Архитектура нейросети
Нейросеть имеет довольно простую структуру и состоит из трех уровней: входной слой, символьный слой и эффекторный слой (рис. 14). Каждый нейрон последующего слоя связан со всеми нейронами предыдущего слоя. Функция передачи во всех слоя линейная, во входном слое моделируется конкуренция.
Архитектура нейросети

Рис. 14
1. Входной слой - этот слой получает сигналы непосредственно от входов нейросети (входы не осуществляют обработку сигнала, а только распределяют его дальше в нейросеть). Он представляет собой один из вариантов самоорганизующейся карты Кохонена, обучающейся без учителя. Основной задачей входного уровня является формирование нейронных ансамблей для каждого класса входных векторов, которые представляют соответствующие им сигналы на дальнейших уровнях обработки. Фактически, именно этот слой определяет эффективность дальнейшей обработки сигнала, и моделирование этого слоя представляет наибольшую трудность.
Нейроны этого слоя функционируют по принципу конкуренции, т.е. в результате определенного количества итераций активным остается один нейрон или нейронный ансамбль (группа нейронов, которые срабатывают одновременно). Для этого нейрона расстояние между входным вектором и вектором, который этот нейрон представляет, минимально (в данном случае используется угловое расстояние, т.е. угол между входным вектором и вектором связей). Данный механизм осуществляется за счет действия латеральных связей и называется латеральным торможением. Он подробно рассмотрен во многих источниках (см. [1], [7], а также приложение 7.1). Так как отработка этого механизма требует значительных вычислительных ресурсов, в моей модели он моделируется искусственно, т.е. находится нейрон с максимальной активностью, его активность устанавливается в 1, остальных в 0.
Обучение слоя Кохонена производится по правилу (7):
wн = wс + a(x – wс)a, (7)
где wн - новое значение веса,
wс – старое значение,
a - скорость обучения, a<1
x - нормированный входной вектор,
a – активность нейрона.
Геометрически это правило иллюстрирует рисунок 15:
Коррекция весов нейрона Кохонена

Рис. 15
Входной вектор x перед подачей на вход нейросети нормируется, т.е. располагается на гиперсфере единичного радиуса в пространстве весов. При коррекции весов по правилу (7) происходит поворот вектора весов в сторону входного вектора. Постепенное уменьшение скорости поворота a позволяет произвести статистическое усреднение входных векторов, на которые реагирует данный нейрон.
Проблемы, которые возникают при обучении слоя Кохонена, описаны в разделе 5.2.4
2. Символьный слой – нейроны этого слоя ассоциированы с символами алфавита (это не обязательно должен быть обычный буквенный алфавит, но любой, например, алфавит фонем). Этот слой осуществляет генерацию символов при распознавании и ввод символов при синтезе. Он представляет собой слой Гроссберга, обучающийся с учителем ([1], «Сеть встречного распространения»). Нейрон этого слоя функционирует обычным образом: вычисляет суммарный взвешенный сигнал на своих входах и при помощи линейной функции передает его на выход. Модификация весов связей при обучении происходит по следующему правилу:
wijн = wijс + b(yj – wijс)xi, (8)
где wijн, wijс – веса связей до и после модификации
b - скорость обучения, b<1
yj – выход нейрона
xi – вход нейрона
По этому правилу вектор весов связей стремится к выходному вектору, но только если активен вход, т.е. модифицироваться будут связи только от активных в данный момент нейронов слоя Кохонена. Выходы же у символьного слоя бинарные, т.е. нейрон может быть активен (yj = 1) или нет (yj = 0), что соответствует включению определенного символа. Входной слой совместно с символьным слоем позволяют сопоставить каждому классу входных сигналов определенный символ алфавита.
3. Эффекторный слой – этот слой получает сигналы от символьного слоя и также является слоем Гроссберга.Выходом слоя является вектор эффекторов – элементов, активность которых управляет заданными параметрами в модели синтеза. Связь эффекторов с параметрами модели синтеза осуществляется через карту эффекторов. Этот слой позволяет сопоставить каждому нейрону символьного слоя (а следовательно, и каждому символу алфавита) некоторый вектор эффекторов (а следовательно, и определенный синтезируемый звук). Это слой обучается аналогично символьному слою.
Формат звуковых файлов Microsoft Wave
Это наиболее распространенный благодаря своей гибкости формат хранения аудиоданных. Данный формат принадлежит к группе форматов файлов для передачи ресурсов RIFF (Resource Interchange File Formats). Обычно файлы имеют расширение wav. Помимо звуковых данных, файл может содержать текстовую информацию, различную служебную информацию и вообще любые (не только звуковые) данные. Каждый фрагмент данных имеет заголовок, в котором уточняется тип данных и размер фрагмента. Глобальный фрагмент имеет заголовок RIFF. Допускается вложенность фрагментов. Звуковые данные могут быть как сжатые, так и не сжатые. Несжатые данные хранятся в формате PCM (Pulse Code Modulation), при этом порядок следования таков: идет первый отсчет первого (например, левого) канала, затем второго, и т.д. (естественно, если звук моно, то канал всего один), затем второй отсчет первого канала, второго, и т.д. Для отсчетов разрядностью 16 бит (слово) данные хранятся в виде знакового целого, сначала младший, затем старший байт. При этом отсутствию сигнала соответствует значение 0, а максимально возможная амплитуда 215.
Структура файла с единственным фрагментом аудиоданных изображена на рис. 1:
Формат файлов Microsoft Wave RIFF PCM

Рис. 1
Структура WAVEFORMATEX используется для определения формата записанных данных. В Windows она определена следующим образом:
typedef struct {
WORD wFormatTag; // формат данных, например WAVE_FORMAT_PCM
WORD nChannels; // количество каналов
DWORD nSamplesPerSec; // частота дискретизации
WORD nAvgBytesPerSec; // скорость потока, байт в секунду
// для PCM равен nSamplesPerSec*nBlockAlign
WORD nBlockAlign; // минимальная единица измерения в байтах,
// для PCM равна BitsPerSample/8*nChannels
WORD wBitsPerSample; // Количество бит на отсчет
WORD cbSize; // размер доп. информации
} WAVEFORMATEX;
Генетические алгоритмы
1. Идея метода
Генетические алгоритмы используют принцип естественного отбора и эволюционной мутации для конструирования или обучения нейросетей. Иногда бывает очень трудно построить хорошую модель нейросети для конкретной задачи обработки информации, из-за трудности понимания работы как самой нейросети, так и принципов, управляющих информацией в самой задаче из-за её неформализуемости (а нейросети используются чаще всего именно в таких задачах).
Существуют различные приложения генетических алгоритмов: 1. Построение топологии НС; 2. Обучение нейросети; 3. Оптимизация контрольных параметров.
2. Алгоритм работы для задачи построения топологии
Входные данные: начальная популяция нейросетей, предположительно подходящих для решения задачи.
Выходные данные: нейросеть, решающая задачу с требуемой точностью.
1. Обучение каждой нейросети в популяции
2. Для каждой НС определяется её эффективность решения данной задачи
3. Если задача решена какой либо нейросетью, ВЫХОД
4. Наименее эффективные НС удаляются из популяции, наиболее эффективные скрещиваются(1) и дают новое поколение НС; самая лучшая нейросеть остается в популяции
5. На новое поколение накладывается мутация(2) (чтобы обойти локальные минимумы ошибки)
6. Повторяется цикл с 1.
1: Механизм скрещивание НС зависит от конкретной архитектуры нейросети. Например, для многослойного персептрона с прямым распространением этот процесс представляет собой образование новой НС, в которой выходные нейроны родителей станут скрытыми нейронами потомка (рис. 1). При этом сохраняются знания, накопленные родителями.
Скрещивание двух нейросетей для образования нового поколения

Рис. 1
2: Мутация может представлять собой умножения произвольно выбранных весов НС на случайный коэффициент, близкий к 1.
3. Алгоритм работы для задачи обучения нейросети
Входные данные: нейросеть, требующая обучения.
Выходные данные: обученная нейросеть, решающая задачу с требуемой точностью.
1. Создается случайным образом исходная популяция нейросетей (все индивиды имеют одинаковую архитектуру, но разные значение весов связей и других переменных)
2. Оценивается эффективность решения задачи каждой нейросетью
3. Если задача решена, ВЫХОД
4. Индивиды сортируются в соответствии с эффективностью решения задачи
5. Самая лучшая нейросеть сохраняется, на остальные накладываются мутации
6. При достижении некоторого момента времени происходит генерация нового поколения: наиболее подходящие индивиды скрещиваются, наименее подходящие удаляются из популяции; недостающее количество генерируется случайным образом
7.

4. Выводы
Генетические алгоритмы дают возможность построить такие модели НС, которые было бы трудно создать аналитическими методами. Благодаря эволюционному подходу возможно без участия конструктора автоматически найти эффективное решение задачи. Но из-за самой природы алгоритма (случайность и перебор вариантов) время, необходимое на решение задачи, может быть очень большим, и достижение желаемого результата не гарантировано.
Экспериментальная проверка модели
Для проверки функционирования системы анализа речи была проведена серия экспериментов. Описания экспериментов и вспомогательные данные доступны в каталоге /Exp/. Порядок работы с системой и инструментами подробно описан в справочной системе.
Критерии выбора модели нейросети
На уровне ввода сигнала происходит выделение из него знакомых системе образцов и представление их одним нейроном или нейронным ансамблем на следующих уровнях. Как при обучении, так и при распознавании входные вектора являются нечеткими, т.е. имеется небольшой разброс векторов, принадлежащих к одному классу. В связи с этим нейросеть, осуществляющая эту операцию, должна обладать определенной способностью к статистическому усреднению. Напротив, может оказаться, что группа векторов находится в непосредственной близости друг к другу, но все они представляют разные классы. Тогда нейросеть должна определять тонкие различия между векторами.
Ещё одно требование к нейросети входного уровня – обучение без учителя, т.е. способность самостоятельно формировать нейронные ансамбли.
Существует большое число нейросетевых алгоритмов, выполняющих функцию разделения входного сигнала на классы. В основе большинства из них лежат 3 способа разделения:
1. Разделение входных сигналов гиперплоскостями (простой персептрон). Применение этого алгоритма оправдано только для задач, обладающих высокой линейностью. Например, можно построить нейросеть, разбивающую точки (0,0) и (1,1) на два класса для двумерного сигнала, но невозможно решить задачу по разбиению точек (0,0), (1,1) – первый класс, и (0,1), (1,0) – второй (рис. 11). Это хорошо известный пример неспособности простого персептрона решить задачу «исключающее или».
Разделение двумерного сигнала простым персептроном

Рис. 11
2. Разделение входного сигнала гиперповерхностями (многослойные персептроны). При последовательном соединении слоев, подобных простому персептрону, появляется возможность комбинировать гиперплоскости и получать гиперповерхности довольно сложной формы, в том числе и замкнутые. Такая нейросеть в принципе при достаточном числе нейронов способна разделять сигналы на классы практически любой сложности. Но применение таких нейросетей ограничено сложностью их обучения. Был разработан мощный алгоритм, называемый «алгоритмом обратного распространения ошибки», но и он требует значительного времени обучения и не гарантирует успешный результат (опасность попадания в локальные минимумы).
Подробнее этот алгоритм описан в приложении 7.2, а пример его работы проиллюстрирован на рисунке 12. Скриншот получен с программы \NNTest\nntest.exe (с библиотекой nntest4.dll), и на нем видно, что 3-х слойный персептрон способен строить довольно сложные гиперповерхности для разделения входных сигналов на классы (здесь красные и синие крестики иллюстрируют два класса в двумерном сигнальном пространстве, а интенсивность белого цвета в каждой точке с координатами [x,y] показывает уровень отклика нейросети на сигнал [x,y]).
Разделение двумерного сигнала многослойной нейросетью с обучением алгоритмом обратного распространения ошибки.

