данных, таким образом, приводят к увеличению счетчика
буфера. Набор команд контроллера приведен в табл. 9.10.
Таблица 9.8. Командные регистры контроллера ST506, цит. по [chip.ms.mff.cuni.cz АТА2]
| Адрес | Функция (чтение) | Функция (запись) | Код |
| 0x1 F0 | Данные (младш.) | Данные (младш.) | |
| 0x1 F1 | Ошибка | Прекомпенсация | PC |
| 0x1 F2 | Счетчик секторов | — " — | SC |
| 0x1 F3 | Номер сектора | — " — | SN |
| 0x1 F4 | Цилиндр (младш.) | — " — | CY |
| 0x1 F5 | Цилиндр (старш.) | — " — | CY |
| 0x1 F6 | Устройство/поверхность | — " — | DH |
| 0x1 F7 | Статус | Команда |
Таблица 9.9. Биты регистра статуса ST506, цит. по [chip.ms.mff.cuni.cz IDE]
| Бит | Мнемоника | Описание |
| 7 | BUSY | Устройство занято |
| 6 | DRDY | Устройство готово принимать команды |
| 5 | DWF | Ошибка записи |
| 4 | DSC | Подача головки завершена |
| 3 | DRQ | Запрос данных |
| 2 | CORR | Исправимая ошибка при чтении данных |
| 1 | INDEX | Маркер начала дорожки |
| 0 | ERROR | Ошибка |
Таблица 9.10. Команды контроллера ST506, цит. по [chip.ms.mff.cuni.cz IDE]
| Код | Описание | PC | SC | SN | CY | DH |
| 90h | Диагностика привода | — | — | — | — | D+ |
| 50h | Форматировать дорожку | — | — | — | V | V |
| 20h | Чтение секторов с повтором | — | V | V | V | V |
| 21h | Чтение секторов | — | V | V | V | V |
| 40h | Проверка секторов с повтором | — | V | V | V | V |
| 41h | Проверка секторов | — | V | V | V | V |
| 1Xh | Возврат к дорожке | — | — | — | — | D |
| 7Xh | Подача головки | — | — | — | V | V |
| 30h | Запись секторов с повтором | — | V | V | V | V |
| 31h | Запись секторов | — | V | V | V | V |
V— используется значение регистра
D — используется только бит выбора диска
D+ — независимо от бита выбора диска, реагируют оба диска
Контроллеры жестких дисков ESDI, IDE,
EIDE
Дальнейшее совершенствование ST506 шло в направлении переноса функции
контроллера на сам жесткий диск. Первым шагом стал интерфейс ESDI, предложенный
фирмой IBM в 1985 году. В ESDI модулирование сигнала выполнялось не контроллером,
а платой, установленной на диске. Это позволило, во-первых, использовать
жесткие диски со схемами модуляции, отличными от МЧМ и RLL и, во-вторых,
увеличить допустимую длину кабелей до трех метров. Контроллер ESDI по
регистрам и набору команд был полностью совместим с ST506/412, но обеспечивал
работу с дисками большей емкости и большей производительности.
Следующий, более радикальный, шаг был сделан в следующем году фирмами
Western Digital и Compaq, предложившими перенести весь контроллер на жесткий
диск. Соответствующий конструктив был назван IDE (Integrated Drive Electronics
— интегрированная на приводе электроника).
40-жильный плоский кабель IDE представляет собой, фактически, расширение
шин адреса и данных ISA. По нему передаются 16 бит данных и пять линий
адреса. Первые две линии адреса выбирают группу регистров — контрольный
или командный блок регистров, расположенных по тем же адресам шины ISA,
что и соответствующие регистры ST506. Последние три линии выбирают один
из регистров соответствующей группы и через линии данных кабеля подключают
его к шине данных ISA.
IDE, как и ST506, допускает подключение двух жестких дисков, Каждый из
дисков имеет свой контроллер и свои блоки регистров. Когда ЦПУ производит
запись в эти регистры, она происходит в регистры обоих контроллеров. Однако
на запросы чтения и, тем более, исполнения команды откликается только
тот контроллер, который выбран регистром он. Эта весьма своеобразная архитектура
позволила сохранить полную программную совместимость с контроллером ST506
при полном же изменении конструктива. Основным недостатком этой архитектуры
является тот печальный факт, что пока один диск отрабатывает команду или
передает данные, обращения ко второму диску невозможны.
IDE несколько позднее получил статус стандарта ANSI под названием ATA
(AT Attachment— [интерфейс] присоединения к IBM PC/AT) [www.t13.org],
и до сих пор является основным способом подключения жестких дисков к настольным
компьютерам и иногда даже к маломощным серверам, причем не только на основе
процессоров х86, но и PowerMac, SPARCStation и др.