Рис. 12
3. Поиск наибольшего соответствия (наименьшего углового или линейного расстояния). Принадлежность входного вектора к какому либо классу определяется путем нахождения наименьшего расстояния до нейрона или нейронного ансамбля, представляющего этот класс, или при попадании входного сигнала в некоторую окрестность нейронного ансамбля (рис. 13) При этом в разных алгоритмах используется различная форма расстояния.
Классификация по максимальному соответствию

Рис. 13
В данной работе был выбран 3 способ, потому что одно из важных особенностей нейросети с такой формой классификации заключается в способности обучаться без учителя.
Многослойный персептрон
1. Идея метода
Сеть состоит из входного слоя нейронов, нескольких скрытых слоев и выходного слоя. Каждый нейрон последующего слоя связан со всеми нейронами предыдущего модифицируемыми связями. Нейроны имеют сигмоидальную (реже пороговую) функцию возбуждения. Многослойный персептрон является нелинейным классификатором , т.е. может делить пространство сигнала несколькими плоскостями. Сеть обучается классификации изменением весов связей (также могут изменяться и “смещения”).
2. Математическое описание
Аналогично простому персептрону, каждый нейрон в многослойном персептроне выполняет разделение пространства сигналов гиперплоскостями. Наличие скрытых слоев позволяет объединять эти гиперплоскости операциями ИЛИ, НЕ, И, и получать в результате поверхности любой сложности.
Для обучения нейросети был разработан алгоритм обратного распространения ошибки, являющийся дальнейшим развитием дельта-правила, используемого в простом персептроне.
Введем следующие обозначения:
EW – производная ошибки по весу
EA – производная ошибки по уровню активности элемента
EI – скорость изменения ошибки при изменении входа элемента
X – входной вектор
Y – выходной вектор
W – матрица связей,

f – функция возбуждения (сигмоидальная функция)

Dj – желаемый выход j-го элемента
E – ошибка классификации

С использованием этих обозначений можно записать следующие соотношения:




Т.о., в (6) мы получили EA для следующего слоя, и теперь имеем возможность повторить эти операции для всех нижележащих слоев.
После нахождения матрицы EWij корректируются связи Wij:

где e – скорость обучения.
3. Алгоритм обучения
Входные данные: обучающая выборка (множество пар вход-выход)
Выходные данные: модифицированные веса связей, при которых нейросеть наиболее эффективно классифицирует обучающую выборку.
1. На вход сети подаётся первый элемент обучающей выборки
2. Вычисляется выход сети Y
3. Вычисляется ошибка E
4. Если E<=E0 для всей выборки, ВЫХОД
5. Вычисляется EAj для каждого элемента слоя (для выходного – по формуле (3), для остальных – по формуле (6) )
6. Вычисляется EIj по формуле
7. Вычисляется EWij по формуле (5)
8. Корректируются связи в соответствии с (7)
9. Повторяются шаги [5-8] для всех слоев
10. Повторить [2-9] для всех элементов обучающей выборки
11. Повторять [1-10], пока сеть не обучится или число итераций не превысит максимально допустимого
Примечание: параметр e (скорость обучения) выбирается исходя из следующих соображений: при большом е будет наблюдаться осцилляция ошибки относительно 0, при слишком малом – малая скорость обучения и возможность локальных минимумов ошибки. Наиболее оптимальным вариантом предполагается большое значение е в начале обучения и постепенное уменьшение до 0.
4. Выводы
Многослойный персептрон с обратным распространением ошибки является наиболее распространенной на сегодняшний день архитектурой нейросети. К его достоинствам можно отнести сравнительную простоту анализа и достаточно высокую эффективность классификации. Благодаря использованию непрерывной функции возбуждения он способен к обобщению обучающей выборки, что хорошо видно на примере (см. приложение).Но все равно в связи с использованием в качестве разделительных поверхностей гиперплоскостей классификация сильно нелинейных сигналов (например, в задаче анализа изображений) требует большого числа нейронов, что не всегда является приемлемым.Выход здесь видится в предварительном преобразовании пространства сигналов с целью уменьшения нелинейностей.
Модель нейросети
| Входные данные: | Однослойная нейросеть с двумя входами, состоящая из 10 нейронов (инструмент Модель нейросети).
Коэффициенты обучения: alpha0 = 0.0500 alpha1 = 1.6000 alpha2 = 0.1000 alpha3 = 5.0000 dAlpha = 0.0010 Было задано 10 обучающих паттернов, распределенных в 2 удаленные друг от друга группы в параметрическом пространстве. |
| Цель эксперимента: | Показать способность слоя Кохонена эффективно распределить нейроны для классификации всей обучающей выборки |
| Ход эксперимента: | В начале обучения все нейроны расположились в центре масс обоих групп обучающих паттернов, затем разделились на две группы, соответствующие группам обучающей выборки, и т.д. |
| Результат: | В конце обучения нейроны действовали независимо друг от друга, «найдя» все обучающие паттерны. |
| Выводы: | Процесс последовательного разделения групп нейронов позволяет нейросети эффективно обучаться выборке, неравномерно распределенной в параметрическом пространстве. Правило «желания работать» позволяет избежать потери нейронов. |
Модель синтеза речи
Схематически формантно-голосовая модель синтеза речи изображена на рис. 17. При построении модели использовались данные об артикуляционном аппарате человека, а также данные фонетики и лингвистики ([5]).
Формантно-голосовая модель синтеза речи

Рис. 17
Построение модели – это всегда упрощения того, что мы собираемся моделировать. Здесь важно найти компромисс между качеством модели (т.е. пригодностью её для решения поставленной задачи), и её сложностью. Для этого необходимо выбрать наиболее важные параметры исследуемой системы. В моей модели выбраны следующие основные параметры:
1. Частота основного тона. Определяющий параметр голосового источника, характеризует высоту голоса.
2. Частота шума. Образование шума – довольно сложный процесс и зависит от многих факторов – давления и скорости воздушной струи, геометрической формы воздушного тракта, акустических свойств материала – поэтому моделирование этого процесса на физическом уровне представляет собой серьезную задачу и требует построения всего речевого аппарата человека. Альтернатива этому – представить звук как белый шум, спектр которого распределен по некоторому закону (например, по Гауссу) относительно некоторой частоты. Закон распределения можно подобрать экспериментально, и у нас остается один переменный параметр – центральная частота, что намного упрощает моделирование.
3. Число формант. Число активных формант, участвующих в речеобразовании. Выбирается экспериментально, ориентировочно 4.
4. Центральная частота каждой форманты. т.к. форманта представляет собой резонанс в речевом тракте, у неё есть частота резонанса и огибающая. Вид огибающей также определяется экспериментально, в первом приближении это Гауссово распределение.
5. Вклад каждой форманты. Насколько сильно форманта воздействует на основной сигнал.
Жирным шрифтом выделены параметры, которые будут меняться в процессе речеобразования для получения различных звуков.
Как видно, этих параметров немного, но вполне достаточно для того, чтобы синтезируемые звуки были разборчивыми. Естественно, для получения более качественного синтеза необходимо строить более детальную модель, но для решения поставленной задачи этой модели вполне достаточно.
Синтез речи в системе осуществляется следующим образом:
1. уровни выходов нейронов эффекторного слоя нейросети при помощи карты эффекторов
преобразуются в значения выбранных параметров модели синтеза. Карта эффекторов определяет соответствие между каждым нейроном эффекторного слоя и конкретным параметром модели синтеза, а также предельные значения каждого параметра. Число эффекторов и число параметров модели может не совпадать; если параметру не соответствует ни один эффектор, используется некоторое фиксированное значение (значение по умолчанию).
2. по текущему состоянию модели синтезируется сигнал в пространстве частот: генерируется линейка частот, представляющих голосовой источник, на неё накладывается формантная структура (резонансы). Для синтеза шума используется генератор случайной амплитуды и фазы.
3. выполняется обратное преобразование Фурье для получения звука во временной форме
В этом алгоритме узким местом является размер окна ДПФ. В данной модели синтезируются статичные звуки, т.е. в не происходит изменение параметров в процессе синтеза. В реальной же речи параметры звука меняются при переходе от одного звука к другому, причем меняются непрерывно. Очевидно, при использовании окон ДПФ такой результат получить невозможно – в пределах окна параметры звука меняться не будут (вернее сказать, что невозможно получить приведенным выше алгоритмом; теоретически же благодаря полной обратимости дискретного преобразования Фурье возможно получить спектр для любого сигнала, в том числе и с динамически меняющимися параметрами). Поэтому для генерации звука с изменяющимися параметрами нужно сокращать размер окна ДПФ или брать не весь сгенерированный кадр, а только его часть (естественно, не забывая синхронизировать фазу сигнала).В идеале размер кадра можно свести к одному сэмплу (одному отсчету дискретизации по времени). Этот способ генерации речи дает лучшие по сравнению с ДПФ результаты, но работает гораздо медленнее ДПФ. В системе имеется возможность выбрать используемый способ генерации.
Для исследования формантно-голосовой модели синтеза речи был создан инструмент Модель синтеза, в котором ручным заданием параметров можно синтезировать практически любой гласный или шипящий звук. Также приводятся уже готовые образцы некоторых звуков (в форме параметров модели).
Модель системы анализа речи
Структурная схема системы изображена на рис. 6.
Уровни системы анализа речи
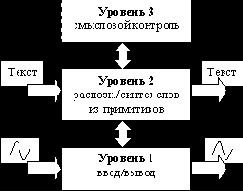
Рис. 6
Система состоит из двух уровней: уровня ввода/вывода, предварительной обработки и выделения примитивов речи, и уровня распознавания/синтеза слов из этих примитивов. Также возможно добавление более высоких уровней, например, уровня смыслового контроля (т.е. управление распознаванием/синтезом речи в контексте предложения, смыслового блока, и т.д.), но это требует других, параллельных со звуковым, источников информации, и ближе к задачам ИИ.
В связи с разделением системы анализа речи на несколько уровней появилась возможность моделировать нейросеть отдельно для каждого уровня в соответствии с требованиями по обработке информации на нём. Но различия в моделях нейросетей должны быть сведены к минимуму, так как такие различия не являются биологически оправданными, кроме того, при аппаратной реализации нейросети гораздо проще работать с однотипными структурами.
Уровень ввода/вывода сигнала

Рис.7
Блок-схема уровня ввода-вывода показана на рис. 7. При распознавании осуществляется ввод звуковой информации, предварительная обработка, получение энергетического спектра и выделение примитивов речи. При синтезе осуществляется выделение из нейросети запомненного примитива, синтез спектра (частотный параметрический синтез), преобразование спектра в звуковой сигнал. При обучении последовательным повторением двух вышеописанных процедур осуществляется запоминание примитивов речи в нейросети.
Обучение нейросети
Обучение системы в целом состоит из трех этапов. Сначала системе предъявляется только образцы звуков, при этом во входном слое формируются нейронные ансамбли, ядрами которых являются предъявляемые образцы. Затем предъявляются звуки и соответствующие им символы алфавита. При этом происходит ассоциация нейронов входного уровня с нейронами символьного слоя. На последнем этапе система обучается синтезу. При этом системе не предъявляются никакие образцы, а используется накопленная на предыдущих этапах информация. Используется механизм стохастического обучения: нейроны эффекторного слоя подвергаются случайным изменениям, затем генерируется звук, он распознается и результат сравнивается с тем символом, для которого был сгенерирован звук. При совпадении изменения фиксируются. Этот процесс повторяется до тех пор, пока не будет достигнута правильная генерация всех звуков.
Выбор скоростей обучения
Зачем в правиле обучения слоя Кохонена (7) присутствует коэффициент a? Если бы он был равен 1, то для каждого входного вектора вектор связей активного нейрона приравнивался бы к нему. Как правило, для каждого нейрона существует множество входных сигналов, которые могли бы его активировать, и его вектор связей постоянно менялся бы. Если же a<1, на каждый входной сигнал активный нейрон реагирует лишь частично. Уменьшая a в процессе обучения, мы в конце обучения получим статистическое усреднение схожих входных сигналов. С этой же целью вводятся скорости обучения во всех остальных обучающих правилах.
Чем определяется скорость обучения? Здесь главную роль играет порядок предъявления образцов. Допустим, имеется большая обучающая выборка, последовательным предъявлением элементов которой обучается нейросеть. Если скорость обучения велика, то уже на середине этой выборки нейросеть «забудет» предыдущие элементы. А если каждый образец предъявляется подряд много раз, то уже на следующем образце нейросеть забудет предыдущий. Таким образом, главный критерий выбора скоростей обучения – незначительное изменение связей в пределах ВСЕЙ обучающей выборки. Но не следует забывать, что время обучения обратно пропорционально скорости обучения. Так что здесь необходимо искать компромисс.
Запоминание редко встречающихся элементов
Описанный выше алгоритм обучения хорош для часто повторяющихся сигналов. Если же сигнал встречается редко на фоне всей обучающей выборки, он просто не будет запомнен. В таком случае необходимо привлечение механизма внимания. При появлении неизвестного нейросети образца скорость обучения многократно возрастает и редкий элемент запоминается в нейросети. В разрабатываемой системе обучающая выборка строится искусственно, поэтому такой проблемы не возникает, и механизм внимания не реализован. Необходимость механизма внимания появляется при обучении в естественных условиях, когда обучающая выборка заранее не предсказуема.
Обучение системы при малом размере обучающей выборки
| Входные данные: | Система анализа речи со следующими стартовыми параметрами:
+Конфигурация нейросети Число входов: 20 Нейронов во входном слое: 10 Нейронов в символьном слое: 5 Эффекторов: 4 +Эффекторы +EF0 Тип: Частота форманты Индекс: 1 Min: 100.0000 Max: 3000.0000 +EF1 Тип: Воздействие форманты Индекс: 1 Min: 0.0000 Max: 0.8000 +EF2 Тип: Частота форманты Индекс: 2 Min: 1000.0000 Max: 4000.0000 +EF3 Тип: Воздействие форманты Индекс: 2 Min: 0.0000 Max: 0.1000 +Скорости обучения alpha0: 0.1000 alpha1: 1.0000 alpha2: 0.0500 alpha3: 0.5000 +Модель синтеза Частота основного тона: 115 Частота шума: 5000.0000 Четкость шума: 0.0500 Число формант: 3 +Форманты +F0 Частота: 100.0000 Четкость: 0.1000 Воздействие: 1.0000 +F1 Частота: 259.7322 Четкость: 0.5000 Воздействие: 0.1362 +F2 Частота: 1824.6669 Четкость: 0.1000 Воздействие: 0.0264 +Алфавит S0='а' S1='и' S2='о' S3='у' S4='?' Обучающая выборка: звуковые файлы с записанными звуками а,и,о,у и соответствующие текстовые файлы. |
| Цель эксперимента: | 1.Анализ процесса обучения при небольшой обучающей выборке, элементы которой близки друг к другу
2.Обучение синтезу сложного сигнала с использованием 4 эффекторов |
| Ход эксперимента: | Как и в предыдущем эксперименте, обучение проводилось в три этапа, перед каждым этапом корректировались значения скоростей обучения. |
| Результат: | Система со 100% результатом распознает тестовые примеры и звуки, произносимые в микрофон. Получены удовлетворительные результаты при обучении синтезу: полученное распределение формант для каждого звука соответствует распределению формант в оригиналах, но уровни (воздействия) формант в некоторых звуках различаются. Предполагается, что это происходит из-за несовпадения огибающих этих формант.
Результат обучения синтезу  Рис. 19 |
| Выводы: | Система хорошо обучается распознаванию, даже если входные сигналы достаточно близки друг другу.
Обучение синтезу длилось дольше, чем в предыдущем эксперименте с одним эффектором – увеличение числа эффекторов существенно снижает эффективность механизма стохастического обучения. Введенные в модель синтеза упрощения (3 форманты и 4 переменных параметра) не позволяют получить качественный синтез. Следовательно, необходимо увеличивать число управляющих параметров, участвующих в синтезе и более точно задавать форму огибающей формант. |
Обучение системы с одним эффектором
| Входные данные: | Система анализа речи со следующими параметрами:
+Конфигурация нейросети Число входов: 10 Нейронов во входном слое: 10 Нейронов в символьном слое: 6 Эффекторов: 1 +Эффекторы +EF0 Тип: Частота форманты Индекс: 0 Min: 100.0000 Max: 5000.0000 +Скорости обучения alpha0: 0.0500 alpha1: 1.6000 alpha2: 0.1000 alpha3: 0.5010 +Модель синтеза Частота основного тона: 115 Частота шума: 5000.0000 Четкость шума: 0.0500 Число формант: 1 +Форманты +F0 Частота: 4048.8281 Четкость: 1.0000 Воздействие: 1.0000 +Алфавит S0='а' S1='б' S2='в' S3='г' S4='д' S5='?' Обучающая выборка: звуковой файл tones.wav с записанными чистыми тонами 100, 500, 1000, 2000, 4000 Гц и текстовый файл, в котором каждому тону соответствует буквы алфавита а,б,в,г,д. (cистема сохранена как /Exp/Exp1/один эффектор.sas) |
| Цель эксперимента: | Проверить способность обучения системы синтезу в простейшем случае - с одним эффектором. Эффектор управляет частотой единственной форманты. |
| Ход эксперимента: | Сначала проводилось обучение на примерах – только звук. При этом в слое Кохонена сформировались нейронные ансамбли для каждого звука. Наблюдался хорошая упорядоченность полученной одномерной карты признаков.
Затем проводилось обучение на примерах – звук и текст. При этом установились правильные связи между нейронами слоя Кохонена и нейронами символьного слоя. Затем проводилось обучение синтезу. В результате в эффекторном слое установились правильные связи с символьным слоем. |
| Результат: | Система успешно обучилась синтезу – синтезируемые звуки в точности соответствуют тонам из обучающей выборки (рис. 18):
Результат обучения синтезу чистых тонов  Обучающая выборка  Результат синтеза Рис. 18 |
| Выводы: | Используемый алгоритм стохастического обучения синтезу хорошо работает в случае малого числа эффекторов. Введение обратной связи в систему позволяет обучаться синтезу при отсутствии обучающей выборки. |
Обзор алгоритмов распознавания речи
Ввод речи и цифровая обработка
Для анализа речи её необходимо преобразовать в форму, понятную вычислительной системе. Это может быть аналоговая форма, цифровая форма, спектральное представление, представление в виде оптического излучения и т.д. Так как в работе затрагивается только моделирования систем анализа речи на персональном компьютере, то рассматривается только один вид представления звука – в цифровой форме. Для представления акустического сигнала в цифровой форме практически во всех системах, имеющих дело со звуком, используется импульсная модуляция. Как известно, звук представляет собой продольные волны разрежения-сжатия, распространяющиеся в акустичеки-проводящей среде. Посредством звукозаписывающих устройств (например, микрофона) он преобразуется в электрический сигнал, колебания которого повторяют звуковые колебания (рис 2).
Ввод звука в компьютер

Рис. 2
Затем этот сигнал фильтруется с целью отсечения частот, превышающих некоторую частоту fmax. После этого он подается на аналого-цифровой преобразователь, который с некоторой частотой fd, называемой частотой дискретизации, записывает текущий уровень сигнала в цифровой форме, т.е. квантует сигнал по времени и по амплитуде. Как следует из теоремы Колесникова,