Современные версии стандарта поддерживают обмен 16-разрядными данными
(при нормальной отработке команды код ошибки не нужен, а прекомпенсация
современными контроллерами вообще не используется, поэтому для данных
можно использовать регистры 0x1 FO и 0x1 F1, образующие при этом единый
16-разрядный регистр), автоидентификацию геометрии и других параметров
жестких дисков, логическую адресацию блоков (LBA — Logical Block Addressing,
когда регистры SN, CY и 4 младших бита он образуют линейный 28-битный
адрес сектора), работу в режиме ПДП и передачу данных со скоростями до
60 Мбит/с [Гук 2000, citforum.ukrpak.net IDE, PC Guide IDE, www.t13.org].
Расширение протокола ATAPI (ATA Packet Interface) пакетный интерфейс ATA
предусматривает также возможность управления недисковыми устройствами
(CD-ROM, стриммерами, магнитооптическими дисками) путем передачи через
регистр данных 12-байтовых блоков команд, аналогичных командам SCSI.
Производительность жестких дисков
Скорость работы дискового накопителя определяется рядом параметров.
Во-первых, любой обмен данными с таким устройством предваряется двумя
обязательными задержками: позиционированием блока головок и ротационной
задержкой (rotational delay), когда контроллер ждет, пока требуемый
сектор подъедет к головке. Кроме того, само чтение сектора происходит
не мгновенно, и, наконец, необходимо принимать во внимание скорость передачи
данных по шине, к которой подключен диск, и возможные коллицизии на этой
шине.
Задержку позиционирования головки можно в определенных пределах сокращать
облегчением блока головок и совершенствованием механики. Единственный
способ сокращения ротационной задержки — это увеличение скорости вращения
диска. У современных дисков эта скорость достигает 15000 об/мин. Скорость
вращения повышает также и скорость чтения отдельного сектора. Кроме того,
увеличение плотности записи (как за счет улучшения физических характеристик
магнитного слоя, так и за счет совершенствования способов модуляции) и
обусловленное этим увеличение количества секторов на дорожке также ускоряет
считывание каждого отдельного сектора.
Любопытный прием сокращения ротационной задержки при чтении последовательных
секторов — это форматирование дисков с чередованием
(interleave), когда номера секторов на дорожке не совпадают с их
физической последовательностью (рис. 9.38). Количество физических секторов,
размещенных между логически последовательными секторами, называется коэффициентом
чередования.
Рис. 9.38. Дорожка диска, отформатированного с чередованием
Благодаря чередованию, если ЦПУ сформирует команду чтения следующего
сектора немгновенно после завершения передачи предыдущего (на практике,
это всегда происходит немгновенно), не придется ждать следующего оборота
диска. Впрочем, если коэффициент чередования окажется слишком большим,
ждать подхода следующего сектора все-таки придется. В годы молодости автора
подбор оптимальных параметров чередования для жестких дисков был почти
столь же популярным развлечением, каким ныне является "разгон"
(подбор частот процессора и системной и периферийной шин, которые выше
паспортных, но обеспечивают более или менее устойчивую работу системы).
Ряд файловых систем, разработанных в 80-е годы, реализовали свои собственные
схемы чередования, размещая последовательные блоки файлов в чередующиеся
физические секторы. Современные дисковые контроллеры предоставляют логику
опережающего считывания и отложенной записи, которые снижают потребность
в таких приемах. Кроме того, фабричное форматирование жестких дисков обычно
сразу осуществляется с оптимальным чередованием.
Для сокращения времени подачи головки нередко используют сортировку запросов
по номеру дорожки. В [Дейтел 1987) приводится анализ нескольких алгоритмов
такой сортировки. В наше время шире всего используется элеваторная сортировка
(в |Дейтел 1987] она называется SCAN). При отсортированных в соответствии
с этим алгоритмом запросах, блок головок начинает от внутренней дорожки
(или, точнее, от запроса, ближайшего к этой дорожке) и движется к наружной,
исполняя последовательные запросы так, чтобы направление движения головки
не изменялось (рис. 9.39). Запросы, поступающие на уже пройденные дорожки,
откладываются на обратный проход. Достигнув внешней дорожки (или, точнее,
самой внешней из дорожек, на которую есть запрос), блок головок меняет
направление движения.
Рис. 9.39. Элеваторная сортировка
Сортировке подвергаются только запросы на чтение. По причинам, которые мы в полной мере поймем в главе 11, запросы на запись практически никогда не переупорядочиваются.
Дисковые массивы
| У тебя, Федот, жена, хоть умна, а все ж
одна! А соткать такое за ночь — их дивизия нужна! Л. Филатов |
Еще один прием оптимизация производительности дисковых накопителей —
это объединение нескольких физических дисков в один большой логический
диск. При таком объединении некоторые диски могут передавать данные, в
то время, как другие позиционируют блок головок или ждут подхода нужного
сектора к головке. Дисковые массивы выгодны не только с точки зрения производительности,
но и повышают единичную емкость запоминающего устройства — это может быть,
например, полезно для хранения крупных неделимых объектов, таких, как
таблицы реляционной СУБД.