Таким образом, параметрами, определяющими качество оцифровки сигнала, являются частота дискретизации (fd) и разрядность преобразования (сколько единиц информации кодирует один отсчет). Частота дискретизации определяет максимальную частоту сигнала, которую можно записать. Типичные значения - 11025, 22050, 44100 Гц. От разрядности зависит точность кодирования информации при аналого-цифровом преобразовании. Типичные значения – 4 бит, 8 бит, 16 бит на отсчет. Естественно, чем больше разрядность и частота дискретизации, тем точнее записывается звук, но и тем больше поток информации и тем сложнее его записать или обработать. Технические вопросы ввода звука в компьютер в разрабатываемой системе подробно рассматриваются в приложении 7.5.
Предварительная обработка и выделение первичных признаков
Речевой сигнал, поступающий в систему распознавания речи, подвергается предварительной обработке с целью компенсации погрешностей ввода звука и учета специфики сигнала. Как правило, такая обработка заключается в очистке сигнала от шума (например, отсечением неинформативных участков спектра), фильтрации, нормализацией до некоторого установленного уровня.
Затем необходимо выделить информативные признаки речевого сигнала, т.е. те, которые наиболее полно описывают сигнал в наиболее краткой форме. Очевидно, эффективность этого этапа определяет эффективность дальнейшей обработки сигнала и его распознавание. Понятно, что временное представление сигнала является довольно неэффективным, т.к. во-первых, не учитывает периодичности звука, во-вторых, из-за большой изменчивости речи даже один и тот же звук, произнесенный одним и тем же человеком, сильно варьируется в его временном представлении.
Гораздо более информативно спектральное представление речи. Для получения спектра используют набор полосовых фильтров, настроенных на выделение различных частот, или дискретное преобразование Фурье. Затем полученный спектр подвергается различным преобразованиям, например, логарифмическое изменение масштаба (как в пространстве амплитуд, так и в пространстве частот), сглаживание спектра с целью выделения его огибающей, кепстральному анализу (обратное преобразование Фурье от логарифма прямого преобразования, см. [3], Cepstral analysis). Это позволяет учесть некоторые особенности речевого сигнала – понижение информативности высокочастотных участков спектра, логарифмическую чувствительность человеческого уха, и т.д.
Как правило, полное описание речевого сигнал только его спектром невозможно. Наряду со спектральной информацией, необходима ещё и информация о динамике речи. Для её получения используют дельта-параметры, представляющие собой производные по времени от основных параметров.
Полученные таким образом параметры речевого сигнала считаются его первичными признаками и представляют сигнал на дальнейших уровнях его обработки.
Выделение примитивов речи
Под примитивами речи понимается неделимые звуки речи – фонемы, из которых и образуется сложная речь (относительно количества фонем идут постоянные споры: по некоторым данным, в русском языке 43 фонемы, по другим – 64, по третьим – более 100). Выделение и распознавание этих примитивов – первый этап распознавания в большинстве существующих систем. От его эффективности во многом зависит дальнейший ход распознавания на последующих этапах.
В случае применения нейросетей обучение выделению примитивов речи может заключаться в формировании нейронных ансамблей, ядра которых соответствуют наиболее частой форме каждого примитива [6]. Формирование нейронных ансамблей – это процесс обучения без учителя, при котором происходит статистическая обработка всех поступающих на вход нейросети сигналов. При этом формируются ансамбли, соответствующие наиболее часто встречающимся сигналам. Запоминание редких сигналов происходит позже и требует подключения механизма внимания или иного контроля с высших уровней.
Распознавание сложных звуков, слов, фраз, и т.д.
Для распознавания слитной речи наиболее простой и понятной является построение системы в виде иерархии уровней, на каждом из которых распознаются звуки все большей сложности: на первом – фонемы, на втором – слоги, затем слова, фразы, и т.д. На каждом уровне сигнал кодируется представителями предыдущих уровней. При переходе с уровня на уровень помимо представителей сигналов передаются и некоторые дополнительные признаки, временные зависимости и отношения между сигналами. Собирая сигналы с предыдущих уровней, высшие уровни располагают большим объемом информации (или её другим представлением), и могут осуществлять управление процессами на низших уровнях, например, с привлечением механизма внимания (см. приложение 7.3).
Определение нейрокомпьютера
Под термином нейрокомпьютер понимается вычислительная система (система, производящая обработку информации), моделирующая с той или иной степенью точности реальные биологические нейросети, и обладающая следующими основными свойствами:
§ Значащим уровнем анализа является не активность одного элемента, но паттерн активности многих элементов
§ Система состоит из простых элементов и сложных связей между ними
§ Элементы взаимодействуют посредством возбуждения и торможения
§ Эффективность обработки информации осуществляется не за счет высокого быстродействия отдельных элементов, а за счет одновременной работы многих элементов (массовый параллелизм).
§ Минимальный контроль извне: система сама определяет свое поведение, как правило, это стремление к устойчивому состоянию
§ Поведение системы не программируется заранее, а формируется за счет её обучения (модификации пластических элементов)
§ Правила модификации локальны (определяются текущим состоянием и активностью в окрестности точки локализации)*
§ Система устойчива к потере небольших объемов информации и флуктуациям состояния отдельных элементов**
* Это свойство необязательно, но оно позволяет существенно упростить аппаратную реализацию нейросетевых моделей, когда будет необходимо создавать множество связей между элементами.
** Это свойство является особенностью биологических нейросетей, в которых постоянно происходит потеря информации за счет гибели клеток и естественных физиологических процессов.
В таблице 1 приведены основные отличия нейрокомпьтера от классического компьютера - машины Фон Неймана:
Таблица 1
Отличие нейрокомпьютера от машины Фон Неймана
| Машина фон Неймана | Биологическая нейронная система | |
| Процессор | Сложный | Простой |
| Высокоскоростной | Низкоскоростной | |
| Один или несколько | Большое количество | |
| Память | Отделена от процессора | Интегрирована в процессор |
| Локализована | Распределенная | |
| Адресация не по содержанию | Адресация по содержанию | |
| Вычисления | Централизованные | Распределенные |
| Последовательные | Параллельные | |
| Хранимые программы | Самообучение | |
| Надежность | Высокая уязвимость | Живучесть |
Пример одного слоя простейшей нейросети изображен на рис.1. В основе большинства нейросетевых моделей лежит концепция распространения информации от одного слоя к другому по связям (матрица связей W). При этом сигналы представляются векторами (X,Y), и обработка сигнала в одном слое выглядит следующим образом:

X-вектор входа,
А-вектор нейронных входов,
Y – вектор выхода.
Пример одного слоя простой нейросети

Рис. 1
В разделе 5.2 подробно описывается выбранная для построения системы анализа речи модель нейросети. За более полной информацией по существующим нейросетевым алгоритмам обращайтесь к [1],[6],[7],[8].
Принципы построения самообучающихся систем
Чем отличается работа, которую выполняют роботы и которую может выполнить человек? Роботы могут обладать качествами, намного превосходящими возможности людей: высокая точностью, сила, реакция, отсутствие усталости. Но вместе с тем они остаются просто инструментами в руках человека. Существует работа, которая может быть выполнена только человеком и которая не может быть выполнена роботами (или необходимо создавать неоправданно сложных роботов) . Главное отличие человека от робота – это способность адаптироваться к изменению обстановки. Конечно, практически у всех роботов существует способность работать в нескольких режимах, обрабатывать исключительные ситуации, но все это изначально закладывается в него человеком. Таким образом, главный недостаток роботов – это отсутствие автономности (требуется контроль человека) и отсутствие адаптации к изменению условий (все возможные ситуации закладываются в него в процессе создания). В связи с этим актуальна проблема создания систем, обладающих такими свойствами.
Один из способов создать автономную систему с возможностью адаптации – это наделить её способностью обучаться. При этом в отличие от обычных роботов, создаваемых с заранее просчитанными свойствами, такие системы будут обладать некоторой долей универсальности.
Попытки создания таких систем предпринимались многими исследователями, в том числе и с использованием нейросетей. Один из примеров – созданный в Киевском Институте кибернетики еще в 70-х годах макет транспортного автономного интегрального робота (ТАИР) [7]. Этот робот обучался находить дорогу на некоторой местности и затем мог использоваться как транспортное средство.
Вот какими свойствами, по моему мнению, должны обладать самообучающиеся системы:
1.Разработка системы заключается только в построении её архитектуры. В процессе создания системы разработчик создает только функциональную часть, но не наполняет (или наполняет в минимальных объемах) систему информацией. Основную часть информации система получает в процессе обучения.
2.Возможность контроля своих действий с последующей коррекцией
Этот принцип говорит о необходимости обратной связи Действие-Результат-Коррекция в системе . Такие цепочки очень широко распространены в сложных биологических организмах и используются на всех уровнях – от контроля мышечных сокращений на самом низком уровне до управления сложными механизмами поведения.
3.Возможность накопления знаний об объектах рабочей области
Знание об объекте – это способность манипулировать его образом в памяти т.е. количество знаний об объекте определяется не только набором его свойств, но ещё и информацией о его взаимодействии с другими объектами, поведении при различных воздействиях, нахождении в разных состояниях, и т.д., т.е. его поведении во внешнем окружении (например, знание о геометрическом объекте предполагает возможность предсказать вид его перспективной проекции при любом повороте и освещении). Это свойство наделяет систему возможностью абстрагирования от реальных объектов, т.е. возможностью анализировать объект при его отсутствии, тем самым открывая новые возможности в обучении
4. Автономность системы
При интеграции комплекса действий, которые система способна совершать, с комплексом датчиков, позволяющих контролировать свои действия и внешнюю среду, наделенная вышеприведенными свойствами система будет способна взаимодействовать с внешним миром на довольно сложном уровне, т.е. адекватно реагировать на изменение внешнего окружения (естественно, если это будет заложено в систему на этапе обучения). Способность корректировать свое поведение в зависимости от внешних условий позволит частично или полностью устранить необходимость контроля извне, т.е. система станет автономной.
Проблемы, возникающие при обучении слоя Кохонена
Для исследования динамики обучения и свойств слоя Кохонена был создан инструмент «Модель нейросети», в котором моделируется слой Кохонена в двумерном сигнальном пространстве (Рис 16).
Моделирование слоя Кохонена

1. Начальные значения весов 2. Веса после обучения
Рис.16
В инструменте моделируется нейросеть с двумя входами, так что она способна классифицировать входные вектора в двумерном сигнальном пространстве. Хотя функционирование такой нейросети и отличается от функционирования нейросети в сигнальном пространстве с гораздо большей размерностью, основные свойства и ключевые моменты данного нейросетевого алгоритма можно исследовать и на такой простой модели. Главное преимущество – это хорошая визуализация динамики обучения нейросети с двумя входами.
В ходе экспериментов с этой моделью были выявлены следующие проблемы, возникающие при обучении нейросети:
1. выбор начальных значений весов.
Так как в конце обучения вектора весов будут располагаться на единичной окружности, то в начале их также желательно отнормировать на 1.00. В моей модели вектора весов выбираются случайным образом на окружности единичного радиуса (рис. 16.1).
2. использование всех нейронов.
Если весовой вектор окажется далеко от области входных сигналов, он никогда не даст наилучшего соответствия, всегда будет иметь нулевой выход, следовательно, не будет корректироваться и окажется бесполезным. Оставшихся же нейронов может не хватить для разделения входного пространства сигналов на классы. Для решения этой проблемы предлагается много алгоритмов ([1],[8]). в моей работе применяется правило «желания работать»: если какой либо нейрон долго не находится в активном состоянии, он повышает веса связей до тех пор, пока не станет активным и не начнет подвергаться обучению. Этот метод позволяет также решить проблему тонкой классификации: если образуется группа входных сигналов, расположенных близко друг к другу, с этой группой ассоциируется и большое число нейронов Кохонена, которые разбивают её на классы (рис. 16.2).
Правило «желания работать» записывается в следующей форме:
wн=wc + a1
, (9)
где wн - новое значение веса,
wс – старое значение,
a1 - скорость модификации,
Выбор коэффициента a1 определяется следующими соображениями: постоянный рост весов нейронов по правилу (9) компенсируется правилом (7) (активные нейроны стремятся снова вернуться на гиперсферу единичного радиуса), причем за одну итерацию нейросети увеличат свой вес практически все нейроны, а уменьшит только один активный нейрон или нейронный ансамбль. В связи с этим коэффициент a1 в (9) необходимо выбирать значительно меньше коэффициента a в (7), учитывая при этом число нейронов в слое.
3. неоднородное распределение входных векторов в пространстве сигналов и дефицит нейронов.
Очень часто основная часть входных векторов не распределена равномерно по всей поверхности гиперсферы, а сосредоточена в некоторых небольших областях. При этом лишь небольшое количество весовых векторов будет способно выделить входные вектора, и в этих областях возникнет дефицит нейронов, тогда как в областях, где плотность сигнала намного ниже, число нейронов окажется избыточным.
Для решения этой проблемы можно использовать правило «нахождения центра масс», т.е. небольшое стремление ВСЕХ весовых векторов на начальном этапе обучения к входным векторам. В результате в местах с большой плотностью входного сигнала окажется и много весовых векторов. Это правило записывается так:
wн
= wс + a2(x
– wс). (10)
где wн - новое значение веса,
wс – старое значение,
a2 - скорость модификации,
x – входной вектор
Это правило хорошо работает, если нейроны сгруппированы в одном месте. Если же существует несколько групп нейронов, то это правило не дает нужного результата.
Ещё одно решение – использовать «отжиг» весовых векторов. В нашем случае он может быть реализован как добавление небольшого шума при модификации весов, что позволит им перемещаться по поверхности гиперсферы.
При обучении уровень шума постепенно понижается, и весовые вектора собираются в местах наибольшей плотности сигнала.
Недостаток этого правила – очень медленное обучение. Если в двумерном пространстве нейроны «находили» входные вектора более-менее успешно, то в многомерном пространстве вероятность этого события существенно снижается.
Самым эффективным решением оказалось более точное моделирование механизма латерального торможения. Как и раньше, находится нейрон с максимальной активностью. Затем искусственно при помощи латеральных связей устанавливается активность окружающих его нейронов по правилу (11):

где aj – активность нейрона
i - выигравший нейрон
j – индекс нейрона

При этом предполагается, что все нейроны имеют определенную позицию по отношению к другим нейронам. Это топологическое отношение одномерно и линейно, позиция каждого нейрона определяется его индексом. Правило (11) говорит о том, что возбуждается не один нейрон, а группа топологически близких нейронов. В результате обучения образуется упорядоченная одномерная карта признаков. Упорядоченность означает, что ближайшие два нейрона в ней соответствуют двум ближайшим векторам в пространстве сигнала, но не наоборот (так как невозможно непрерывно отобразить многомерное пространство на одномерное, [6]). Сначала радиус действия латеральных связей достаточно большой, и в обучении участвуют практически все нейроны. При этом они находят «центр масс» всей обучающей выборки. В процессе обучения коэффициент
Проблемы, возникающие при распознавании речи
Во-первых, звуки речи различаются по длительности. Один и тот же звук, но произнесенный в разных словах, значительно варьируется по длительности. Например, длительность звука а в слове сад составляет 250-300 мс, а в слове садовод около 60 мс. Опытным путем установлена постоянная времени человеческого слуха, т.е. минимальная длительность звука, при которой ухо может проанализировать, узнать это звук. Эта величина равняется приблизительно 30-50 мс.
Во-вторых, желательно, чтобы система распознавания речи была независима от диктора. Но голоса отдельных людей очень сильно отличаются друг от друга, так что решение этой проблемы является непростой задачей.
В-третьих, речь даже одного человека подвержена сильным изменениям в результате разного эмоционального состояния говорящего. При этом может меняться темп речи, высота, ширина динамического диапазона (вариации по частоте и громкости).
В-четвертых, при распространении звука в пространстве он подвергается довольно сильным искажениям. Такие эффекты, как эхо, реверберация, изменение спектрального состава в результате неоднородного поглощения звука в среде, и т.д., очень сильно искажают звук.
Очевидно, что о простой записи слов в базу данных и последующем распознавании речи путем сравнения с записанными образцами не может быть и речи. Два временных представление звука речи даже для одного и того же человека, записанные в один и тот же момент времени, не будут совпадать. Необходимо искать такие параметры речевого сигнала, которые полностью описывали бы его (т.е. позволяли бы отличить один сигнал от другого), но были бы инвариантны относительно описанных выше вариаций речи. Полученные таким образом параметры должны затем сравниваться с образцами, причем это должно быть не простое сравнение на совпадение, а поиск наибольшего соответствия. Это вынуждает искать нужную форму расстояния в найденном параметрическом пространстве.
При определении объема хранимых системой данных также возникают определенные трудности. Как записать практически бесконечное число вариаций звуков речи в отведенный размер памяти? Очевидно, что здесь не обойтись без какой-либо формы статистического усреднения. Ещё одна проблема – уменьшение быстродействия системы при обработке большого количества данных, а ведь распознавание речи в большинстве случаев должно происходить в реальном времени!
В разделе 4.3. показано, что использование нейросетевых алгоритмов позволяет решить большинство перечисленных проблем.
Работа со звуком на платформе Windows
Современное развитие аппаратных и программных средств делает работу со звуком довольно простой и практически все пользователи персональных компьютеров не испытывают при этом затруднений. Точно так же обстоит дело и при программировании приложений, работающих со звуком. В ОС Windows имеется мощный интерфейс Multimedia API, позволяющий разработчику использовать возможности всех современных устройств мультимедиа без привязки к конкретной модели и фирме-производителю устройства. В моей работе используется ввод и обработка звука в реальном времени, и здесь я кратко опишу некоторые технические вопросы и возникшие сложности при реализации этого процесса.
Запись и воспроизведение звука в компьютере осуществляется посредством звуковой карты – платы, вставляющейся в стандартный слот ISA или PCI, на которой имеется несколько аудио входов/выходов, АЦП, ЦАП, предварительные/буферные усилители, цифровые микшеры, фильтры и, возможно, процессор цифровой обработки сигнала. Стандартные частоты дискретизации – 11025, 22050, 44100 и 48000 Гц, разрядность данных 4, 8, 16 бит на отсчет, один или два канала. В системе может быть установлено несколько устройств записи звука, можно использовать каждое в отдельности или устройство по умолчанию.
Процесс ввода звука в компьютер представлен таблицей 1:
Таблица 1
Ввод звука в компьютер при помощи Multimedia API в Windows
| Действие | Функция Windows |
| Открытие устройства записи с заданными параметрами | waveInOpen |
| Подготовка блоков памяти для записи
(выделение памяти и создание заголовков) |
waveInPrepareHeader |
| Добавление всех блоков в очередь записи | waveInAddBuffer |
| Начало записи | waveInStart |
| …………..
Обработка события окончания записи очередного блока и добавление в очередь нового ……………. |
Реакция на сообщение, функция обратного вызова, сброс объекта-события |
| Окончание записи | waveInStop,
waveInReset |
| Освобождение заголовков блоков и освобождение памяти | waveInUnprepareHeader |
| Закрытие устройства | waveInClose |
При открытии устройства и начале записи создается непрерывный процесс, который записывает вводимые звуковые данные в находящиеся в очереди записи блоки памяти. При записи очередного блока он удаляется из очереди и приложение информируется об окончании записи блока. Можно задать несколько способов: посредством сообщений некоторому окну или процессу, функцией обратного вызова (callback), через объект-событие. Приложение обрабатывает записанный блок и добавляет в очередь новый. При отсутствии блоков в очереди ошибки не выдается, просто теряются поступающие данные, поэтому всегда надо следить, чтобы в очереди был пустой блок. Наиболее простая схема записи без потери данных – запись с двумя блоками.
Проблема синхронизации процессов записи, обработки и визуализации.
В разрабатываемой мной системе осуществляется как обработка и визуализация звука в реальном времени, так и сохранение записываемых данных в файл. В первом случае важна синхронизация процесса обработки сообщений главным окном приложения и процесса записи. Если процесс записи непрерывный, то процесс главного окна помимо сообщений от звукозаписи обрабатывает ещё множество сообщений графического интерфейса Windows (например, перемещение курсора или нажатие кнопок). Во втором случае наоборот важна независимость процесса записи от процесса главного окна, чтобы исключить потерю данных. Очевидно, что использование механизма обработки сообщений о записи блоков главным окном невозможно как в первом, так и во втором случае (что и показал опыт разработки первой версии программы). В первом случае если время обработки блока аудиоданных будет меньше времени его записи (что вполне возможно в связи со сложностью вычислений и визуализации), то очередь сообщений главного окна очень быстро переполнится и приложение “зависнет”, т.е. перестанет реагировать на действия пользователя. Во втором случае будет происходить потеря данных, т.к. приложение помимо сообщений звукозаписи будет обрабатывать сообщения Windows (например, при перемещении окна обработка очереди сообщений прекращается).
Проблема решается созданием ещё одного процесса, независимого от процесса главного окна. Он обрабатывает сообщения от звукозаписи и может при помощи механизма синхронизации передавать блоки на для обработки окну приложения.
Применительно к конкретной среде C++ Builder мной создан класс TWaveRecorder, унаследованный от класса TThread, в котором полностью реализуется описанный выше механизм. Схема процессов и взаимодействия между ними изображена на рис. 1
Взаимодействие процессов при вводе звука