Следует учесть, что объединение дисков приводит к резкому снижению наработки
массива на отказ: вероятности независимых событий складываются поэтому
вероятность отказа любого из дисков массива равна сумме вероятностей отказа
одиночного диска. Для компенсации или устранения этого недостатка данные
в дисковых массивах обычно хранятся с избыточностью. Общее название всех
технологий объединения дисков — RAID (Redundant Irray
of Inexpensive Disks — избыточный массив недорогих дисков). Этот
термин был предложен в работе [Gibson/Katz/Patterson I988], в которой
проведен анализ различных технологий создания дисковых массивов с точки
зрения их производительности и надежности и было рассмотрено пять возможных
способов размещения избыточных данных. Предложенная авторами статьи нумерация
этих технологий без ссылки на источник используется в самых разнообразных
публикациях в форме RAID уровня X. В современных публикациях, например
[www.acnc.com], часто упоминаются также дополнительные и комбинированные
уровни RAID, в именовании которых общего согласия не достигнуто.
Впрочем, один дополнительный уровень, не упоминавшийся в статье [Gibson/Katz/Patterson
1988], практически везде понимается и именуется одинаково. Под RAID уровня
0 практически единогласно понимают простой стриппинг
(stripping — дословно, разделение на полосы).
Стриппинг, строго говоря, не является методом создания избыточных массивов,
потому что он не предполагает избыточности: емкость результирующего логического
диска равна сумме объемов физических дисков (рис. 9.40). Из-за этого RAID
0 не обсуждался в работе [Gibson/Katz/Patterson 1988].
RAID уровня 1 известен также как зеркалирование (mirroring).
При зеркали-ровании на каждый из дисков записывается полная копия данных
(рис. 9.41). Обычно в зеркальном режиме используется не более двух дисков.
Зеркалирование обеспечивает некоторое падение производительности (обычно
все-таки менее, чем двукратное), но гарантирует работоспособность системы
при отказе любого из дисков. Оба эти приема широко применяются па практике,
обычно с небольшим количеством дисков, не более двух, реже, трех. Они
не требуют значительных вычислительных ресурсов и потому обычно реализуются
программно, драйвером диска или файловой системы.
RAID уровня 2 предлагает снабжение блоков данных на дисках кодом Хэмминга
(см. разд. Контрольные суммы) и
размещение этого кода на отдельном диске массива. Эта технология имеет
смысл, если контроллеры дисков не хранят код восстановления ошибок в собственных
заголовках секторов. Поскольку современные диски практически без исключения
используют восстанавливающее кодирование и динамическое переназначение
дефектных секторов, RAID 2 практически не применяется.
Рис. 9.41. RAID1 (зеркалирование)
RAID уровня 3 и 4 похожи во многих отношениях. Каждый из этих методов
требует не менее трех дисков и подсчета контрольной суммы таким способом,
чтобы данные могли быть однозначно восстановлены при полной потере одного
из дисков. В RAID уровня 3 контрольные суммы подсчитываются для каждого
байта записываемых данных, а в RAID уровня 4 — для групп блоков. Для хранения
контрольных сумм отводится отдельный диск.
Эти методики обеспечивают более низкую (хотя и достаточную для большинства
практических целей) избыточность, чем зеркалирование, но, как стриппинг.
увеличивают единичную емкость диска и повышают производительность. Для
отказа всей системы требуется полный отказ более чем от одного диска;
многие конструктивы дисковых массивов уровня более 2 предусматривают "горячую"
(без выключения системы) замену дисков, что допускает теоретически неограниченную
наработку на останов, недостижимую при использовании одиночных дисков.
RAID 3 требует изменения формата секторов диска и соответствующей переделки
контроллера и не может применяться с серийными дисковыми приводами. Основным
недостатком RAID 4 является необходимость обращения к диску с контрольной
суммой при каждой модификации одного из блоков группы. При записи большого
количества логически последовательных блоков это не проблема, но может
превратиться в проблему при случайно распределенных записях одиночных
блоков.
Этого недостатка лишен RAID уровня 5, в котором контрольные суммы распределены
по всем дискам массива (рис. 9.42). RAID 5 находят широкое применение
в серверах уровня рабочей группы, или подразделения. При программной реализации,
впрочем, подсчет контрольных сумм требует значительной доли вычислительной
мощности ЦПУ, поэтому широкое распространение получили "аппаратные"
контроллеры RAID 5, имеющие собственный процессор и, как правило, довольно
большой объем собственной памяти. Это не мешает некоторым ОС, в частности
Windows NT/2000/XP, реализовать RAID 5 программно на уровне файловой системы.
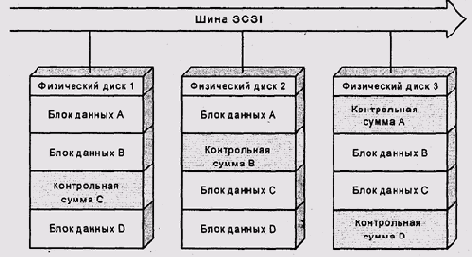
Рис. 9.42. RAID уровня 5
Сети доступа к дискам
| — А теперь, прикинь солдат — где Москва,
а где Багдад! Али ты смотался за ночь до Богдаду и назад? Л. Филатов |
Волоконно-оптические каналы подключения дисковых устройств к компьютерам,
как, например, упоминавшийся в разд.