Рис. 1
Запись начинается сразу после создания экземпляра класса TWaveRecorder. Конструктору передается формат аудиоданных, размер блоков, адрес функции-обработчика записанных блоков и необходимость синхронизации с окном приложения. Завершается запись функцией TWaveRecorder::Stop() или удалением объекта.
Распознавание речи
Задачу распознавания речи считают средоточием всех задач искусственного интеллекта [2]. При построении систем распознавания речи охватывается очень широкий круг вопросов: от построения датчиков, позволяющих вводить речь в компьютер, до сложнейших баз данных, позволяющих использовать смысловую нагрузку речи и распознавать слова в контексте целых предложений и фраз. При этом отдельные задачи в этой области далеко не тривиальны.
Что понимается под распознаванием речи? Это может быть преобразование речи в текст, распознавание и выполнение определенных команд, выделение из речи каких либо характеристик (например, идентификация диктора, определение его эмоционального состояния, пола, возраста, и т.д.) – все это в разных источниках может попасть под это определение. В моей работе под распознаванием речи понимается отнесение звуков речи или их последовательности (фонем, букв, слов) к какому-либо классу. Затем этому классу могут быть сопоставлены символы алфавита – получим систему преобразования речи в текст, или определенные действия – получим систему выполнения речевых команд. Вообще этот способ обработки речевой информации может использоваться на первом уровне какой-либо системы с гораздо более сложной структурой. И от эффективности этого классификатора будет зависеть эффективность работы системы в целом.
Сети с латеральным торможением (карты признаков Кохонена)
1. Идея метода
Этот класс нейросетей выполняет переработку входной информации с целью формирования одно- или двумерной “карты признаков” путем нелинейного преобразования многомерного сигнального пространства. При этом предполагается, что такое отображение должно сохранять топологические отношения, существующие между входными сигналами. Реализация такого отображения основывается на использовании механизма латерального торможения – особой организации нейронных связей, которая встречается в живых нейробиологических системах и хорошо известна в нейрофизиологии.
2. Архитектура
Нейроны расположены в виде одно- или двумерного слоя. Каждый нейрон имеет два вида связей: mij, которые интерпретируются как связи от сенсорных входов или других областей системы, и wij – латеральные связи между нейронами одного слоя, характер которых описывается какой либо топологической зависимостью. Рассмотрим случай, когда веса связей зависят от расстояния между нейронами. Эта зависимость выражается изображена на рис.1:
Характер действия латеральных связей
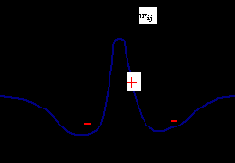
Рис. 1
Каждый нейрон связан с ближайшими к нему нейронами сильными возбуждающими связями. Затем на некотором расстоянии возбуждение сменяется торможением, и далее вновь проявляются слабые возбуждающие связи. Нейроны имеют сигмоидальную переходную функцию. Латеральные связи wjk в модели считаются постоянными, изменяются только связи mij.
Работа сети начинается с подачи на вход входного вектора X. Затем для каждого узла вычисляется нейронная активность согласно итеративной формуле (1):

Процесс прекращается при установлении стабильного состояния, при этом вектор S будет искомым отображением X на карту признаков (в S останется активным один или несколько элементов, соответствующих некоторому признаку).
При подаче на вход сети сигнала, представленного вектором X, вокруг нейрона, связи которого mij наиболее соответствуют входному вектору (т.е.

будет максимальным) образуется пузырёк активности (рис.2) , контрастность которого при выполнении итераций постепенно повышается.
Изменение уровней активности нейронов после 10 итераций

Рис. 2
3. Обучение
Обучение такой сети заключается в коррекции весов связей mij для получения желаемого отображения. Сеть обучается без учителя. Вводится следующий закон модификации весов связей:

где a, b – положительные константы.
Если учесть, что соотношение активностей (y) внутри и вне пузырька практически бинарное, и промасштабировать переменные так, что a=b, правило (3) переходит в (4):

где NC – «пузырёк».
Обычно пластичность а и радиус пузырька NC монотонно уменьшаются в процессе обучения.
Т.о. в результате обучения в сети должна формироваться непрерывная упорядоченная карта признаков сигнального пространства. Непрерывность следует из того, что связи соседних пузырьков модифицируются в одном направлении, что приводит к сглаживанию их величин. Упорядоченность была доказана только для одномерного отображения.
Алгоритм обучения
Входные данные: обучающая выборка (набор входных векторов)
Выходные данные: скорректированные связи mij
1. Предъявить сети входной вектор
2. Выполнять итерации до установления стабильного состояния
3. Для всех узлов сети выполнить коррекцию связей согласно (2) или (3)
4. Повторять [1-3] для каждого входного вектора
4. Пример (экспериментальные данные)
Существуют многочисленные экспериментальные данные функционирования сетей с латеральным торможением в двухмерном сигнальном пространстве. В одной из моделей сеть состояла из 100 нейронов и матрицы связей M от двух входных нейронов (x1, x0). Обучение сети выполнялось по вышеописанному алгоритму и проиллюстрировано на рис.3. Здесь каждая точка изображает значения весов связей, каждая линия соединяет топологически ближайшие нейроны.
Функционирование карты Кохонена в двумерном пространстве

Рис. 3
Вначале веса связей выбраны произвольно внутри круга в середине сигнального пространства. После обучения получено равномерное и непрерывное отображение входного пространства на 2-мерную карту признаков.
Синтез речи
Синтез речи – задача, решенная намного лучше, чем задача распознавания. Существует много методов синтеза речи, но в основе большинства из них лежит две модели: компилятивный синтез - синтез речи путем конкатенации (составления) записанных образцов отдельных звуков, произнесенных диктором, и формантно-голосовая модель, в которой моделируется с той или иной степенью точности речевой тракт человека. Первая модель требует очень кропотливой работы по созданию звуковой базы данных, и самообучение этой модели представляется крайне затруднительным. Вторая модель, напротив, допускает самообучение в широких пределах, хорошо интегрируется в нейросетевую модель, но в связи со сложностью моделирования речевого тракта человека обладает низкой точностью синтезируемого звука. Тем не менее, уже при довольно простом моделировании синтезируемые звуки разборчивы, поэтому для исследовательских целей она предпочтительней первой.
Для построения модели синтеза речи естественно разобраться, каким образом речь синтезируется человеком. На рис. 3 схематически изображен речевой аппарат человека (см. [5]).
Речевой аппарат человека

Рис. 3
Дыхательные органы (легкие, бронхи, дыхательное горло) служат для передачи звуковых колебаний, возникающих в артикуляционном аппарате, во внешнюю среду. Источником колебаний при образовании звуков речи могут быть прежде всего голосовые связки. Голосовой источник принимает активное участие в образовании гласных и всех звонких согласных: колебания голосовых связок образуют основной тон голоса, частота которого зависит от физических свойств связок (в основном от длины и толщины) и степени их натяжения (что дает возможность изменять основной тон в широких пределах). Кроме основного тона голосовой звук содержит большое число гармоник. В основном это гармоники, кратные основному тону, и их появление хорошо объясняется теорией колебаний.
Кроме голоса, возможны другие источники звука, а именно – шумовые источники – турбулентный и импульсный. Турбулентный шум образуется при наличии сужения в каком-либо месте речевого аппарата.
В результате этого воздушный поток, поступающий из легких по относительно широкому проходу, в месте сужения создает вихревые потоки, вызывающие специфический шум, который мы слышим при образовании таких согласных, как с, ш, х. Импульсный источник вызывает звук при образовании таких согласных, как п, т, к, когда происходит резкое прерывание воздушной струи, создается избыточное давление за местом смыкания артикуляционных органов, а затем его внезапный спад при раскрытии смыкания.
Но кроме действия этих трех источников и их комбинаций вклад в звукообразование вносят резонансы
в многочисленных полостях речевого тракта. Резонансы могут усиливать или ослаблять какие-то частоты, тем самым ещё больше усложняя звук. Эти усиленные частоты называются формантами. Число формант ограничено, специалистами выделяется не более четырех формант, активно участвующих в речеобразовании ([5]). В процессе речеобразования происходит постоянное изменение формант в результате изменение положения артикуляционных органов, их твердости, объема полостей, и т.д. На рисунке 4 четко виден формантный состав гласных и и у. При переходе от гласной и происходит смещение частоты форманты F2 c 2400 Гц на 784 Гц и одновременное ослабление формант F3, F4. (Спектр получен инструментом Анализатор для файла а-о-и-у.wav при размере окна FFT 256 сэмплов, окне сглаживания Хэмминга и логарифмическом масштабе).
Спектр файла “а-о-и-у.wav” при переходе с и
на у.

Рис. 4
Образование шипящих звуков также хорошо объясняется действием резонансов. Например, спектр звука х представляет собой шум с характерной для резонансов огибающей (рис. 5)
Спектр файла х.wav

Рис. 5
Построение формантно-голосовой модели синтеза речи подробно описывается в разделе 5.3.
Система распознавания речи как самообучающаяся система
С целью изучения особенностей самообучающихся систем модели распознавания и синтеза речи были объединены в одну систему, что позволило наделить её некоторыми свойствами самообучающихся систем. Это объединение является одним из ключевых свойств создаваемой модели. Что послужило причиной этого объединения?
Во-первых, у системы присутствует возможность совершать действия (синтез) и анализировать их (распознавание), т.е. свойство (2). Во-вторых, система обладает свойством (1), так как при разработке в систему не закладывается никакая информация, и возможность распознавания и синтеза звуков речи – это результат обучения. Так как система реализована на основе нейросети, то она обладает и свойством (4), ведь самоорганизация - один из базовых принципов нейросетевой обработки информации. Наконец, свойство (3) наделяет систему возможностью автоматического обучения синтезу. Механизм этого обучения описывается в разделе 5.2.3.
Ещё одной очень важной особенностью является возможность перевода запоминаемых образов в новое параметрическое пространство с гораздо меньшей размерностью. Эта особенность на данный момент в разрабатываемой системе не реализована и на практике не проверена, но тем не менее я постараюсь кратко изложить её суть на примере распознавания речи.
Предположим, входной сигнал задается вектором первичных признаков в N-мерном пространстве. Для хранения такого сигнала необходимо N элементов. При этом на этапе разработки мы не знаем специфики сигнала или она настолько сложна, что учесть её затруднительно. Это приводит к тому, что представление сигнала, которое мы используем, избыточно. Далее предположим, что у нас есть возможность синтезировать такие же сигналы (т.е. синтезировать речь), но при этом синтезируемый сигнал является функцией вектора параметров в M-мерном пространстве, и M<<N (действительно, число параметров модели синтеза речи намного меньше числа первичных признаков модели распознавания речи). Но тогда мы можем запоминать входной сигнал не по его первичным признакам в N-мерном пространстве, а по параметрам модели синтеза в M-мерном пространстве. Возникает вопрос: а как переводить сигнал из одного параметрического пространства в другое? Есть все основания предполагать, что это преобразование можно осуществить при помощи довольно простой нейросети. Более того, по моему мнению, такой механизм запоминания работает в реальных биологических системах, в частности, у человека.
Список использованных источников
1. Ф. Уоссермен «Нейрокомпьютерная техника: Теория и практика». /Перевод на русский язык Ю. А. Зуев, В. А. Точенов, М., Мир, 1992. (имеется электронный вариант /Doc/Нейрокомпьютерная техника)
2. Винцюк Т.К. «Анализ, распознавание и интерпретация речевых сигналов.» /Киев: Наук. думка, 1987. -262 с.
3. Speech Analysis FAQ - http://svr-www.eng.cam.ac.uk/~ajr/SA95/SpeechAnalysis.html (имеется электронный вариант /Doc/Speech Analysis/)
4. Г. Нуссбаумер «Быстрое преобразование Фурье и алгоритмы вычисления сверток» / Перевод с англ. – М.: Радио и связь, 1985. –248 с.
5. Л.В.Бондарко «Звуковой строй современного русского языка» /М.: Просвещение, 1997. –175 с.
6. Э.М.Куссуль «Ассоциативные нейроподобные структуры» /Киев, Наукова думка, 1990 (имеется электронный вариант /Doc/Ассоциативные нейроподобные структуры/)
7. Н.М. Амосов и др. «Нейрокомпьютеры и интеллектуальные роботы» /Киев: Наукова думка, 1991
8. А.Н.Горбань, В.Л.Дунин-Барковский, А.Н.Кирдин и др. «Нейроинформатика» / Новосибирск: Наука. Сибирское предприятие РАН, 1998. - 296с. (имеется электронный вариант /Doc/Нейроинформатика)
Теория адаптивного резонанса
1. Идея метода
Теория адаптивного резонанса является одной из самых развитых и продуманных систем нейросетевой обработки информации, впервые была предложена в начале 70-х годов и детализирована в работах Гроссберга. Её стержнем является модель нейронной сети и алгоритмы управления ею, всё вместе образует самостоятельную систему, которая способна самообучаться распознаванию образов различной степени сложности. Она относит входной образ к одному из классов, на который он больше всего похож. Если входной образ не соответствует ни одному из запомненных, создается новый класс путем его запоминания. Если найден образ, с определенным допуском соответствующий входному, то он модифицируется так, чтобы стать ещё больше похожим на входной.
2. Архитектура системы
Архитектура системы изображена в виде блок-схемы на рис. 1:
Теория адаптивного резонанса

F1 – первое нейронное поле
F2 – второе нейронное поле
КВП – кратковременная память
ДВП – долговременная память
X, I, V, S – паттерны активности
УГВ – управляемый генератор возбуждения
mij, mji – матрицы весов связей, реализующие ДВП
g – порог бдительности
Рис. 1
3. Алгоритм работы
Функционирование системы происходит следующим образом:
1. Входной образ I подается на вход F1
2. Наличие I на входе F1 включает УГВ1, который выдает на F сигнал подвозбуждения G (для поля F1 действует правило «2 из 3», в соответствии с которым нейрон становится активным только тогда, когда он возбуждается сигналами одновременно с двух источников)
3. После «включения» УГВ1 на выходе F1 появится паттерн активности X, совпадающий с I. Из-за идентичности I и X подсистемой ориентации не генерируется сигнал торможения КВП F2 (т.е. УГВ2 не включен)
4. Сигнал X с F1 приходит по связям mij и трансформируется во входной вектор S поля F2
5. F2 представляет собой аналог карты признаков Кохонена (см.
«Сети с латеральным торможением»), для случая когда пузырек активности сосредоточен в одном нейроне. Т.о. после подачи на вход F2 паттерна S на выходе появляется паттерн Y, который представляет собой гипотезу системы относительно того, на какой из классов больше похож входной образ I
6. Паттерн Y проходит сверху вниз через связи mji
и преобразуется в паттерн-шаблон V, который представляет собой декодированный след памяти, соответствующий эталонному образцу того класса, к которому был отнесен I
7. Теперь в поле F1 поступают два паттерна: I (снизу) и V (сверху). Наличие активности F2 отключает УГВ1, и согласно правилу «2 из 3» в F1 останутся активными только те нейроны, которые получают возбуждение и от I, и от V. Следовательно, если прочитанный паттерн-шаблон V сильно отличается от I, активность F1 значительно тормозится. Теперь на выходе F1 – паттерн X*
8. Вычисляется отношение размеров |X*| к размеру |I|. Полученная величина сравнивается с «порогом бдительности» g.
 |
 |
|
9. УГВ2 не генерирует сигнал сброса, система переходит в стабильное состояние 10. В устойчивом состоянии происходит обучение системы. Возможны два варианта: 1) Поиск привел к активации уже имеющегося эталона (т.е. в КВП F2 возбудился нейрон, соответствующий одному из известных классов). В этом случае обучение может рафинировать эталон (содержащийся в mji) и критерий допуска к нему (mij) так, чтобы в следе ДВП сохранились только общие с I признаки. 2) Поиск привел к незанятому нейрону в F2 (т.е. I не был отнесён ни к одному из классов, но его эталон содержался в mji). В этом случае обучение добавит к уже существующим новый эталон, совпадающий с I. |
9. УГВ2 генерирует сигнал, тормозящий F2 (сигнал сброса) 10. Это приведет к снятию паттерна V с входа F1, и в поле F1 восстановится первоначальный паттерн X 11. Пройдя через mij, паттерн X преобразуется в S 12. S не сможет активировать первоначальный паттерн Y из-за торможения, поэтому активируется близкий к нему Y* 13. Y* проходит через mji и преобразуется в V* 14. Для V* повторяются шаги с [7] |
4. Обучение
Следы долговременной памяти подчиняются правилу обучения (1):

где xi – выход в F1,
yi – выход в F2,
k=const,
Eij - коэффициент “забывания”.
Вследствие забывания следы ДВП между активными нейронами в F2 и неактивными в F1 исчезают, что приводит к их уточнению входным образом. Для связей сверху вниз Eij=1, а для связей снизу вверх

где L=const.
Такое задание Eij обеспечивает выполнение правила Вебера: при обучении снизу вверх следы при запоминании паттерна X с меньшим количеством активных нейронов должны быть больше, чем у паттерна с большим количеством активных нейронов при прочих равных условиях. Такая зависимость может быть достигнута путем конкуренции между следами ДВП за синаптические ресурсы нейронов F2, что и описывается формулой (2).
Возможность использования нейросетей
Классификация - это одна из «любимых» для нейросетей задач. Причем нейросеть может выполнять классификацию даже при обучении без учителя (правда, при этом образующиеся классы не имеют смысла, но ничто не мешает в дальнейшем ассоциировать их с другими классами, представляющими другой тип информации – фактически наделить их смыслом). Любой речевой сигнал можно представить как вектор в каком-либо параметрическом пространстве, затем этот вектор может быть запомнен в нейросети. Одна из моделей нейросети, обучающаяся без учителя – это самоорганизующаяся карта признаков Кохонена. В ней для множества входных сигналов формируется нейронные ансамбли, представляющие эти сигналы. Этот алгоритм обладает способностью к статистическому усреднению, т.е. решается проблема с вариативностью речи. Как и многие другие нейросетевые алгоритмы, он осуществляет параллельную обработку информации, т.е. одновременно работают все нейроны. Тем самым решается проблема со скоростью распознавания – обычно время работы нейросети составляет несколько итераций.
Далее, на основе нейросетей легко строятся иерархические многоуровневые структуры, при этом сохраняется их прозрачность (возможность их раздельного анализа). Так как фактически речь является составной, т.е. разбивается на фразы, слова, буквы, звуки, то и систему распознавания речи логично строить иерархическую.
Наконец, ещё одним важным свойством нейросетей (а на мой взгляд, это самое перспективное их свойство) является гибкость архитектуры. Под этим может быть не совсем точным термином я имею в виду то, что фактически алгоритм работы нейросети определяется её архитектурой. Автоматическое создание алгоритмов – это мечта уже нескольких десятилетий. Но создание алгоритмов на языках программирования пока под силу только человеку. Конечно, созданы специальные языки, позволяющие выполнять автоматическую генерацию алгоритмов, но и они не намного упрощают эту задачу. А в нейросетях генерация нового алгоритма достигается простым изменением её архитектуры. При этом возможно получить совершенно новое решение задачи. Введя корректное правило отбора, определяющее, лучше или хуже новая нейросеть решает задачу, и правила модификации нейросети, можно в конце концов получить нейросеть, которая решит задачу верно. Все нейросетевые модели, объединенные такой парадигмой, образуют множество генетических алгоритмов (см. приложение 7.4). Генетические алгоритмы обязаны своим появлением эволюционной теории (отсюда и характерные термины: популяция, гены, родители-потомки, скрещивание, мутация). Таким образом, существует возможность создания таких нейросетей, которые не были изучены исследователями или не поддаются аналитическому изучению, но тем не менее успешно решают задачу.
Итак, мы установили, что задача распознавания речи может быть решена при помощи нейросетей, причем нейросетевые алгоритмы имеют все права на конкуренцию с обычными алгоритмами.
Современные цифровые вычислительные машины намного
Современные цифровые вычислительные машины намного превосходят человека по способности производить числовые и символьные вычисления, однако отличаются крайне низкой эффективностью в задачах, связанных с обработкой данных, представленных большим количеством нечеткой и неполной информации (например, распознавания образов), тогда как мозг живых существ, каждый элемент которого обладает сравнительно низким быстродействием, справляется с такими задачами за доли секунды. Приняв гипотезу, что обработка информации мозгом осуществляется путем передачи электрохимических сигналов между отдельными вычислительными элементами, возникает вопрос, а можно ли искусственно смоделировать такую вычислительную систему? Таким образом, в классической работе МакКаллока и Питтса 1943 г. впервые было обозначено новое научное направление - теория нейронных сетей. В работе утверждалось, что, в принципе, любую арифметическую или логическую функцию можно реализовать с помощью простой нейронной сети. В настоящее время происходит бурный рост теории нейронных сетей, и в ближайшем будущем ожидается достижение значительных результатов, в первую очередь в связи с успехами в областях, связанных с аппаратной реализации нейросетевых моделей.
Исследование нейросетей обусловлено также потребностью в увеличении роста производительности вычислительных систем. Увеличение сложности и быстродействия современных последовательных процессоров скоро упрется в границы, обусловленные физическими законами (предел интеграции и тактовой частоты). Выход – использовать параллельные вычислительные системы, но при этом возникает другая проблема – сложность написания эффективных алгоритмов для параллельной обработки без излишнего дублирования действий. Нейросетевая обработка информации, одним из принципов которой является массовый параллелизм, позволяет решить эту проблему. Возможно, теория нейронных сетей позволит не только разрабатывать алгоритмы для таких узких систем, как нейроподобные сети, но и позволит перенести результаты на более широкий класс параллельных вычислительных систем при большом числе составляющих их элементов.
Ещё одной причиной пристального внимания к нейросетям является высокая степень самоорганизации, присущая многим нейросетевым алгоритмам, т.е. на основе нейросетей легко можно создавать самообучающиеся адаптивные вычислительные системы, построение и настройка которых намного проще написания программ для современных последовательных компьютеров.
Теоретическое исследование нейросетевых алгоритмов ведется уже давно, и на данный момент они уже широко применяются для решения практических задач. В связи с очевидной конкурентоспособностью этого способа обработки информации по сравнению с существующими на сегодняшний момент традиционными способами особый интерес представляет проблема определения круга задач, для которых было бы эффективным применение нейросетевых алгоритмов. Распознавание образов – это одна из задач, успешно решаемых нейросетями. Одним из приложений теории распознавания образов является распознавание речи. Проблема распознавания речи как одно из составляющих искусственного интеллекта давно привлекала исследователей, и на сегодняшний день хоть и достигнуты определенные успехи, она остается открытой. Объединенная с проблемой синтеза речи, она представляет очень интересное поле для исследований.
В работе сделана попытка создать основанную на нейросетевой обработке данных интегрированную самообучающуюся систему, в которой в отличие от большинства существующих систем объединены алгоритмы распознавания и синтеза речи (при обучении система одновременно учится как распознаванию, так и синтезу). На начальном этапе программистом в неё не закладывается никакая информация, обучение происходит просто путем подачи на вход примеров. Такие самообучающиеся системы обладают многими полезными свойствами, выделяющими их из класса остальных вычислительных систем (см. раздел Самообучающиеся системы). А реализация таких системы на основе нейросетевых алгоритмов наделяет их значительной вычислительной мощью и простотой программирования.
В работе ставились следующие задачи:
§ Исследование методов ввода, обработки и анализа звуковых сигналов при помощи компьютера.
§ Изучение специфики речевых сигналов, определение их характерных свойств и построение на основе этих знаний модели распознавания и синтеза речи
§ Решение проблем, возникающих при практическом применении нейросетевых алгоритмов;
§ Формулировка общих принципов построения самообучающихся систем и их применение на примере системы автоматического распознавания и синтеза речи
§ Построение инструментальной базы на персональном компьютере для проведения вышеперечисленных исследований.
§ создание полной поддерживающей документации для возможности использования системы другими исследователями.
Для решения этих задач была разработана интегрированная система, программно реализованная в среде Windows на IBM-совместимом персональном компьютере; была достигнута открытость всех алгоритмов (т.е. возможность управления и контроля над всеми процессами в ходе обучения и работы). Для построения удобного пользовательского интерфейса использовалась среда разработки Borland C++ Builder 4.0. Параллельно с разработкой системы были созданы следующие инструментальные средства:
§ Инструмент для спектрального анализа речи, как записанной в файлы, так и в реальном времени
§ Инструмент для синтеза звуков речи вручную, основанный на формантно-голосовой модели
§ Инструмент для визуализации процессов обучения и распознавания в используемой нейросетевой модели
§ Инструмент для записи звука в файлы на жестком диске
Сама система представляет собой программно смоделированную нейросеть, вспомогательные процедуры по вводу, обработке и выводу сигналов, и процедуры визуализации работы всех алгоритмов.Имеется возможность выбрать конфигурацию будущей системы, для каждой конфигурации создается отдельный проект с возможностью сохранения на диск и восстановления.
Ввод звукового сигнала
Ввод звука осуществляется в реальном времени через звуковую карту или через файлы формата Microsoft Wave в кодировке PCM (разрядность 16 бит, частота дискретизации 22050 Гц). Работа с файлами предпочтительней, так как позволяет многократно повторять процессы их обработки нейросетью, что особенно важно при обучении.
Процесс ввода звука изображен на рисунке 8:
Ввод звука

Рис. 8
При обработке файла по нему перемещается окно ввода, размер которого равен размеру окна дискретного преобразования Фурье (ДПФ) – N элементов. Смещение окна относительно предыдущего положения можно регулировать. В каждом положении окна оно заполняется данными типа short (система работает только со звуком, в котором каждый отсчет кодируется 16 битами). После ввода данных в окно перед вычислением ДПФ на него накладывается окно сглаживания Хэмминга:

где Data – массив данных
newData – массив данных, полученный после наложения окна сглаживания
N – размер ДПФ
Наложение окна Хэмминга немного понижает контрастность спектра, но позволяет убрать боковые лепестки резких чстот (рис 9), при этом особенно хорошо проявляется гармонический состав речи.
Действие окна сглаживания Хэмминга (логарифмический масштаб)

без окна сглаживания с окном сглаживания Хэмминга
Рис 9
После этого выполняется дискретное преобразование Фурье по алгоритму быстрого преобразования Фурье [4]. В результате в реальных и мнимых коэффициентах получается амплитудный спектр и информация о фазе. Информация о фазе отбрасывается и вычисляется энергетический спектр:

где E[i] – энергии частот
Так как звуковые данные не содержат мнимой части , то по свойству ДПФ результат получается симметричным, т.е. E[i] = E[N-i]. Таким образом, размер информативной части спектра NS равен N/2.
Все вычисления в нейросети производятся над числами с плавающей точкой и большинство сигналов ограничены диапазоном [0.0,1.0], поэтому полученный спектр нормируется на 1.0.
Для этого каждый компонент вектора делится на его длину:


Информативность различных частей спектра неодинакова: в низкочастотной области содержится больше информации, чем в высокочастотной. Поэтому для предотвращения излишнего расходования входов нейросети необходимо уменьшить число элементов, получающих информацию с высокочастотной области , или, что тоже самое, сжать высокочастотную область спектра в пространстве частот. Наиболее распространенный метод благодаря его простоте – логарифмическое сжатие, или mel-сжатие (см. [3], “ Non-linear frequency scales”):

где f – частота в спектре, Гц,
m – частота в новом сжатом частотном пространстве
Процесс логарифмического сжатия проиллюстрирован рисунком 10:
Нелинейное преобразование спектра в пространстве частот

Рис. 10
Такое преобразование имеет смысл, только если число элементов во входе нейросети NI меньше числа элементов спектра NS.
После нормирования и сжатия спектр накладывается на вход нейросети. Вход нейросети – это линейно упорядоченный массив элементов, которым присваиваются уровни соответствующих частот в спектре. Эти элементы не выполняют никаких решающих функция, а только передают сигналы дальше в нейросеть. Наложение спектра на каждый входной элемент происходит путем усреднения данных из некоторой окрестности, центром которой является проекция положения этого элемента в векторе входов на вектор спектра (рис. 10). Радиус окрестности выбирается таким, чтобы окрестности соседних элементов перекрывались. Этот прием часто используется при растяжении/сжатии векторов, (например, изображений), предотвращая «выпадение» данных. Полученный результат очень похож на действие полосовых фильтров, каждый из которых выделяет определенную полосу частот, а все вместе они перекрывают весь полезный спектр частот.
Выбор числа входов – сложная задача, потому что при малом размере входного вектора возможна потеря важной для распознавания информации, а при большом существенно повышается сложность вычислений (только при моделировании на PC, в реальных нейросетях это неверно, т.к.
все элементы работают параллельно).
При большой разрешающей способности ( большом числе) входов возможно выделение гармонической структуры речи и как следствие определение высоты голоса. При малой разрешающей способности (малом числе) входов возможно только определение формантной структуры.
Как показало дальнейшее исследование этой проблемы, для распознавания уже достаточно только информации о формантной структуре. Фактически, человек одинаково распознает нормальную голосовую речь и шепот, хотя в последнем отсутствует голосовой источник. Голосовой источник дает дополнительную информацию в виде интонации (изменением высоты тона на протяжении высказывания), и эта информация очень важна на высших уровнях обработки речи. Но в первом приближении можно ограничиться только получением формантной структуры, и для этого с учетом сжатия неинформативной части спектра достаточное число входов выбрано в пределах 10~50.
После наложения сигнала на вход нейросети начинается его обработка нейросетью. Подробно работа нейросети описана в разделе 5.2.
В дипломной работе была показана
В дипломной работе была показана возможность решения задачи распознавания и синтеза речи с использованием нейросетевых алгоритмов, были выявлены основные преимущества их применения перед обычными последовательными вычислительными машинами. Были созданы необходимые для проведения исследований инструментальные средства и при их помощи разработана модель системы распознавания и синтеза речи на основе нейросети. Была выполнена серия экспериментов, исходные данные и результаты которых включены в дипломную работу. На основе этих экспериментов был произведен анализ применяемых нейросетевых алгоритмов, были выявлены их преимущества и недостатки.
Для возможности использования разработанной системы и инструментальных средств другими исследователями была создана справочная система, все исходные коды программ были снабжены комментариями.
